《微机原理与接口技术》第 5 章 汇编语言程序设计
汇编语言:计算机系统底层机器语言的符号表示形式
特点:
① 用助记符代替二进制的指令代码。
② 用标号 or 符号代表地址、常量或变量,克服了机器语言不容易记忆,不方便使用的缺点。
汇编语言能够利用CPU的指令系统及相应的寻址方式,编写出占用内存少,运行速度快的程序,还能直接利用计算机硬件提供的寄存器、标志和中断,对寄存器、内存及I/О端口进行各种操作,是直接操作硬件的、效率最高的语言。
本章介绍汇编语言程序设计步骤、基本语法、伪指令语句、宏指令、系统功能调用等,并通过程序实例介绍分支、循环、子程序等常用的汇编语言结构,最后介绍汇编语言程序的上机步骤和调试程序DEBUG的使用方法。
5.1 汇编语言程序基本格式
5.1.1 汇编语言源程序和汇编程序
通过2.1.1节大家知道,用汇编语言编写的汇编语言源程序,计算机无法直接识别和执行,需要通过汇编程序翻译成目标程序(.OBJ)。
汇编后形成的目标程序(.obj)虽然是二进制代码,但还不能直接上机运行,必须经过链接程序链接,将库文件或其他目标文件链接到一起形成可执行文件(.exe)后,才能送入计算机执行。汇编语言程序从建立到汇编、连接形成可执行程序的整个过程如图5.1所示。
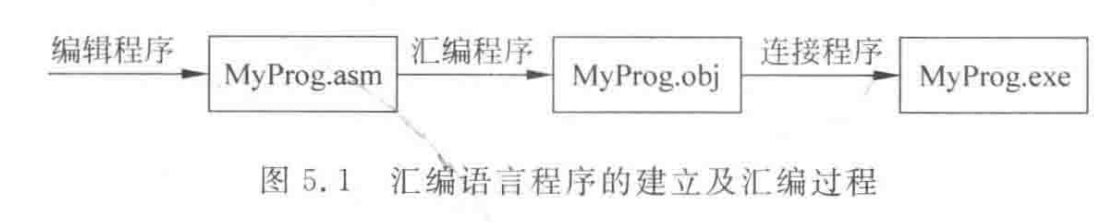
汇编程序:是较早、较成熟的一种系统软件,它的主要功能是将汇编语言源程序转换为目标程序,同时还具有以下的一些功能:检查源程序中的语法错误,并给出出错信息;进行数制转换、计算表达式;分配内存空间;展开宏指令等。目前使用的汇编程序主要是宏汇编程序(Micro Assembler,MASM)。
5.1.2 汇编语言的特点
汇编语言远不如高级语言方便、实用,而且编写同样的程序,使用汇编语言比使用高级语言花费的时间更多,调试和维护更困难。既然如此,为什么还要使用汇编语言呢?主要有两个原因:性能和对计算机的完全控制。使用汇编语言编写的程序有如下特点。
(1)执行速度快。
(2)程序短小。
(3)可以直接控制硬件。
(4)可以方便编译。
(5)辅助计算机工作者掌握计算机体系结构。
5.1.3 一般汇编语言程序的结构形式
与内存分段结构相对应,汇编语言源程序采用分段结构,一般一个完整的源程序由3个程序段组成:代码段、数据段、堆栈段。
每一个段都以SEGMENT开始,以ENDS结束,二者之间为语句体,整个源程序以END结束。
汇编语言程序的一般结构形式为:

每一段的语句体由语句序列组成。
8086汇编语言语句分为如下3类:
(1)指令语句:8086指令系统的指令形式,与机器指令一一对应。
(2)伪指令语句:又称管理语句。在汇编语言源程序的汇编过程中起主要作用,它是对汇编程序的命令语句,一般没有相应的目标代码。
(3)宏指令语句:是宏汇编程序能识别的、预先定义的指令代码序列。一旦定义以后,宏指令就像一条指令一样,可以在源程序中被引用,其效果等同于引入一段代码序列。
每个语句最多由4个域组成,一般格式如下:
指令语句:
[标号:] 操作符 操作数 [;注释]伪指令语句:
[名字] 伪指令符 参数 [;注释]其中,标号(或名字)和注释是可选的,操作数或参数的有无及个数根据具体的指令或伪指令而异。

5.2 汇编语言中的数据
5.2.1 常量
常量(Constant):是指在程序运行过程中不变的量,8086汇编语言允许的常量如下。
(1)数值常量
汇编语言中的数值常量可以是二进制B、八进制O、十进制D、十六进制数H。
① 二进制数:由0和1组成的数字序列,以字母B结尾,示例:00101100B。
② 八进制数:由数字0~7组成的数字序列,以字母О或Q结尾,示例:1777O、1777Q。
③ 十进制数:由0~9组成的数字序列,以字母D结尾,示例:178D。
一般情况下,基数默认为十进制数,因此可以省略后缀D。
④ 十六进制数:由0~9 及A~F组成的数字序列,以字母H结尾。这个数的第一个字符必须是0~9。如果第一个字符是A~F,则应在其前面加上数字0,以避免和标示符混淆,示例:0FFFFH。
(2)字符串常量
包含在单引号中的若干个字符形成字符串常量,字符串在计算机中存储的是相应字符的ASCII码。
示例:'A'的值是41H,'AB'的值是4142H。
(3)符号常量
常量用符号名来代替就是符号常量。
示例:
COUNT EQU 3
COUNT=3定义了一个符号常量COUNT,与数值常量3等价。
5.2.2 变量
变量(Variable):是存放在内存中某个存储区域中的数据,这些数据在程序运行期间随时可以修改。
变量名:为了便于对变量的访问,它常常以变量名的形式出现在程序中。变量名是内存中一个数据区域的名称,即数据内存地址的符号表示,可以在数据段、附加数据段或堆栈段中定义。
(1)变量的定义
定义变量:就是给变量分配存储单元,并且给这个单元赋予一个变量名。
定义变量是使用数据定义伪指令来实现的,其格式为:
[变量名] 伪指令 表达式 [表达式 …】说明:
(1)这些伪指令可以把其后的数据存入指定的存储单元,并初始化数据,或者只分配存储空间而并不初始化数据。
其中,变量名字段是可有可无的,它是内存单元地址的符号表示,其作用与指令语句前的标号相同,但它的后面没有冒号。程序汇编时,将第一字节的偏移地址赋给变量名。
伪指令字段:说明所定义的数据类型,常用的数据定义伪指令有以下几种。
① DB伪指令:用来定义字节,其后的每个操作数都占有一字节(8位)。
(Define Byte)
② DW伪指令:用来定义字,其后的每个操作数占有一字(16位,其低位字节在第一个字节地址中,高位字节在第二个字节地址中——低位低地址,高位高地址)。
③ DD伪指令:用来定义双字,其后的每个操作数占有两字(32位)。
④ DF伪指令:用来定义6字节的字,其后的每个操作数占有48位,可存储由16位段地址及32位偏移地址组成的远地址指针。这一伪指令只能用于80386 及其后继机型中。
⑤ DQ伪指令:用来定义4字,其后的每个操作数占有4字(64位),可用来存放双精度浮点数。
⑥ DT伪指令:用来定义10字节,其后的每个操作数占有10字节,形成压缩的BCD码。
(2)表达式字段:是给变量预置的初值,可以是下述情况之一。
① 数值表达式:数值允许用二进制、八进制、十进制、十六进制形式书写。
② ?:表示不预置确定的初值。
③ 字符串表达式:用引号括起来的不超过255个字符或其他ASCII码符号。DB伪指令将按顺序为字符串中每一个字符或符号分配一字节单元,存放它们的ASCII编码,但除DB以外的数据定义伪指令只允许定义最多两个字符的字符串,且按逆序存放在低地址开始的单元。
④ 带DUP操作符的表达式:DUP是定义重复数据操作符,它的使用格式为:
N DUP (EXP)其中,N为重复次数,EXP为表达式。
示例:
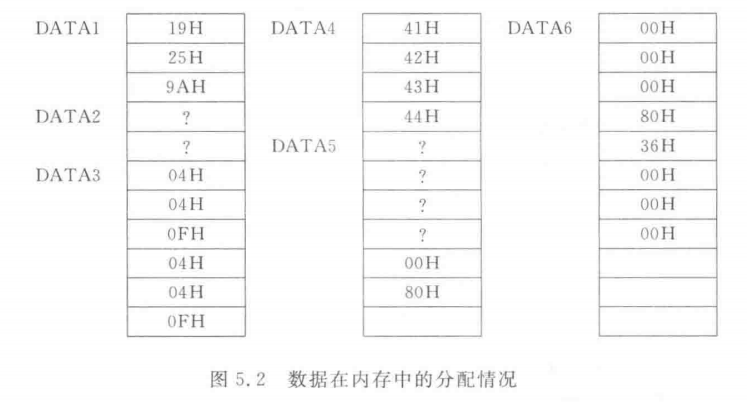
DATA1 DB 25,25H,10011010B ;数值表达式,25为19H
DATA2 DB ?,? ;?表达式
DATA3 DB 2 DUP(2 DUP(4),15) ;DUP表达式DATA4 DB 'AB','CD' ;字符串表达式
DATA5 DW ?,?,-32768 ;字类型DATA6 DD 80000000H,36H ;双字类型上述语句汇编后的内存分配情况如图5.2所示。
(2)变量的属性
经过定义的变量有3种属性:段属性、偏移属性、类型属性。
① 段属性(SEGMENT):变量所在段的起始地址(16位),此值必须在一个段寄存器中。
② 偏移属性(OFFSET):该变量与段的起始地址之间相距的字节数。对于16位段,是16位无符号数;对于32位段,则是32位无符号数。在当前段内给出变量的偏移值等于当前地址计数器的值,当前地址计数器的值可以用$来表示。
③ 类型属性(TYPE):定义该变量的字节数,如BYTE(DB,1字节长)、WORD(DW,2字节长)、DWORD(DD,4字节长)、FWORD(DF,6字节长)、QWORD(DQ,8字节长)、TBYTE(DT,10字节长)。
可以通过取值运算符SEG、OFFSET和TPYE取得变量的属性,详见5.3节。
(3)变量的使用
① 变量名作为存储单元的直接地址:变量名用直接寻址时,变量的类型必须与指令的要求相符合。
示例:假设已定义字节变量AB,字变量AW,用变量名直接寻址形式为:
MOV AH, [AB] AH存储AB地址空间的内容
MOV AX, [AW]注:
MOV AH, AB AH存储立即数AB② 用合成运算符PTR可以临时改变变量类型。
示例:假设已定义字节变量AB,字变量AW,在如下指令序列中:
MOV CX,WORD PTR AB ;当作字指针,读取AB及AB+1两个字节的内容
MOV CL,BYTE PTR AW ;当作字节指针,仅读取AW开始一个字节的内容临时把AB变为字类型,AW变为字节类型,但段和偏移属性不变。
③ 变量名作为相对寻址中的偏移量。
示例:假设已定义字节变量AB,字变量AW,在如下指令序列中:
MOV AX, AB[SI] ;AX存储AB地址开始偏移SI处两个字节的内容
MOV AX, AW[BX][SI] ;AX存储AW地址开始偏移BI+SI处两个字节的内容AB、AW分别表示它们的偏移量而不是它们所表示的数据,常用于数组或表格操作,AB[SI]就表示AB数组中第SI个元素。
④ 变量名仅对应数据区第一个数据项。
示例:
WORD DW 20 DUP(?)
MOV AX, WORD ;第一个元素送AX
MOV AX,WORD+38 ;第20个元素送AX
5.2.3 标号
标号(Label):是某条指令所在内存单元地址的符号表示,经常在转移指令或子程序调用指令的地址码字段出现,用于表示转向的目标地址。
示例:
LOP1: 指令……LOOP LOP1……JNE NEXT
NEXT: 指令……标号在代码段中定义,后面跟着冒号,它也可以用LABEL或EQU伪操作来定义。此外,它还可以作为过程名来定义。
对于汇编程序来说,标号与变量是类似的,都是存储单元地址的符号表示。
只是标号对应的存储单元中存放的是指令;而变量所对应的存储单元中存放的是数据。
所以,标号也有3种属性:段属性、偏移属性和类型属性。
① 段属性:定义标号的程序段的起始地址,标号的段地址总是在CS寄存器中。(代码段)
② 偏移属性:标号与所在段的段起始地址之间的字节数。对于16位段,是16位无符号数;对于32位段,则是32位无符号数。(8086是16位段)
③ 类型属性:用来指出该标号是在本段内引用的,还是在其他段中引用的。
如果是在本段内引用的,则称为NEAR。对于16位段,指针长度为2 Byte;对于32位段,指针长度为4 Byte。
若在段外引用,则称为FAR。对于16位段,指针长度为4B(段地址2B、偏移地址2B);对于32位段,指针长度为6B(段地址2B,偏移地址4B)。
在同一个程序中,同样的标号或变量的定义只允许出现一次,否则汇编程序会指示出错。
5.3 运算符与表达式
运算符:8086汇编语言定义了多种类型的运算符。
表达式:运算符与操作数组成表达式,表达式经汇编后形成新的操作数。
表达式分为数值表达式和地址表达式。数值表达式的运算结果是一个数;地址表达式的运算结果是一个存储单元的地址。
(1)算术运算符
+(加)、-(减)、*(乘)、/(除)、MOD(取模)
算术运算符可以用于数值表达式和地址表达式中,用于地址表达式中要注意地址表达式的物理意义。
例如:
① 同一段中的两个地址相减,其值为两个地址之间字节单元的个数;
② 一个地址加上一个整数,其值为另一个单元的地址;
③ 一个地址减去一个整数,其值为另一个单元的地址。
以上这些运算都是有意义的。而两个地址相加、相乘、相除则是没有意义的。
例如,下面的两条指令分别包含了算术表达式和地址表达式。
MOV AL,4*8+5 ;数值表达式
MOV SI,OFFSET BUF+12 ;地址表达式
(2)逻辑运算符
AND(与)、OR(或)、XOR(异或)、NOT(非)。
逻辑运算符只能用于数值表达式中,不能用于地址表达式中。
逻辑运算符和逻辑运算指令是有区别的。逻辑运算符的功能在汇编阶段完成,而逻辑运算指令的功能在程序执行阶段完成。
在汇编阶段,以下两条指令是等价的。
AND AL,78H AND 0FH
AND AL,08H
(3)关系运算符
EQ(相等)、LT(小于)、LE(小于或等于)、GT(大于)、GE(大于或等于)、NE(不等于)。
关系运算符要有两个运算对象。两个运算对象要么都是数值,要么都是同一个段内的地址。
关系运算的结果为数值,当关系成立时,结果为0FFFFH(全1);当关系不成立时,结果为0000H(全0)。
例如,以下两条指令的结果是等价的。
MOV BX, 32 EQ 45
MOV BX,0以下两条指令的结果也是等价的。
MOV BX,56 GT 30
MOV BX,OFFFFH(4)取值运算符
SEG、OFFSET、TYPE、LENGTH、SIZE。
取值运算符(又称分析运算符)可以从变量和标号中分析出它们的段地址、偏移地址、变量的类型、元素的个数和占用内存的大小等。
① SEG:返回变量和标号的段地址。
② OFFSET:返回变量和标号在段内的地址偏移量。
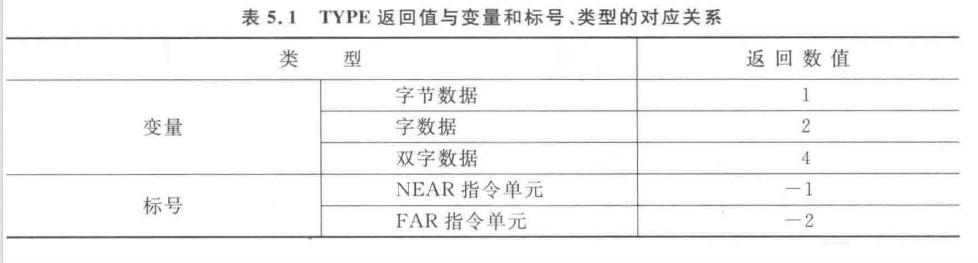
③ TYPE:返回变量和标号的类型,用一个数字表示。返回值与变量和标号、类型的对应关系如表5.1所示。
④ LENGTH:如果一个变量已经用重复操作符DUP说明其变量的个数,则LENGTH运算符可返回该变量所包含的数据个数。
⑤ SIZE:返回变量所占用内存的字节数。它等于LENGTH与 TYPE的乘积。
例如:
SCORE DW 30 DUP(O)定义了一个变量SCORE,则 TYPE SCORE为2,LENGTH SCORE为30,而SIZE SCORE为60。
(5)合成运算符
PTR、THIS。
合成运算符也称为修改属性运算符,它能修改变量或标号原有的类型属性并赋予其新的类型。
① PTR运算符
格式:
类型 PTR 表达式其中,类型可以是 BYTE、WORD、DWORD、NEAR、FAR,表达式是被修改的变量或标号。
例如,NUM被语句
NUM DB 1,3,5,7定义为字节类型,若要将NUM 开始两字节的数据装入AX,则指令:
MOV AX, NUM是非法的,应修改为:
MOV AX,WORD PTR NUM因为在这个指令中 WORD PTR NUM将NUM一次性地修改为字型。若先用赋值语句:
DNUM EQU WORD PTR NUM则上面的传送指令可写为:
MOV AX,DNUM虽然上述的赋值语句重新定义了一个符号名DNUM,但并未给 DNUM分配新的内存,DNUM仍指向NUM所指的单元,它们有相同的内存空间,即二者具有相同的段属性和偏移属性。它们的区别仅在于类型的不同,NUM为字节型,而 DNUM为字型。
② THIS运算符
THIS的功能与PTR相同,只是格式不同。THIS语句中建立一个新的符号名并指定它有THIS后的类型,而新符号名指向下一语句的原符号名的内存地址。
格式:
新符号名 EQU THIS 类型
原符号名 类型 参数,…例如,前面用PTR修改NUM类型可用下面的THIS语句代替:
DNUM EQU THIS WORD
NUM DB 1,3,5,7其中,DNUM是字型并指向NUM所指的内存单元,DNUM 的存取以字为单位,而NUM仍是字节类型。
5.4 伪指令
除汇编指令外,汇编语言程序的语句还可以由伪指令和宏指令组成。
伪指令:是构成汇编语言源程序的一种重要语句。它不像机器指令那样是在程序运行期间执行的,而是在汇编期间由汇编程序处理的操作。
伪指令在汇编期间告诉汇编程序如何为数据项分配内存空间,如何设置逻辑段、段寄存器和各逻辑段的对应关系及源程序到哪里结束等信息,以便指导汇编程序分配内存、汇编源程序、指定段寄存器。在最后形成的目标代码及可执行程序中,伪指令已经不存在。也就是说,伪指令不产生相应的机器代码。
MASM有60多种伪指令,本节介绍一些常用的伪指令。不同版本的汇编程序支持不同的伪指令。
(1)符号定义伪指令
符号定义伪指令用来给一个符号重新命名,或者定义新的类型属性等。
① 赋值伪指令 EQU
(Equate)
EQU伪指令给表达式赋予一个标识符,此后,程序中凡是用到该表达式的地方,就都可以用这个标识符来代替了。这里的表达式可以是常数、符号、数值表达式、地址表达式,甚至可以是指令助记符。
格式:
符号名 EQU 表达式EQU的引入提高了程序的可读性,也使其更加易于修改。
例如:
CONSTANT EQU 256 ;将数256赋给符号名 CONSTANT
DATA EQU HEIGHT+12 ;HEIGHT为标号,将地址表达式赋给符号名DATA
ALPHA EQU 7
BETA EQU ALPHA-2 ;把7-2=5赋给符号名BETA
B EQU [BP+8] ;变址引用赋给符号名B
P8 EQU DS:[BP +8] ;加段前缀的变址引用赋给符号名P8在EQU语句中,如果出现变量或标号,则在该语句前应该先给出它们的定义。例如,若有以下伪指令语句:
BETA EQU ALPHA-2则在该语句之前必须有ALPHA的定义,否则汇编程序将指示出错。
另外,EQU语句在使用PURGE语句解除之前,不允许重新定义。
purge:回收,清理,释放
② 等号伪指令=
与EQU相类似,等号伪指令也可以用作赋值操作——给表达式一个标识符。
它们之间的区别是:EQU伪指令定义的标识符是不允许重复定义的,而等号伪指令则允许重复定义。
例如:
EMP = 6或
EMP EQU 6它们都可以使数6赋以符号名EMP,然而不允许二者同时使用——EMP被EQU赋值后被锁定。
但是,下列语句:
EMP = 7
EMP = EMP+1
在程序中是允许使用的,因为等号伪指令允许重复定义。在这种情况下,在第一个语句后的指令中,EMP的值为7,而在第二个语句后的指令中,EMP的值为8。
③ 类型定义伪指令LABEL
(label:标签)
LABEL伪指令可以指定变量或标号所对应存储单元的类型。其中变量的类型值可以是BYTE、WORD、DWORD、标号的类型值可以是 NEAR和/或AR。
格式:
变量 LABEL 类型
标号 LABEL 类型变量或标号的段属性和偏移属性由下一条语句决定。
例如:
DATW LABEL WORD
DATB DB 20 DUP(O)这个20字节元素的数组被赋予两个不同类型的数组名,即 DATW是 DATB的别名,这两个变量具有同样段属性和偏移属性,只是类型不同,DATW为字类型,DATB为字节类型。换言之,同一数组定义了两种不同的类型,在接受不同数据类型访问时,可以指定相应的标号。例如:
MOV AX,DATW
MOV AL,DATB如接收一个字类型数据访问时,使用DATW,接收一个字节类型数据访问时,使用DATB。否则会因为数据类型不匹配,编译器编译时将出现异常。
下面是LABEL伪指令定义标号的例子:
FLPT LABEL FAR
NLPT: MOV AX, BX“MOV AX,BX”指令有两个标号,即近类型的NLPT和远类型的FLPT,既可以在段内引用这条指令,也可以用标号FLPT实现段间引用。
④ 解除定义伪指令PURGE
使用EQU伪指令定义过的符号,若以后不再使用了,可以使用PURGE语句来解除定义。
格式:
PURGE 符号1,符号2,…,符号N解除符号定义后,可用EQU语句重新定义。例如:
Y1 EQU 7 ;定义Y1的值为7
PURGE Y1 ;解除Y1的定义
Y1 EQU 36 ;重新定义Y1的值为36(2)数据定义伪指令
数据定义伪指令用来定义变量,为变量分配存储单元并赋初值等,这在5.2.2节已经进行了介绍。
(3)段定义伪指令
80x86的内存是分段的,程序必须按段来组织和利用存储器。一个程序允许使用代码段、数据段、堆栈段和附加段4个段,程序的不同部分应放在确定的段中。例如,程序中可执行的代码放在代码段中,程序使用的数据放在数据段中。
段定义伪指令就是为程序的分段而设置的。
① 段定义伪指令 SEGMENT 和 ENDS
格式:
段名 SEGMENT [定位类型][组合类型]['类别']
……
段名 ENDS其中,段名由用户自己定义;
定位类型、组合类型、类别分别确定段名的属性。这三部分不是必需的,可视需要选取。
(Ⅰ)定位类型:定位类型用于指定段的起始地址在内存中所取的位置,它可以是PARA、PAGE、WORD和 BYTE 这4种类型。
PARA(节):是默认类型,表示段起始边界地址的低4位为0,即段的起始地址总是16的倍数。
PAGE(页):表示段起始边界地址的低8位为0,即段的起始地址总是256的倍数。
WORD(字):表示段从一个字边界地址开始,即段地址必须是偶数。当多个目标程序段要连接在同一个物理段时,各源程序的段首说明中选用WORD,以节省内存。
BYTE(字节):表示段可以从任何地址开始。
(Ⅱ)组合类型:组合类型用于告诉链接程序该段与其他段的链接关系。一个程序的源程序可以分为若干部分编写,每个部分中都可能有代码段﹑数据段等。源程序经汇编后还需链接才能成为可执行的程序,链接时需要将分散在不同部分而又有共同特征的段进行组合,如将某些代码段组合在一起构成统一的代码段等,组合类型用于确定源程序中各段的链接关系。
组合类型有NONE、PUBLIC、COMMON、MEMORY、AT、STACK等多种类型。
NONE:表示该段与其他段无任何关系,各自有自己的段基址,是默认的设置;
PUBLIC:表示该段与其他同名、同类别段链接成一个物理段时,所有这些段有一个共同的段基地址。
(Ⅲ)类别:程序在链接时只将同类别的段链接并放在一个连续的存储区构成段组,类别就是给这个段组命名的。类别可以是任何合法的名称,必须用单引号括起来,如'CODE'、'STACK'等。
② 段寄存器指派伪指令ASSUME
段定义伪指令定义了不同的段,但它并没有说明所定义的段中,哪个是代码段、哪个是数据段、哪个是堆栈段等。ASSUME伪指令就是用来指定程序中定义的段分别是什么段对应哪个段寄存器,以便在执行指令时,能够正确地计算物理地址。也就是说,它明确了源程序中的逻辑段和内存中的物理段之间的对应关系。
格式:
ASSUME 段寄存器:段名[,段寄存器:段名,…]其中,段名必须是由SEGMENT定义过的,段寄存器则是CS、DS、SS和ES。由于不同的段可以彼此分离、重叠或完全重叠,因此,不同的段名既可以指派不同的段寄存器,也可指派同一个段寄存器。应当注意,ASSUME伪指令只是定义段名与段寄存器的对应关系并不能将段地址装入段寄存器中。因此,DS、ES和SS 中的段地址还要在程序中通过 MOV 指令装入,代码段CS寄存器的初值由系统自动装入。程序代码为:
MOV AX,DATA
MOV DS,AX(4)过程定义伪指令(PROC和 ENDP)
过程也称为子程序,它是实现程序模块化设计的重要方法。过程作为一个独立存在的模块,能完成特定的任务。过程定义语句可以把程序分成模块,以便编写、阅读、调试和修改和组合。过程定义语句的格式为:
过程名 PROC [NEAR/FAR]
……
过程名 ENDP过程名是过程的标识符,也是过程的入口地址,它具有段属性和偏移属性。
过程名是由用户自己定义的合法的名称。
过程的属性有近调用(NEAR)和远调用(FAR)。若过程和调用过程的程序在同一段内,则属于近调用,该过程具有NEAR属性;若二者不在同一段内,则属于远调用,它具有FAR属性。
在一个过程中至少应有一条RET指令,以使程序能够正常返回。
(5)程序标题伪指令(TITLE)
TITLE伪指令指定一个标题,以便能在列表文件每一页的第一行打印出这个标题,放置在程序的开始处。
格式:
TITLE 文本其中,文本是用户给出的字符串,要求长度不超过6个字符。
(6)地址计数器与对准伪指令
① 取当前地址伪指令$
在汇编程序对源程序的汇编过程中,汇编程序使用一个地址计数器来保存当前正在被汇编的指令或数据的地址。$伪指令就是用来取这个当前汇编地址计数器中的值,它也被称为地址运算符、地址计数器。
当编译完成后,代码中的“$”被一个实际的地址值取代了。
$用在指令中时,它表示当前指令的首地址。当开始汇编或在每一段开始时,$初始化为零,以后在汇编过程中,每处理一条指令,$就增加一个值,这个增量是该指令的字节数。
例如,指令
JNE $+6的转向地址是JNE指令的首地址加上6。
$用在数据段时,它表示当前变量的位置,即地址计数器的当前值。例如:
ARRAY DW 1,2,$+4,3,4,$+4若汇编时ARRAY分配的偏移地址为0074,则汇编后的存储区如图5.3所示。
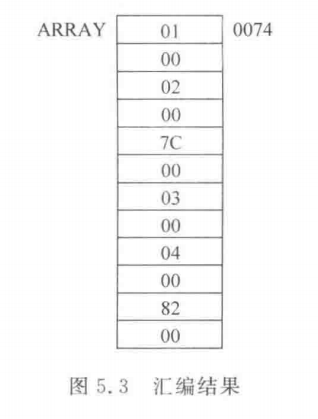
注意,ARRAY 数组中的两个($+4)得到的结果是不同的,这是由于$的值是在不断变化的。
② 移动地址指针伪指令ORG
(Origin)用于指定程序或数据的起始地址
伪指令ORG可以设置当前汇编地址计数器中的值。格式:
ORG 常量表达式其中,常量表达式给出了地址指针相对于当前指针的偏移量。当ORG指定了新的地址指针之后,其后的程序和数据就从此指针指示的起始地址开始存放。
例如,在代码段开始有语句为:
ORG 100H则从此语句起,其后的指令或数据从当前段的100H处开始存放。
ORG也可以指定数据的地址,例如:
VECTORS SEGMENTORG 10
VECT1 DW 47A5HORG 20
VECT2 DW 0C596H
VECTORS ENDSVECT1的偏移地址值为0AH,而VECT2的偏移地址值为14H。
在 ORG语句中若使用含有$的表达式,例如:
ORG $+8表示地址指针从当前地址跳过8字节,即建立了一个8字节的未初始化的数据缓冲区。程序中需要访问该缓冲区,则可用LABEL伪指令来定义该缓冲区。
BUEFER LABEL BYTE
ORG $+8其功能和
BUFFER DB 8 DUP(?)是一样的。
③ EVEN伪指令
EVEN伪指令使下一个变量或指令开始于偶数字节地址。一个字的地址最好从偶地址开始。对于字数组,为保证其从偶地址开始,可以在其前用EVEN伪指令。例如:
DATA SEGMENT……EVENWORD ARRAY DW 100 DUP(?)……
DATA_SEGENDS④ ALIGN伪指令
ALIGN伪指令使下一个变量或指令开始于指定的位置。格式:
ALIGN BOUNDARY其中,BOUNDARY必须是2的幂。
例如,为保证双字数组边界从4的倍数开始,则可以使用如下语句。
.DATA
……
ALIGN 4
ARRAY DB 100 DUP(?)
……显然,“ALIGN 4”可以保证下一个数据和指令是从偶地址开始,其功能和“EVEN”是等价的。
(7)基数控制伪指令(.RADIX)
汇编程序默认的数为十进制数,.RADIX伪指令可以把默认的基数改变为2~16的任何基数。其格式为:
.RADIX 表达式其中,表达式用来表示基数值(用十进制数表示)。例如:
MOV BX,0FFH
MOV BX,178与
.RADIX 16
MOV BX,OFF
MOV BX,178D是等价的。
在用.RADIX 16把基数定为十六进制后,十进制数后面都应跟字母D。在这种情况下,如果某个十六进制数的末字符为D,则其后应跟字母H,以免与十进制数发生混淆。
5.5 汇编语言程序上机过程
5.6 汇编语言程序基本结构设计
5.6.1 程序基本结构
1966年,Bohra和Jacopini提出了以下3种基本结构,用这3种基本结构表示一个良好算法的基本单元。
(1)顺序结构
如图5.4所示,虚线框内是一个顺序结构。其中,A 和B两个框是顺序执行的,即在执行完A框所指定的操作后,必然接着执行B框所指定的操作。顺序结构是最简单的一种基本结构。
(2)选择结构
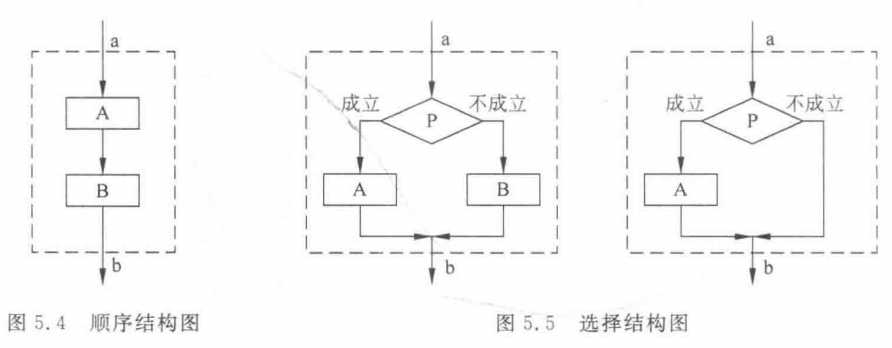
选择结构又称分支结构,如图5.5所示。虚线框内是一个选择结构,此结构中必包含个判断框。根据给定的条件Р是否成立而选择执行A框或B框。注意,无论Р条件是否成立,都只能执行A框或B框之一,不可能既执行A框又执行B框。无论走哪一条路径,在执行完A框或B框之后,都经过b点,然后脱离本选择结构。A框和B框中可以有一个是空的,即不执行任何操作。
(3)循环结构
循环结构又称重复结构,即反复执行某一部分的操作。循环结构分为当型(WHILE型)循环结构和直到型(UNTIL型)循环结构两种。
5.6.2 顺序结构程序设计
顺序结构程序是最简单的程序,在顺序结构程序中,完全按照指令先后顺序逐条执行,这在程序段中是大量存在的,但作为完整的程序则很少见,一般作为程序的部分使用。
【例5.6】 编程序计算。
例如:SUM=3*(X+Y)+(Y+Z)/(Y-Z),其中,X、Y、Z都是16位无符号数,要求结果存入SUM单元。假设运算过程中,中间结果都不超出16位二进制数的范围。程序片段为:
MOV AX,X ;取X
ADD AX,Y ;AX<-X+Y,乘法操作数1
MOV CX,3 ;乘法操作数2
MUL CX ;DX:AX<-3*(X+Y)
MOV CX,AX ;CX<-3*(X+Y)保存
MOV AX,Y ;取Y
ADD AX,Z ;AX<-Y+Z,被除数
XOR DX, DX ;DX<-0
MOV BX,Y ;取Y
SUB BX,Z ;BX<-Y-Z,除数
DIV BX ;AX<-(Y+Z)/(Y-Z)的商
ADD AX, CX ;AX<-3*(X+Y)+(Y+Z)/(Y-Z),两项之和
MOV SUM, AX ;存结果
-------------------------------------------------------------------------------------------------------------------
1. 功能
-
MOV DX, 0:-
直接将寄存器
DX的值设置为0。 -
这条指令需要一个立即数(0)作为操作数。
-
-
XOR DX, DX:-
将寄存器
DX与自身进行异或操作。 -
由于任何数与自身异或的结果都是0,因此这条指令也能将
DX清零。
-
2. 指令长度
-
MOV DX, 0:-
这条指令的机器码长度为3字节。具体来说:
-
MOV指令的操作码(Opcode)占1字节。 -
寄存器
DX的寄存器编码占1字节。 -
立即数
0占1字节。
-
-
-
XOR DX, DX:-
这条指令的机器码长度为2字节。具体来说:
-
XOR指令的操作码(Opcode)占1字节。 -
寄存器
DX的寄存器编码占1字节。
-
-
3. 执行速度
-
MOV DX, 0:-
由于需要处理一个立即数,这条指令在某些处理器上可能需要更多的时钟周期来执行。
-
-
XOR DX, DX:-
这条指令通常更快,因为它不需要处理额外的立即数。在现代处理器中,
XOR指令通常被优化为非常快的操作。
-
4. 代码风格和习惯
-
MOV DX, 0:-
这条指令的意图非常明确,即直接将
DX设置为0。
-
-
XOR DX, DX:-
这条指令在汇编语言编程中是一种常见的惯用法,尤其是在性能敏感的代码中。它不仅更短,而且在某些情况下执行速度更快
-
---------------------------------------------------------------------------------------------------------------------------------
【例5.7】将两个字节数据相加,存放到一个结果单元中,并显示十六进制结果。
//数据段定义
DATA SEGMENTAD1 DB 4CH ;定义第1个加数AD2 DB 25H ;定义第2个加数SUM DB ? ;定义结果单元
DATA ENDS//代码段定义
CODE SEGMENTASSUME CS:CODE,DS:DATA
START: MOV AX,DATAMOV DS, AX ;定义数据段MOV AL,AD1 ;AL<-AD1ADD AL,AD2 ;AL<-AD1 + AD2MOV SUM, AL ;将结果存放在SUM单元MOV BL, AL ;将 AL 的值备份到寄存器 BL 中,以便后续使用MOV CL,4 ;将常数4加载到寄存器 CL 中。SHR AL,CL ;逻辑右移4位,取二进制高4位AND AL, 0FH ;与操作,确保 AL 中只有低4位(原AL高4位)有效ADD AL,30H ;将 AL 中的值加上 30H,转换为ASCII码(0-9)或加上 37H 转换为ASCII码(A-F)。MOV DL, AL ;将 AL 的值加载到寄存器 DL 中。MOV AH,2INT 21H ;调用DOS中断21H的2号功能,将 DL 中的字符输出到屏幕。MOV AL, BL AND AL, 0FH ;与操作,确保 AL 中只有低4位(原AL低4位)有效ADD AL,30H ;低位十六进制 ASCII 码MOV DL, AL ;输出低位MOV AH,2INT 21HMOV AH, 4CH INT 21H ;终止程序并返回到DOS的常用指令组合CODE ENDSEND START本程序采用了DOS中断调用的4CH号功能来退出程序段运行,返回DOS现场。这是一种常用的执行程序返回DOS现场的方法。
5.6.3 分支结构程序设计
(1)分支程序的结构形式
分支程序结构可以有两种形式,如图5.6所示。
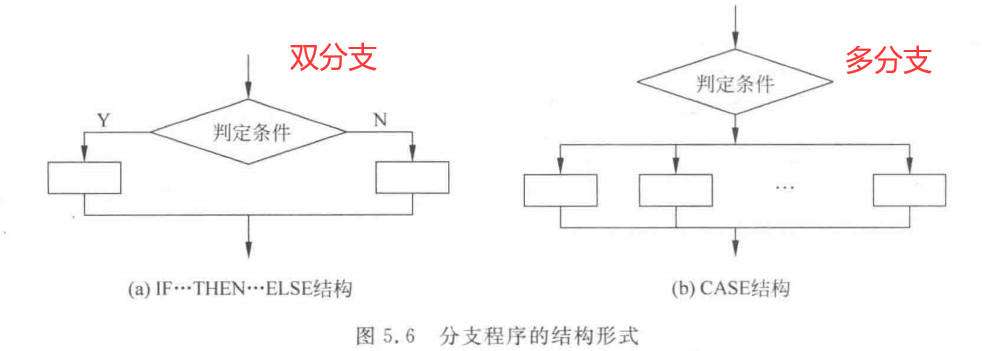
它们分别相当于高级语言中的IF…THEN…ELSE语句和CASE语句,适用于要求根据不同条件做不同处理的情况。IF…THEN…ELSE语句可以引出两个分支;CASE语句则可以引出多个分支。
无论哪一种形式,它们的共同特点是:运行方向是向前的,在某一种特定条件下,只能执行多个分支中的一个分支。
(2)分支程序的设计方法
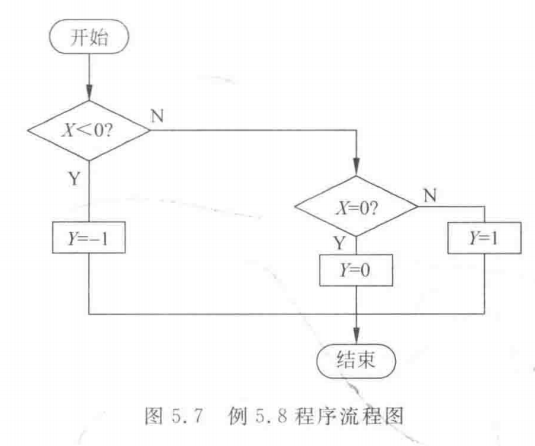
程序的分支一般用条件转移指令来产生,利用转移指令不影响条件码的特性,连续地使用条件转移指令可以使程序产生多个不同的分支,如例5.8所示。

程序中要求对X的值加以判断,根据X的不同值,给Y单元赋予不同的值。程序流程图如图5.7所示。
程序部分代码如下:
CMP X,0JL PNUM ; X<0转移到 PNUM
JZ ZERO ; X=0转移到 ZEROMOV Y,1 ; X>0,就继续执行,给Y单元赋值1
JMP EXIT ;跳转到程序结束位置,结束程序PNUM: MOV Y,-1 ;X<0时,给Y单元赋值-1
JMP EXIT ;跳转到程序结束位置,结束程序ZERO: MOV Y,0 ;X=0时,给Y单元赋值0EXIT: …… ;程序结束的代码
(3)跳跃表法
分支程序的两种结构形式都可以用上面所述的方法来实现。此外,在实现CASE结构时,还可以使用跳跃表法,使程序能够根据不同的条件转移到多个程序分支中,下面举例说明。
【例5.9】试根据AL寄存器中哪一位为1(从低位到高位)把程序转移到8个不同的程序分支中。
下面列出了用变址寻址方式实现跳跃表法的程序。
DATA SEGMENT
DATATAB DW ROUTINE_1DW ROUTINE_2DW ROUTINE_3DW ROUTINE_4Dw ROUTINE_5DW ROUTINE_6DW ROUTINE_7DW ROUTINE_8
DATA ENDSCODE SEGMENT
MAIN PROCFARASSUME CS:CODE, DS:DATA
START:PUSH DSSUB BX, BXPUSH BXMOV BX,DATAMOV DS,BXCMP AL, 0JE CONTMOV SI, 0LP:SHR AL,1JNB NOT_YETJMP DATATAB[SI]NOT_YET: ADD SI, TYPE BRANCH TABLEJMP LPCONT:
……
ROUTINE_1:……
ROUTINE_2:……
……RETMAIN ENDPCODE ENDSEND START
跳跃表法是一种很有用的分支程序设计方法。此外,还可以使用寄存器间接和基址址寻址方式来达到同一目的。
以上实现分支程序的方法并无实质的区别,只是其中关键的JMP指令所用的寻址方式不同而已。
5.6.4 循环结构程序设计
(1)循环程序结构
如果程序中有需要多次重复执行的程序段,则往往将它们设计为循环结构,这样不但程序结构清晰,而且减少源程序的书写,节省占用的内存空间。
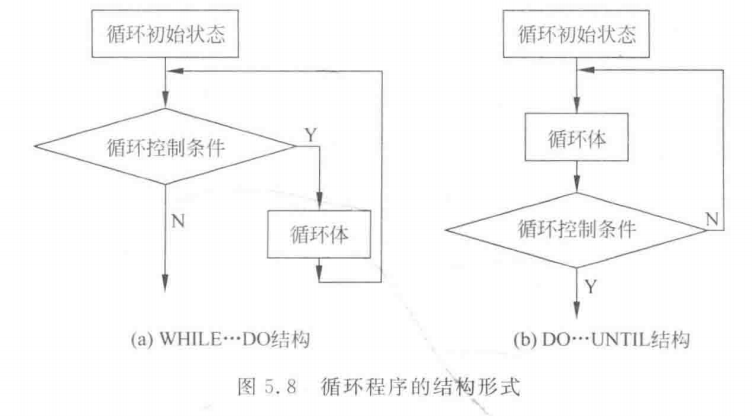
循环程序结构可以总结为两种结构形式:一种是WHILE…DO结构形式;另一种是DO…UNITIL结构形式,如图5.8所示。
① WHILE…DO结构
WHILE…DO结构把对循环控制条件的判断放在循环的入口,先判断条件,满足条件就执行循环体,否则就退出循环。
② DO…UNTIL结构
DO…UNTIL结构则先执行循环体,然后再判断控制条件,不满足条件则继续执行循环操作,一旦满足条件则退出循环。
这两种结构可以根据具体情况选择使用。如果循环次数等于0,则应选择WHILE...DO结构,否则使用DO…UNTIL结构。
循环程序都可由如下三部分组成。
① 循环初始状态设置
它为循环做好必要的准备工作,以保证循环在正确的初始条件下开始工作。这部分完成的工作主要是设置循环次数、给地址指针赋初值、累加器清零、进位标志清零等。
② 循环工作部分
循环工作部分即需要重复执行的程序段,这部分是循环的主体。是针对具体问题而设计的程序段,从初始状态开始,动态地执行相同的操作。
③ 循环修改部分
它与循环工作部分协调配合,通过修改或恢复计数器、寄存器、操作数地址指针等,保证每一次循环时,参加执行的信息能发生有规律的变化。
循环工作部分和循环修改部分合称循环体。
(2)循环控制方法
每个循环程序必须选择一个循环控制条件来控制循环的运行和结束,而合理地选择该控制条件就成为循环程序设计的关键。
① 有时,循环次数是已知的,此时可以用循环次数作为循环的控制条件,通过使用LOOP指令能够很容易地实现这种循环程序;
② 某些情况下,虽然循环次数是已知的,但有可能通过其他特征或条件来提前结束循环,可以使用LOOPZ和LOOPNZ指令实现这种循环程序设计。
③ 然而,有时循环次数是未知的,那就需要根据具体情况找出控制循环结束的条件。循环控制条件的选择是很灵活的,有时可供选择的方案不止一种,此时就应分析比较,选择一种效率最高的方案来实现。
控制循环的执行并判断是否结束循环的方法主要有3种:计数控制、条件控制、逻辑尺控制。
① 计数控制
计数控制是一种最常用的循环控制方法,适用于事先已知循环次数的情况。既可用循环指令LOOP实现,也可用条件转移指令实现。
【例5.10】在首地址为BUFF的内存缓冲区中,存放着20H个带符号的字数据。要求找出其中的最小值,并将最小值存入MIN 单元。
分析:对于这个问题,要找最小值,就要逐个比较这20H个数据,所以可用循环结构程序重复比较过程。比较的方法是:可以先假定第一个数据就是最小值(当前最小值),然后和其余数据比较,如果比当前最小值大,则不处理;否则将该数据置换为当前最小值,直至所有的数据都比较完。显然,这个循环的循环次数是1FH。
程序片段如下:
LEA SI, BUFF ;设地址指针MOV CX, 20H ;CX<-循环次数MOV AX, [SI] ;AX<-第一个数据INC SIINC SI ;字数组,SI自增两次,地址+2个字节,才指向第二个数DEC CX ;修改循环次数计数器AGAIN:CMP AX,[SI]JLE NEXT ;小于或等于时转移,进入下一次循环的准备MOV AX, [SI] ;若AX较大,更新最小值,再进入下一次循环的准备NEXT:INC SIINC SI ;修改地址指针指向下一个数LOOP AGAINMOV MIN,AX
② 条件控制
条件控制适用于事先不知道循环次数的情况,但可以用给定的某种条件来判断是否结束循环。
【例5.11】编程统计AX寄存器中1的个数,并将结果存入SUM单元。
分析:要统计二进制数中1的个数,最方便的方法是将这个数的各位依次移入CF标志,通过检测CF的值来判断该位是否为1,以此统计所含1的个数。这是一个重复计数的过程,可以用循环程序实现。对循环的控制,可以用计数方法,共检测16次;还可以通过判断移位后二进制数是否变为0作为循环结束的条件。当二进制数的后几位全部为0时,用这种方法可以提前结束循环,提高程序的运行效率。程序流程图如图5.9所示。
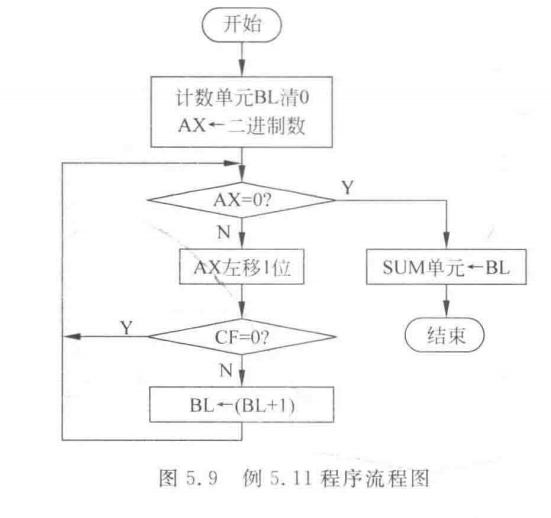
程序片段如下:
MOV BL,0 ;计数单元B清0
AGAIN: OR AX, AX ;测试AX是否为0JZ EXIT ;若AX=0,则转移到结束点SHL AX,1 ;将AX最高位移至CFJNC NEXT ;CF=0,转去NEXT,即AGAIN继续INC BL ;CF≠0,BL加1
NEXT: JMP AGAIN
EXIT: MOVSUM, BL③ 逻辑尺控制
有时候,循环体内的处理任务在每次循环执行时并无规律,但确实需要连续运行。此时,可以给各处理操作标以不同的特征位,所有特征位组合在一起,就形成了一个逻辑尺。
【例5.12】在数据段中有两个数组X和Y,每个数组含有10个双字节数据元素。现将两个数组的对应元素进行下列计算,形成一个新的数组M。假定数组的对应元素计算后,结果不产生溢出。
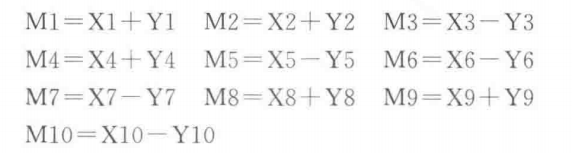
很显然,这个问题可以用循环实现,而且循环次数确定为10次。但每次循环的操作是进行加还是减,无规律可循。为此,可以为每一次操作设置一个特征位,即0表示加,1表示减,构成一个16位的逻辑尺,存放于DX寄存器中。本例逻辑尺为:
0010,1110,0100,0000
从左到右依次为数组元素1~10的特征位。每次将逻辑尺左移1位,根据移入CF的特征位,判断本次循环体所进行的操作。程序流程图如图5.10所示。
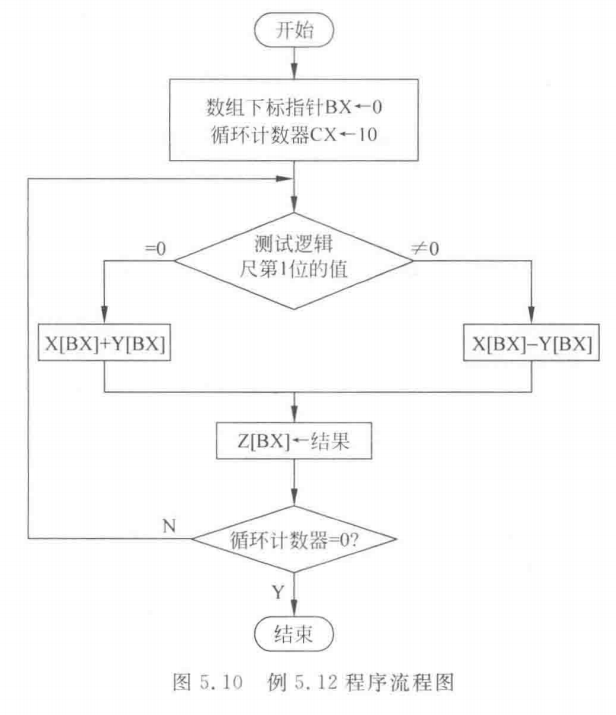
程序片段如下:
MOV BX,0 ;设数组下标指针MOV CX,10 ;设循环计数器
AGAIN:MOV AX,X[BX]SHL DX,1 ;左移1位送入CFJC SUBB ;若当前特征位为1,则做减法;否则做加法ADD AX,Y[BX]JMP NEXT
SUBB: SUB AX,Y[BX]
NEXT: MOV M[BX],AX ;送结果INC BXINC BXLOOP AGAIN
(3)双重循环程序设计
【例5.13】编制程序实现延时1ms。
延时程序就是让计算机执行一些空操作或无用操作,来占用CPU的时间,从而达到延时的目的。延时程序通常用循环程序实现。程序片段如下:
MOV CX,374
DELAY1: PUSHF ;10TPOPF ;8TLOOP DELAY1 ;3.4T上面程序段的循环体和循环控制部分由指令PUSHF POPF和 LOOP构成。这3条指令执行所花费的时钟周期个数和为10+8+3.4=21.4。如果CPU的主频为8MHz,那么它的时钟周期为0.125us ;如果要实现延时1ms,则该循环体重复执行的次数为:
循环次数=1ms/(0.125us×21.4)≈374
如果要延时100ms,那么只需将这个程序再执行100次,从而构成一个双重循环。其程序片段如下:
SOFTDLY PROC MOV BL,100 ;4T
DELAY2: MOV CX, 374 ;4T
DELAY1: PUSHF ;10T,标志寄存器进栈,内层循环,循环374次POPF ;8TLOOP DELAY1 ;3.4TDEC BL ;2T
SOFTDLY PROC JNZ DELAY2 ;8T,外层循环,循环100次显然,该程序的准确延时时间=4T+100(4T+21.4T×374+2T+8T)=100.22ms.
5.7 汇编语言子程序设计
如果在一个程序的多个位置,或者在多个程序的多个位置中用到了同一段程序,则可将这段程序抽取出来,单独存放在某一区域,每当需要执行这段程序时,就用调用指令转到这段程序,执行完毕再返回原来的程序。抽取出来的这段程序称为子程序或过程,而调用它的程序称为主程序或调用程序。主程序向子程序的转移过程称为子程序调用或过程调用。
使用子程序是程序设计的一种重要方法。子程序的引入使程序功能的层次性更加分明,增强了程序的可读性,为较大软件设计的分工合作提供了方便。
5.7.1 子程序的定义
子程序的定义由过程定义伪指令PROC/ENDP实现。
(Procedure,程序)
其格式为:

所定义的子程序可以和主程序在同一个代码段内,也可以在不同的代码段内。
说明:
① 过程名(子程序名)用以标识不同的过程,是一个用户自定义的标识符号。
② PROC 与 ENDP相当于一对括号,将子程序的处理过程(过程体)括在其中。过程体是一段相对独立的程序,是完成子程序功能的主体。过程的最后一条指令必须是RET(返回指令)。
③ NEAR或FAR是子程序属性的说明参数。NEAR属性的子程序只允许段内调用这时,子程序的定义必须和调用它的主程序在同一代码段内;FAR属性的过程允许段间调用,即允许其他段的程序调用。过程的属性决定了调用指令CALL和返回指令RET的操作。
5.7.2 子程序的调用和返回
子程序的调用和返回由CALL指令和RET指令实现。从不同的角度,可对子程序的调用进行以下分类。
(1)段内调用与段间调用
段内调用:在子程序和调用返回过程中,转移地址和返回地址不涉及CS的变化,只通过IP内容的变化实现程序的转移和返回。
段间调用:由CS和IP的变化共同决定程序的转移和返回。
显然,当主程序和子程序处于同一代码段时,可以把子程序定义为NEAR属性或FAR属性;而当主程序与子程序不在同一代码段时,子程序必须被定义为FAR属性。
(2)直接调用与间接调用
当调用指令使用过程名调用某过程时,调用时通过把该过程的指令入口地址送入CS和IP(段内调用仅修改IP)来实现的,这个调用过程称为直接调用。
当调用指令是通过某个寄存器或存储器单元指出被调用子程序的入口地址时,这个调用过程称为间接调用。
间接调用可分为寄存器间接调用和存储器间接调用。
在实际使用时,直接调用因方便清楚而使用较多。无论采用哪种调用方式,为了能保证子程序执行完后顺利地返回主程序,CALL指令在将控制转移到子程序之前,都将自动保护返回地址。返回地址也称为断点,是CALL指令下一条指令的第一个字节地址(段内调用仅保存IP,段间调用保存CS和IP),然后才转入子程序执行。待执行完子程序后,RET指令负责把保护的返回地址(即断点)恢复到CS和IP中(段内调用仅需恢复IP),继续执行主程序。断点的保护和返回是通过堆栈指令PUSH和 POP实现的。
子程序示例如下:
CODE1 SEGMENT……CALL PROC1
AAA:……PROC1 PROC……RET PROC1 ENDPPROC2 PROC FAR……RETPROC2 ENDP
CODE1 ENDSCODE2 SEGMENT……CALL PROC2
BBB:……
CODE2 ENDS
在以上程序段中,CALL PROC1是段内调用,CALL PROC2是段间调用。AAA 和BBB是两个返回地址。子程序 PROCl返回后,从 AAA处开始执行;子程序PROC2返回后,从 BBB处开始执行。
5.7.3 编写子程序时的注意事项
由于子程序可在程序的不同位置或在不同的程序中被多次调用,因此对于子程序的设计提出了很高的要求,如通用性强、独立性好、程序目标代码短、占用内存空间少、执行速度快、结构清晰,以及有详细的功能、参数说明等。在设计子程序时,需要注意以下几点:
-----------------------------------------------------------------------------------------------------------------------------
(1)参数传递
为了使子程序具有较强的通用性,子程序所处理的数据往往并不是常量,而是约定在某数据区的地址单元处。主程序每次调用子程序时,必须对约定地址单元中的数据进行处理。这些数据被称为参数,主、子程序间的数据传递就称为参数传递。其中主程序传递给子程序的参数称为子程序的入口参数,子程序返回给主程序的参数称为出口参数。
主程序和子程序间的参数传递通常使用的方法有通用寄存器传递、存储单元传递、地址表传递和堆栈传递。每种传递方法都有自己的优缺点,要根据不同的问题选择适合的传递方法。具体传递方法的设计将在后面举例讨论。
这一点在第四版改为:
(1)信息保护:……
(2)子程序的说明:……
(3)汇编语言子程序无参数。子程序中指令访问的存储单元、寄存器等与主程序中访问的是同一物理设备,无需参数传递数据。
-------------------------------------------------------------------------------------------------------------------------------
(2)信息保护
为了保证由子程序返回主程序后程序执行的正确性,通常要将子程序中用到的寄存器压入堆栈保护,子程序执行完成后再恢复出来。将寄存器压入堆栈保护的过程称为保护现场,将寄存器从堆栈中弹出恢复的过程称为恢复现场。保护和恢复现场的工作既可以在调用程序中进行,也可以在子程序中进行。
(3)子程序的说明
为了方便各类用户对子程序的调用,一个子程序应该有清晰的文本说明,以提供给用户足够的使用信息。通常子程序的文本说明包括以下一些内容。
①子程序名。
②子程序功能、技术指标。
③子程序的入口、出口参数。
④子程序使用到的寄存器和存储单元。
⑤是否又调用其他子程序。
⑥子程序的调用形式。
5.7.4 子程序举例
【例5.14】两个16位十进制数以压缩BCD码的形式存放在内存中,求它们的和。可以通过8次字节数相加,每次相加后再进行十进制调整来实现。
DATA SEGMENTDAT1 DB 34H,67H,98H,86H,02H,41H,59H,23H ;低位在前DAT2 DB 33H,76H,89H,90H,05H,07H,65H,12H ;低位在前SUM DB 10 DUP(0)
DATA ENDSSTACK SEGMENT PARA STACKDW 20H DUP(0)
STACK ENDSCODE SEGMENTASSUME CS:CODE,DS:DATA,SS:STACK
START: MOV AX, DATAMOV DS,AXMOV CX,8 ;设子程序入口参数CALL ADDP ;调用加法子程序MOV AH, 4CH ;返回 DOSINT 21H
ADDP PROC ;加法子程序,完成两位十进制数相加PUSH AX ;保护现场PUSH BXCLCMOV BX,0AGAIN: MOV AL, DAT1[BX] ;两数相加ADC AL,DAT2[BX]DAA ;十进制调整MOV SUM[BX],AL ;存储和数INC BX ;修改地址指针LO0P AGAIN ;循环执行8次ADC SUM[BX],0POP BXPOP AX ;恢复现场RET ;返回主程序
ADDP ENDP
CODE ENDSEND START
(第三版是:
(1)用寄存器和存储器传递参数:……
(2)用地址表传递参数:……
(3)用堆栈传递参数:……)
5.7.5 子程序的嵌套和递归调用
在一个子程序中又调用其他的子程序,这种情况称为子程序的嵌套。
只要堆栈允许,嵌套的层次就可以不加限制。图5.12所示为一个两层的子程序嵌套调用示意图。
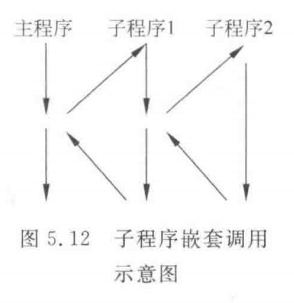
在子程序嵌套调用时,每一个子程序执行完后都要返回上一级调用程序,所以对于堆栈的使用要格外小心,以防出现不能正确返回的错误。
所谓子程序的递归调用,就是指在子程序嵌套调用时,调用的子程序就是它本身。递归子程序和数学上递归函数的定义相对应,必须有一个结束的条件。在递归的过程中,每一次调用所用到的调用参数和运行结果都不相同,必须将本次调用的这些信息存放在堆栈中,这些信息称为一帧,下一次的调用必须保证这帧信息不被破坏。当递归满足结束条件时,开始逐级返回,每返回一级,就从堆栈中弹出一帧信息,计算一次中间结果。在递归结束后,堆栈恢复原状。
子程序的递归调用会用到大量的堆栈单元,因此要特别注意堆栈的溢出。在编制程序时,可以采取一些保护措施。
在实际应用中,程序结构往往不是单一的结构,而是多种结构的复合,应根据具体情况和要求做出合理的设计。
5.8 系统功能调用
系统功能子程序:为了减少程序设计的复杂度,微机系统提供了一些系统功能子程序,用户通过调用这些系统功能子程序,可以方便地实现对底层硬件接口的操作,从而提高汇编语言源程序的设计效率。
微机系统提供两组功能程序:一组固化在基本I/O系统BIOS(Basic Input and OutputSystem)内;另一组在 DOS(Disk Operating System)系统内。
这些功能程序其实是由几十个内部子程序组成的,它们能完成对I/О设备、文件、作业、目录等的管理和操作。程序员不必了解所使用设备的物理特性、接口方式及内存分配等,不必编写烦琐的控制程序,在程序需要的地方,可直接调用,实现相应功能。
使用这些系统功能子程序编写的程序简单、清晰、可读性好,而且代码紧凑,调试方便。
5.8.1 系统功能调用方法
为了调用这些功能子程序,操作系统提供了一个调用接口,通过软中断指令来实现。
格式:
INT n其中,n是中断类型码。
当n=5~1FH 时,调用BIOS中的服务程序,称为系统中断调用;
当n=20~3FH时,调用DOS中的服务程序,称为功能调用。
每一个不同的中断类型码,又包含若干个子功能。为区分这些子功能,系统给每一个子功能一个功能号,要求在调用前将这个功能号送入AH寄存器。对于需要使用入口参数的功能调用,还要事先设置入口参数。它们的调用方法如下。
(1)送分功能号给AH。
(2)设置入口参数。
(3)INT n。
每执行一条软中断指令,就调用一个相应的中断服务程序。
5.8.2 BIOS调用
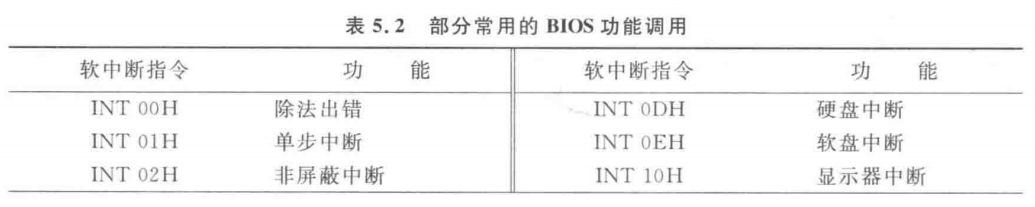
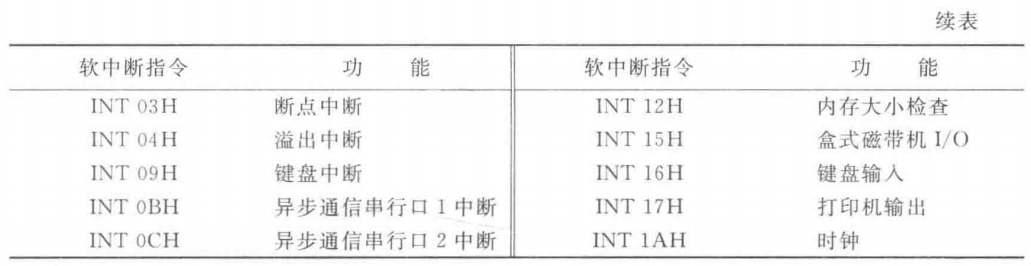
BIOS是固化在ROM中的一组I/О服务程序,除系统测试程序、初始化引导程序及部分中断矢量装入程序外,还为用户提供了常用设备的输入/输出程序,如键盘输入,打印机及显示器输出等。表5.2所示为部分常用的 BIOS功能调用的简要说明。
5.8.3 DOS系统功能调用
DOS系统功能调用和BIOS调用有些功能是类似的,相比较而言,DOS 系统功能调用还增加了许多必要的检测,因此比BIOS调用方便、操作简易、对硬件的依赖性少。
其中,
INT 21H是一个具有调用多种功能服务程序的软中断指令,称为DOS系统功能调用。它内部又包含80多个子功能,大致可以分为设备管理、目录管理、文件管理和其他功能。用户可根据功能号区分调用。下面对几个常用的系统功能调用进行简单介绍。
(1)带显示的单字符键盘输入(01H号功能)
此功能程序等待键盘输入,若有字符键按下,将输入字符的ASCII码送入AL寄存器,并在屏幕上显示。如果按下的键是Ctrl+C组合键,则停止程序运行;如果按下的键是Tab键,则屏幕上的光标自动移至下一个制表位。
入口参数:无
出口参数:AL=输入字符的 ASCII码
格式:
MOV AH,01H
INT 21H(2)输出单字符(02H号功能)
在屏幕上显示输出DL寄存器中的字符。如果 DL中是 Backspace键编码,则光标向左移动一个位置,并使该位置显示空格;如果是其他字符,则显示该字符。
入口参数:DL=输出字符
出口参数:无
格式:
MOV DL,'A' ;A字符的 ASCII 码置入DL中,DL=41H
MOV AH,2 ;将2号功能的入口号存入AH寄存器中。;在DOS中断21H中,不同的AH值对应不同的功能。;AH=2时,表示的是输出单个字符到屏幕的功能。
INT 21H ;调用DOS中断21H。;当执行这条指令时,系统会根据前面设置好的AH和DL寄存器中的值,;来执行相应的中断处理程序。;由于前面已经设置了AH=2和DL=41H,所以系统会调用DOS中断21H的2号功能, ;将DL寄存器中的字符“A”输出到屏幕上。//这段代码是DOS环境下常见的字符输出方式,通过设置好相应的寄存器值,
//然后调用中断来实现简单的字符输出功能。
(3)不带显示的单字符键盘输入(07H号、08H号功能)
07H号和08H号与01H号功能类似,区别仅仅是输入的字符不在屏幕上显示。其中,07H号功能调用对Ctrl+C组合键和Tab键无反应。
入口参数:无
出口参数:AL=输入字符
格式:
MOV AH:07H
INT 21H//或MOV AH,08H
INT 21H(4)字符串输出(09H号功能)
09H号功能是在屏幕上显示输出字符串。它要求事先将要显示的字符串的段地址和段内偏移地址送入DS和DX寄存器,并且该字符串应以'$'结尾。
('$':标志字符串结束——要存储,但是不会输出)
人口参数:DS=字符串所在段的段基值、DX=字符串的段内偏移量
出口参数:无
格式:
MOV DX,字符串偏移量
MOV AH,O9H
INT 21H例如:
STRING DB 'A EXAMPLE'0DH,0AH,'$'
……
MOV DX, OFFSET STRING
MOV AH,09H
INT 21H//0DH 和 0AH:这两个是十六进制的ASCII码值,分别表示回车符(Carriage Return,ASCII
//码为13)和换行符(Line Feed,ASCII码为10)。它们的作用是使光标回到行首并换到下一行,
//类似于按下回车键的效果。//'$':这是一个特殊的字符,通常用于DOS中断21H的9号功能(显示字符串)中,表示字符串的
//结束标志。当DOS中断21H的9号功能遇到 $ 时,就会停止显示字符串。(5)字符串输入(0AH号功能)
从键盘输入一串字符到内存缓冲区,输入的字符串以Enter键结束。
内存缓冲区的第一个字节内容由用户设置,设置为所能接收的最大字符个数(1~255);
第二个字节预留,由系统填充实际输入的字符个数(Enter键除外);
从第三个字节开始,存放从键盘输入的字符。若输入的字符个数大于所能接收的最大字符个数,则系统发出响铃提示,多余的字符被略去;若输入的字符个数小于所能接收的最大字符个数,则空出的位置补零。
入口参数:DS:DX=缓冲区首址、[DS:DX]=缓冲区最大字符个数
出口参数:[DS:DX + 1]=实际输入的字符个数、[DS:DX+2]单元开始存放实际输入的字符
格式:
MOV DX,缓冲区偏移量
MOV DS,缓冲区段基址
MOV AH, OAH
INT 21H例如:
BUFDB 30,?,30 DUP(?)
MOV DX,OFFSET BUF
MOV DS,SEG BUF
MOV AH, OAH
INT 21H(6)返回操作系统(4CH号功能)
4CH号功能是将控制返回操作系统。
入口参数:AL=返回码
出口参数:
格式:
MOV AH,4CH
INT 21H5.9 宏指令
为了简化程序的设计,可以将汇编语言源程序中多次重复使用的程序段用宏指令来代替,即宏定义。
宏指令:是指程序员事先定义的特定的“指令”,这种“指令”是一组重复出现的程序指令块的缩写和替代。
宏调用:宏指令定义以后,凡在宏指令出现的位置,宏汇编程序总是自动地把它们替换为对应的程序指令块,这个引用过程称为宏调用。
宏展开:汇编程序在汇编时遇到宏调用语句时,将把宏调用语句展开,即将宏定义的代码段插入到宏调用语句的位置取而代之,这个过程称为宏展开。
因此,宏的操作必定经过3个步骤:宏定义、宏调用、宏展开。
使用宏指令的优点是:简化源程序的编写、传递参数特别灵活、功能更强。
(宏指令属于可选项,非必须项,选学)
5.9.1 宏定义
宏指令是源程序中的一段具有独立功能的程序代码。它只要在源程序中定义一次,就可以多次调用,调用时只要使用一个宏指令语句就可以了。
宏指令定义由:开始伪指令MACRO、宏指令体、宏指令定义结束伪指令ENDM组成。
其格式为:
宏指令名 MACRO[形式参数1,形式参数2,…,形式参数N]…… ;宏指令体(宏体)ENDM其中,宏指令名是宏定义为宏体程序指令块规定的名,,既可以是任一合法的名称,也可以是系统保留字(如指令助记符、伪指令运算符等),当宏指令名是某个系统保留字时,该系统保留字就被赋予新的含义,从而失去原有的意义。
MACRO语句到ENDM语句之间的所有汇编语句构成宏指令体,简称宏体,宏体中使用的形式参数必须在MACRO语句中列出。
形式参数是宏体内某些位置上可以变化的符号,可以默认,也可以有一个或多个。宏指令定义一般放在源程序的开头,以避免不应发生的错误。
宏指令必须先定义后调用。宏指令可以重新定义,也可以嵌套定义。嵌套定义是指在宏指令体内还可以再定义宏指令或调用另一宏指令。

5.9.2 宏调用
宏指令一旦定义后,就可以用宏指令名来调用了,宏调用的格式为:
宏指令名 [实际参数1,实际参数2,…,实际参数N]其中,实际参数的类型和顺序要与形式参数的类型和顺序保持一致,宏调用时将一一对应地替换宏指令体中的形式参数。宏指令调用时,实际参数的数目并不一定要和形式参数的数目一致,当实参个数多于形参的个数时,将忽略多余的实参;当实参个数少于形参个数时,多余的形参用空串代替。

5.9.3 宏展开
宏汇编程序遇到宏定义时并不对它进行汇编,只有在程序中宏调用时,汇编程序才把对应的宏指令体调出进行汇编处理(语法检查和代码块的插入),这个过程称为宏展开(或宏扩展)。宏指令调用后,在宏指令调用处将产生用实参替换形参的宏体指令语句。
在 MASM汇编生成列表文件(. lst)的每行中间用符号“+”作为标志,表明本行语句为宏指令展开生成的语句。
例如,上述 INOUT宏指令调用后,宏展开后的语句为:
+ MOV AH,9
+ LEA DX,INPUT
+ INT 21H
+ MOV DL,10
+ MOV AH,2
+ INT 21H
+ MOV DL,13
+ MOV AH,2
+ INT 21H
+ MOV AH,10
+ LEA DX, KEYBUE
+ INT 21H
+ MOV AH,9
+ LEA DX, KEYBUE+2
+ INT 21H这里,实际参数以整体去替换形式参数的整体(即对应符号的整体代替)。如果只希望以数值代替形式参数,则可使用特殊宏计算符号“&”和“%”。
5.10 实用程序设计举例
……
5.11 调试程序DEBUG的使用
……
5.12 例题解析
……
5.13 本章实验项目
……