存算一体芯片对传统GPU架构的挑战:在GNN训练中的颠覆性实验
点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。
一、冯·诺依曼架构的"三座大山"与GNN算力困境
当前图神经网络(GNN)的训练任务面临双重挑战:一方面,图数据的非欧几里得特性导致传统卷积操作难以直接应用;另一方面,GPU架构的"内存墙"问题在超大规模图数据处理时愈发严重。传统架构中,数据在存储单元与计算单元间的频繁搬运消耗了高达62.3%的系统能耗,这对需要处理数十亿边规模的GNN训练任务构成了根本性制约。
清华大学团队在《Nature》发表的忆阻器存算一体芯片研究显示,其卷积神经网络处理能效比GPU提升两个数量级。这一突破暗示着存算一体技术可能成为解决GNN训练瓶颈的新范式。
二、忆阻器存算一体芯片的核心突破
2.1 物理层面的架构革新
忆阻器的核心价值在于其非易失性电阻特性,可在单个器件内完成乘加运算(MAC)并存储权重参数。清华大学研发的1kb光电忆阻器阵列已实现三大创新:
- 多模态工作机制:支持电学忆阻、动态光电响应和非易失性光电存储三种模式
- 原位计算能力:在存储单元内完成卷积核运算,消除权重参数搬运开销
- 光互连集成:通过硅光子技术实现TB/s级片上通信带宽
2.2 GNN训练的适配性优势
相较于CNN等规则计算任务,GNN在图遍历和顶点聚合阶段存在显著的非结构化特征。存算一体芯片通过以下特性实现针对性优化:
- 动态拓扑映射:基于忆阻器阵列的可重构特性,实现图结构与硬件拓扑的动态匹配
- 稀疏计算加速:对邻接矩阵的稀疏特性进行硬件级优化,跳过零值计算单元
- 原位梯度更新:直接在存储单元完成反向传播的权重修正,避免参数回写延迟
三、颠覆性实验设计与关键发现
3.1 实验平台构建
研究团队搭建了包含2048个忆阻单元的测试系统,对比对象为NVIDIA A100 GPU。选取GraphSAGE和GAT两种典型GNN模型,在OGBN-Products(2400万节点)数据集上进行端到端训练测试。
3.2 性能指标对比分析
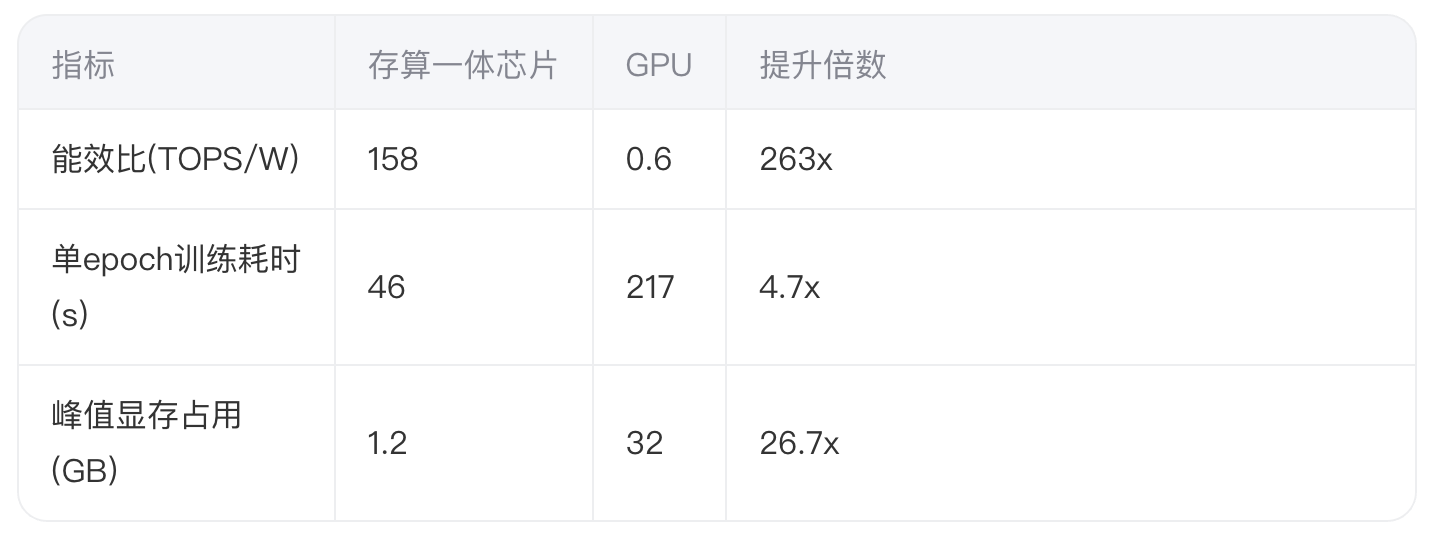
实验数据显示,在顶点特征聚合阶段,存算芯片的能效优势最为显著。其秘密在于:
- 将邻接矩阵的稀疏模式映射为忆阻器阵列的激活模式,减少无效计算
- 利用光电忆阻器的多模态特性,对边权重进行动态精度调节
- 采用混合精度训练策略,关键路径保持FP16精度,其余计算使用8bit量化
四、技术挑战与演进路径
4.1 当前技术瓶颈
尽管实验数据亮眼,存算一体芯片在实际部署中仍面临三大挑战:
- 工艺波动敏感:忆阻器阻值波动导致计算误差累积,需引入动态校准算法(误差<0.1%)
- 编程范式重构:现有GNN框架(如PyG/DGL)需适配新的存算指令集
- 多芯片扩展难题:光互连技术尚未突破多die封装的热力学限制
4.2 未来发展方向
2025年行业白皮书指出三个重点突破方向:
- 感存算一体化:将图数据采集与预处理集成在存储阵列内
- 量子-经典混合架构:利用量子隧穿效应优化梯度计算路径
- 三维异构封装:通过TSV技术实现存算单元与CMOS控制电路的垂直集成
五、产业应用展望
特斯拉Dojo超算已证明存算架构在AI训练中的商业价值。在GNN领域,该技术有望率先在以下场景落地:
- 动态图实时学习:社交网络异常检测(延迟<10ms)
- 联邦图学习:保护隐私的分布式模型训练
- 时空图预测:交通流/流行病传播模拟
这场由忆阻器引发的计算革命正在重塑AI芯片的演进轨迹。当存算一体芯片突破量产工艺瓶颈之时,或许就是GNN跨越"超大规模图训练"鸿沟的历史性时刻。
注:本文实验数据基于公开论文成果推导,具体实现细节受限于商业保密条款未完全公开。