具身-机器人-分层框架-大脑模块-RoboBrain1.0 RoboOS
截止当前(2025年5月),具身领域无论是基于长程任务还是桌面操作任务上,实现的架构尚未统一,大致分为两个流派,一类是推崇纯端到端VLA方式,另一类是推崇大小脑分层方式。代表模型介绍如下:
- 纯端到端VLA方式: 其输入为视觉+语言+机器人状态(可选),直接输出关节角度、末端位姿增量、关节角度序列等。直接输出下一时刻关节角度的代表有Google-RT系列,其动作模块基于自回归实现,输出末端位姿的代表有OpenVLA,输出一段时间内关节角度序列的如π0、RDT,其动作专家多是基于扩散模型或基于CVAE的输出。该类方法往往是一个VLM+动作专家形式,而这个VLM往往比较小,如π0为3B,这类模型如果数据分布不足或数据量少的情况下,泛化能力比较差,对于物体平面位姿、高度、背景等比较敏感,如Open-VLA 使用4k 小时的开源数据集进行训练,而π0 则利用10k 小时的专有数据,从而显著提升了性能。但只要数据量够多,够充足,该类方法是值得推崇的。
- 大小脑分层方式: 个人认为分层方式包括两类,一类是大脑输出显示任务拆解结果或抓取的目标框等,代表模型如RoboBrain系列;另一类是大脑输出隐式向量(包括场景语言信息+“规划结果”)的,比较有代表性的是Figure-Helix、星动纪-ERA42、pi0.5、Germini Robotic。基于此模式下,大脑模块可以是VLM大模型如Qwen-VL系列、GPT-4o等,也可以是基于LLava、Qwen系列微调或全量训练的。小脑模块包括底盘运动和机械臂操作模块,其中机械臂操作模块可以选择为基础模型如GraspNet、AnyGrasp、FoundationPose,传统方法如直接解算IK或借用Moveit!工具,端到端VLA如π0、RDT等,也可为纯模仿学习ACT或纯强化学习模型等。底盘运动模块可以是SLAM+Navigagtion也可以为VLN如PointNav或ObjectNav。该类方法在工程化或端到端VLA未彻底成熟前,是值得推崇的。
本篇分享将基于大小脑分层方式中的RoboBrain以及由其延伸的RoboOS的分析来展开,此类模型是2025年3月,由北京智源研究院相继发布的面向长程作业任务的大脑模块RoboBrain1.0和跨本体多机协同的通用大脑系统RoboOS(基于RoboBrain1.5),通过背景、方法、模型、数据、训练方式、实验和思考几个方面来深入分析。
1. RoboBrain1.0
1.1 一句话总结
使用qwen-7B借助LLAVA搭建一套网络,在RT-X选择数据上标注了一套数据集,可以看图做任务规划、可抓取区域预测、末端轨迹预测。并做实验证明这一思路,开放了全部数据、代码和训练参数。

模型结果概览:
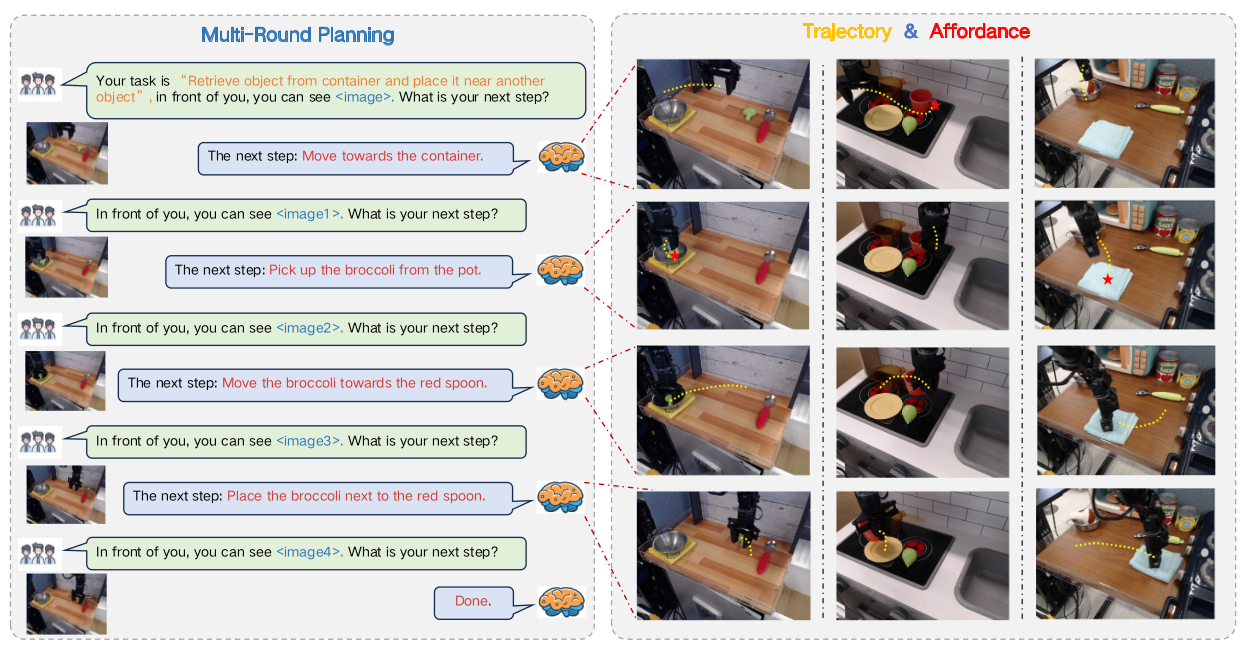
其中任务拆解: 偏向于单步结果,其prompt可选择预测下一步骤,或者余下几步。可供性是预测抓取的区域框,轨迹是拿放流程中在2D图片上的像素轨迹,可进一步转换为3D空间。
1.2 背景及主要工作概述:
背景: 当前的多模态模型如Palm-E可以分解任务,但作者认为他们缺乏执行复杂原子任务的足够机制,也就是没有提供可供性区域选择,规划出来的结果机器人不一定能执行。
主要工作:
-
设计了RoboBrain模型框架.这是一个专为机器人操作设计的统一多模态大语言模型,它通过将抽象指令转化为具体动作,有助于更高效地执行任务。siglip(siglip-so400m-patch14-384)特征提取对齐 + MLP投影(2层) + Qwen2.7-7B-Instruct作为LLM。
-
做了数据集ShareRobot. 102万个问答对,非自采,从Embodied-X数据集中筛选),这是一个高质量的异构数据集,它对包括任务规划、物体可供性和末端执行器轨迹在内的多维信息进行标注,有效提升了机器人的各项能力
-
训练数据比例设计+融入了长视频。精心设计了机器人数据与通用多模态数据的比例,实施了多阶段训练策略,并和高分辨率图像。这种方法为 RoboBrain 提供了历史帧记忆和高分辨率图像输入,从而进一步增强了其在机器人操作规划方面的能力。
1.3 模型介绍

输入:视频或多视角图像 + 用户指令
输出: 规划结果 + 可供性区域 + 轨迹,其中规划结果支持107个低级指令
关键模块: 分词器(代码中默认选择千问的分词器) + 图像特征提取(siglip) + 投影器(MLP) + LLM(Qwen2.5)+ 可供性选择微调模块 A-LoRA + 轨迹输出微调模块T-LoRA
1.4 数据来源及数据格式

1.视觉和文本对齐用的数据: 来源于开源数据
2.适应机器人任务规划的数据:开源数据 + 自做数据。
其中,自做数据特别说明如下:
1)来源: 从 Open-X-Embodiment 数据集 [66] 中选取数据,制定了严格的标准,重点关注高分辨率、准确的描述、成功的任务执行、可辨识的可供性以及清晰的运动轨迹。拥有 1,027,990 个问答对,,ShareRobot 涵盖了 12 种实体中的 102 个场景以及 107 种原子任务类型,是用于任务规划、可供性感知和轨迹预测的最大规模的开源数据集。注意由于其数据要求严格可能带来一些缺点:
a) 数据中剔除了任何目标物体或末端执行器被其他物体遮挡的视频,因为其要求能够准确识别出可供性区域。因此物体有遮挡时候是不行的。
b) 高清高质量图片,视频超过30s的
c)只要成功的,没有使用失败的数据。
2)格式:问答对的格式是使用RoboVQA中的10种问题类型,可供性区域是标注矩形框,轨迹是给出点集列表。任务规划数据100万训练/2050测试(由Germma大模型prompt生成),可供性判断6000训练/522测试,轨迹预测6000训练/870测试。
3.适应机器人可供性和轨迹输出的数据
自做数据集微调
1.5 训练方法
训练实际分2个大阶段,第一阶段专注于通用的 OneVision(OV)训练,以开发一个具备强大理解能力和指令跟随能力的基础多模态大语言模型。第二阶段,即机器人训练阶段,旨在赋予 RoboBrain 从抽象到具体的核心能力。

- 第一阶段:通用 OV 训练
- Stage-1:使用 LCS558K 数据集的图像 - 文本数据。该数据集是 LAION/CC/SBU 数据集的子集,经过筛选以确保概念覆盖的平衡分布。此阶段的作用是训练 Projector,使视觉编码器输出的视觉特征(Z_{v})能与 LLM 的语义特征(H_{v})对齐,为后续模型理解视觉信息奠定基础。
- Stage-1.5:利用 4M 高质量图像 - 文本数据,这些数据来源于 8 个不同数据源,如 BLIP558K、COCO118K 等。训练整个模型,增强模型对多模态通用知识的理解能力,让模型初步具备处理多种模态信息的能力。
- Stage-2:采用 3.2M 单图像数据(SI-3.2M )和 1.6M 图像与视频数据(OV-1.6M) 。SI-3.2M 包含多个数据集的子集并经过清洗和重新标注,OV-1.6M 包含重采样数据和视频数据。该阶段旨在增强 RoboBrain 的指令跟随能力,提高对高分辨率图像和视频的理解,使模型能更好地遵循指令进行任务处理。
- 第二阶段:机器人训练
- Stage-3:使用 1.3M 机器人数据,这些数据来自 RoboVQA800K、ScanView-318K(包含 MMScan-224K、3RScan-43K 等)以及 ShareRobot-200K 等数据集,还选取了约 1.7M Phase 1 的高质量图像 - 文本数据与之混合。提升模型的操作规划能力,其中 ShareRobot 数据集的细粒度、高质量规划数据发挥了重要作用,同时缓解灾难性遗忘问题,让模型在学习新的机器人数据时,不会忘记之前学到的通用知识。
- Stage-4:运用 ShareRobot 数据集以及其他开源来源的可供性和轨迹数据,并引入 LoRA 模块。增强模型从指令中感知物体可供性和预测操作轨迹的能力,使模型能够更准确地识别物体的可操作区域,并规划出合理的操作轨迹,实现从抽象指令到具体动作的转化。
训练的策略参考LLaVA-Onevision,使用8*A800GPUs
1.6 实验结果
设计了几个评测维度:
1) 基本视频推理能力:
视觉感知与多领域推理。这一类别聚焦于复杂的视觉感知以及多学科的推理任务。用于视觉感知的基准测试包括 MMStar [14]、MMBench [55] 和 MME [23],而推理基准测试则包括 MMMU [91] 和 SeedBench [39]。在多个基准测试中,RoboBrain 展现出了与 GPT-4V [2] 和 LLAVA-OV-7B [44] 相当的性能。
2) 机器人任务规划层面
为了评估 RoboBrain 在现实世界场景中执行机器人相关任务的能力表现,我们选择了 RoboVQA [73]、OpenEQA [61] 以及从所提出的 ShareRobot 数据集中提取的 ShareRobot 测试集,将它们作为用于多维度评估的机器人领域基准测试。
其中OpenEQA 和 ShareRobot 数据集评测时候使用GPT-4O对结果进行评分,而RoboVQA 基准上采用 BLEU1 - BLEU4 指标进行评估。
BLEU(Bilingual Evaluation Understudy)指标最初用于机器翻译评估,通过比较模型生成的文本与参考译文之间的相似度来打分。

支持107个低级指令,分布如下:

3)可供性选择AP

4)轨迹预测上,未与其他模型对比

1.7 消融结果
- 各阶段对规划性能的影响:从第 1 阶段到第 3 阶段的训练持续且有效地提升了模型的规划性能。在 RoboVQA 任务中,第 1.5 阶段模型得分仅为 2.60,到第 3 阶段提升至 62.96;在 ShareRobot 任务上,第 1.5 阶段得分为 9.81,第 3 阶段达到 65.05。这表明前期阶段的训练对模型理解和处理任务规划起到了关键作用,逐步增强了其规划能力。
- 第 4 阶段对特定能力的提升:第 4 阶段主要增强了模型的可供性和轨迹能力。在可供性方面,模型在该阶段训练后,AP 值从之前的较低水平提升至 27.1,表明其识别物体可供性区域的能力显著提高;在轨迹预测上,模型的相关误差指标得到优化,如与基线相比,DFD 降低了 42.9%,HD 降低了 94.2%,RMSE 降低了 31.6% ,意味着模型预测的轨迹更接近真实轨迹,性能得到极大改善。
1.8 不足
- 规划方面:在 “清洁桌子” 任务中出现失误。存在物体识别错误,将图像中的 “纸巾” 误识别为 “消毒湿巾”;遗漏关键步骤,在擦拭桌子前未规划抽取纸巾的动作;行动决策偏差,未优先清理洒出的咖啡液体,而是聚焦于清洁整个桌子。原因可能是桌子和洒出咖啡颜色相近,干扰了模型判断。不过在大量测试中,这类不合理案例较少,整体规划能力依然可靠。
- 可供性感知方面:存在误判情况。如在某些场景下出现误识别物体、受场景中其他物体干扰,甚至无法识别物体的现象。这主要是因为模型在复杂、嘈杂环境中的感知和定位能力有限,训练数据可能未充分覆盖这些特殊场景。
- 轨迹预测方面:在一些操作中出现问题。比如机器人末端执行器无法准确找到杯子位置,打开冰箱门时未考虑门的铰接特性,折叠衣物时未考虑衣物的可变形属性。这些问题反映出模型在空间感知、对物体物理约束和世界知识的理解与应用上存在不足,需要进一步改进以生成更合理、可行的轨迹。
2. RoboOS
2.1 一句话概况
相比单一的大脑RoboBrain,RoboOS是一个大框架,囊括大脑和小脑。其中大脑又分为决策层和记忆层。决策层是基于RoboBrain1.0,添加多机协同完成任务的数据进行训练得到的RoboBrain1.5。记忆层包括空间环境信息(类似SceneGraph或SceneScript描述了几个房间,有哪些家具,家具上有哪些物体等,各个机器人当前在哪,该部分可以基于一些视觉基础模型来构建,也可以基于一些基于模型的slam来构建和实时更新)、时空信息如历史操作信息(本任务已经操作过的子任务有哪些)、实时本体信息(当前机器人都在干啥,手臂是否拿取了啥物体等)。小脑是指的是该模型实验兼容的各个机器人,由于大脑和本体解耦了,只要某本体具备了既定的操作能力,任意切换本体就可以。该大脑模块可以部署在云端,控制多个机器人,达到“一脑多机”形态。
2.2 背景及主要工作
作者提出了但当前的机器人系统仍面临着持续存在的局限性,包括跨实体适应性差、任务调度效率低下以及动态错误纠正不足。像 OpenVLA 、RDT-1B 和π0这样的端到端视觉语言动作模型在长期规划和任务泛化方面表现较弱,而诸如 Helix、Gemini-Robotics 、GR00T-N1 、Hi-Robot 和π0.5 等分层 VLA 框架则存在跨实体兼容性碎片化以及在可扩展多智能体协调方面面临挑战的问题。这些问题凸显了迫切需要一个统一的系统,该系统能够将高级认知与低延迟执行相连接,同时促进异构机器人之间的无缝协作。其实说白了最的亮点还是为了突出多机器人协作。
基于此背景,作者提出了这个大脑 - 小脑分层架构RoboOS,主要做了这四个事:
1)大脑决策模型RoboBrain1.5,这是一个多模态大语言模型(MLLM),负责协调全局感知 —— 包括 3D 场景重建和历史状态跟踪 —— 以及进行高级决策,以实现多智能体任务分解和感知功能的轨迹生成,同时通过实时重新规划动态纠正错误;
2)小脑技能库,这是一个模块化的即插即用工具包,支持异构实体(例如单臂、人形机器人)以低延迟执行操作(基于视觉语言动作的工具、基于专家知识的工具)、导航(基于视觉语言导航的工具VLN系列如MapNAV、同步定位与地图构建如cartographer、fastlio或其他基于模型的slam)以及专业技能 ;
3)大脑实时共享内存,这是一个时空同步中心,用于维护空间记忆(例如空间关系、物体和机器人的位置)、时间记忆(例如任务反馈、工具调用历史)和实体记忆(例如运动域、关节状态和电池电量),以实现机器人之间的故障预测和负载平衡。
4)高性能部署:RoboOS 通过边缘云通信和基于云的分布式推理来优化可扩展性,借助该团队深度参与开放的 Flagscale 确保实现高频交互以及云推理的大规模部署。

2.3 模型介绍
如图所示,RoboOS总体组成架构由大脑决策模块、大脑共享记忆模块和小脑执行器模块的展示,其承接复杂场景任务、长程任务等,经过RoboOS后由不同的本地联合实现。

不同模块的介绍如下:
大脑决策模块 - 这个里面最核心的是大脑决策层的设计,基于 RoboBrain1.0 的功能 —— 单机器人规划、功能预测和轨迹预测,利用预训练的 Qwen2.5VL-7B 模型实施多阶段训练,以改进多机器人任务规划、基于智能体的工具调用和时空更新。关键的增强功能包括:多机器人任务规划,利用实时共享的时空记忆来预测协作任务的工作流程拓扑结构;基于智能体的工具调用,管理智能体并根据反馈进行自我纠正规划,按需调用工具;时空记忆更新,根据子任务执行情况和工具反馈实时动态更新共享内存;低级指导,在工具执行过程中预测可操作区域和轨迹,以辅助操作。下节讲重点讲述数据如何采集,如何训练的。
大脑-实时共享内存:该组件维护空间、时间和机器人相关的内存信息,以实现机器人之间的故障预测和负载均衡。空间内存由场景图 [61] 构成,用于跟踪实时空间关系、物体位置和机器人的位置。时间内存记录任务执行历史、反馈、工具调用日志及其他时间相关数据,为自适应决策提供支持。机器人内存存储实时系统属性,如运动域约束、关节状态和电池电量等信息,根据每个机器人的能力、电量状态和连接条件来优化任务分配。
小脑技能库:涵盖三个关键方面,机械臂操作方面,整合了基于专家知识的工具(如感知功能抓取、通用抓取)和基于视觉语言动作(VLA)的工具(如 OpenVLA、RDT-1B 、Octo 、π0);导航方面,支持传统的建图 - 定位 - 导航流程(如同步定位与地图构建)以及视觉语言导航(VLN)工具(如 MapNav 、NavID );还有用于丰富接触交互、可变形物体处理和灵巧手部控制的专业技能。
说白了这个RoboOS还是属于一套实现流程,其实现的工作流如下:

分为4个步骤:
1)用大脑决策模块拆解人的指令:
在接收到全局任务指令T_{global}后,RoboOS 通过 RoboBrain 启动检索增强生成(RAG)过程,查询共享空间内存,提取与环境相关的信息M_{s}。这些信息会与以下内容进行整合:(i)先前任务执行的状态反馈M_{t}(存储在共享时间内存中);(ii)机器人的运行状态S_{r}(空闲、忙碌或离线);(iii)机器人技能库M_{r};以及(iv)T_{global}。RoboBrain 对这些输入进行处理,生成结构化推理轨迹R和子任务图G,其形式化表示为:

其中,⊕表示多模态输入的连接或融合。
2)用子任务以及各个机器人当前位置来做拓扑子任务分配
监控器根据有向无环图G中编码的拓扑依赖关系,动态地并行调度和分配子任务。图G中的每个子任务分为两种类型:(1)单机器人子任务(d, r_{i}),由机器人r_{i}在拓扑深度d处自主执行;(2)协作子任务(d, r_{i: j}),需要在深度d处由多个机器人{r_{i}, …, r_{j}}协同执行。在这里,d表示执行优先级,而r_{i}(或r_{i: j})表示被分配任务的机器人。为了实施依赖约束,监控器采用并行分配方式 —— 在同一深度并发执行独立的子任务(例如,图 3 中的(1, R_{1})和(1, R_{2}),以及顺序分配方式,即子任务(d + 1, r_{k})会被阻塞,直到深度d处的所有先决条件都得到满足(例如(2, R_{1+2})。在实际应用中,该系统支持对多个子任务图{G_{1}, G_{2}, …, G_{n}}进行并发管理,确保能够实时适应机器人的动态状态和不断变化的任务依赖关系。
3)分布式子任务智能体
对于每个子任务,RoboOS 都会部署一个专门的机器人智能体来管理执行过程。该智能体基于以下几点自主地从技能库中协调工具选择:(1)先前执行任务的反馈;(2)工具调用历史记录;(3)对环境的部分空间记忆。这种闭环推理有助于动态错误恢复。例如(图 3),当接到 “寻找一个鸡蛋并将其放在桌子上” 的任务时,智能体会按顺序调用工具(比如 “检测鸡蛋”)。如果搜索失败(例如,在厨房中未检测到鸡蛋),智能体会利用空间记忆推断潜在的位置(例如,冰箱),并选择导航工具来 “移动到冰箱处”,通过迭代优化工具使用来展示自适应恢复能力。
4)动态内存更新
在完成一个子任务后(无论成功与否),共享内存都会进行更新。例如,如果 “寻找一个鸡蛋并将其放在桌子上” 这一子任务成功完成,在ScenceGraph中鸡蛋的位置会从 “厨房” 更新为 “桌子”,事实上,这些信息理论上两种方式都是可以更新,第一种是实时更新,即SceneGraph可以利用其构建的方法实时更新的,另一种是基于既定已完成的任务来确定性修改。
2.4 数据来源及数据格式
数据集包含三类:视觉语言模型(VLM)数据集、机器人数据集以及 RoboOS 增强型数据集。

(1)视觉语言模型(VLM)数据集,包括:
- General-873k,从 LRV-400K [62] 和 LLaVA-665K [33] 中经过严格筛选和重组得到,通过涵盖描述性、分析性和推理性任务的多样化问答对,增强了广泛的问答能力。
- ScanView-318k 整合了来自 MMScan-224K [63](带注释的物体分割和文本描述)、3RScan-43K [65](带语义标签的 3D 重建数据)、ScanQA-25K [66](基于 3D 环境的问答对)和 SQA3D-26K [67](空间问答)的多模态 3D 场景理解数据,实现了细粒度的环境感知。
- VG-326k 结合了 Ref-L4 [70](涵盖 365 个物体类别的 4.5 万个表达式)、OV-VL [33](Llava-OneVision 中的视觉基础样本)、RefCOCO/RefCOCO+[68, 69](带有限制性 / 非限制性空间约束的自然语言描述)以及 Visual Genome [71](丰富的区域描述和关系注释),以实现精确的视觉基础定位。
- Spatial-R-1005k 利用 Ref-Reasoning-791K [72](包含属性 / 空间推理的复杂表达式以及对抗性图像)、COPS-Ref-148K [73] 和 Spatial-Trans66K [39] 来对组合关系进行建模。
- Temporal-R-525k 综合了 EmbodiedReasoner-9K [42]、HandMeThat-300K [74](基于抽象命令的规划)以及超过 20 万个模拟推理样本,用于理解顺序事件。所有数据集都经过了去重和质量筛选,以在平衡能力覆盖范围的同时消除噪声。
(2)机器人数据集:这些数据集是为了针对机器人的四项核心操作能力而精心整理的,如下面四类,除这四类还保留了第一阶段的10%数据:
- 规划 - 70 万个样本:整合了 RoboVQA - Clean - 20 万(从最初的 80 万个样本的 RoboVQA 重构而来)、ShareRobot - Plan - 40 万(ShareRobot 的规划子集)、RoboBench - 5 万(我们根据现实世界中的具身任务构建)和 AgiBotWorld - Alpha - 5 万,用于训练分层任务分解和长期规划。
- 指向 - 53.7 万个样本:统一了 Object - Ref - 34.7 万(28.7 万张带有基于坐标的问答图像)和 Pixmo - Point - 19 万(室内场景点注释),通过坐标回归来细化空间感知。
- 可供性 - 37.3 万个样本:合并了 Region - Ref - 32 万(27 万张带有交互区域问答的图像)、PACO - LVIS - 4.5 万(对象功能标签)和 ShareRobot - Affordance - 0.8 万,以预测可操作对象的属性。
- 轨迹 - 42.8 万个样本:结合了 LLaRVA - 42 万和 ShareRobot - Trajectory - 0.8 万来学习成功执行的操作序列。
(3)RoboOS 增强(OS)数据集:
RoboOS 框架内进行了多机器人任务规划和基于智能体的工具调用方面的工作。 - “多机器人 - 4.5 万” 数据集具有通过 DeepSeek-V3-0324 [60] 生成的 68 种协作任务类型(超市 / 家庭 / 餐厅场景),包含场景图、机器人规格以及用于子任务推理的工作流可视化。
- “机器人智能体 - 14.4 万” 数据集通过 DeepSeek-V3-0324 [60] 生成的样本扩充了 “多机器人 - 4.5 万” 数据集,采用概率采样的 “观察 - 动作” 对(14.4 万个正确样本和注入错误的样本变体),通过监督微调(SFT)和强化学习(RL)训练来提高操作的稳健性(14 万个样本用于监督微调,其余用于组相对偏好优化(GRPO))。这种架构确保了在保持多智能体协调和工具调用方面特定任务性能的同时,能够无缝适配 RoboOS 生态系统的实现。
2.5 训练方法
RoboBrain-1.5-OS 以 Qwen2.5-VL-7B的强大基础为依托,通过精心设计的三阶段训练范式逐步提升模型的通用能力和特定领域能力,包含三个阶段。
(1)在第一阶段,该模型使用 300 万个高质量的通用视觉语言模型(VLM)数据集进行全参数监督微调(SFT),学习率为 1e-4,在 20 台各配备 8 个 A800 GPU 的服务器上进行训练,旨在建立强大的基础视觉理解和推理能力。
(2)第二阶段专注于机器人领域,使用精心整理的 230 万个与机器人相关的训练数据,同时保留第一阶段 10% 的数据以防止灾难性遗忘。学习率降至 1e-5 以确保稳定收敛。
(3)最后一个阶段专门针对 RoboOS 进行优化,首先使用 24.5 万个 OS-SFT 样本(包含 2% 的第一阶段数据和 3% 的第二阶段数据)进行监督微调(SFT),然后使用 4000 个 OS-RL 样本(仅为工具调用样本)进行组相对偏好优化(GRPO)[85],利用强化学习(RL)的高效性和可扩展性。第三阶段的组相对偏好优化(GRPO)阶段进一步将学习率降至 1e-6,并在一台配备 8 个 A800 的服务器上经过 3 个训练周期完成训练。整个训练过程采用了 DeepSpeed Zero3 [81] 优化策略,精心配置了关键参数,包括批量大小(监督微调时为 2,组相对偏好优化时为 1)、最大序列长度(监督微调时为 32768,组相对偏好优化时为 8192)以及权重衰减(0.1)。完成次数(4 次)和最大完成长度(512)是组相对偏好优化的特定参数。详细的超参数见表 2。这种训练方案显著提升了模型在机器人应用中的性能以及系统兼容性,同时保留了 Qwen2.5-VL-7B [31] 的原有能力。
训练用参数如下:

3.6 实验结果
为评估 RoboOS 的核心组件 RoboBrain-1.5-OS 的具身能力,作者选择了参数规模相近的可对比的VLM如 LLaVA-OneVision-7B 、Qwen2.5-VL-7B ,LLM如 Qwen3-14B 、DeepSeek-V3-685B ,具身基准模型如 RoboPoint-14B 和 RoboBrain-1.0 作为通用基准。测试项为四项核心机器人操作能力(多机器人规划、指向预测、功能感知预测和轨迹预测)进行了全面评估,基准配置如下:
- 多机器人规划: 评估框架在三种任务场景(餐厅环境、商业超市和家庭环境)中评估多机器人规划能力。以 RoboOS 作为测试系统,我们采用工具调用准确率(AR)指标 [82] 进行定量评估。对于餐厅、超市和家庭这三种任务场景,我们从每个场景中随机采样并生成 200 个任务样本作为测试基准用于评估 RoboOS 中的全局任务分解和基于智能体的工具调用。
- 指向预测: 使用 Where2Place 数据集评估指向预测性能,该数据集包含 100 张描绘杂乱环境并标注了空间关系的真实世界图像。每张图像包括:(i) 描述所需自由空间的文本描述,(ii) 目标区域的真实掩码,以及 (iii) 用于探测模型对参考空间定位能力的相应查询点。通过使用 AR 指标针对目标掩码测量命中准确率来量化性能,以此评估机器人系统在解释空间参考和预测预期指向位置方面的精度。
- 功能感知预测:利用 AGD20K 基准 (一个包含超过 20,000 张标注图像、涵盖多种功能感知类别的综合数据集)来评估功能感知预测的性能。评估协议在多个交并比(IoU)阈值(0.25、0.50、0.75、0.90)下测量平均精度均值(mAP),对模型的稳健性进行严格评估。
- 轨迹预测:轨迹分析采用 ShareRobot-Trajectory 基准,使用三个互补指标:(1) 离散弗雷歇距离(DFD):计算预测轨迹和真实轨迹耦合遍历所需的最小牵引长度,捕捉几何相似性和时间对齐情况。(2) 豪斯多夫距离(HD):测量轨迹之间的最坏情况位置偏差。(3) 均方根误差(RMSE):量化逐点欧几里得距离误差的平均值。这种多指标方法能够从全局形状保持(DFD)到局部精度(RMSE)对轨迹质量进行分层分析,而豪斯多夫距离(HD)则用于识别关键的失败情况。
测试结果如表 所示,RoboBrain-1.5-OS 在多机器人规划方面取得了优异的性能,比 Qwen2.5-VL-7B 高出 28.14%,比 DeepSeek-V3-685B 高出 5.53%,从而提升了 RoboOS 的能力。在指向、功能感知和轨迹预测方面,它也优于所有基准模型,分别比 RoboBrain-1.0 提高了 3.64%、16.96% 和 40.77%,在多种具身能力上展现出了卓越的效果。
