JVM——方法内联
引入
在现代软件开发中,性能优化始终是一个关键课题。随着硬件架构的不断演进,CPU的主频提升逐渐放缓,而软件复杂度却持续增加,这使得编译器优化技术的重要性日益凸显。方法内联(Method Inlining)作为编译器优化的核心手段之一,在提升程序执行效率、减少运行时开销方面发挥着至关重要的作用。
函数调用是程序执行的基本操作之一,但它本身存在不可忽视的开销。以Java语言为例,调用一个简单的getter方法时,程序需要完成以下步骤:保存当前方法的执行位置、创建并压入新的栈帧、传递参数、跳转至目标方法执行、弹出栈帧并恢复原方法执行。这些操作虽然在单次调用中微不足道,但在高频执行路径中(例如循环体内的方法调用),累计开销可能占据总执行时间的显著比例。根据二八原则,程序80%的执行时间往往集中在20%的热点代码上,因此对这些热点代码中的方法调用进行优化具有极高的性价比。
方法内联正是针对这一问题的解决方案。它通过将被调用方法的代码直接嵌入到调用处,消除了函数调用的开销,同时为后续的深度优化(如常量传播、死代码消除等)奠定了基础。
方法内联的基本概念与原理
定义与目标
方法内联是指在编译过程中,当遇到方法调用时,将目标方法的代码直接插入到调用处,取代原有的方法调用指令。这一过程通常由即时编译器(JIT Compiler)在运行时动态完成,其核心目标是:
-
消除函数调用开销:避免栈帧的创建、参数传递、跳转等操作,直接执行目标方法的代码。
-
触发后续优化:内联后,编译器可以在更大的代码范围内进行优化,例如将内联后的代码与调用方代码合并,进行全局常量传播、循环展开等。
以一个简单的Java代码为例:
public class Example {private static int add(int a, int b) {return a + b;}
public static int compute(int x, int y) {return add(x, y) + add(x, y);}
}内联前,compute方法两次调用add方法,每次调用都伴随栈帧操作。内联后,compute方法将被优化为:
public static int compute(int x, int y) {return (x + y) + (x + y);
}这不仅消除了两次函数调用的开销,还为后续的常量折叠(若x和y为常量)和代数化简(如合并同类项)创造了条件。
内联的收益与代价
方法内联的主要收益包括:
-
性能提升:减少函数调用开销,尤其是在高频调用场景下效果显著。
-
优化机会增加:内联后的代码为其他优化(如公共子表达式消除、循环优化)提供了更完整的上下文。
然而,内联也并非毫无代价:
-
代码膨胀:内联会导致生成的机器码体积增大,可能超出指令缓存的容量,反而降低性能。
-
编译时间增加:内联需要编译器解析目标方法的代码,并进行复杂的数据流分析,可能延长编译时间。
-
调试难度加大:内联后的代码结构变得复杂,难以直接对应到原始源代码,增加了调试的难度。
因此,编译器需要在性能提升与代码膨胀之间进行权衡,根据具体情况决定是否进行内联。
IR图分析:内联前后的代码结构变化
为了深入理解方法内联的实现机制,我们需要从编译器的中间表示(IR)层面进行分析。IR是编译器在优化阶段使用的代码抽象表示,它独立于具体的编程语言和目标平台,便于编译器进行各种优化操作。
方法内联的IR转换流程
在编译器中,方法内联的过程通常包括以下步骤:
-
解析调用点:编译器在编译调用方方法时,遇到方法调用指令,需要确定目标方法的具体实现。
-
生成目标方法的IR:编译器解析目标方法的字节码,生成其IR图。
-
合并IR图:将目标方法的IR图嵌入到调用方方法的IR图中,替换原有的调用指令。
-
调整参数和返回值:将目标方法的参数替换为调用方传递的实际参数,并处理返回值的传递。
-
处理异常和控制流:如果目标方法可能抛出异常,需要将异常处理逻辑与调用方的异常处理器连接。
下面以一个具体的例子来说明这一过程。假设我们有以下Java代码:
// 方法内联的过程
public static boolean flag = true;
public static int value0 = 0;
public static int value1 = 1;public static int foo(int value) {int result = bar(flag);if(result!=0){return result;} else {return value;}
}public static int bar(boolean flag) {return flag ? value0 : value1;
}
上面这段代码中的foo方法将接收一个int类型的参数,而bar方法将接收一个boolean类型的参数。其中,foo方法会读取静态字段flag的值,并作为参参数调用bar方法。
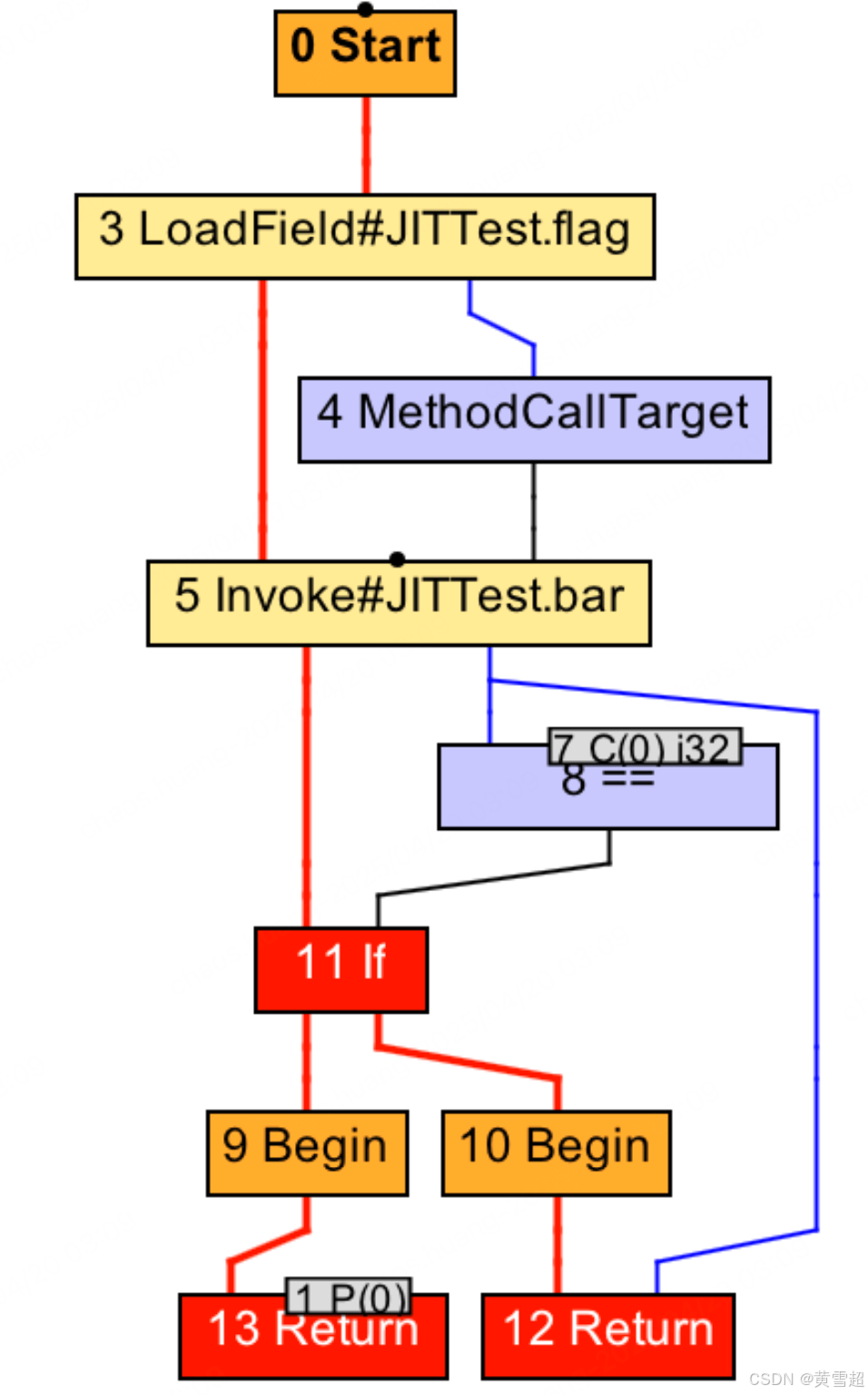
foo方法内联前的IR图分析
在foo方法的IR图中,当遇到bar(value)调用时,会生成一个Invoke节点,表示方法调用。该节点包含目标方法的符号引用、参数列表和返回值处理逻辑。如果内联算法判定应当内联对bar方法的调用时,那么即时编译器将开始解析bar方法的字节码,并生成对应的IR图,如下图所示。
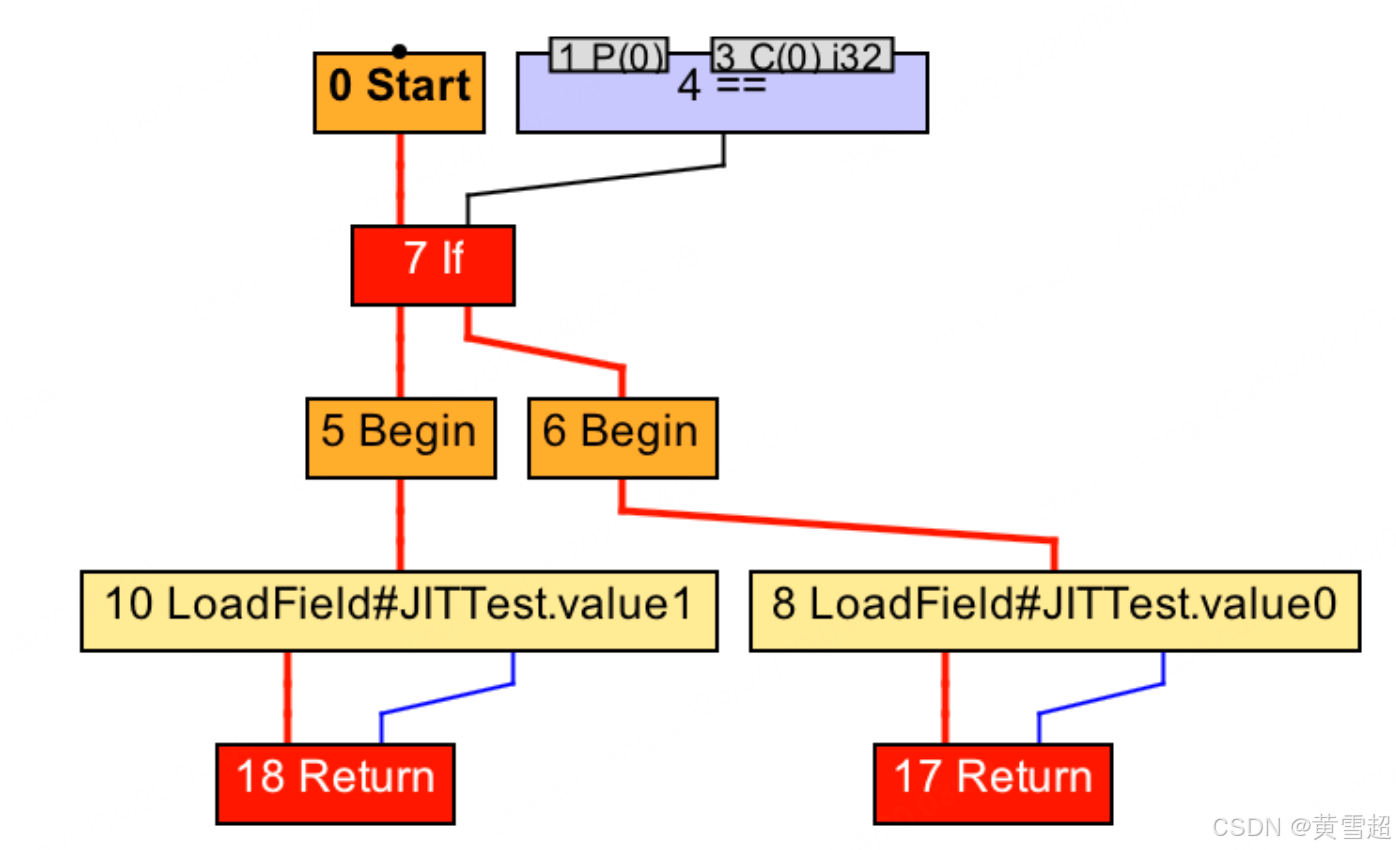
bar方法的IR图分析
接下来,即时编译器便可以进行方法内联,把bar方法所对应的IR图纳入到对foo方法的编译中。具体的操作便是将foo方法的IR图中5号Invoke节点替换为bar方法的IR图。
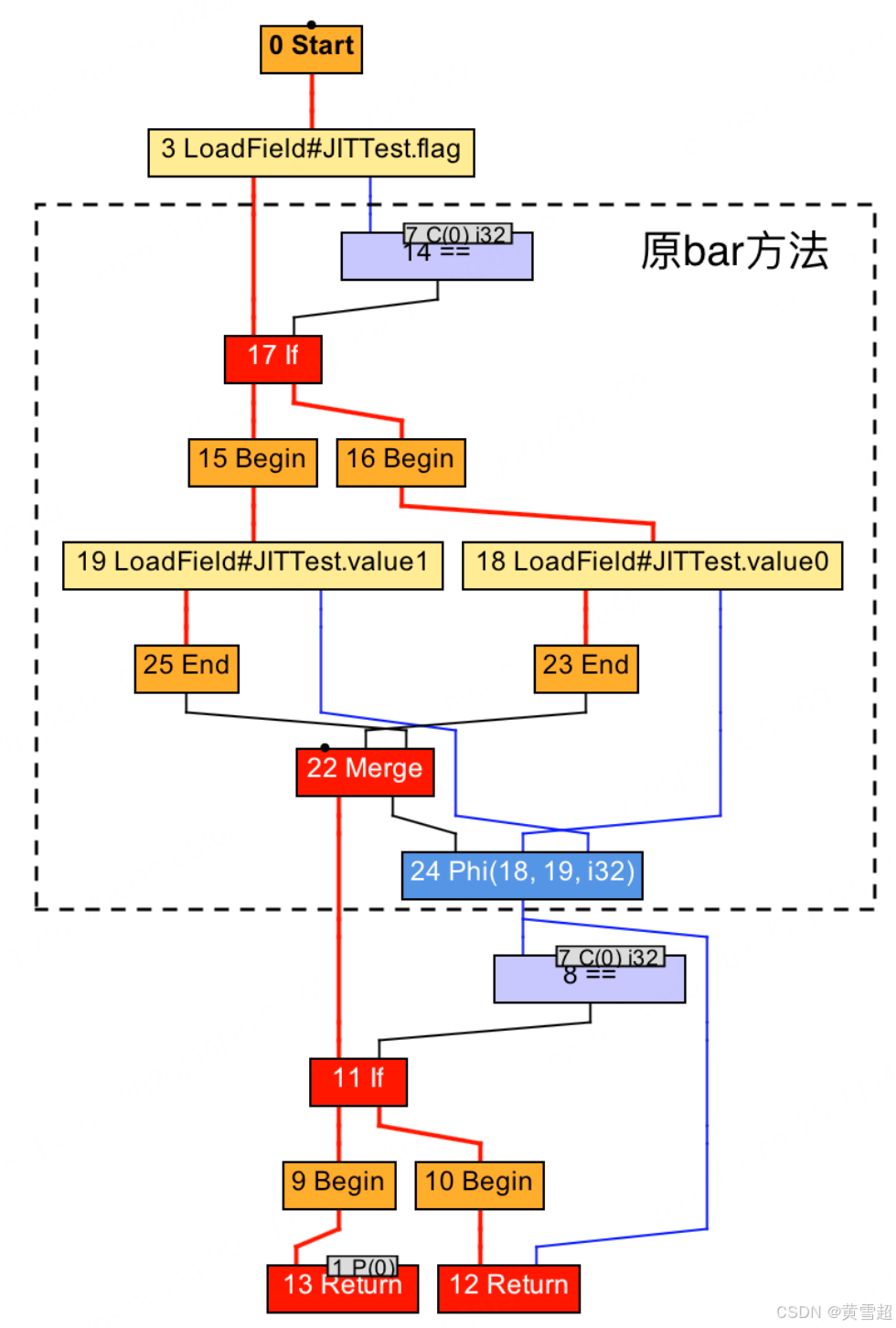
内联过程的三步核心操作
当编译器决定内联
bar到foo中时,会执行以下 IR 图变换:节点替换:Invoke 节点的展开
- 将 foo 的 5 号
Invoke节点替换为 bar 的完整 IR 图,包括条件判断、字段加载和返回逻辑。- 内联后,foo 的 IR 图包含 bar 的所有节点,形成一个融合的控制流图。
参数映射:输入输出的重定向
- 输入处理:bar 的参数节点
P(0)被替换为 foo 中的 3 号LoadField节点(即实际传入的flag值),确保参数传递的正确性。- 输出处理:若 bar 有多个返回路径(如异常或正常返回),编译器会生成
Phi节点(如 24 号节点),聚合所有可能的返回值,维持数据流的一致性。异常处理:路径连接与假设注册
- 若 bar 可能抛出异常且 foo 包含对应的异常处理器,编译器会将异常抛出节点与 foo 的处理器直接连接,避免运行时的异常栈回溯。
- 对于无异常的简单情况(如本例),则直接省略异常处理逻辑,简化 IR 图结构。
foo方法内联后的IR图分析
除了将被调用方法的IR图节点复制到调用者方法的IR图中,即时讨编译器还需额外完成下述三项操作:
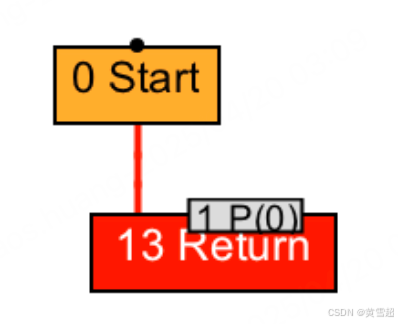
- 被调用方法的传入参数节点,将被替换为调用者方法进行方法调用时所传入参数对应 的节点。在我们的例子中,就是将 bar 方法 IR 图中的 1 号 P(0) 节点替换为 foo 方法 IR 图中的 3 号 LoadField 节点。
- 在调用者方法的 IR 图中,所有指向原方法调用节点的数据依赖将重新指向被调用方 法的返回节点。如果被调用方法存在多个返回节点,则生成一个 Phi 节点,将这些返回值聚合起来,并作为原方法调用节点的替换对象。
在我们的例子中,就是将 8 号 == 节点,以及 12 号 Return 节点连接到原 5 号 Invoke 节 点的边,重新指向新生成的 24 号 Phi 节点中。 - 如果被调用方法将抛出某种类型的异常,而调用者方法恰好有该异常类型的处理器,并且该异常处理器覆盖这一方法调用,那么即时编译器需要将被调用方法抛出异常的路径,与调用者方法的异常处理器相连接。
经过方法内联之后,即时编译器将得到一个新的 IR 图,并且在接下来的编译过程中对这个新的 IR 图进行进一步的优化。
不过在上面这个例子中,方法内联后的 IR 图并没有能够进一步优化的地方。
内联后的 IR 图优化方案
不过,如果我们将代码中的三个静态字段标记为 final,那么 Java 编译器(注意不是即时编译器)会将它们编译为常量值(ConstantValue),并且在字节码中直接使用这些常量值, 而非读取静态字段。
简单说,就是当flag、value0、value1被标记为final时,Java 编译器会将其编译为常量,即时编译器进一步优化。
在编译 foo 方法时,一旦即时编译器决定要内联对 bar 方法的调用,那么它会将调用 bar 方法所使用的参数,也就是常数 1,替换 bar 方法 IR 图中的参数。经过死代码消除之后, bar 方法将直接返回常数 0,所需复制的 IR 图也只有常数 0 这么一个节点。
经过方法内联之后,foo 方法的 IR 图将变成如下所示:
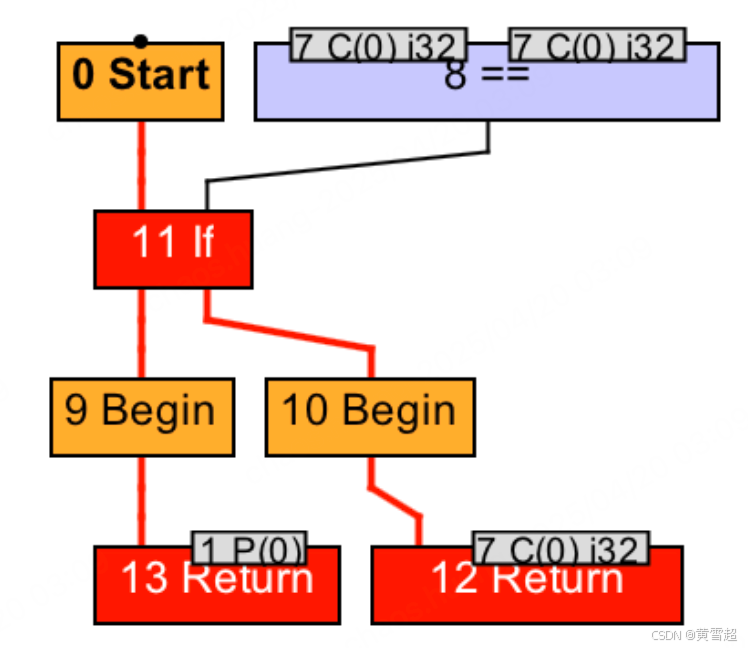
该 IR 图可以进一步优化(死代码消除),并最终得到这张极为简单的 IR 图:
IR图的实现细节
在现代编译器(如HotSpot的C2编译器)中,IR图通常采用Sea-of-Nodes结构,这是一种基于静态单赋值(SSA)形式的IR表示。在这种结构中,每个节点代表一个值,边表示数据依赖关系,控制流通过条件分支和Phi节点(用于处理不同路径的值合并)来表示。
以bar方法的IR图为例,内联后的节点替换过程如下:
-
参数替换:将
bar方法的参数节点(如P(0))替换为foo方法传递的实际参数节点(如LoadField节点)。 -
返回值处理:将
bar方法的返回节点连接到foo方法中调用点的后续逻辑。如果bar方法有多个返回路径,编译器会生成一个Phi节点来合并这些路径的返回值。 -
异常处理:如果
bar方法可能抛出异常,编译器需要将异常抛出路径与foo方法的异常处理器连接,确保异常能够被正确捕获和处理。
通过这种方式,内联后的IR图将调用方和被调用方的代码合并为一个连续的执行序列,消除了方法调用的开销,并为后续优化提供了更完整的上下文。
方法内联的条件:编译器的权衡与策略
即时编译器不会无限制内联,而是通过一系列规则和参数平衡性能与编译成本,以下是核心条件:
强制规则:显式控制内联
强制内联:通过-XX:CompileCommand=inline指令或@ForceInline注解(仅限 JDK 内部方法)指定必须内联的方法。
强制不内联:-XX:CompileCommand=dontinline或@DontInline注解可阻止特定方法被内联。
方法特征限制
字节码大小:非热点方法字节码超过-XX:MaxInlineSize(默认 35 字节)则不内联;热点方法(调用次数超过-XX:InlineFrequencyCount)阈值放宽至-XX:FreqInlineSize(默认 325 字节)。
调用层数:C2 不支持超过 9 层的嵌套内联(-XX:MaxInlineLevel),直接递归调用限制为 1 层(-XX:MaxRecursiveInlineLevel)。
运行时状态检查
类加载状态:目标方法所在类未初始化、符号引用未解析或为native方法时,无法内联。
Code Cache 容量:生成的机器码若超过-XX:ReservedCodeCacheSize限制,会触发 “Code Cache 已满” 警告,停止内联。
关键参数表
| 参数名 | 默认值 | 说明 |
|---|---|---|
-XX:InlineSmallCode | 2000 | 已编译方法机器码超过此值则不内联 |
-XX:MaxTrivialSize | 6 | 字节码小于此值的方法直接内联(如简单的 getter/setter) |
-XX:MinInliningThreshold | 250 | 调用次数低于此值的方法不内联(热点检测阈值) |
-XX:LiveNodeCountInliningCutoff | 40000 | IR 节点数超过此值则停止内联(防止 IR 图爆炸) |
现代编译器中的方法内联实现
HotSpot虚拟机的分层编译策略
HotSpot虚拟机采用分层编译(Tiered Compilation)策略,结合了解释执行和即时编译的优势:
-
第0层:纯解释执行,不开启性能监控。
-
第1层(C1编译器):快速编译,进行简单优化(如方法内联),并加入性能监控。
-
第2层(C2编译器):深度优化,采用激进的优化手段(如方法内联、循环展开、逃逸分析等)。
在分层编译中,方法内联主要由C2编译器完成。C2在解析字节码时遇到方法调用指令,会根据内联条件决定是否内联目标方法。如果内联成功,目标方法的IR图将被嵌入到调用方方法的IR图中,随后进行进一步的优化。
LLVM的内联策略
LLVM编译器框架采用模块化设计,其优化器(LLVM IR Optimizer)支持多种内联策略:
-
静态内联:在编译时根据函数大小、调用频率等静态信息决定是否内联。
-
动态内联:在运行时根据实际调用频率动态调整内联决策,生成内联和非内联两个版本的代码,根据运行时条件选择执行。
LLVM的内联策略高度灵活,允许开发者通过-inline和-noinline等编译选项手动控制内联行为。此外,LLVM还支持链接时优化(Link-Time Optimization,LTO),可以在链接阶段进行跨模块的方法内联,进一步提升优化效果。
其他编译器的内联实现
-
GCC:GCC通过
-finline-functions和-finline-functions-called-once等选项控制内联行为,默认根据函数大小和调用频率进行内联。 -
Graal编译器:Graal是OpenJDK 10引入的实验性编译器,采用与C2类似的内联策略,但支持更灵活的优化阶段和更复杂的数据流分析。
方法内联的实际应用与调优
代码编写建议
为了充分利用方法内联优化,开发者在编写代码时应注意以下几点:
-
保持方法短小:避免编写大型方法,尤其是在高频执行路径中。
-
使用合适的修饰符:对于不需要多态的方法,尽量使用
private、static或final修饰,以提高内联成功率。 -
避免虚方法调用:在性能敏感的代码中,优先使用非虚方法或通过接口明确方法实现。
-
减少副作用:避免在方法中修改全局状态,以降低内联的复杂性。
JVM参数调优
HotSpot虚拟机提供了丰富的参数来控制方法内联行为,以下是一些常用参数:
-
-XX:+PrintInlining:打印内联详情,需配合-XX:+UnlockDiagnosticVMOptions使用。 -
-XX:MaxInlineSize:非热点方法的最大内联字节码大小,默认35字节。 -
-XX:FreqInlineSize:热点方法的最大内联字节码大小,默认325字节。 -
-XX:MaxInlineLevel:内联的最大调用层数,默认9层。 -
-XX:MaxRecursiveInlineLevel:递归调用的最大内联层数,默认1层。
通过调整这些参数,可以根据具体应用场景优化内联策略。例如,对于内存受限的嵌入式系统,可以适当降低MaxInlineSize以减少代码膨胀;对于计算密集型应用,可以增加FreqInlineSize以允许更大的方法被内联。
性能监控与分析
为了验证方法内联的效果,开发者可以使用以下工具和方法:
-
JVM日志分析:通过
-XX:+PrintCompilation和-XX:+PrintInlining参数输出编译和内联日志,分析哪些方法被内联,哪些未被内联及其原因。 -
性能分析工具:使用
perf、JProfiler等工具分析程序的热点代码,确定内联优化的重点区域。 -
反汇编工具:通过
hsdis等工具查看生成的汇编代码,确认方法调用是否被内联,以及内联后的代码结构。
总结
方法内联作为编译器优化的核心技术,通过消除函数调用开销和触发后续优化,显著提升了程序的执行效率。然而,其效果受到方法大小、调用频率、代码结构等多种因素的制约,需要编译器在性能提升与代码膨胀之间进行精细权衡。
我们需要深入理解方法内联的原理和实现机制,合理编写代码并利用编译器的优化选项,才能充分发挥这一技术的优势,提升程序的性能和可维护性。
随着硬件架构的不断演进(如多核处理器、向量指令集的普及)和软件复杂度的持续增加,方法内联的重要性将进一步凸显。未来,编译器可能会结合机器学习和人工智能技术,实现更智能的内联决策,例如根据历史执行数据预测内联效果,动态调整内联策略。此外,跨语言内联(如Java与C++代码的内联)和动态内联(如运行时根据输入数据调整内联行为)等新技术也将成为研究热点。