bootstrap自助(抽样)法
一,概念

一言以蔽之:从训练集中有放回的均匀抽样——》本质就是有放回抽样;
自助法(bootstrap)是一种通过从数据集中重复抽样来估计统计量分布的非参数方法。它可用于构建假设检验,当对参数模型的假设存在怀疑,或者基于参数模型进行统计推断不可行、计算标准误差需要复杂公式时,自助法可作为替代方案。
说的更严谨点,就是随机可置换抽样(random sampling with replacement)


从总体中获取样本,再从样本中重采样获取重样本,即总体-样本-重样本的处理路线;
注意,从样本到重样本的重采样,通常需要确保重采样的大小和原本样本的大小一致(通常要求重采样的样本大小与原始样本大小相同)——
数据使用完备性,尽可能使用上所有的数据,另外一方面因为最终的目的是为了估计总体中的某个参数,也就是说无论是重样本还是样本,最终目的都是为了估计最上游总体中的某个参数,方法都是基于重样本或者是样本的统计量的估计。
所以一般要求重采样的样本大小与原始样本大小相同,目的是为了保证重采样样本能够尽可能地反映原始样本的分布特征,从而使得基于重采样样本得到的统计量的估计更加准确和可靠。如果重采样样本大小与原始样本大小不同,可能会导致估计结果出现偏差。
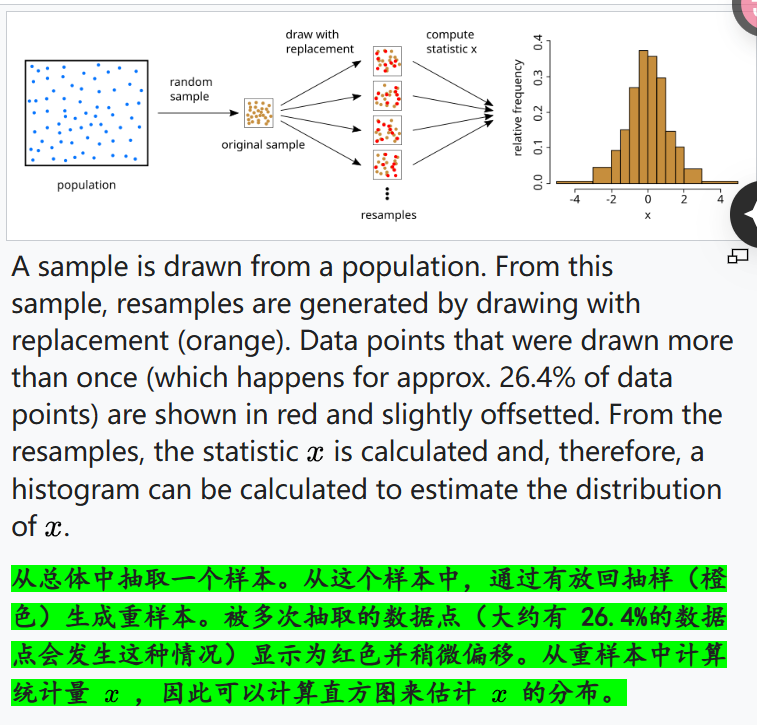
道理其实很简单:如果我的样本比如说是长度为1000的字符序列(比如说是长度为1000的氨基酸序列),那么我每次重采样,就需要从这个长度为1000的字符序列中重新采样生成长度为1000的一个样,这才是一个样;
我可以是采样原始氨基酸序列前100个字符重复10次;或者是重复后200个字符5次;
总之每个字符的选择都是有放回的采样采得的,然后一共采了1000个原始氨基酸序列长度个字符,这样才是一个样;
然后我需要按照这种采样规则采样n次,这就是bootstrap。
如果要严谨一点的、数学一点的定义:





自助法的基本原理

自助法的评估机制


自助法通过模拟重采样数据的经验分布 来近似原始数据的真实分布 ,并利用已知的 来评估推断的准确性。如果 是 的合理近似,那么就可以通过评估 的推断质量来推断 的推断质量。这种方法为在有限样本数据下进行统计推断提供了一种有效的途径。
————》
当然,嵌套了两层的近似,从总体-原始样本-重采样,总会有点概念上的迷惑,比如说近似传递性的证明是否严谨等?
我们需要更清晰地区分总体、样本和重样本,再次对以上内容进行复述;
总体、样本和重样本的定义
- 总体(Population)

- 样本(Sample)

样本分布对总体分布的近似就是一般初学者大一学的概率论中的统计推断、参数估计部分;
我们对于不同的总体,抽样获取的样本,也会有一个对应的分布。
- 重样本(Bootstrap Sample)

自助法的核心逻辑

详细解释
- 类比推断过程


- 评估
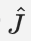 的准确性
的准确性

- 推断
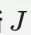 的质量
的质量

总的来说

——》
在这个表述下,我们对近似的传递性,会自然而然的有一个疑问:
我有一个问题,这里是从样本中有放回抽样得到样本分布的一个近似,那么样本分布又可能是总体分布的一个近似,那么这里的重采样获取的经验分布岂不是对总体分布近似的近似?
这种疑问的产生是因为数学严谨性要求自然产生的疑问,某种程度上这么理解是正确的。
自助法(bootstrap)确实是从样本中有放回地抽样,以得到样本分布的一个近似,而这个样本分布本身又是总体分布的一个近似。因此,通过重采样得到的经验分布可以被视为对总体分布的近似的近似。
为了更清楚地解释这一点,我们可以从以下几个方面来理解:
- 样本分布与总体分布:样本分布是根据从总体中抽取的样本数据计算得到的分布,它试图近似总体分布。由于样本量有限,样本分布可能无法完全准确地反映总体分布,但随着样本量的增加,样本分布通常会越来越接近总体分布。
- 重采样与经验分布:在自助法中,我们从原始样本中有放回地抽取多个重采样样本,每个重采样样本的大小与原始样本相同。然后,我们根据每个重采样样本计算出一个经验分布。这个经验分布是基于重采样样本的,因此它是对样本分布的一个近似。
- 近似的近似:由于样本分布本身是总体分布的近似,而经验分布又是样本分布的近似,因此经验分布可以被视为对总体分布的近似的近似。尽管存在这种双重近似,但自助法在很多情况下仍然能够提供对总体分布的可靠估计,特别是当原始样本量较大时。
- 自助法的有效性:自助法的有效性依赖于样本分布与总体分布之间的相似性,以及重采样样本与原始样本之间的相似性。如果样本量足够大,样本分布通常能够较好地近似总体分布,而重采样样本也能够较好地近似原始样本,从而使得经验分布成为对总体分布的一个合理近似。
综上所述,虽然经验分布是总体分布的近似的近似,但自助法通过重采样和利用样本分布的相似性,仍然能够提供对总体分布的有效估计。这种方法在统计学中被广泛使用,特别是在样本量有限或总体分布未知的情况下。

此处目的是为了获取均值这个统计量变异性的一个概念,也就是变异性的一个认知,说白了其实就是想构建这个均值的分布,也就是知道这个均值统计量的取值区间,类似于我们光估计出来均值=10不够,我们还想知道10±1或者±多少。
总的来说:自举法是为了推导一些非常复杂的统计量(比如说是协方差或者是分位数)的分布,比如说计算该统计量的标准误(标准误差SE)和置信区间(CI)的方法。


Bootstrapping不提供通用的有限样本保证,它的运用基于很多统计学假设,因此假设的成立与否会影响采样的准确性。(这个也是数学的魅力所在,在定义中的限制,就是显而易见的缺点,需要满足相应的统计学假设)



bootstrap自助法类型:
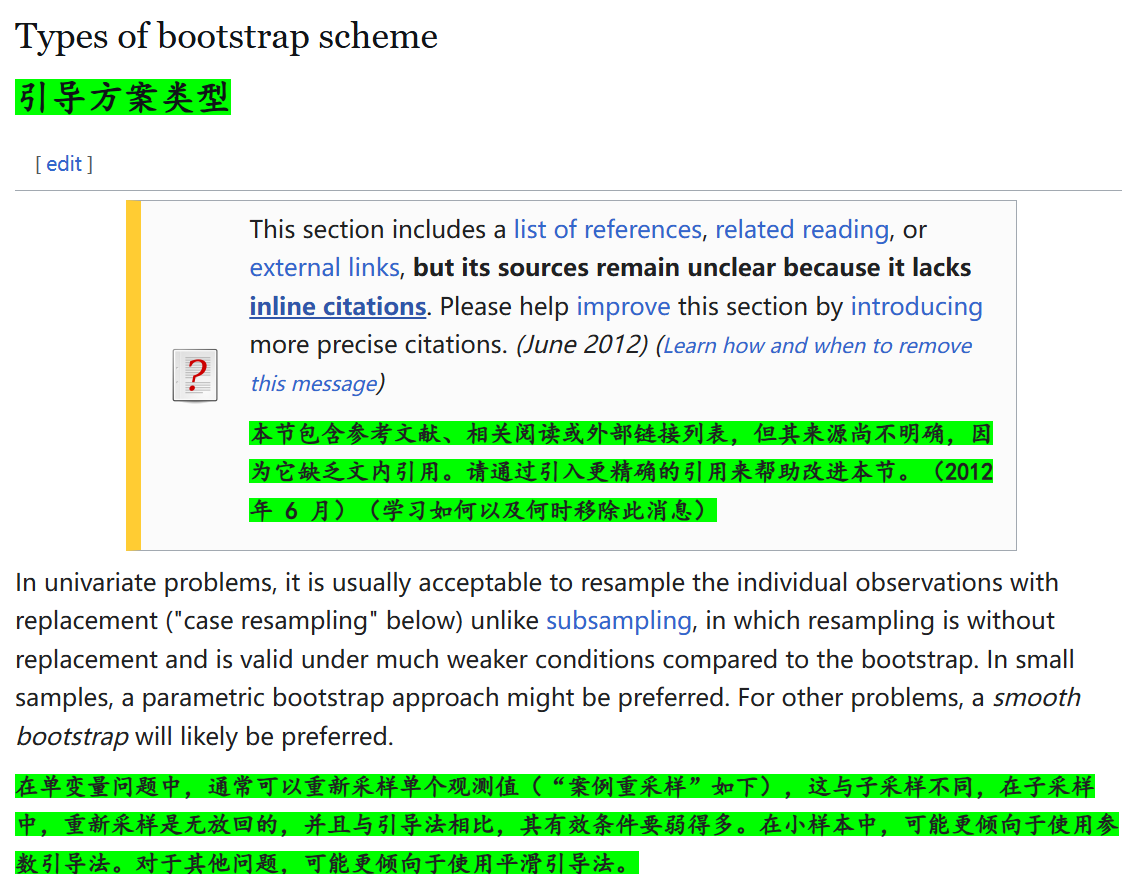

我们可以从排列组合(中学)的隔板法问题中推导出来理论上精确的重采样有多少种组合:




注意这里之所以用2n-1个位置,是因为我们允许某个样本(比如说第i个样本)不被采样到,这是有放回采样的定义自然而然推导获得的是;

参考:https://blog.csdn.net/mingyuli/article/details/81223463

二,实践举例
1,估计样本均值的分布:


2,回归

具体例子:使用重采样估计回归模型的稳健性
假设我们有一个简单的线性回归问题,研究广告投入(解释变量 X)与产品销售额(响应变量 Y)之间的关系。数据集包含100个观测值,每行代表一个时间段的广告投入和对应的销售额。
数据集示例
| 广告投入 X | 销售额 Y |
|---|---|
| 10 | 150 |
| 20 | 200 |
| 30 | 250 |
| … | … |
| 100 | 500 |
使用案例重采样的过程



3,贝叶斯自助法:

4,平滑自举:

5,参数自助法:

6,重采样残差:

7,高斯过程回归自助法:
涉及到随机过程等相关概念




8,野自助法/随机扰动自助法:
处理异方差性(heteroscedasticity)问题,即数据中不同观测值的方差不相等的情况;

9,块自助法**Block bootstrap**




三,拓展
1,统计量的选择

2,自助置信区间——》从自助分布中推导置信区间

我们先讨论理想的构造自助置信区间的方法,或者说应该满足的性质:


偏差、不对称性和置信区间:

场景设定
假设我们有一个班级,班级里学生的数学考试成绩是我们感兴趣的总体。我们想估计这个班级的平均成绩,但只有一部分学生的成绩样本。
1. 偏差(Bias)
假设我们从班级中随机抽取了10个学生的成绩作为样本,样本平均成绩是75分。但实际上,班级的总体平均成绩是80分。这种情况下,样本平均数(75分)和总体平均数(80分)之间的差异(-5分)就是偏差。
用数学公式表示:
[ \text{Bias} = \text{样本估计值} - \text{总体真实值} ]
[ \text{Bias} = 75 - 80 = -5 ]
偏差的来源:
- 样本可能不具有代表性。比如,我们可能不小心抽到了一些成绩较低的学生。
- 样本量太小,导致估计不够准确。
2. 不对称性(Asymmetry)
假设我们用自助法(Bootstrap)来估计班级平均成绩。我们从样本中重复抽样(有放回)1000次,每次抽10个成绩,计算每次抽样的平均值,得到一个自助法分布。
如果这个分布是对称的,比如:
- 一半的自助样本平均值在70分到75分之间,
- 另一半在75分到80分之间,
那么这个分布是对称的。
但如果分布不对称,比如:
- 大多数自助样本平均值集中在70分到75分之间,
- 只有少数在75分到80分之间,
那么这个分布就是不对称的。
不对称性的直观理解:
- 想象一个钟形曲线,如果它左右两边是对称的,那么它就是对称分布;如果它偏向一侧,比如右边更高,左边更低,那么它就是不对称的。
3. 置信区间(Confidence Intervals)
假设我们想估计班级平均成绩的95%置信区间。置信区间是一个范围,我们有95%的信心认为总体平均成绩在这个范围内。
情况1:对称分布
如果自助法分布是对称的,我们可以用百分位数法来计算置信区间。比如,我们取自助样本平均值的第2.5百分位数和第97.5百分位数作为置信区间的上下限。
假设自助样本平均值的分布如下:
- 第2.5百分位数是72分,
- 第97.5百分位数是78分,
那么95%置信区间就是[72, 78]。
情况2:不对称分布
如果自助法分布是不对称的,百分位数法可能不适用。因为百分位数法假设分布是对称的,而不对称分布会导致置信区间估计不准确。
比如,假设自助样本平均值的分布如下:
- 大多数集中在70分到75分之间,
- 只有少数在75分到80分之间,
如果还用百分位数法,可能会得到一个偏向较低值的置信区间,比如[71, 76],但实际上总体平均成绩可能更高。
通俗易懂的总结
- 偏差:样本估计值和总体真实值之间的差异。比如我们用样本平均成绩估计总体平均成绩,但估计值和真实值不一样。
- 不对称性:自助法分布的形状。如果分布左右不对称,说明数据更倾向于一边,这种情况下用百分位数法计算置信区间可能会出问题。
- 置信区间:一个范围,我们有较高信心(如95%)认为总体参数在这个范围内。如果分布对称,可以用百分位数法;如果不对称,可能需要其他方法。
我们一般遇到的都是正态分布或者是t分布等对称分布,如果我们使用自助法抽样获取的某个统计量也符合对称的分布,那么我们其实确实是可以使用百分位数来表征置信区间,注意,此处只是表征。
我想一个很容易被搞混的点,就是很多人容易搞混置信区间的置信指标α,或者说置信水平1-α,
与该置信区间的覆盖度,以及所谓假设检验中经常提及的上下α分位点的概念等。
为什么要考虑分布是否对称呢,F检验的时候用的也是F分布的上下5%分位数区间?(看,这里我们很容易搞混这个概念)。也不对,F分布使用的是上下分位点,分位点实际使用的是概率的覆盖所定义的,并不是分位数所定义的,确实是这样的。
从定义上讲,置信区间所覆盖的范围本质上就是从概率定义的,所以我们很容易将概率频率,再降级为相应的分位数。
我们说上α分位点,或者说下α分位点,但是我们不常说上α分位数或者是下α分位数。
1. 为什么分布的对称性很重要?
在统计推断中,对称性是一个重要的假设,因为它影响置信区间的构建和解释。具体来说:
- 对称分布的优势:
- 如果一个分布是对称的(例如正态分布),那么分布的中位数和均值是相同的,且分布的上下尾部是对称的。这意味着我们可以使用简单的百分位数方法来构建置信区间。例如,对于一个对称分布,95%的置信区间可以通过取分布的2.5%和97.5%百分位数来定义。
- 对称分布使得估计量的偏差(Bias)更容易被识别和校正,因为偏差通常表现为分布中心的偏移。
- 非对称分布的问题:
- 如果分布是非对称的(例如卡方分布或某些自助法分布),使用百分位数方法构建置信区间可能会导致区间估计不准确。因为非对称分布的尾部不对称,简单地取百分位数可能导致区间覆盖概率不正确。
- 非对称分布的置信区间需要更复杂的调整方法,例如使用偏差校正的自助法(Bias-Corrected and Accelerated, BCA)置信区间。
2. F检验中的分位数和分位点
- F检验的背景:
- F检验用于比较两个方差是否相等,或者在方差分析(ANOVA)中检验多个组的均值是否相等。
- F检验的统计量遵循F分布,F分布是非对称的,其形状取决于分子和分母的自由度。
- F分布的分位点:
- 在F检验中,我们通常使用F分布的上下分位点来构建置信区间或临界值。例如,对于一个95%的置信区间,我们会找到F分布的0.025分位点和0.975分位点。
- 这些分位点是通过F分布的概率密度函数(PDF)或累积分布函数(CDF)计算得到的,而不是简单地取分布的百分位数。
- 分位数与分位点的区别:
- 分位数:是指将数据分成具有相等概率的连续区间的点。例如,中位数是50%分位数,它将数据分成两部分,每部分的概率为50%。
- 分位点:是指分布函数的反函数在特定概率值处的取值。例如,F分布的0.025分位点是指F分布的累积分布函数等于0.025时对应的值。
3. 为什么F检验中使用分位点而不是分位数?
- F分布的非对称性:
- F分布是非对称的,因此不能简单地使用百分位数方法来定义置信区间。例如,F分布的0.025分位点和0.975分位点并不对称地分布在分布的中位数周围。
- 使用分位点可以确保置信区间的覆盖概率是正确的,即使分布是非对称的。
- 概率覆盖的定义:
- 在F检验中,我们关心的是置信区间的覆盖概率,即区间包含真实参数的概率。分位点是通过分布的概率密度函数或累积分布函数计算得到的,能够更准确地反映这种概率覆盖。
- 而简单地使用百分位数可能会忽略分布的非对称性,导致区间估计不准确。
总结
- 对称性的重要性:对称分布使得置信区间的构建更简单,因为可以使用百分位数方法。非对称分布则需要更复杂的调整方法。
- F检验中的分位点:F分布是非对称的,因此使用分位点而不是分位数来定义置信区间,以确保覆盖概率的准确性。
3,自助置信区间的构建方法


百分位数法构造置信区间:这个方法实际上是很常用的,首先从代码实践上操作很简单,因为python的numpy或者是R的tidyverse中对于数组/array计算分位数的API很容易调用(也就是调包,自己写函数很简单)。
所以我们说写简单的包或者是函数,调包调库def不是很难,难的是数学严谨性,也就是应用的条件。

当然了,此处还是需要注意前面已经提到的问题,就是当自助分布是对称的,并且以观察到的统计量为中心的时候,这种自助法估计真实总体参数的置信区间(用重采样的分位数去估计推导)才是比较合适的。
1. 估计分位数参数时,自助抽样得到的中位数分布是否对称?
简短回答:
通常情况下,自助法得到的中位数分布并不一定是严格对称的,但是如果原始数据“不是严重偏斜”,当样本量不是特别小的时候,自助分布往往“近似对称且集中在观测中位数附近”。但如果原始数据特别偏斜(比如90%的点都挤在一边),则自助中位数分布也会偏斜,不能保证一定对称。
详细解释与举例:
举例1(数据分布接近对称):
- 假设你的原始数据是
[2, 3, 4, 5, 6],中位数是4。 - 用自助法重复抽样后,每一组都算中位数,得到一大堆“自助中位数”。
- 你会发现这些自助中位数大部分也集中在4的附近,分布近似对称——这时候用百分位法效果好。
举例2(数据强偏斜):
- 如果原始数据是
[1, 1, 1, 1, 10],中位数是1。 - 自助重抽时,大部分样本的中位数仍然是1,只在极少数时候抽到比较多10时,中位数才变成10。这时自助分布极度偏斜(大多数1,个别出现10),就很不对称。
- 如果你直接用bootstrap分布的2.5%和97.5%分位数,得到的置信区间将“严重低估”或者“不能如实反映实际分布的不确定性”。
结论:
自助中位数分布是否对称,取决于原始数据分布。如果样本偏态、不均匀,bootstrap分布也往往偏斜。这时百分位法的置信区间未必可靠,建议使用偏差校正类的改进方法(比如BCa),特别是样本量不大或分位数落在分布的“偏斜端”时。
2. 分位数和概率可以对应吗?分位数区间为何不等于概率置信区间?
这是bootstrap置信区间常见误解。
分位数和概率的基本关系:
- 分位数的定义:第p百分位数就是分布中有p比例数据点小于等于它。比如0.975分位数=97.5%的bootstrap统计量小于它。
- 概率置信区间:在bootstrap自助法里,用p和1-p分位数围出来的区间,在bootstrap分布下,覆盖被估计的统计量的概率大约是(1-2p)。
疑惑来源与本质:
- 理论上,如果自助分布与真实抽样分布等价、对称并以观测统计量为中心,那么用分位数构造置信区间,和直觉上的概率置信区间基本一致。(比如bootstrap均值是对称、集中的)
- 但如果分布偏斜,观测统计量未必正好落在中心,那么用bootstrap分位数构造的区间,实际置信水平和你期望的不完全一致。也就是,置信区间中包含真实参数的概率不再等于你用的百分比。
举个极端例子:
- 你的自助分布大多数“挤在一侧”,那你得到的“95%区间”可能有95%的自助统计量落在区间内,但这个区间对应原参数的实际置信概率可能远低于95%。
为什么会这样?
- 分位数只是把自助统计量本身排序后的排名,不等同于对真实未知参数的概率分布排序。
- 只有分布对称、以观测统计量为中心时,这两者才近似等价。
- 一旦分布偏斜,区间边界和实际参数脱钩;也可能区间包含观测统计量的概率达不到设定的95%等。
总结与建议
- Bootstrap中位数分布是否对称,视原始样本分布和样本量而定,并不保证天然对称,实际常常偏斜,需具体检验。
- 分位数与置信区间的概率只有在分布对称、以观测统计量为中心时才近似等价;一旦偏斜就不准。
- 如果估计分位数参数,且分布明显偏斜,建议使用:
- 偏差校正加加速法(BCa, bias-corrected accelerated)
- 或者用“基本自助法”(basic bootstrap),校准中心和分布形状
一句话总结:
百分位数法的核心假设是bootstrap分布“对称+居中”,否则分位数和真实置信概率不等价,区间易失真。


注:以上结论仅供参考,实际分析时,需要绘制bootstrap自助参数的分布形状


如果是数学一点的表述:

4,与其他重采样方法的关系:我们重点理解其和交叉验证CV的关系

在统计学习也就是机器学习中,经常和bootstrap一起提到的就是cross validation即CV交叉验证(一般是数据集划分+模型验证部分会涉及到)。


上面说的是只是一次抽样中可能产生的偏差,如果一次抽样,抽样样本无限大(也就是N或者是d无限大),我们实际上通过抽样划分出来的数据是有偏差的:也就是说如果我们只是有放回的重采样1次+采样样本量很大,相当于我们只是划分了63.2%的训练集,然后再用这63.2%的数据之外的作为验证集去验证模型,其实就相当于是63.2:36.8的数据集划分了(近似于6:4),
然后我们再不断重复这个重采样也就是划分过程,不断地进行64划分CV。
和CV不同的是,我们每次64划分中的6和4是不定的,也就是变动的
1. 自助法(Bootstrap)的基本原理
自助法是一种基于有放回抽样的统计方法,主要用于估计模型的性能或评估模型的稳健性。它的核心思想是从原始数据集中有放回地抽取样本,生成新的数据集(称为“自助样本集”),并基于这些自助样本集进行分析。
2. .632自助法的具体过程
在.632自助法中,具体步骤如下:
- 生成训练集:从原始数据集(包含d个样本)中,有放回地随机抽取d次,生成一个新的训练集。由于是有放回抽样,某些样本可能会被重复抽取,而有些样本可能一次也没有被抽到。
- 生成验证集:那些在训练集中没有被抽到的样本,自然就形成了验证集(也称为测试集)。根据前面的数学推导,当样本数量足够大时,大约有36.8%的样本会进入验证集,而63.2%的样本会进入训练集。
- 模型训练与验证:使用生成的训练集训练模型,然后在验证集上评估模型的性能。
3. 与交叉验证的区别
- 交叉验证:
- 原理:将原始数据集划分为若干个互不重叠的子集,每次用其中一部分作为验证集,其余部分作为训练集,重复多次,最后取平均性能。
- 优点:充分利用了所有数据,每个样本都有机会被用作验证集。
- 缺点:计算成本较高,尤其是当数据集较大或模型训练时间较长时。
- .632自助法:
- 原理:通过有放回抽样生成训练集和验证集,每次抽样得到的训练集和验证集是随机的。
- 优点:计算成本相对较低,因为每次只需要生成一个训练集和一个验证集,适合大规模数据集。
- 缺点:验证集的样本数量较少(约占36.8%),可能导致验证结果的方差较大。
4. 应用场景
.632自助法常用于以下场景:
- 模型评估:当数据集较大且计算资源有限时,.632自助法可以快速评估模型的性能。
- 模型选择:通过多次自助抽样,比较不同模型的性能,选择最优模型。
- 特征选择:评估特征对模型性能的影响,选择重要特征。
5. 总结
.632自助法是一种利用自助法划分训练集和验证集的方法,它通过有放回抽样生成训练集和验证集,并利用数学推导保证了验证集的样本比例约为36.8%。它与交叉验证不同,更注重计算效率,适合大规模数据集的快速模型评估。
总的来说,两者的异同在于:
交叉验证法
采用无放回的随机采样方式,从数据集D中抽出部分数据作为训练集T,另外一部分作为测试集T’,并重复若干次随即划分过程,以每次划分对应的测试评估的均值作为评估结果(交叉便体现在重复若干次随机划分过程中两个数据集间数据的交叉)。
自助法
采用有放回的随机抽样方法,在保持训练集T与数据集D规模一致的条件下,从数据集D中抽出有重复的数据作为训练集T,剩下没有被抽中的数据作为测试集T’。
相同点:
交叉验证法和自助法都是随机采样法。它们作为人工智能中评估模型的方法,根据一定规则从数据集D中划分训练集和测试(验证)集,从而评价模型在数据集上的表现,便于我们选择合适的模型。
不同点:
正如上面所述,这两种方法最大的不同点在于每次划分过程中每个样本点是否只有一次被划入训练集或测试集的机会。下面将针对这方面详细展开论述:
交叉验证法采用的是无放回的随机采样方式,这种方式可以保持数据分布的一致性条件,并严格划分训练集与测试集的界限,从而增强测试评估的稳定性和可靠性。
自助法主要面向数据集同规模的划分问题。其采用的是有放回的随机抽样方法,可以使得得到的模型更为稳健,解决了交叉验证法中模型选择阶段和最终模型训练阶段的训练集规模差异问题;但训练集T和原始数据集D中数据的分布未必相一致,因此对一些对数据分布敏感的模型选择并不适用。
四,code实现
此处以python实现为主,我们考虑
首先按步骤分解我们的问题:
(1)从原始样本中有放回的抽取一定数量的样本:
因为是随机抽样+有放回,使用numpy中的np.random.choice函数
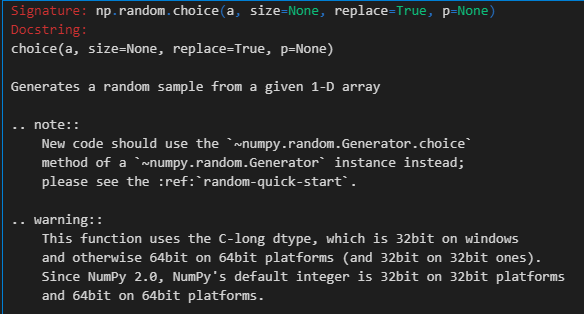
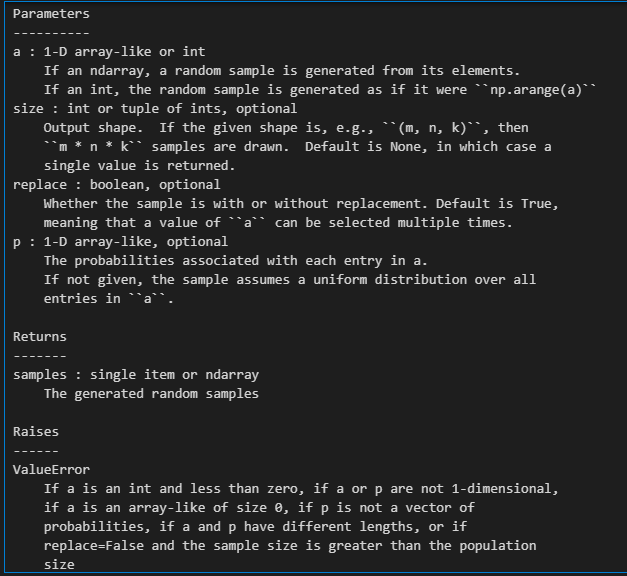
我们只需要关注其中的参数size(一般为原始样本的尺寸size)、replace(True,即有放回抽样);
注意上面只是1次抽样,返回的也是一个ndarray对象;
我们可以通过for循环进行多次抽样:
for iter in range(num_of_bootstrap):
(2)根据抽出的样本计算给定的统计量:
即自助统计量,比如说我们此处以中位数为例,numpy中可以调用median
(3)重复上述抽样操作N次,得到N个统计量,见(1)
(4)构造置信区间,使用百分位数法:
在python中计算一个多维数组的任意百分比分位数,此处的百分位是从小到大排列,只需用np.percentile即可(至于百分位数的问题,还是参考前面的说法)
下面是我的一个草稿代码:
def bootstrap_X(n_bootstrap,sample:list[float],real_param_to_test,alpha=0.05):"""Args:n_bootstrap: 自助法抽样的次数sample: 需要进行自助法抽样的样本数据,此处设置为list浮点数列表类型real_param_to_test: 需要进行置信区间估计(显著性判断)的真实数据,比如说某个待检测样本的均值、方差、中位数、相关系数等alpha: 置信水平,默认值为0.05Fun:1,进行自助法抽样,返回一个包含n_bootstrap次抽样结果的列表;每次抽样计算一个统计量,此处命名为X,可以是均值、方差、中位数、相关系数等,比如说bootstrap_of_median函数,此处统一使用“X”指代2,利用百分位数法构造该参数X(比如说上面X指代median中位数)的置信区间;比如说置信水平为α,则使用(1-α/2)的百分位数和α/2的百分位数来构造置信区间,即α*100/2%和(1-α/2)*100%分位数;3,返回置信区间的下限和上限;4,顺便我们可以判断一下某个真实样本的参数数据(真实数据)是否在置信区间内,即是否显著,即real_param_to_test是否在置信区间内;"""import numpy as npfrom scipy import stats# 注意下面都是以X代称需要估计的统计量bootstrap_X = [] # 存储自助法抽样获取的多次抽样结果,比如说是bootstrap_medianfor i in range(n_bootstrap):bootstrap_sample = np.random.choice(sample,size=len(sample),replace=True)bootstrap_X.append(np.X(bootstrap_sample)) # np.X指代任何python实现中能够计算指标X的api函数,比如说均值用np.mean,中位数用np.median等ci_lower = np.percentile(bootstrap_X, alpha * 100 / 2) # 置信区间下限ci_upper = np.percentile(bootstrap_X, (1 - alpha / 2) * 100) # 置信区间上限# 下面是判断真实数据是否在置信区间内,即是否显著 is_significant = not (ci_lower <= real_param_to_test <= ci_upper)# 或者我们也可以使用# result = False if ci_lower <= observation_param <= ci_upper else Truereturn ci_lower, ci_upper, is_significant# 也可以return result如果是在一个真实的机器学习例子中:
假设我们有样本数据X和标签y,以scikit-learn的分类器为例:
import numpy as np
from sklearn.base import clone
from sklearn.metrics import accuracy_scoredef bootstrap_632(X, y, model, metric=accuracy_score, n_iterations=100):'''.632自助法评估模型性能参数:X, y : 原始样本和标签, X为(n_samples, n_features)的ndarray,y为(n_samples,)的ndarraymodel : 已实现fit/predict接口的sklearn模型metric : 性能度量函数,如accuracy_score等n_iterations : 自助法抽样次数返回:.632自助法估计的得分'''n_samples = X.shape[0]scores_in = [] # 训练集分数scores_out = [] # 留出(测试集)分数for _ in range(n_iterations):# 有放回随机采样训练集索引train_idx = np.random.choice(n_samples, size=n_samples, replace=True)# 检验集为未被选中的样本test_idx = np.setdiff1d(np.arange(n_samples), train_idx)model_ = clone(model)model_.fit(X[train_idx], y[train_idx])# 训练集得分score_in = metric(y[train_idx], model_.predict(X[train_idx]))scores_in.append(score_in)# 检验集得分if len(test_idx) > 0:score_out = metric(y[test_idx], model_.predict(X[test_idx]))else:# 若某次抽样所有样本都被抽中,则检验集为空,跳过score_out = np.nanscores_out.append(score_out)# 取所有非nan的测试集分数平均scores_out = np.array(scores_out)mean_score_in = np.nanmean(scores_in)mean_score_out = np.nanmean(scores_out)# .632法则组合训练集与检验集得分final_score = 0.368 * mean_score_in + 0.632 * mean_score_outreturn final_score# 使用示例
if __name__ == "__main__":from sklearn.datasets import load_irisfrom sklearn.tree import DecisionTreeClassifierX, y = load_iris(return_X_y=True)model = DecisionTreeClassifier(random_state=42)score = bootstrap_632(X, y, model, metric=accuracy_score, n_iterations=300)print(".632自助法评估得分:", score)训练集样本有重复,检验集为未被采样的样本。
每次实验如检验集为空,则该次得分记为NaN,整体均值时跳过。
.632法则最终得分为:
final_score = 0.368 × 训练集得分均值 + 0.632 × 检验集得分均值
metrics可更换为需要的其它评估指标。
参考:
https://en.wikipedia.org/wiki/Bootstrapping_(statistics)
http://taggedwiki.zubiaga.org/new_content/5c318780fb5bb20ff852e11a72b52b5f
https://www.math.pku.edu.cn/teachers/lidf/docs/statcomp/html/_statcompbook/sim-bootstrap.html