字节后端开发一面面经
哪些方案可以避免流量高峰造成的问题
- 消息队列削峰填谷
- 缓存预热
- 负载均衡,分散请求
- 限流和降级
了解常用的限流或者降级的算法嘛?描述一下原理?
固定窗口计数器:按照时间段划分窗口,有一次请求就+1,最为简单的算法,但是限流不够平滑且无法应对突然激增的流量。
滑动窗口计数器:通过将窗口再细分,并且按照时间“滑动”来解决突破限制的问题,但是时间区间的精度越高,算法所需的空间容量就越大。
漏桶:请求类似水滴,先放到桶里,服务的提供方则按照固定的速率从桶里面取出请求并执行。缺陷也很明显,当短时间内有大量的突发请求时,即便此时服务器没有任何负载,每个请求也都得在队列中等待一段时间才能被响应。
**令牌桶:**往桶里面发放令牌,每个请求过来之后拿走一个令牌,然后只处理有令牌的请求。令牌桶满了则多余的令牌会直接丢弃。令牌桶算法既能够将所有的请求平均分布到时间区间内,又能接受服务器能够承受范围内的突发请求,因此是目前使用较为广泛的一种限流算法。
滑动窗口相对固定窗口算法解决了什么问题?
相比于固定窗口算法,滑动窗口计数器算法可以应对突然激增的流量。
滑动窗口算法相对于固定窗口算法,解决了以下几个问题:
1. 更平滑的流量控制
-
固定窗口:
- 在每个时间窗口内,流量会突然重置,可能导致在窗口边界处出现突发流量(bursting),从而导致系统过载。
-
滑动窗口:
- 通过在每个时间点都监测请求,流量控制更加平滑,避免了窗口边界的突发流量。
2. 更精确的请求计数
-
固定窗口:
- 只统计每个固定时间段内的请求总数,无法对请求的时间分布进行细致分析。
-
滑动窗口:
- 可以精确到每个时间点,允许更细粒度的流量控制,提高了系统的适应性。
3. 避免过度限制
-
固定窗口:
- 可能会因为某些请求在窗口的开始位置被限制,而在窗口结束时又可以大量请求,导致不合理的请求限制。
-
滑动窗口:
- 允许在整个时间范围内分布请求,减少了对正常流量的过度限制。
总结
滑动窗口算法通过动态监测和灵活的时间窗口设计,解决了固定窗口算法在流量控制中的突发性和不精确性问题,使得系统能够更平稳、合理地处理请求。
进程和线程的区别
进程是操作系统资源分配的基本单位,线程是cpu调度的基本单位。进程是一个程序的动态运行实例,而线程是进程当中的一条执行流程。进程包含多个线程,线程从属于一个进程;各进程间相互独立,但线程不一定,同一个进程的多个线程可能相互影响。进程切换的开销显著高于线程切换。
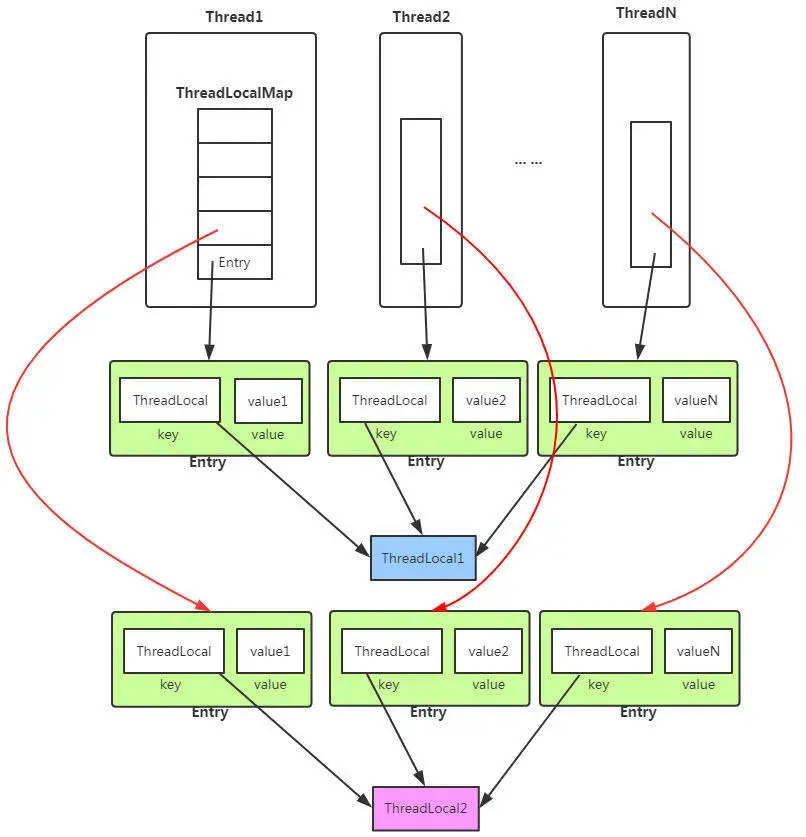
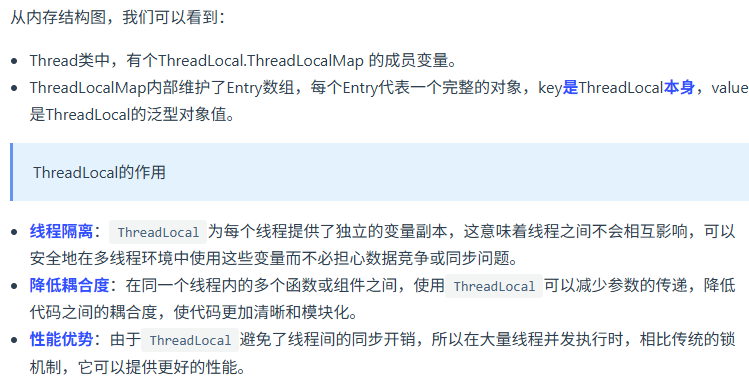
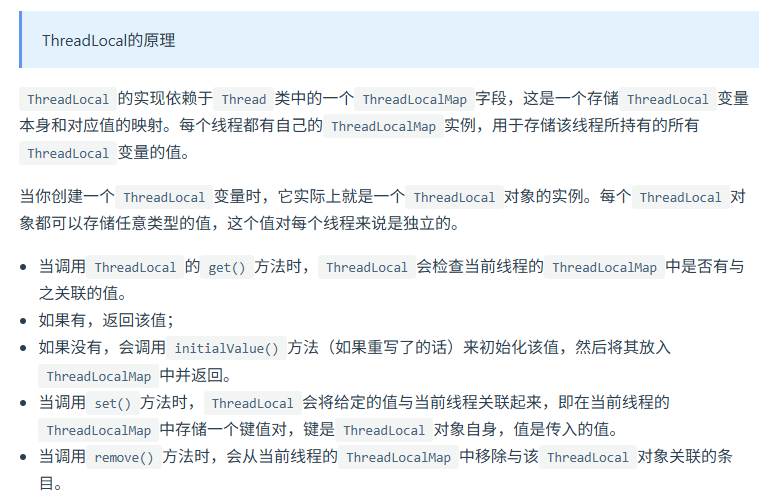
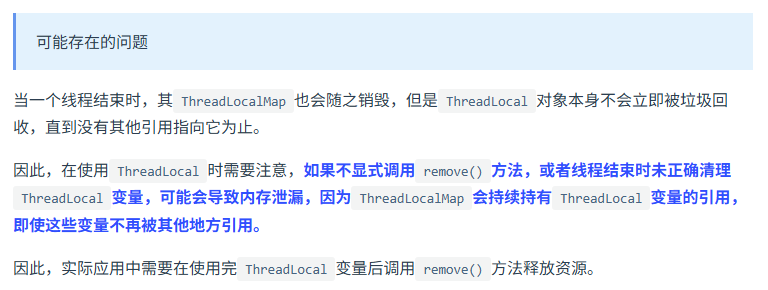
threadlocal的原理
就是线程本地变量,如果创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的一个本地拷贝,多个线程操作这个变量的时候,实际是操作自己本地内存里面的变量,从而起到线程隔离的作用,避免了线程安全问题。ThreadLocal的底层数据建构就是ThreadLocalMap,它的key就是ThreadLocal的引用,值就是Object对象。

用户的请求进来,用户的信息怎样在一个请求内传递?
- 请求头
- 请求体
- url参数
- 上下文
- session
- 中间件
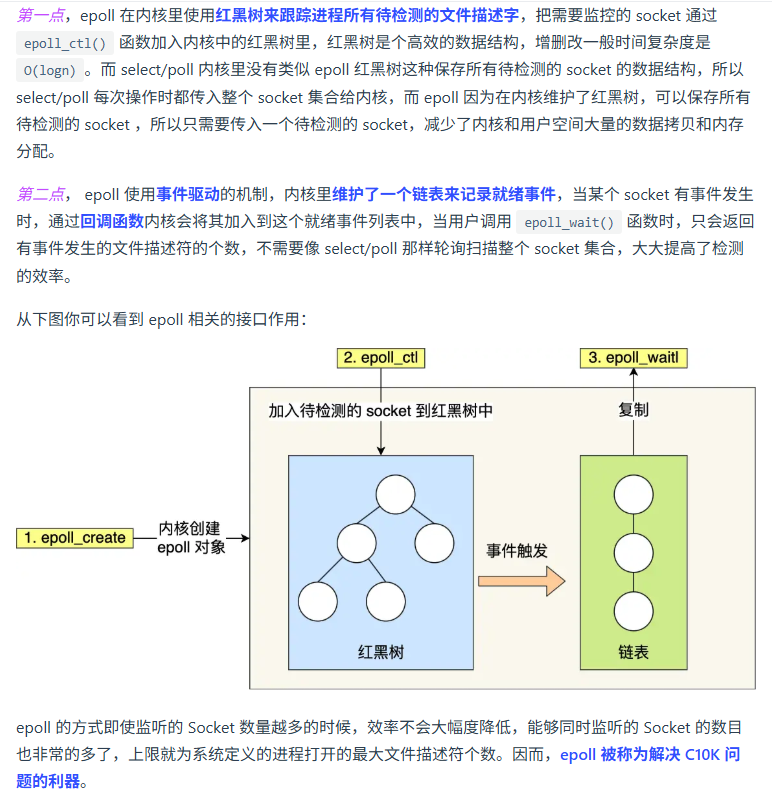
epoll 多路复用

介绍一下rpc和http在使用场景上的区别
rpc通常使用在分布式系统、跨语言调用、高性能服务中。http通常使用在网页浏览、RESTful API、文件下载等
流量可以通过不同的协议和方式进入系统,主要有以下两种:
1. HTTP 流量
- 描述: HTTP 流量通常用于 Web 应用程序和 RESTful API。用户通过浏览器或其他客户端发送 HTTP 请求。
- 特点:
- 无状态:每个请求独立,服务器不保存状态。
- 适合于浏览器交互和标准的 API 接口。
2. RPC 流量
- 描述: RPC(远程过程调用)流量用于服务间通信,通常在微服务架构中使用。常见的 RPC 框架有 gRPC、Thrift 等。
- 特点:
- 状态保持:可以更高效地处理复杂数据类型和方法调用。
- 适合于服务间的内部通信,通常性能更高。
总结
- HTTP 流量: 适合外部用户请求和 RESTful API。
- RPC 流量: 适合服务间的高效通信。
选择使用哪种方式取决于具体的应用场景和需求。
用rpc代替http会有什么问题?
使用 RPC 代替 HTTP 可能会导致以下几个问题:
1. 兼容性问题
- 客户端支持: 不是所有客户端都支持 RPC 协议,特别是浏览器。HTTP 是 web 的标准,广泛支持。
- 跨语言支持: HTTP 更加通用,RPC 可能需要特定的库和工具链,增加了兼容性问题。
2. 网络安全
- 安全性: HTTP 在传输层的安全性(如 HTTPS)得到广泛应用,RPC 框架可能需要额外的安全措施。
- 认证和授权: HTTP 生态系统中有成熟的认证机制(如 OAuth),RPC 可能需要重新实现。
3. 调试和监控
- 可视化工具: HTTP 流量可以使用浏览器开发者工具进行调试,RPC 的调试工具可能不够成熟,增加了调试难度。
- 可读性: HTTP 请求和响应是文本格式,容易理解,RPC 可能使用二进制格式,不易直接查看。
4. 学习曲线
- 复杂性: RPC 架构通常比 HTTP 更复杂,开发团队需要掌握新的协议和工具,增加了学习成本。
5. 服务发现和负载均衡
- 实现复杂性: 使用 RPC 时,服务发现和负载均衡的实现可能更复杂,尤其是在微服务架构中。
总结
虽然 RPC 在某些场景下提供了更高效的服务间通信,但在替代 HTTP 时,需要解决兼容性、安全性、调试等多个问题,确保系统的可维护性和可扩展性。
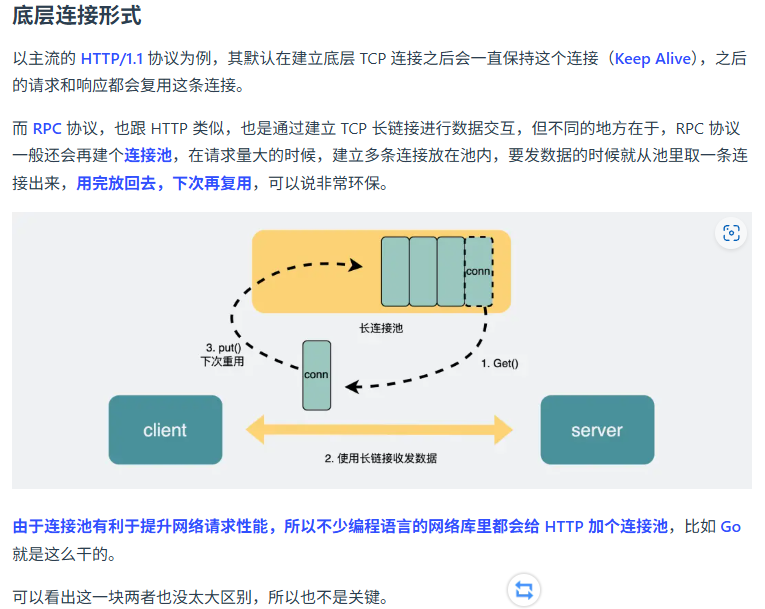
http底层连接可以基于连接池嘛
是的,HTTP 底层连接可以基于连接池。使用连接池可以显著提高性能和资源利用效率。以下是关于 HTTP 连接池的一些要点:
1. 连接复用
- 连接池允许复用已有的连接,避免频繁建立和关闭连接的开销。
- 在 HTTP/1.1 中,连接复用(Keep-Alive)使得在同一 TCP 连接上可以发送多个请求。
2. 降低延迟
- 连接池减少了连接建立时间,从而降低请求的延迟,提升了响应速度。
3. 资源管理
- 通过连接池,可以有效管理系统资源,控制最大连接数,避免资源耗尽。
4. 实现方式
- 许多 HTTP 客户端库(如 Go 的
http.Client、Java 的HttpClient)都内置了连接池机制。 - 开发者可以根据需求配置连接池的参数,如最大连接数、超时时间等。
5. 示例
在 Go 中,可以使用 http.Client 来自动管理连接池:
client := &http.Client{Transport: &http.Transport{MaxIdleConns: 100, // 最大空闲连接数IdleConnTimeout: 90, // 空闲连接的超时时间MaxIdleConnsPerHost: 10, // 每个主机的最大空闲连接数},
}
总结
HTTP 连接池通过复用连接和管理资源,提高了系统的性能和响应速度,是现代 HTTP 客户端的重要特性。


红黑树相对于普通的树有哪些特征?通常用来解决什么问题?
红黑树的特征
红黑树是一种自平衡的二叉搜索树,具有以下特征:
节点颜色:每个节点要么是红色,要么是黑色。
根节点:根节点总是黑色。
叶子节点:叶子节点(NIL节点,即空节点)是黑色。
红色节点的子节点:如果一个节点是红色,则它的两个子节点都是黑色(即没有两个连续的红色节点)。
黑色高度:从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
这些特征确保了红黑树在插入、删除和查找操作时能够保持相对平衡,从而保证操作的时间复杂度为O(log n)。
红黑树的应用
高效查找:红黑树是一种二叉搜索树,支持高效的查找操作,时间复杂度为O(log n)。
动态数据集合:红黑树支持高效的插入和删除操作,适用于需要频繁更新数据的场景。
有序数据存储:红黑树可以保持数据的有序性,适用于需要按顺序访问数据的场景。
实现关联容器:许多编程语言的标准库(如C++的std::map和std::set)使用红黑树来实现关联容器,以提供高效的键值对存储和查找。
红黑树的优势
自平衡:红黑树通过颜色和旋转操作自动保持平衡,避免了普通二叉搜索树在极端情况下退化为链表的问题。
操作效率:红黑树的插入、删除和查找操作的时间复杂度均为O(log n),适用于大规模数据处理。
空间效率:红黑树的空间复杂度为O(n),与普通二叉搜索树相同,但在保持平衡的同时提供了更高的操作效率。
红黑树通过其独特的平衡机制,在需要高效查找和动态更新的场景中表现出色,是许多高级数据结构和算法的基础。