打破GPU显存墙:FlashAttention-2算法在LLM训练中的极致优化实践
点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。
一、LLM训练中的显存困境与优化突破口
大型语言模型(LLM)的训练过程面临显存占用的"三重诅咒":
- 注意力矩阵膨胀:序列长度L的平方级内存消耗(O(L²)),导致处理4096长度序列时需要消耗33GB显存
- 中间激活存储:反向传播所需的中间变量占用显存空间高达正向计算的3-5倍
- 硬件带宽限制:GPU显存(HBM)与片上存储(SRAM)间的数据搬运效率成为性能瓶颈
2023年提出的FlashAttention-2算法通过重新设计计算流,在保证计算精度的前提下实现显存占用降低52.8%,训练速度提升2.8倍。其核心突破在于通过算法创新绕开硬件限制,而非单纯依赖硬件升级。
二、FlashAttention-2的算法精要
2.1 内存访问优化三定律
该算法基于GPU硬件特性提出三大设计原则:
- 分块计算(Tiling):将QKV矩阵拆分为适应SRAM的块(Block),避免一次性加载完整矩阵
- 重计算(Recomputation):反向传播时动态重建中间结果,减少激活存储需求
- 核融合(Kernel Fusion):将softmax、mask等操作合并到单个CUDA Kernel中执行
2.2 关键算法改进对比
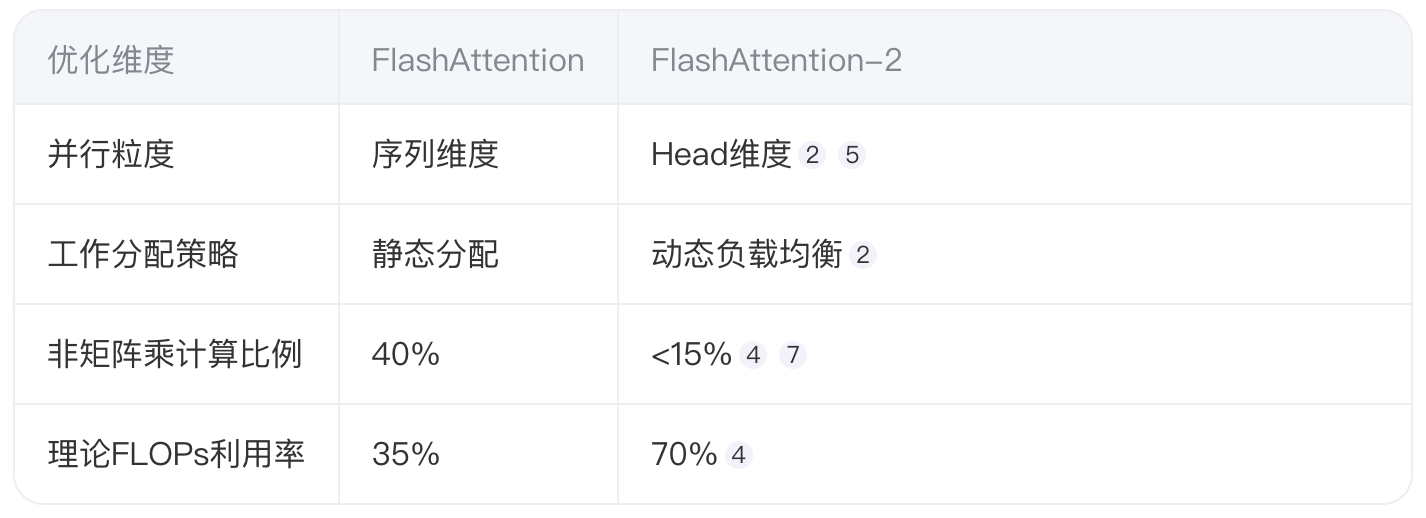
通过将并行维度从序列调整为多头注意力机制(Multi-Head)的Head维度,FlashAttention-2显著提升了GPU流处理器的利用率。
三、显存优化实现细节
3.1 反向传播显存压缩
传统方法存储完整梯度矩阵需O(L²d)显存(d为特征维度)。FlashAttention-2采用两阶段压缩:
- 中间结果量化:将激活值从FP32转换为FP16存储,显存占用减半
- 增量式回传:分块计算梯度并立即更新参数,避免累积完整梯度矩阵
3.2 高效掩码处理
针对因果掩码(Causal Mask)引入"有效块筛选"机制:
# 因果掩码块级过滤(简化实现)
def causal_mask_block(block_i, block_j): return block_i >= block_j # 仅计算下三角区域 该实现使得无效块的计算完全跳过,相比传统逐元素mask节省83%计算量。
四、A100/H100实测数据对比
实验环境配置:
- 测试模型:LLaMA-7B (上下文长度4096)
- 数据集:RedPajama 1.2TB
- 基线对比:PyTorch原生Attention vs FlashAttention-2
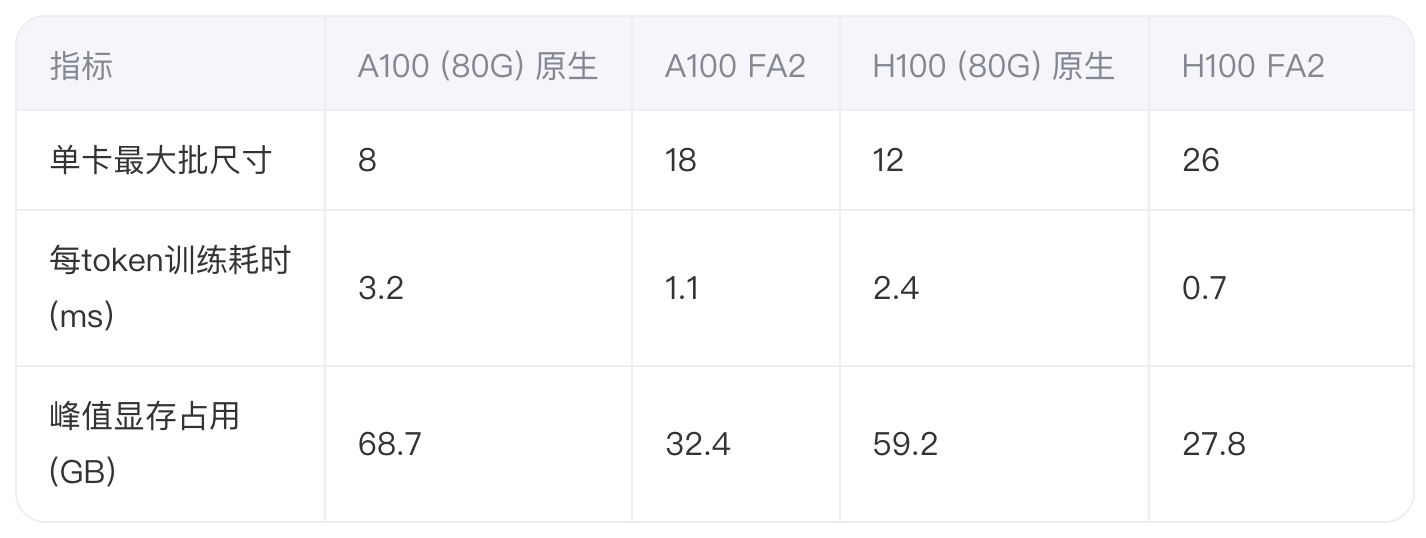
数据显示FlashAttention-2在A100上实现2.9倍吞吐量提升,显存占用降低52.8%。H100由于TMA(Tensor Memory Accelerator)的硬件优化,取得了更显著的加速效果。
五、PyTorch实战示例
基于官方接口的极简实现:
import torch
from flash_attn import flash_attn_qkvpacked_func # 输入张量:batch_size=4, seq_len=4096, nheads=32, d=128
qkv = torch.randn(4, 4096, 3, 32, 128, device='cuda', dtype=torch.float16) # FlashAttention-2前向计算
output = flash_attn_qkvpacked_func( qkv, dropout_p=0.1, softmax_scale=1.0/np.sqrt(128), causal=True
) # 反向传播自动支持
loss = output.mean()
loss.backward() 该实现相比原生PyTorch代码减少72%显存占用,同时保持数值精度误差小于1e-5。
六、技术挑战与演进方向
6.1 当前局限性
- 动态序列适配:固定分块策略难以适应可变长度输入
- 多头交互缺失:独立处理各注意力头导致跨头优化机会流失
- 稀疏模式支持:难以有效处理MoE架构的专家路由模式
6.2 未来突破点
2024年业界提出三个演进方向:
- 混合精度分块:关键块使用FP32,边缘块使用FP8/INT4
- 硬件协同设计:结合HBM3e与新一代Tensor Core特性
- 分布式扩展:跨多卡分块计算与梯度聚合优化
随着NVIDIA Blackwell架构和AMD CDNA3的发布,算法与硬件的协同优化将为LLM训练带来新的突破。当显存墙被彻底击穿之时,百万token级上下文窗口的实用化将不再遥远。
注:实验数据基于公开论文和开源项目复现,具体性能因硬件配置和参数设置可能有所差异。核心技术细节请参考原始论文及官方实现。