Ollama本地部署

一、简介
Ollama 是一个开源的本地大模型部署工具,旨在简化大型语言模型(LLM)的运行和管理。通过简单命令,用户可以在消费级设备上快速启动和运行开源模型(如 Llama、DeepSeek 等),无需复杂配置。它提供 OpenAI 兼容的 API,支持 GPU 加速,并允许自定义模型开发。
二、本地部署
官网地址:Ollama
2.1、windows部署
windows下载后直接安装
2.2、linux 部署
1、Linux因网络原因会安装Ollama失败
# 1、下载ollama_install.sh并保存
curl -fsSL https://ollama.com/install.sh -o ollama_install.sh# 2、使用github文件加速替换github下载地址
sed -i 's|https://ollama.com/download/ollama-linux|https://gh.llkk.cc/https://github.com/ollama/ollama/releases/download/v0.5.7/ollama-linux|g' ollama_install.sh# 3、替换后增加可执行权限
chmod +x ollama_install.sh# 4、执行sh下载安装
sh ollama_install.sh
2、ollama 提供给外部访问
# 1、修改ollama配置
vi /etc/systemd/system/ollama.service# 2、增加配置
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_ORIGINS=*# 3、重启ollama
systemctl restart ollama
postMan访问效果
http://10.11.20.40:11434/v1/chat/completions
http://10.11.20.40:11434/api/chat#请求
{"model": "qwen3:1.7b","messages": [{"role": "user","content": "hello"}],"stream": false
}三、常用命令
命令运行格式:ollama run {model},示例下载模型:
ollama run llama3.2 #或者 ollama run deepseek-r1:7b
| 命令 | 作用描述 |
|---|---|
ollama serve | 启动 Ollama 服务(后台运行) |
ollama create | 通过 |
ollama run | 运行指定模型(如 |
ollama list | 列出所有已下载模型 |
ollama ps | 查看正在运行的模型 |
ollama rm | 删除指定模型(如 |
ollama pull | 从注册表拉取模型(如 |
ollama stop | 停止正在运行的模型 |
ollama show | 显示模型详细信息(如 |
| ollama help | 查询帮助命令 |
四、模型存储路径优化
默认路径问题
-
Windows:
C:\Users\<用户名>\.ollama -
Linux/macOS:
~/.ollama -
问题:可能占用系统盘空间,尤其对小容量 SSD 用户不友好。
路径迁移方案
Windows
-
右键「此电脑」→ 属性 → 高级系统设置 → 环境变量。
-
新建系统变量
OLLAMA_MODELS,路径设为D:\ollama\model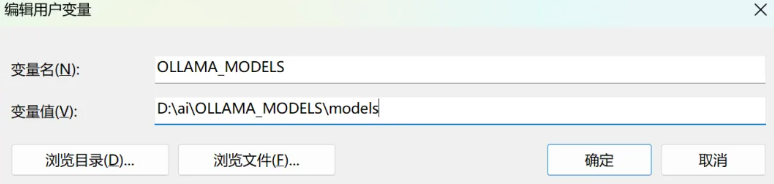
-
重启电脑或终端后生效。
Linux/macOS
五、模型管理:从下载到优化
1.、模型下载
- 官方模型:
ollama pull llama3 # 下载 Llama3 模型-
自定义模型:
-
准备模型文件(如 GGUF 格式,从 Hugging Face 下载)。
创建 Modelfile 配置模板(示例):
name: mymodel
template: qwen
path: /path/to/your/model.q4_K_M.gguf构建模型:
ollama create mymodel -f Modelfile2. 运行与交互
-
终端交互:
ollama run --gpu mymodel # 启动 GPU 加速输入问题后按
Ctrl+D提交,等待模型响应。 -
API 调用:
Ollama 内置 OpenAI 兼容 API,通过http://localhost:11434访问:curl http://localhost:11434/v1/models # 查看模型列表 curl -X POST "http://localhost:11434/v1/completions" -H "Content-Type: application/json" -d '{"mod
3. 性能监控与优化
-
显存不足:
-
选择轻量模型(如
deepseek:1.5b)。 -
尝试低精度版本(如
q4_K_M或q3_K_L)。
-
-
内存不足:
-
确保至少 8GB 内存(小模型)或 32GB+(大模型)。
- 使用
--verbose参数监控资源消耗:
输出示例:ollama run deepseek-r1:70b --verbosetotal duration: 12m1.056s # 总耗时 load duration: 1.810s # 模型加载时间 eval rate: 2.09 tokens/s # 生成速度
-
六、安全加固指南
1. 限制网络访问
-
默认风险:Ollama 默认监听
0.0.0.0:11434,可能暴露公网。 - 解决方案:
# 仅允许本地访问 export OLLAMA_HOST=127.0.0.1:11434 # 或通过环境变量设置 OLLAMA_HOST=127.0.0.1:11434 ollama serve
2. 关闭危险端口
-
若仅本地使用,可通过防火墙屏蔽
11434端口的外部访问。
3. 定期更新版本
-
Ollama 定期修复安全漏洞,建议升级到最新版:
七、总结与建议
-
硬件规划:
-
7B 模型需 8GB 内存,70B 模型需 32GB+。
-
显存不足时优先选择低精度版本。
-
-
安全第一:
-
避免将 Ollama 端口暴露公网,定期更新版本。
-
-
模型选择:
-
根据需求选择(如
DeepSeek适合代码生成,Qwen适合多语言)。
-