深度策略梯度算法PPO
一、策略梯度核心思想和原理
从时序差分算法Q学习到深度Q网络,这些算法都侧重于学习和优化价值函数,属于基于价值的强化学习算法(Value-based)。
1. 基于策略方法的主要思想(Policy-based)
基于价值类方法当状态动作空间较大且连续时面临挑战,对基于策略的目标函数使用梯度上升优化参数最大化奖励。在策略梯度中,参数化的策略π不再是一个概率集合,而是一个概率密度函数
2. 优点:建模效率高、探索性更好、收敛性更优
3. 模型结构
是无环境模型的结构,神经网络作为策略函数近似器,其参数表示或策略
仍然是一个无环境模型结构,和之前基于价值类的方法有很大的不同。首先,策略不再是隐式的,而是要直接求解。对于深度策略梯度而言就是使用神经网络作为策略函数的函数逼近器,通过神经网络的参数来表示策略π。其次,在下边的PGM图中,没有画出价值结点,多了奖励累计部分,这是因为经典的策略梯度方法经常使用奖励和的期望作为优化的目标,而不直接使用状态价值函数V(s),或者动作价值函数Q(s,a)。与之前的Value-Based方法不同,基于策略的方法不依赖与价值函数的估计,不适用贝尔曼方程或者贝尔曼期望方程,是直接使用神经网络逼近策略函数,并使用策略梯度来进行更新。
R(t)和G(t)的区别:其中R(t)是累计奖励,G(t)是回报。回报是随时间步变化的量,累计奖励R是整个episode的奖励的总和。
4. 目标函数
episode可以用很多个,比如打游戏每个回合就是一个episode,希望在多个回合中找到最佳策略或者规律。目标函数的设计原则就是所有的回合总回报的加权平均值最大(用加权平均的原因是因为每条轨迹发生的概率不同,用的经常发生,有的发生的概率极小,显然不能平均)
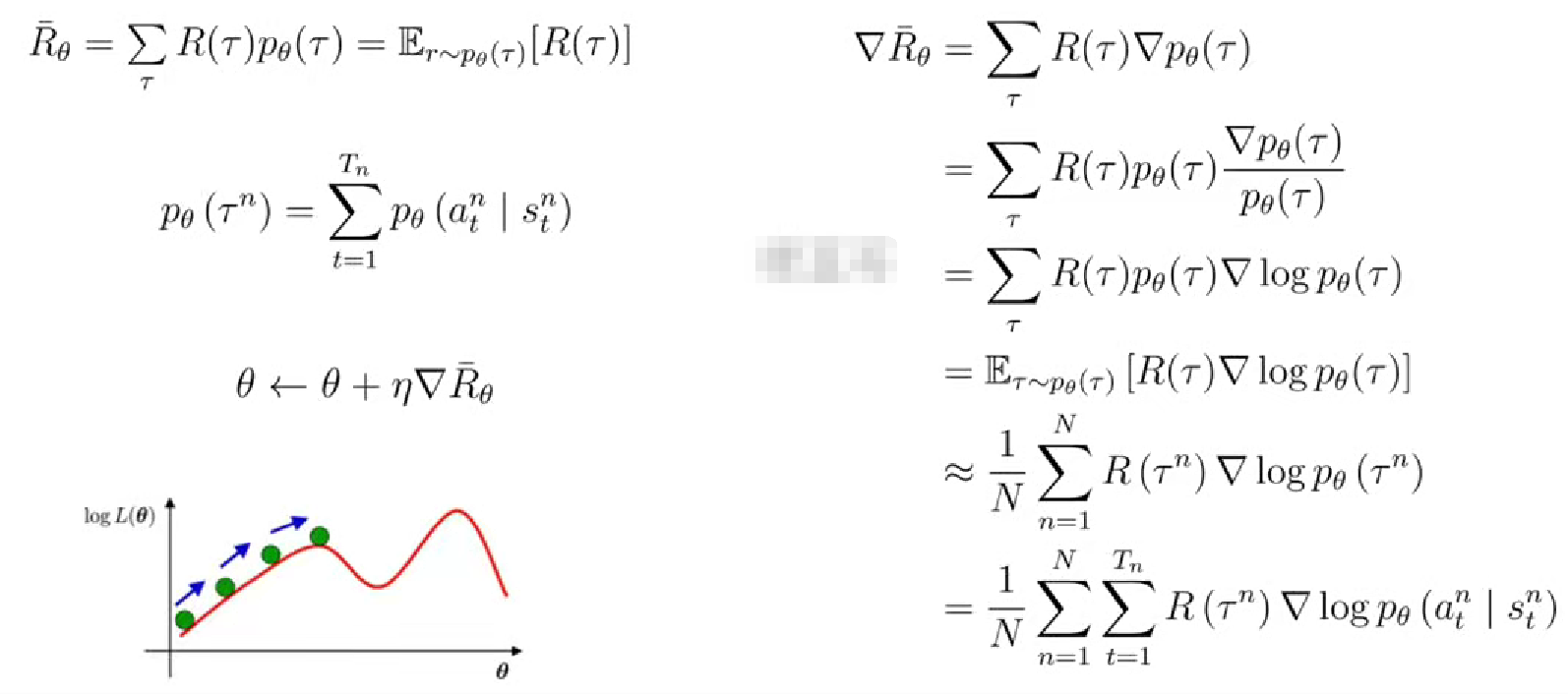
5. 策略梯度的两种常见改进
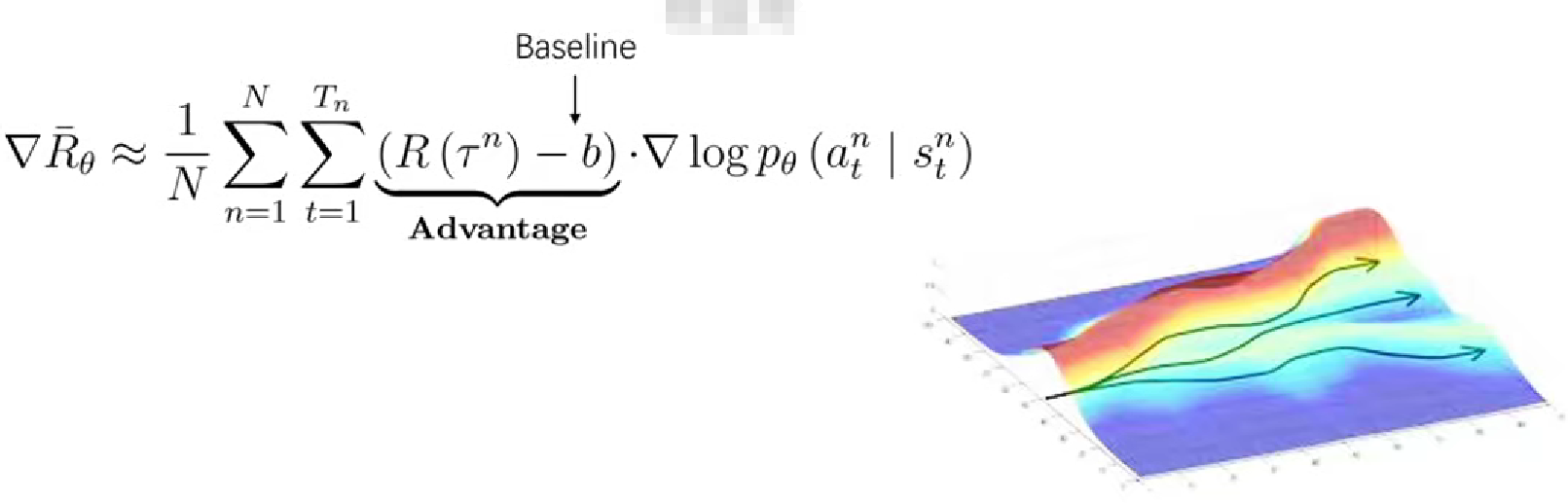
5.1 添加基线:如前所述,策略梯度的计算往往采样轨迹的方法。通过多条轨迹,也就是多次与环境的交互来收集数据,每条轨迹都会算出来一个梯度用来更新函数的参数,然而单条轨迹梯度可能存在高方差的问题,容易导致训练过程的不稳定,或者说收敛的速度比较慢。为了解决这个问题,引入所谓基线这一概念,就是在目标函数梯度中减去一个b,其中b代表baseline,b是一个相对奖励的参考值,因为他的波动范围相对来说更小,因此可以使训练过程更加稳定并且加快收敛速度。具体可以通过减去奖励均值,再除以方差来实现,这样可以将奖励调整为正态分布,从而使得梯度更新的尺度更加合适。![]() 这一项叫优势函数,某种程度上可以将优势函数视为价值函数在策略梯度算法中的一种变体。在强化学习中,价值函数通常在基于价值的方法,如动态规划、Q-Learring等中使用,来估计状态或者动作的价值来指导agent的决策。在策略梯度的方法当中,通常使用优势函数,不过这都属于价值评估的范畴。如果我们用便想边干来比喻强化学习过程的话,想就代表求价值,干就是求策略,优势函数就是属于想的这个范畴中。
这一项叫优势函数,某种程度上可以将优势函数视为价值函数在策略梯度算法中的一种变体。在强化学习中,价值函数通常在基于价值的方法,如动态规划、Q-Learring等中使用,来估计状态或者动作的价值来指导agent的决策。在策略梯度的方法当中,通常使用优势函数,不过这都属于价值评估的范畴。如果我们用便想边干来比喻强化学习过程的话,想就代表求价值,干就是求策略,优势函数就是属于想的这个范畴中。
5.2 改进二:Credit-Assignment功劳分配
在前面的目标函数当中,同一个episode中所有时间步的状态动作对使用同样的奖励来进行加权,这显然是不公平的,因为在同一个episode中有些动作是好的,有些动作是不好的,不应该公平对待。改进如下:在计算总回报的时候,只计算当前时刻之后的奖励,忽略之前的。还可以再未来奖励前加个折扣,让影响力计算更加合理,因为一般情况下,时间拖的越久,未来时刻对当前时刻的影响力就越小。因此γ随时间呈指数级的减小。
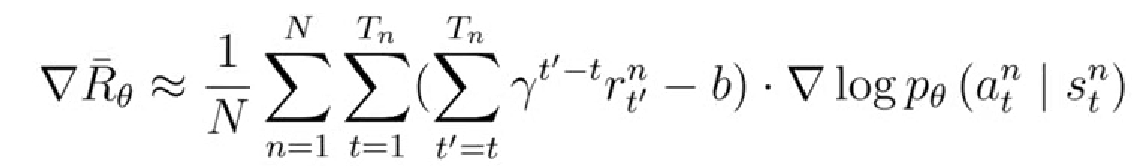
6. 策略梯度的适用条件和常见的应用场景
6.1 策略梯度方法可以处理连续的问题,而不需要对动作空间进行离散化。
6.2 适用于高纬度状态空间的问题,可以处理包含大量状态的环境。
6.3 通过参数化的策略函数,使得策略可以灵活调整和优化
在应用场景方面,策略梯度方法适用于各种强化学习任务,比如机器人控制、游戏等等。这些问题中往往都有连续动作空间,此外面对高纬度状态空间问题,图像处理任务,自然语言处理任务等,策略梯度表现出良好的适应性,还有就是策略梯度方法可以很好的应用于带有约束的优化问题。总的来说策略梯度方法相对于基于价值的方法更加灵活,特别是在连续动作空间和高纬度状态空间的情况下。
面临的挑战:梯度估计的方差问题和采样效率等等,在离散动作空间和低纬状态空间中基于价值的方法更具有优势。
二、蒙特卡洛策略梯度
在强化学习中提到蒙特卡洛一般就是指基于经验的学习方法,使用采样轨迹进行学习,而且通常是用完整的轨迹进行学习和估计。
1. 主要思想:蒙特卡洛策略梯度就是一种结合了蒙特卡洛学习和策略梯度的方法,通过采样轨迹,采用梯度上升法,更新参数,最大化累计奖励。
2. 模型结构
属于无环境模型,用神经网络逼近策略函数。选用回报,而非总回报表示价值。
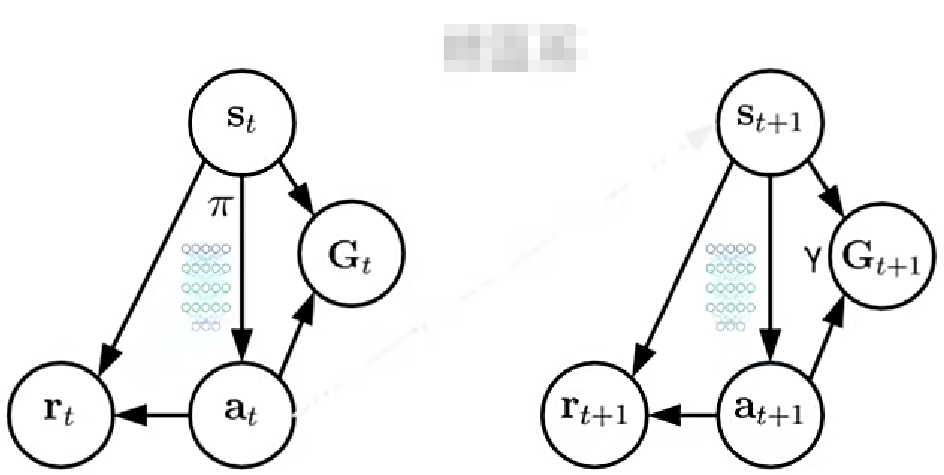
3. 概念对比

4. 目标函数:给定策略之后的累计期望
5. 适用条件
5.1 通常适用于离散空间的强化学习问题,不需要进行连续的动作选择。
5.2 不依赖环境模型的支持,而是通过环境模型的交互来收集经验的样本。
5.3 由于该方法使用完整的轨迹方法进行参数更新,进而可以处理高方差问题,更好地利用轨迹中的奖励信息
5.4 无需探索策略或探索率,因为可以通过与环境的交互来进行自然地探索,这使得他在探索利用平衡方面更加灵活。
三、近端策略优化算法(PPO)
Proximal Policy Optimization
1. 主要思想:
传统策略梯度方法是同策略的,有一些列显著的缺点:
采样效率低:每个样本只用于一次更新,用完就废掉,无法重复利用
方差大、收敛不稳定:受样本随机性和噪声的影响
难以探索新策略空间:只使用当前的采样数据,容易陷入局部最优
优点:异策略(off-policy)将采样与学习分离,数据复用,收敛性和稳定性更好
2. 前置知识
2.1 重要性采样(Importance Sampling)
是一种用于估计概率分布的统一方法,常常用于强化学习,概率推断和统计推断等领域,主要目的是用一个概率分布的样本来估计另一个概率的期望或者是累计的分布函数。比如:兄弟俩,其中有一个很神秘,不知道其连续分布长什么样。另外一个很熟悉,分布是已知的。两个人都可以采样,也就是说可以同时知道他们的一些具体的行为,比如他俩同时参加一次考试得到的分数,这样以来就能根据一个人的行为,再加上两个人在某些具体的事上的比值来估计另外一个人。
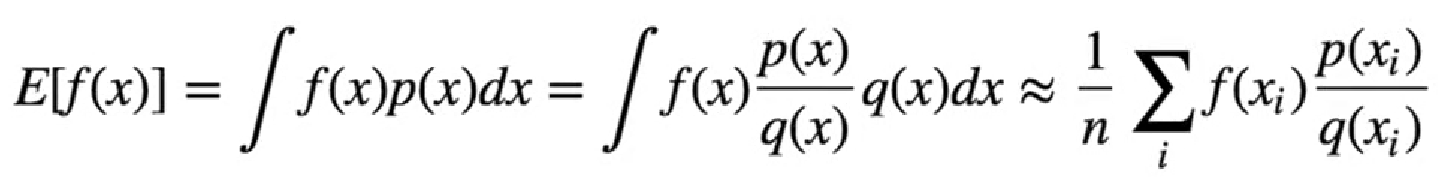
3. 目标函数
近端强调的就是KL项起到的约束作用。重要性采样+KL散度=PPO算法同策略到异策略的完美转换。其中KL散度是用来度量两种分布间相似程度的量,简单理解就是一个数值,约相似这个数值就约小。
4. 改进
4.1 改进一、自适应惩罚(PPO penalty)
在KL惩罚之前有个参数β,理想情况下是可以自适应调整的,用来实现动态惩罚的目的。具体调整如下:进一步前边的期望可以简化为一个求和的运算有两个原因,一是假定所有样本的概率相同。二是在求梯度的情况下除以样本数的意义也不是很大,去掉也不受影响。

4.2 PPO-clip
clip修剪:简化原有目标函数KL散度部分,提高运算效率。
5. 模型结构
重要性采样PPO和KL散度都是在修正或约束两个策略分布间相似度
其中虚线表示未知的目标策略,实线表示已知的采样策略
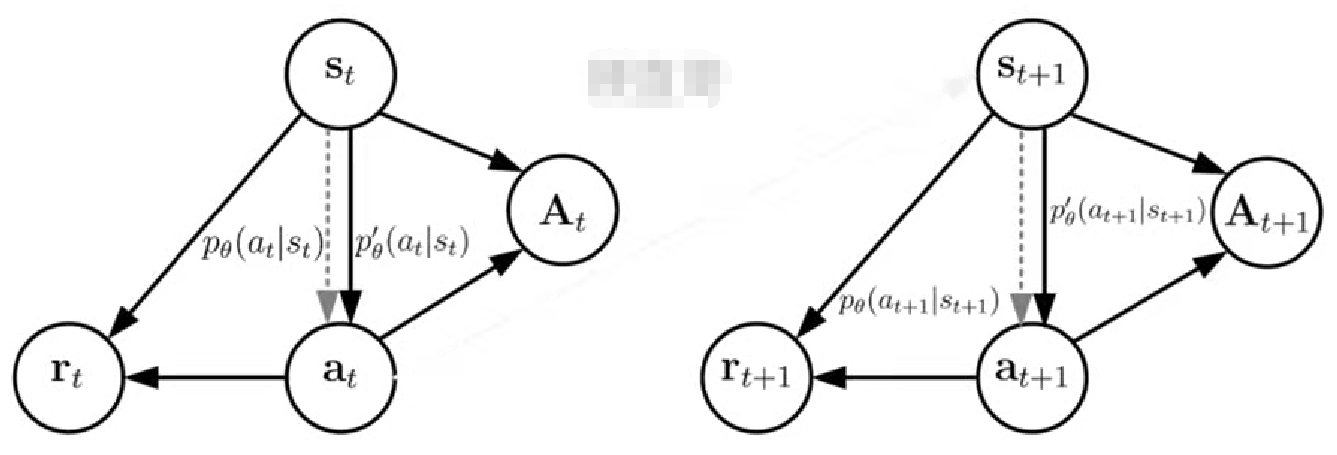
6. 适用条件:
6.1 在高纬度连续动作空间搜索最优策略的问题:机器人控制、自动驾驶等
6.2 适用于需要稳定收敛的任务:限制每次更新中策略改变幅度
6.3 大规模分布式训练:可以在多个并行训练实例上更新和采样