视觉-语言-动作模型:概念、进展、应用与挑战(上)
25年5月来自 Cornell 大学、香港科大和希腊 U Peloponnese 的论文“Vision-Language-Action Models: Concepts, Progress, Applications and Challenges”。
视觉-语言-动作 (VLA) 模型标志着人工智能的变革性进步,旨在将感知、自然语言理解和具体动作统一在一个计算框架内。这篇基础综述全面总结视觉-语言-动作模型的最新进展,并系统地涵盖构成这一快速发展领域格局的五大主题支柱。首先建立 VLA 系统的概念基础,追溯其从跨模态学习架构到紧密集成视觉-语言模型 (VLM)、动作规划器和分层控制器的通用智体演变过程。其方法论采用严格的文献综述框架,涵盖过去三年发布的 80 多个 VLA 模型。关键进展领域包括架构创新、参数高效的训练策略和实时推理加速。其探索人形机器人、自动驾驶汽车、医疗和工业机器人、精准农业以及增强现实(AR)导航等多种应用领域。本综述进一步探讨实时控制、多模态动作表征、系统可扩展性、泛化至未知任务以及伦理部署风险等方面的主要挑战。借鉴最新成果,其提出针对性的解决方案,包括智体 AI 自适应、跨具身泛化和统一神经符号规划。在前瞻性讨论中,概述未来路线图,其中 VLA 模型、VLM和智体 AI 将融合,为符合社会规范、自适应且通用的具身智体提供支持。
在视觉-语言-动作 (VLA) 模型出现之前,机器人技术和人工智能的进步主要发生在不同的领域:能够查看和识别图像的视觉系统 [44, 69],能够理解和生成文本的语言系统 [164, 137],以及能够控制运动的动作系统 [49]。这些系统独立运行良好,但难以协同工作或处理新的、不可预测的情况 [46, 21]。因此,它们无法理解复杂的环境或灵活应对现实世界的挑战。
如图所示,传统的计算机视觉模型主要基于卷积神经网络 (CNN),仅适用于目标检测或分类等特定任务,需要大量标记数据集,并且即使环境或目标发生轻微变化,也需要繁琐的再训练 [156, 62]。这些视觉模型可以“看”(例如,如图所示,识别果园中的苹果),但缺乏对语言的理解,也无法将视觉洞察转化为有目的的动作。语言模型,尤其是大语言模型 (LLM),彻底改变了基于文本的理解和生成 [23];然而,它们仍然局限于处理语言,而缺乏感知或推理物理世界的能力 [76](图中的“果园里成熟的苹果”就体现这一局限性)。与此同时,机器人领域中基于动作的系统严重依赖于手动制定的策略或强化学习 [122],虽然能够实现诸如目标操作之类的特定行为,但需要艰苦的工程设计,并且无法在狭隘的脚本场景之外进行泛化 [119]。尽管 VLM 取得进展,通过结合视觉和语言实现令人印象深刻的多模态理解 [149, 25, 148],但仍然存在明显的整合差距:无法基于多模态输入生成或执行连贯的动作 [121, 107]。
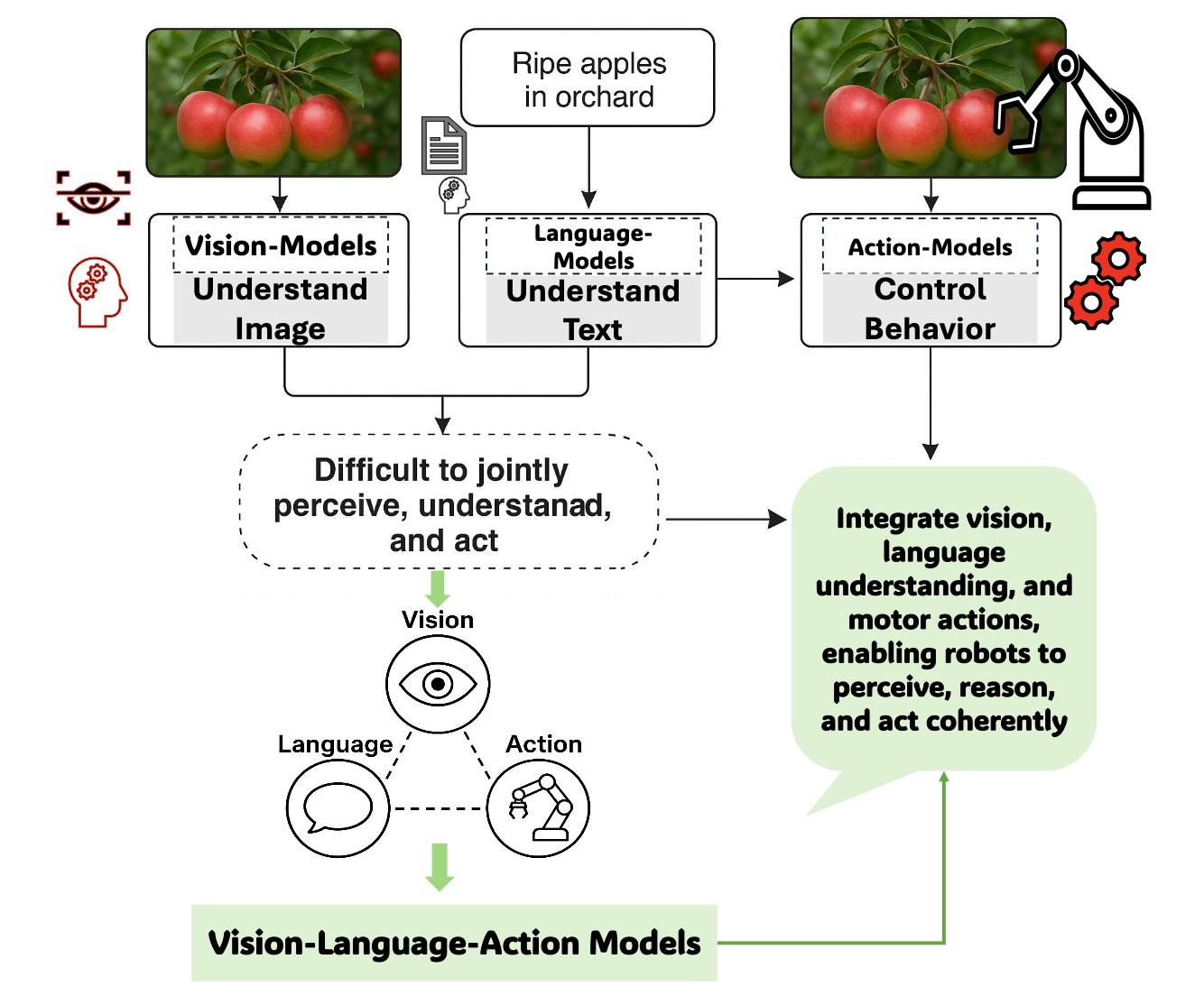
如图所示,大多数 AI 系统最多专注于两种模态——视觉-语言、视觉-动作或语言-动作——但难以将这三种模态完全整合到一个统一的端到端框架中。因此,机器人可以通过视觉识别目标(“苹果”),理解相应的文本指令(“摘苹果”),或执行预定义的运动动作(抓取),但将这些能力协调成流畅、适应性强的行为却遥不可及。结果是一个碎片化的流水线架构,无法灵活地适应新的任务或环境,从而导致泛化能力脆弱和劳动密集型的工程工作。这凸显具身人工智能的一个关键瓶颈:如果没有能够共同感知、理解和行动的系统,智能自主行为仍然是一个难以实现的目标。
弥合这些差距的迫切需求催化 VLA 模型的出现。VLA 模型概念化于2021-2022年左右,由谷歌 DeepMind 的Robot Transformer 2 (RT-2) [224]等项目开创,它引入了一种变革性架构,将感知、推理和控制统一在一个框架内。为了解决图中概述的局限性,VLA集成视觉输入、语言理解和运动控制能力,使具身智体能够感知周围环境,理解复杂指令,并动态地执行适当的操作。早期的 VLA 方法通过扩展视觉-语言模型,将动作 token(机器人运动命令的数字或符号表示)纳入其中,从而实现这种集成,从而使模型能够从成对的视觉、语言和轨迹数据中学习 [121]。这种方法上的创新极大地提高机器人泛化到未见过的目标、解释新的语言命令以及在非结构化环境中执行多步推理的能力 [83]。
VLA 模型代表追求统一多模态智能的变革性一步,克服了长期以来将视觉、语言和动作视为独立领域的局限性 [121]。通过利用整合视觉、语言和行为信息的互联网规模数据集,VLA 不仅使机器人能够识别和描述其环境,还能在复杂、动态的环境中根据上下文进行推理并执行适当的动作 [196]。如图所示的从孤立视觉、语言和动作系统到集成的 VLA 范式的进展,体现向真正具有适应性和可泛化的具身智体发展的根本性转变。
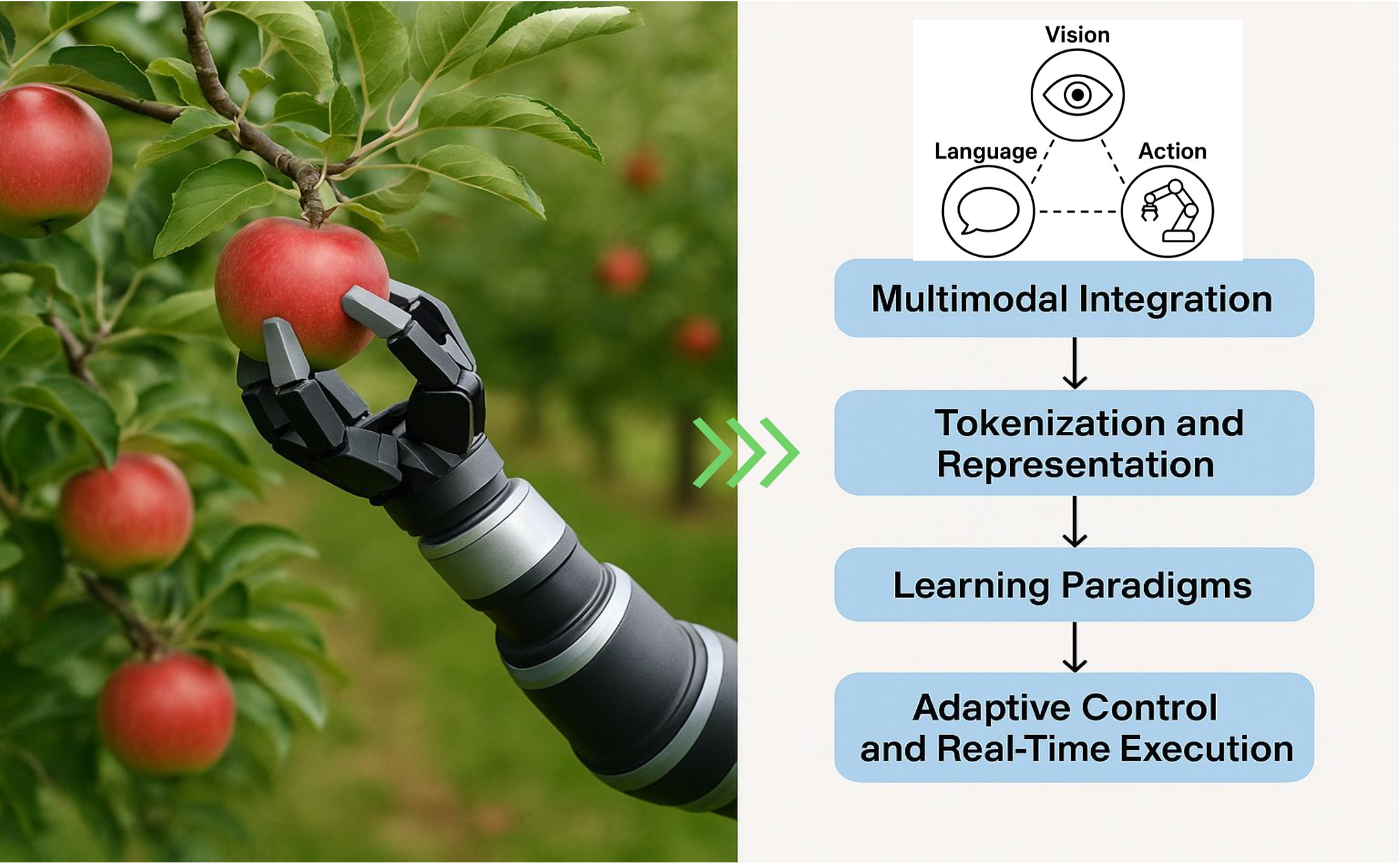
本综述系统地分析 VLA 模型的基本原理、发展进展和技术挑战。目标是巩固当前对 VLA 的理解,同时识别其局限性并提出其未来的发展方向。综述首先详细探讨关键概念基础(如图所示),包括 VLA 模型的构成、其历史演变、多模态集成机制以及基于语言的 token 化和编码策略。这些概念组件为理解 VLA 的结构及其跨模态功能奠定了基础。
在此基础上,呈现了近期进展和训练效率策略的统一视图(如图所示)。这包括支持更强大、更通用 VLA 模型的架构创新,以及数据高效的学习框架、参数高效的建模技术,以及旨在在不影响性能的情况下降低计算开销的模型加速策略。这些进步对于将 VLA 系统扩展到实际应用至关重要。
接下来,探讨 VLA 系统目前面临的局限性(如图所示)。这些局限性包括推理瓶颈、安全隐患、高计算需求、有限的泛化能力以及伦理影响。不仅强调这些紧迫的挑战,还对解决这些挑战的潜在解决方案进行分析性探讨。
这三幅图共同构成一个可视化框架,支持本文的文本分析。通过概述概念图、最新创新和尚未解决的挑战,本文旨在指导未来的研究,并鼓励开发更稳健、更高效、更符合伦理的 VLA 系统。
VLA 模型代表一类新型智能系统,它们能够联合处理视觉输入、解读自然语言并在动态环境中生成可执行动作。从技术上讲,VLA 结合视觉编码器(例如 CNN、ViT)、语言模型(例如 LLM、Transformer)以及策略模块或规划器,以实现任务条件控制。这些模型通常采用多模态融合技术(例如交叉注意、级联嵌入或 token 统一),将感官观察结果与文本指令对齐。
与传统的视觉运动流程不同,VLA 支持语义基础,从而实现上下文-觉察推理、affordance 检测和时间规划。典型的 VLA 模型通过摄像头或传感器数据观察环境,解读用语言表达的目标(例如“拿起红苹果”)(如图所示),并输出低级或高级动作序列。最近的进展整合模仿学习、强化学习或检索增强模块,以提高样本效率和泛化能力。本综述探讨 VLA 模型如何从基础融合架构发展成为能够在机器人、导航和人机协作等领域实际部署的通用智体。
VLA 模型是多模态人工智能系统,将视觉感知、语言理解和身体动作生成统一到一个框架中。这些模型使机器人或人工智能智体能够解读感官输入(例如图像、文本)、理解上下文含义,并在现实环境中自主执行任务——所有这些都通过端到端学习而非孤立的子系统实现。如图概念所示,VLA 模型弥合视觉识别、语言理解和运动执行之间长期以来的脱节,而这种脱节限制了早期机器人和人工智能系统的能力。
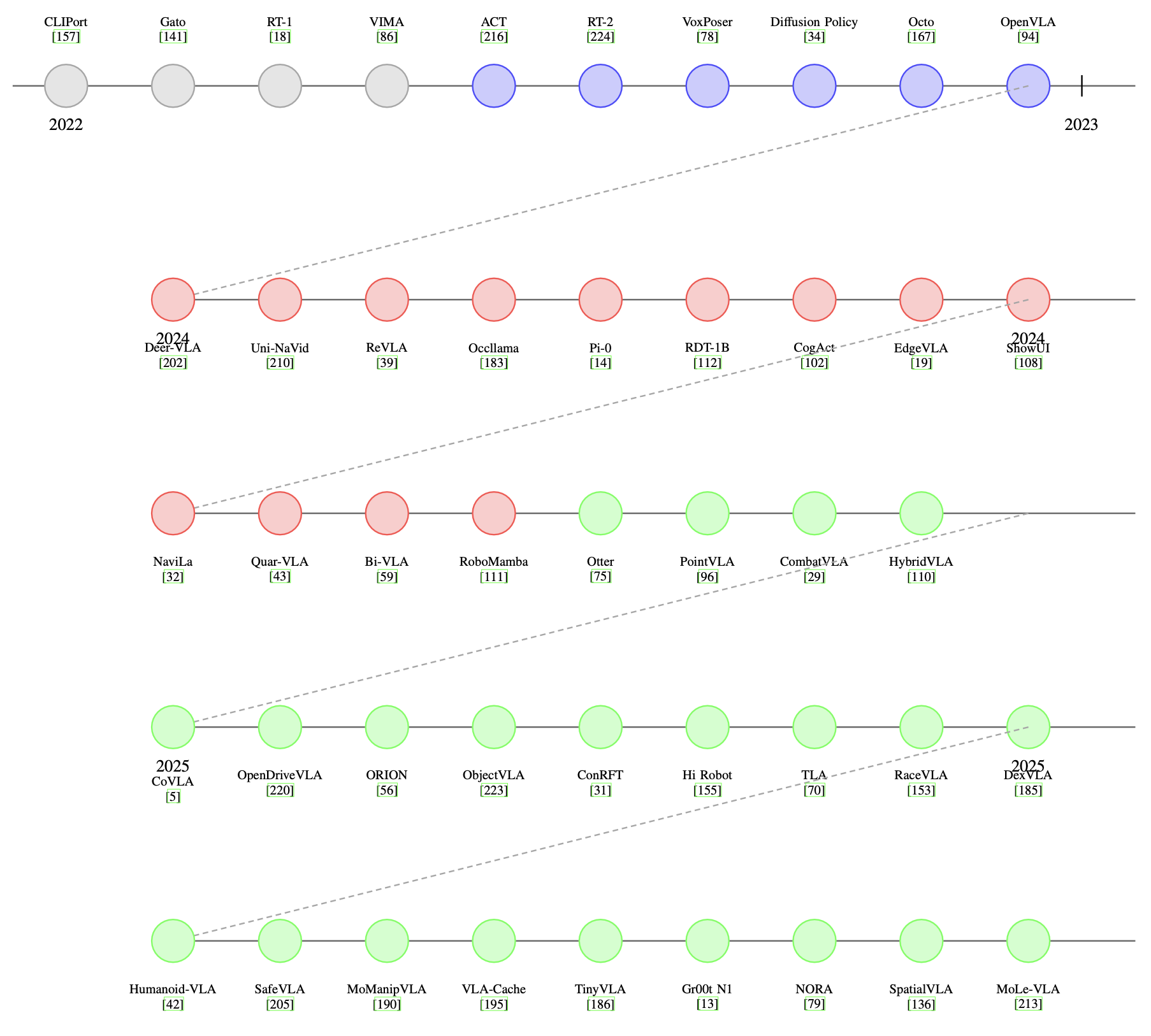
如图展示一条完整的时间线,重点介绍 2022 年至 2025 年间开发的 47 个 VLA 模型的演变历程。最早的 VLA 系统,包括 CLIPort [157]、Gato [141]、RT-1 [18] 和 VIMA [86],通过将预训练的视觉语言表征与任务条件策略相结合,为操作和控制奠定了基础。随后是 ACT [216]、RT-2 [224] 和 Vox-Poser [78],它们整合了视觉思维链推理和 affordance 基础。像 Diffusion Policy [34] 和 Octo [167] 这样的模型引入随机建模和可扩展的数据流水线。 2024年,Deer-VLA [202]、ReVLA [39] 和 Uni-NaVid [210] 等系统增加域专业化和内存高效设计,而 Occllama [183] 和 ShowUI [108] 则着眼于部分可观测性和用户交互。这一发展轨迹延续到专注于机器人技术的 VLA,例如 Quar-VLA [43] 和 RoboMamba [111]。最近的创新强调泛化和部署:SafeVLA [205]、Humanoid-VLA [42] 和 MoManipVLA [190] 融合验证、全身控制和记忆系统。Gr00t N1 [13] 和 SpatialVLA [136] 等模型进一步连接模拟-到-现实的迁移和空间落地。这条时间线展现 VLA 如何从模块化学习发展到通用、安全和具身智能。
VLA 模型兴起的核心进步在于其能够进行多模态集成,即在统一架构内联合处理视觉、语言和动作。传统的机器人系统将感知、自然语言理解和控制视为离散的模块,通常通过手动定义的接口或数据转换进行连接 [109, 20, 168]。例如,经典的基于流水线框架需要感知模型输出符号标签,然后由规划器将其映射到特定的动作——通常需要使用特定领域的手动工程 [138, 90]。这些方法缺乏适应性,在模糊或新的环境中失效,并且无法在预编码模板之外泛化指令。
相比之下,现代 VLA 使用大规模预训练编码器和基于 Transformer 的架构,端到端地融合各种模态 [188]。这种转变使模型能够在同一计算空间内解释视觉观察和语言指令,从而实现灵活的上下文-觉察推理 [99]。例如,在“捡起红色的成熟苹果”任务中,视觉编码器(通常是 Vision Transformer (ViT) 或 ConvNeXt)对场景中的目标(例如,苹果、树叶、背景)进行分割和分类,识别颜色和成熟度属性 [187]。同时,语言模型(通常是 T5、GPT 或 BERT 的变体)将指令编码为高维嵌入。然后,这些表示通过交叉注意或联合token化方案融合,生成一个统一的潜空间,为行动策略提供信息 [68]。
这种多模态协同作用首次在 CLIPort [157] 中得到有效展示,它使用 CLIP 嵌入进行语义基础构建,并使用卷积解码器进行像素级操作。CLIPort 绕过了显式语言解析的需要,直接在自然语言上调节视觉运动策略。同样地,VIMA [86] 通过使用 Transformer 编码器联合处理以目标为中心的视觉tokens和指令tokens,改进了这种方法,从而实现了跨空间推理任务的少样本泛化。
最近的进展通过结合时间和空间基础,进一步推动了这种融合。VoxPoser [78] 采用体素级推理来解决 3D 目标选择中的歧义问题,而 RT-2 [224] 将视觉语言 tokens 融合到一个统一的 Transformer 中,支持对未见指令的零样本泛化。另一个值得关注的贡献是 Octo [167],它引入一种记忆增强的 Transformer,能够跨不同场景进行长视界决策,展示了感知-语言-动作联合学习的可扩展性。
至关重要的是,VLA 为现实世界的落地挑战提供了强大的解决方案。例如,Occllama [183] 通过基于注意机制处理遮挡目标引用,而 ShowUI [108] 演示自然语言界面,允许非专家用户通过语音或键入输入来指挥智体。这些功能之所以能够实现,是因为集成并不局限于表面层次的融合;相反,它能够捕捉跨模态的语义、空间和时间对齐。
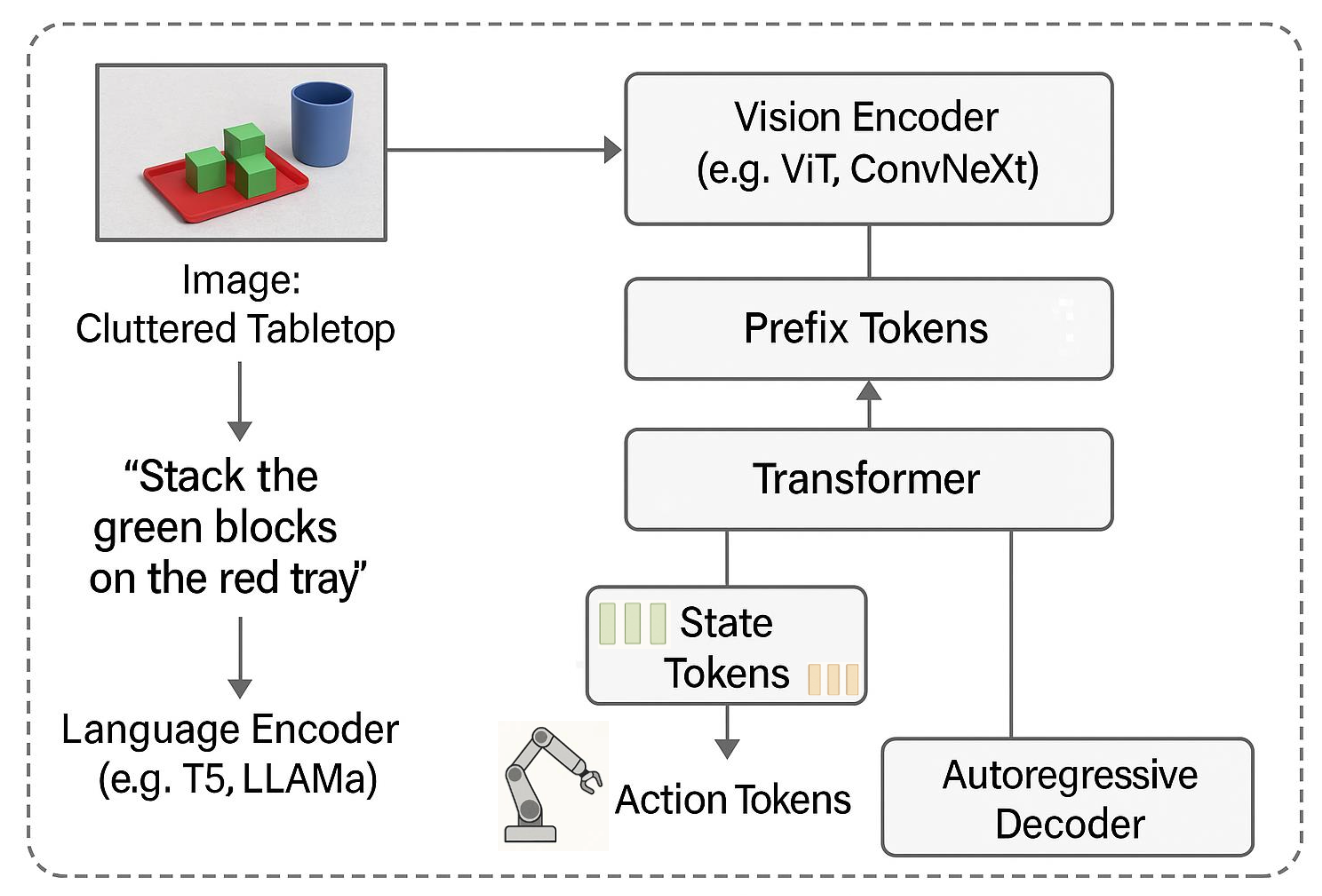
VLA 模型区别于传统视觉-语言架构的核心创新在于其基于 token 的表示框架,该框架支持对感知 [125, 215]、语言和物理动作空间 [106] 进行整体推理。受 Transformer 等自回归生成模型的启发,现代 VLA 使用离散 token 对世界进行编码,将所有模态(视觉、语言、状态和动作)统一到共享的嵌入空间 [110]。这使得模型不仅能够理解“需要做什么”(语义推理),还能以完全可学习和可组合的方式理解“如何做”(控制策略执行)[192, 117, 170]。
• 前缀 token:编码上下文和指令:前缀 token 是 VLA 模型的上下文主干 [195, 83]。这些token将环境场景(通过图像或视频)及其附带的自然语言指令编码成紧凑的嵌入,从而为模型的内部表征做好准备 [16]。
例如,如图所示,在“将绿色积木堆放在红色托盘上”等任务中,杂乱桌面的图像通过 ViT 或 ConvNeXt 等视觉编码器进行处理,而指令则由大语言模型(例如 T5 或 LLaMA)嵌入。然后,这些被转换为一系列前缀 token,用于建立模型对目标和环境布局的初步理解。这种共享表征实现跨模态落地,使系统能够解析跨模态的空间参考(例如,“在左边”、“在蓝色杯子旁边”)和目标语义(“绿色积木”)。
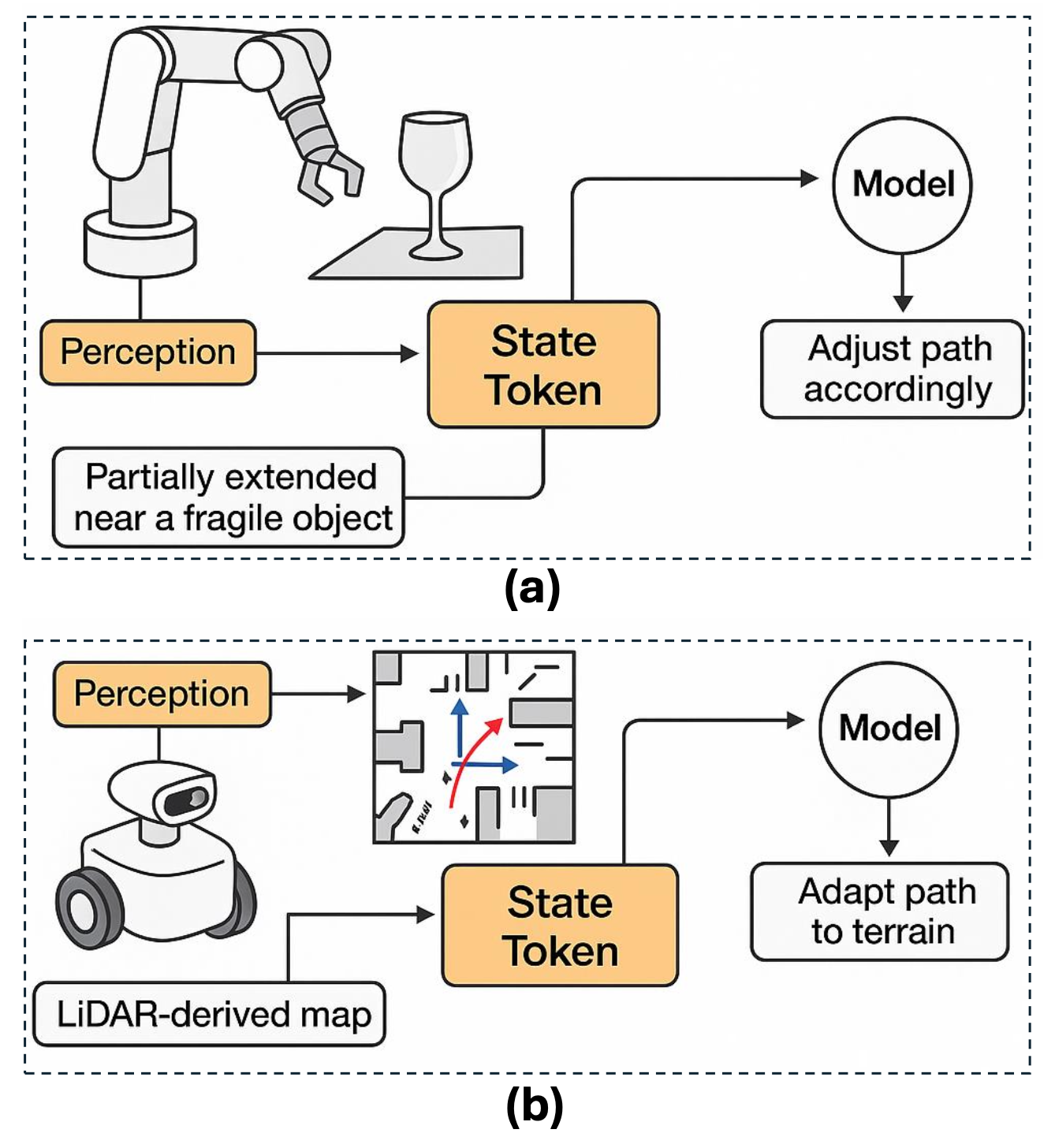
• 状态 token:嵌入机器人的配置:除了感知外部刺激之外,VLA 还必须感知其内部的物理状态 [186, 111]。这通过使用状态 token 来实现,状态 token 编码关于智体配置的实时信息——关节位置、力-扭矩读数、夹持器状态、末端执行器姿态,甚至附近目标的位置 [97]。这些 token 对于确保态势觉察和安全至关重要,尤其是在操作或运动过程中 [163, 81]。
如图展示 VLA 模型如何利用状态 token 在操作和导航环境中实现动态的、基于上下文-觉察的决策。在图 a 中,机械臂在一个易碎物体附近部分伸展。在这种情况下,状态 token 通过编码实时本体感受信息(例如关节角度、夹持器姿势和末端执行器接近度)发挥着关键作用。这些 token 不断与基于视觉和语言的前缀 token 融合,使 Transformer 能够推理物理约束。因此,该模型可以推断出即将发生碰撞并相应地调整电机命令 - 例如,重新规划手臂轨迹或调节力输出。在移动机器人平台中,如图 b 所示,状态 token 封装了里程表、激光雷达扫描和惯性传感器数据等空间特征。这些对于地形-觉察运动和避障至关重要。Transformer 模型将这种状态表示与环境和教学内容相结合,以生成能够动态适应不断变化的环境的导航动作。无论是在杂乱的环境中抓取物体,还是在不平坦的地形上自主导航,状态 token 都为态势-觉察提供了一种结构化的机制,使自回归解码器能够生成精确的、基于情境的动作序列,这些序列既能反映机器人的内部配置,也能反映外部传感数据。
• 动作 token:自回归控制生成:VLA token 流水线的最后一层涉及动作 token [93, 94],这些 tokens 由模型自回归生成,用于表示运动控制的下一步 [186]。每个 token 对应一个低级控制信号,例如关节角度更新、扭矩值、车轮速度或高级运动原语 [64]。在推理过程中,模型以前缀和状态 token 为条件,一步一步地解码这些 token,从而有效地将 VLA 模型转变为语言驱动的策略生成器 [54, 161]。这种方案可以与现实世界的驱动系统无缝集成,支持可变长度的动作序列 [10, 77],并支持通过强化或模仿学习框架进行模型微调 [214]。值得注意的是,RT-2 [224] 和 PaLM-E [47] 等模型体现这种设计,将感知、指令和具体化融合到统一的 token 流中。
例如,如图所示的采摘苹果任务中,模型可以接收包含果园图像和文本指令的前缀 token。状态 token 描述了机器人当前的手臂姿势以及夹持器是打开还是闭合。然后逐步预测动作 token,引导机械臂靠近苹果,调整夹持器方向,并以适当的力度执行抓取。这种方法的妙处在于,它使得传统上用于文本生成的 Transformer 能够以类似于生成句子的方式生成物理动作序列——只不过在这里,句子本身就是动作。
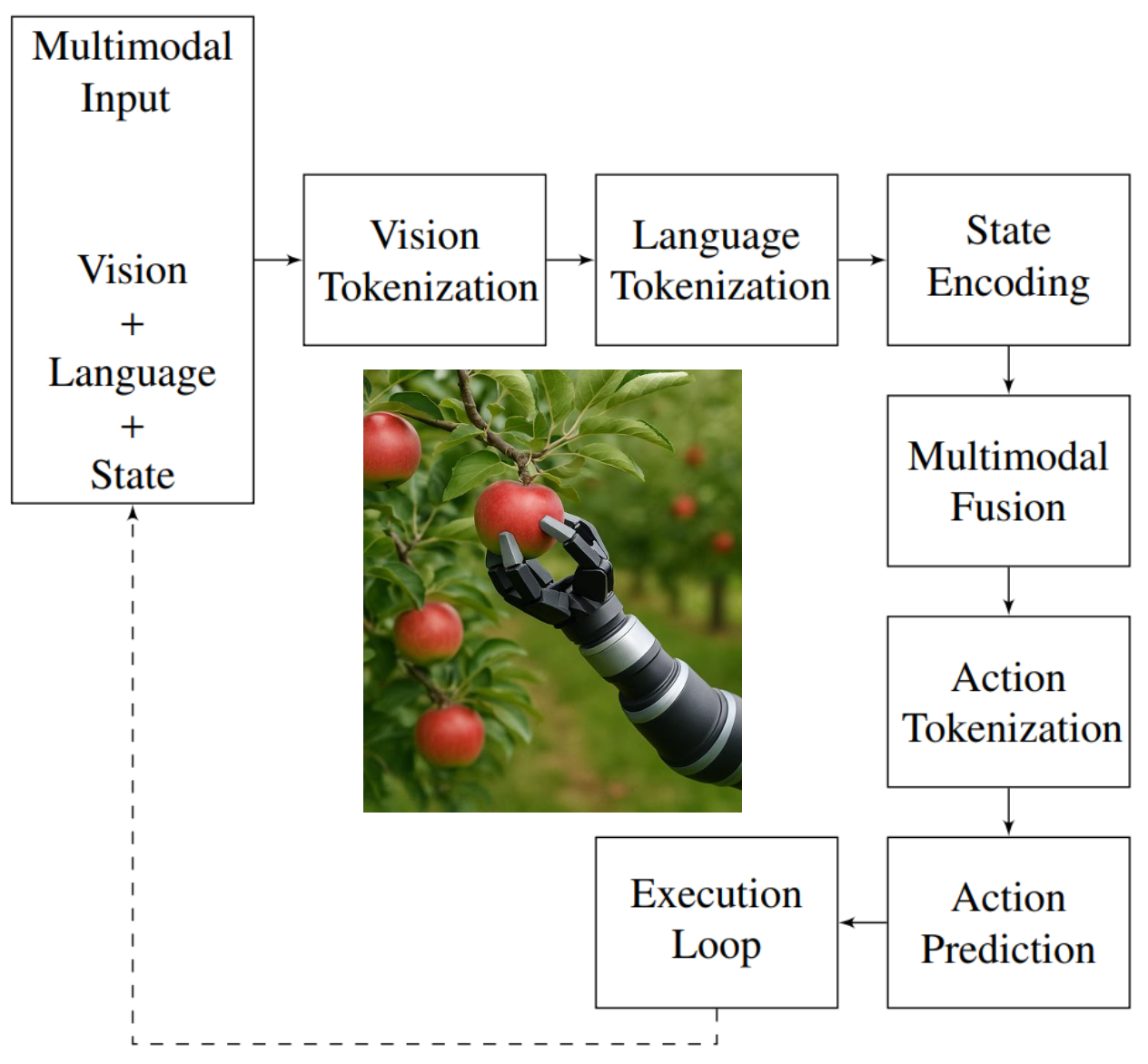
为了在机器人技术中实现VLA范式的可操作性,在图中展示了一个结构化流程,演示了如何将多模态信息(特别是视觉、语言和本体感受状态)编码、融合并转换为可执行的动作序列。这种端到端循环使机器人能够理解诸如“摘取绿叶附近成熟的苹果”之类的复杂任务,并执行精确的、上下文相关的操作。该系统从多模态输入采集开始,收集三种不同的数据流:视觉观测(例如RGB-D帧)、自然语言命令和实时机器人状态信息(例如关节角度或速度)。使用预训练模块 [41, 212] 将它们独立地 token 化为离散的嵌入。如图所示,图像通过视觉 Transformer (ViT) 主干处理以生成视觉 token,指令由 BERT 或 T5 等语言模型解析以生成语言 token,状态输入通过轻量级 MLP 编码器转换为紧凑的状态 token。然后使用跨模态注意机制融合这些 token,其中模型联合推理目标语义、空间布局和物理约束 [61]。这种融合的表示构成决策的上下文基础 [74, 116]。在图中,这个表示为多模态融合步骤。融合的嵌入被传递到自回归解码器(通常是 Transformer)中,该解码器生成一系列动作 tokens。这些 tokens 可能对应于关节位移、夹持器力调节或高级运动原语(例如,“移动到抓取姿势”、“旋转手腕”)。随后,动作 tokens 被转换为控制命令并传递到执行循环,执行循环通过反馈机器人的更新状态来闭合感知-动作循环,从而为下一步推理提供信息。这种闭环机制使模型能够实时动态地适应扰动、目标移动或遮挡[206, 120, 194]。
为了提供具体的实现细节,如下算法 1 形式化 VLA token 化过程。给定 RGB-D 帧 I、自然语言指令 T 和关节角度向量 θ,该算法生成一组可按顺序执行的动作 tokens。图像 I 通过 ViT 处理生成 V,即一组 400 个视觉 tokens。并行地,指令 T 由 BERT 模型编码生成 L,即 12 个语义语言 tokens 的序列。同时,机器人状态 θ 经过多层感知器生成 64 维状态嵌入 S。然后,这些 tokens 通过交叉注意模块融合,生成一个共享的 512 维表示 F,从而捕获执行落地动作所需的语义、意图和态势-觉察。最后,策略解码器(如 FAST [133])将融合的特征映射到 50 个离散的动作 tokens,然后可以将其解码为运动命令 τ_1:N。
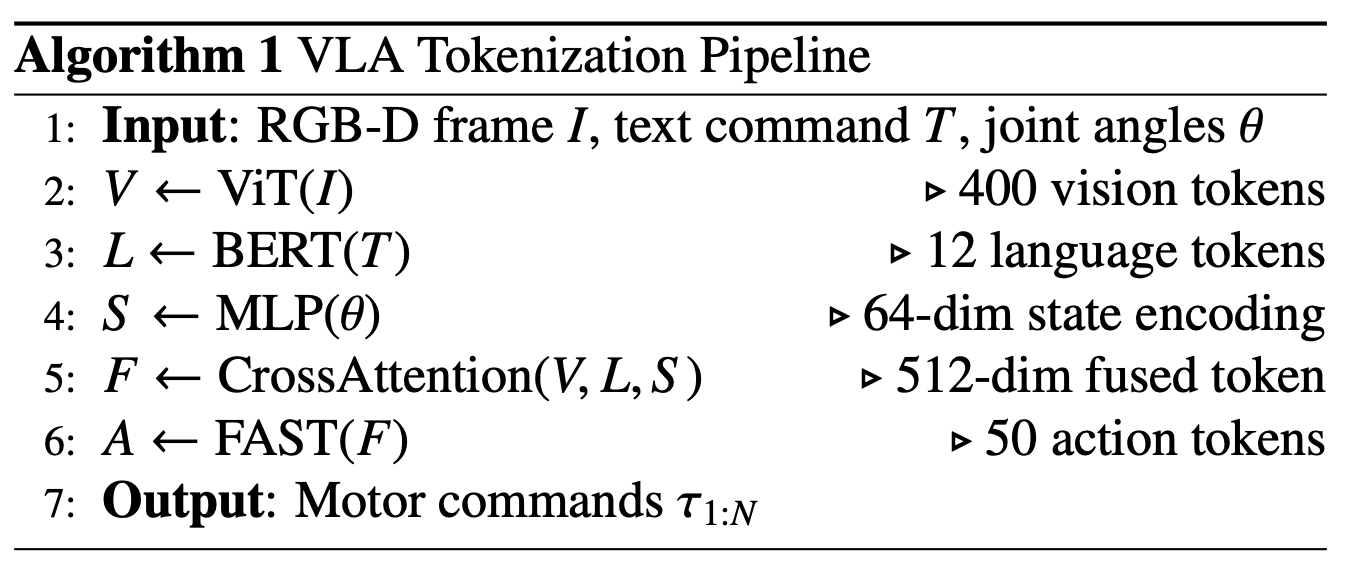
解码过程使用基于 Transformer 的架构实现,如“动作预测代码”的代码片段所示。一个“Transformer”目标,初始化为 12 层,模型维度为 512,并有 8 个注意头。融合后的token 被传递到解码器,解码器根据先前的 token 和上下文,自回归地预测下一个最可能的动作 token。最终的运动指令序列通过对输出进行去 token 化获得。此实现反映了大语言模型中文本生成的工作方式,但这里的“句子”是一条运动轨迹——这是自然语言生成技术在物理动作合成中的一种重新利用。

上图、算法 1 和伪代码,共同说明了 VLA 如何在连贯且可解释的 token 空间中统一感知、指令和具身。这种模块化特性使该框架能够跨任务和机器人形态进行泛化,从而促进其在苹果采摘、家务和移动导航等实际应用中的快速部署。重要的是,token 化步骤的清晰性和可分离性使该架构具有可扩展性,从而支持进一步研究 VLA 系统中的token 学习、分层规划或符号落地。
训练 VLA 模型需要一种混合学习范式,该范式整合来自网络的语义知识和来自机器人数据集的任务落地信息 [30]。VLA 的多模态架构必须接触支持语言理解、视觉识别和运动控制的多种形式的数据。这通常通过两个主要数据源实现。
首先,如图所示,大规模互联网语料库构成模型语义先验的主干。这些数据集包括图像-字幕对(例如 COCO、LAION-400M)、指令跟踪数据集(例如 HowTo100M、WebVid)以及视觉问答语料库(例如 VQA、GQA)。此类数据集支持对视觉和语言编码器进行预训练,帮助模型获得目标、动作和概念的通用表示 [2]。此阶段通常使用对比或掩码建模目标,例如 CLIP 式对比学习或语言建模损失,以在共享的嵌入空间内对齐视觉和语言模态 [146, 199]。重要的是,此阶段为 VLA 提供了基础性的“世界理解”,从而促进了组合泛化、目标落地和零样本迁移 [28, 15]。然而,仅有语义理解不足以执行物理任务 [36, 178, 107]。因此,第二阶段侧重于将模型植根于具身体验 [178]。机器人轨迹数据集(从现实世界的机器人或高保真模拟器收集)用于教导模型如何将语言和感知转化为动作 [54]。其中包括 RoboNet [37]、BridgeData [50] 和 RT-X [175] 等数据集,它们在自然语言指令下提供视频-动作对、关节轨迹和环境交互 [123]。演示数据可能来自动觉教学、遥操作或脚本策略 [89, 12]。此阶段通常采用监督学习(例如行为克隆)[55]、强化学习 (RL) 或模仿学习来训练自回归策略解码器,使其基于融合的视觉-语言-状态嵌入预测动作 token [65]。最近的研究越来越多地采用多阶段或多任务训练策略。例如,模型通常使用掩码语言模型在视觉-语言数据集上进行预训练,然后使用 token 级自回归损失在机器人演示数据上进行微调 [94, 221, 195]。其他方法则采用课程学习,先完成简单任务(例如,物体推送)再完成复杂任务(例如,多步骤操作)[217]。一些方法进一步利用域自适应(例如 Open-VLA [94] 或模拟-到-现实迁移)来弥合合成分布与现实世界分布之间的差距 [96]。通过将语义先验与任务执行数据统一起来,这些学习范式使 VLA 模型能够跨任务、跨领域和跨具体实现进行泛化,从而构成了可扩展、指令跟随型智体的主干,这些智体能够在现实世界中稳健地运行。
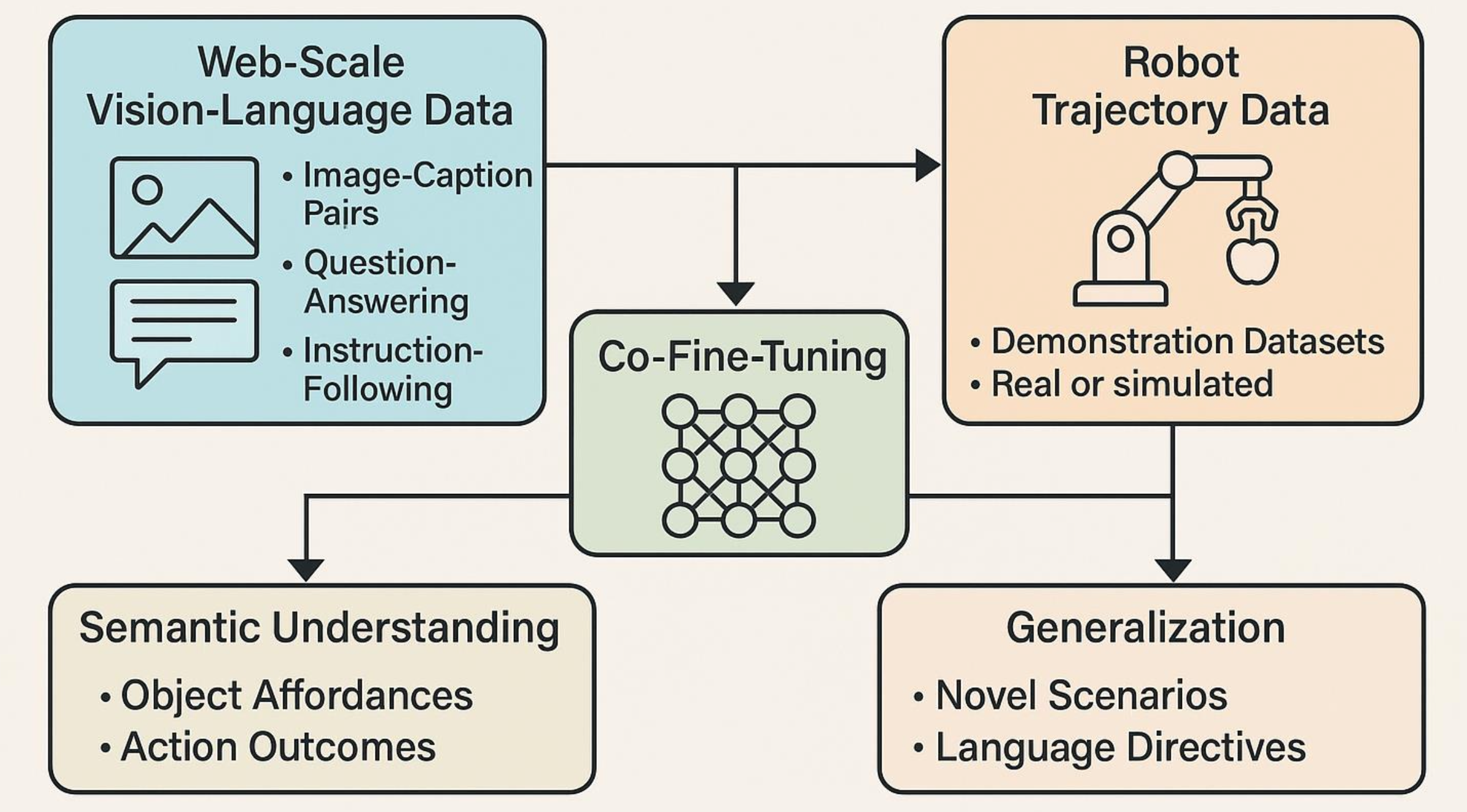
通过共同微调,这些数据集得以对齐 [179, 52]。该模型学习将视觉和语言输入映射到适当的动作序列 [136]。这种训练范式不仅有助于模型理解目标的 affordance(例如,苹果可以被抓取)和动作结果(例如,举起需要力和轨迹),还能促进模型泛化到新场景 [100]。如果一个在厨房操作任务上训练的模型已经学习了物体定位、抓取和遵循语言指令的一般原理,那么它或许能够推断出如何在户外果园里摘苹果。
近期的一些架构,例如谷歌 DeepMind 的 RT-2(机器人 Transformer 2)[224],已经实际演示了这一原理。RT-2 将动作生成视为文本生成的一种形式,其中每个动作 token 对应于机器人控制空间中的一个离散命令。由于该模型是在网络规模的多模态数据和数千个机器人演示上进行训练的,因此它可以灵活地解释新的指令并对新目标和任务进行零样本泛化——这在传统控制系统甚至早期的多模态模型中基本上是不可能的。
VLA 的另一个优势在于它们能够执行自适应控制,利用传感器的实时反馈动态调整行为 [153]。这在果园、住宅或医院等动态非结构化环境中尤为重要,因为意外变化(例如,风吹动苹果、光照变化、人类存在)都可能改变任务参数。在执行过程中,状态 token 会实时更新,反映传感器输入和关节反馈 [195]。然后,模型可以相应地修改其计划好的动作。例如,在采摘苹果的场景中,如果目标苹果略微移动或另一个苹果进入视野,模型就会动态地重新解释场景并调整抓取轨迹。这种能力模仿类似人类的适应性,是 VLA 系统相对于基于流水线的机器人的核心优势。