OpenCV进阶操作:光流估计
文章目录
- 前言
- 一、光流估计
- 1、光流估计是什么?
- 2、光流估计的前提?
- 1)亮度恒定
- 2)小运动
- 3)空间一致
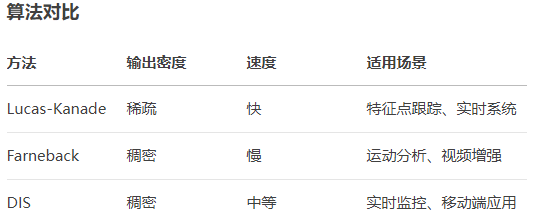
- 3、OpenCV中的经典光流算法
- 1)Lucas-Kanade方法(稀疏光流)
- 2) Farneback方法(稠密光流)
- 3)DIS光流(快速稠密光流)
- 二、使用步骤
- 1、读取视频
- 2、特征检测
- 3、处理每一帧画面
- 4、运行结果
- 5、完整代码
- 总结
前言
光流(Optical Flow)是计算机视觉中用于描述图像序列中物体运动模式的核心技术。从视频稳定到自动驾驶,从动作识别到增强现实,光流估计在动态场景分析中扮演着关键角色。OpenCV提供了多种光流算法实现,本文将深入解析其原理与实践方法。
一、光流估计
1、光流估计是什么?
光流估计是空间运动物体在观测成像平面上的像素运动的“瞬时速度”,根据各个像素点的速度矢量特征,可以对图像进行动态分析,例如目标跟踪。

2、光流估计的前提?
1)亮度恒定
同一点随着时间的变化,其亮度不会发生改变。
2)小运动
随着时间的变化不会引起位置的剧烈变化,只有小运动情况下才能用前后帧之间单位位置变化引起的灰度变化去近似灰度对位置的偏导数。
3)空间一致
一个场景上邻近的点投影到图像上也是邻近点,且邻近点速度一致。因为光流法基本方程约束只有一个,而要求x,y方向的速度,有两个未知变量。所以需要连立n多个方程求解。
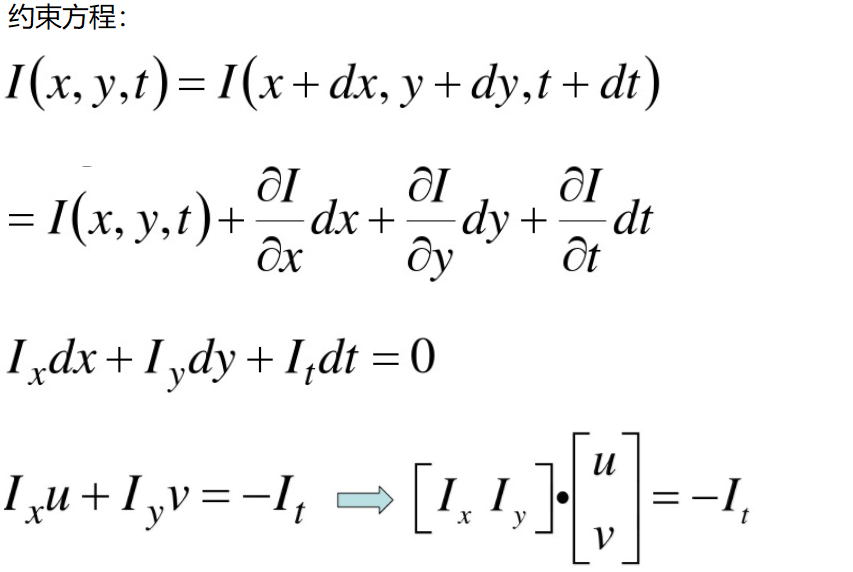
3、OpenCV中的经典光流算法
1)Lucas-Kanade方法(稀疏光流)
-
原理:对局部窗口内的像素应用最小二乘法求解
-
特点:仅跟踪关键特征点
-
计算效率高,适合实时应用
-
函数:cv2.calcOpticalFlowPyrLK()
2) Farneback方法(稠密光流)
-
原理:通过多项式展开近似邻域像素
-
特点:计算每个像素的运动向量
-
资源消耗较大,但信息更丰富
-
函数:cv2.calcOpticalFlowFarneback()
3)DIS光流(快速稠密光流)
-
原理:基于变分方法的快速实现
-
特点:速度与精度的平衡方案
-
函数:cv2.DISOpticalFlow_create()
二、使用步骤
1、读取视频
import numpy as np
import cv2
cap = cv2.VideoCapture('test.avi')
#随机生成颜色,用于绘制轨迹
color = np.random.randint(0,255,(100,3))
ret,old_frame = cap.read()
old_gray = cv2.cvtColor(old_frame,cv2.COLOR_BGR2GRAY)
2、特征检测
feature_params = dict(maxCorners=100,qualityLevel=0.3,minDistance=7)
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
mask = np.zeros_like(old_frame)
lk_params = dict(winSize=(15,15),maxLevel=2)
3、处理每一帧画面
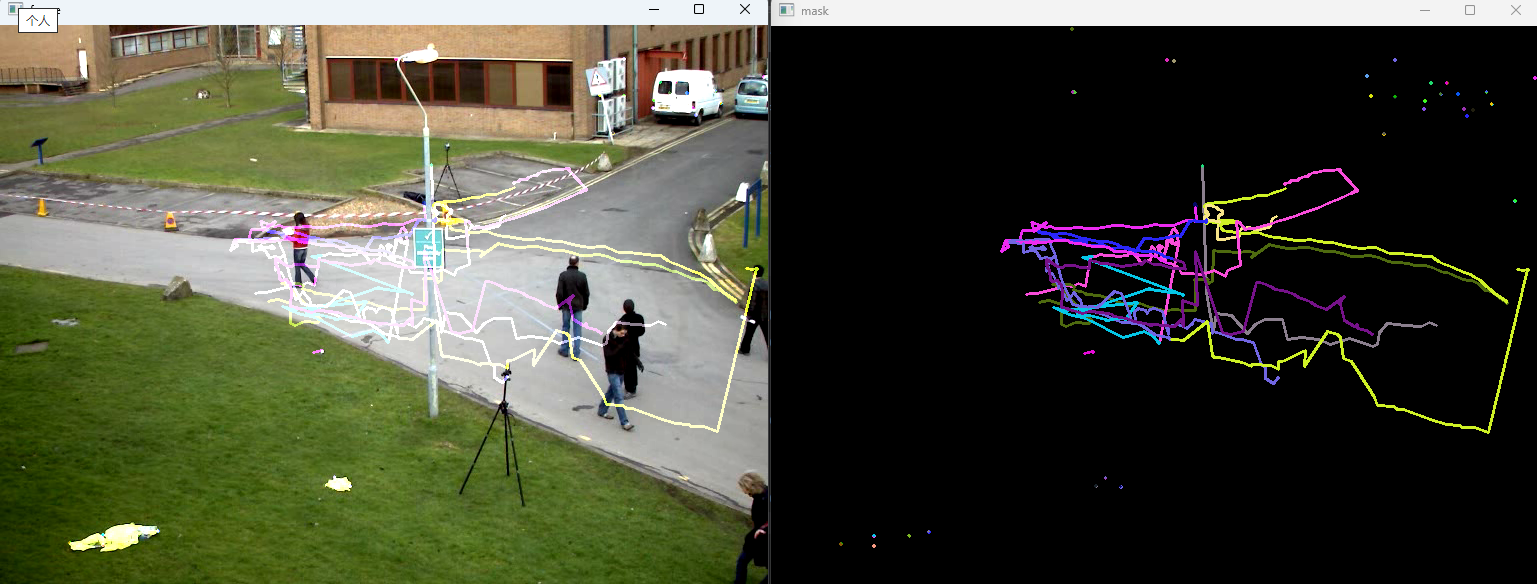
while True:ret,frame = cap.read()if not ret:breakframe_gray = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)p1,st,err = cv2.calcOpticalFlowPyrLK(old_gray,frame_gray,p0,None,**lk_params)good_new = p1[st == 1]good_old = p0[st == 1]for i,(new,old) in enumerate(zip(good_new,good_old)):a,b = new.ravel()c,d = old.ravel()a,b,c,d = int(a),int(b),int(c),int(d)mask = cv2.line(mask,(a,b),(c,d),color[i].tolist(),2)cv2.imshow('mask',mask)img = cv2.add(frame,mask)cv2.imshow('frame',img)k = cv2.waitKey(10)if k == 27:breakold_gray = frame_gray.copy()p0 = good_new.reshape(-1,1,2)cv2.destroyAllWindows()
cap.release()
4、运行结果
5、完整代码
import cv2
import numpy as np# 打开视频文件
cap = cv2.VideoCapture('test.avi')
color = np.random.randint(0,255,(100,3)) # 生成随机整数数组,值范围为0-255,格式为100*3,以此充当颜色用来绘制轨迹,此处的值为矩阵类型
ret,old_frame = cap.read() # 读取视频的di一帧画面,返回读取状态布尔值和每一帧的图像
old_gray = cv2.cvtColor(old_frame,cv2.COLOR_BGR2GRAY) # 将第一帧转换为灰度图# 定义特征点检测参数
feature_params = dict(maxCorners=100, # 最大角点数量,特征点qualityLevel = 0.3, # 角点质量的阚值minDistance = 7) # 两个特征点最小欧式距离,用于分散角点# 对第一帧画面进行特征检测
p0 = cv2.goodFeaturesToTrack(old_gray,mask=None,**feature_params) # **:关键字参数解包,用于将字典解包为关键字参数,# 创建一个与给定数组大小和数据类型都相同的全0的新的数组,将其当做掩膜
mask = np.zeros_like(old_frame)#定义Lucas-Kanade光流参数
lk_params = dict(winSize=(15,15), # 窗口大小为15*15maxLevel=2) # 金字塔层数为2# 主循环,处理视频的每一帧
while (True): # 定义一个死循环ret,frame = cap.read() # 上述已经读取了第一帧画面,再次读取会接着第二帧进行读取if not ret: # 检查是否成功读取到breakframe_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转换为灰度图# calcOpticalFlowPyrLK在图像序列中跟踪特征点的运动,计算前一帧old_gray特征点p0在当前帧frame_gray中的新位置p1p1,st,err = cv2.calcOpticalFlowPyrLK(old_gray,frame_gray,p0,None,**lk_params)# p1 特征点新坐标# st 状态数组,表示每个特征点是否被成功跟踪,1表示成功,0表示失败# err 错误数组,包含每个特征点的跟踪误差,误差与匹配质量有关# 选择好的点(状态为1的点)good_new = p1[st == 1]good_old = p0[st == 1]# 绘制轨迹for i,(new,old) in enumerate(zip(good_new,good_old)): # 将新的特征点和旧的特征点进行打包,因为有很多特针点,所以使用enumerate将其转变成可迭代对象,返回索引和值a,b = new.ravel() # 获取新点的坐标(a,b), 或者使用[a,b]= new,ravel()将多维数组展平成一维数组,一维视图,返回一维数组c,d = old.ravel() # 获取旧点的坐标a,b,c,d = int(a),int(b),int(c),int(d) # 将数值转换为整数# 在掩模上给制线段,连接新点和旧点mask = cv2.line(mask,(a,b),(c,d),color[i].tolist(),2) # 绘制线,在mask图像上绘制从点(a,b)到(c,d)的线,颜色为上述定义的,每个特征点的颜色不同cv2.imshow( 'mask', mask)img = cv2.add(frame, mask) # 使用add叠加图像,将mask图像叠加到当前帧frame上cv2.imshow('frame', img) # 显示结果图像# 等待150ms,检测是否按下了Esc键(键码为27)k = cv2.waitKey(150) & 0xffif k == 27: # 按下ESC键,退出循环break# 更新旧灰度图和旧特征点old_gray = frame_gray.copy() # 每当绘制完当前帧与上一帧的图像后将当前帧的副本赋值给上一帧使其进入下一个循环# 将当前帧的特征点的新位置赋值给p0,重新整理特征点为适合下次计算的形状p0 = good_new.reshape(-1,1,2) # 将当前帧关键点的坐标形状更改为3维,-1表示自动判断维度大小,1,2表示一行两列# 释放资源
cv2.destroyAllWindows() # 关闭所有页面
cap.release() # 释放摄像头资源
总结
OpenCV的光流工具为运动分析提供了强大支持,
-
稀疏光流适合实时跟踪,稠密光流适合精细分析
-
参数调优需在精度与效率之间取得平衡
-
结合传统图像处理与深度学习可获得更鲁棒的结果