因子分析基础指南:原理、步骤与地球化学数据分析应用解析
前言
在看深度学习成矿预测以及地球化学数据分析的文献的时候很多引言部分的内容会提到一些老的技术,正所谓:知其然知其所以然。所以我把关于一些老技术的基础铺垫的内容作为:研究生基础指南部分进行记录。
这部分讲述的是因子分析(Factor Analysis),这部分将会说明如下几点内容:
-
什么是因子分析?
-
因子分析的原理
-
因子分析和主成分分析(PCA)的区别
注:请确保你已经先掌握了主成分分析(PCA)方法
什么是因子分析?
因子分析(Factor Analysis,简称FA) 是一种统计方法,主要用于降维 和探索变量之间的潜在结构 。它通过识别一组可观测变量背后可能存在的、不可直接观测的潜在变量(latent variables)或因子(factors) ,来解释这些变量之间的相关性。
其基本思路是:试图找出少数几个公共因子 ,这些因子能够解释原始变量之间的相关关系。
因子分析的原理
听起来了和主成分分析(PCA)很像不是吗?关于和主成分分析的区别将在本文的最后说明。现在我们来关注一下他的过程。因子分析的一般模型可以表示为:
ε
,其中:
-
X:p个可观测变量组成的向量;
-
F:k个不可观测的公共因子(k < p);
-
Λ:因子载荷矩阵(loadings),表示每个变量与各因子的关系强度;
-
ε:特殊因子(unique factors),代表每个变量中不能被公共因子解释的部分。

这个公式可以先不用仔细看,我们更多的需要关系,他做了什么。在明白他做了什么后,再看公式才会明白他的意思。其具体计算过程如下:
-
数据准备 :标准化数据,检查变量间是否适合做因子分析(如KMO检验、Bartlett球形度检验)。
-
提取因子 :使用主成分法、主轴迭代法等提取初始因子。
-
确定因子个数 :根据特征值 > 1、碎石图(Scree Plot)、解释方差比例等判断。
-
因子旋转 :使因子更容易解释,常用正交旋转(如Varimax)或斜交旋转(如Oblimin)。
-
解释因子 :观察因子载荷,给每个因子命名并赋予实际意义。
-
计算因子得分 :可用于后续分析。
乍一看这个过程前半截和PCA很像,或者你可以说,他在提取因子和筛选因子个数的时候就是可以通过PCA的方法来选择。不同的地方在于数据适用条件和因子旋转。
适用前提
-
因子分析要求变量之间的共线性或相关关系比较强。
-
因子分析变量应该服从正态分布或近似正态分布。
对于第一点而言,就可以通过KMO检验、Bartlett球形度检验来得知,对于第二点,可以通过标准化或者对数变换来消除量纲并且使得数据近似服从正态分布。
KMO 检验和Bartlett球形度检验听起来非常的吓人啊,其实不然,此处做一个简短的说明就能明白了:
KMO检验的作用就是:衡量变量之间的偏相关性是否足够强,也就是说,变量之间是否存在潜在的共同因子。他的判别标准就是计算的值,如果在 0.8-1 之间则表示可以做因子分析,小于 0.5 表示数据没办法做因子分析。
而对于Bartlett球形度检验而言,他的作用就是:检验相关系数矩阵是否是一个单位阵(即所有变量是否彼此不相关)。
这么说的话这两个方法就很简单了,无非就是判别是否满足我们对数据做因子分析的前提工具。

因子旋转
这又是一个第一次听起来非常唬人的名词啊,我来简单解释一下:
因子旋转的作用是调整空间坐标系来使得因子更好解释。它主要是解决一个问题,在我们选择好公因子后,会出现某个变量在其他公因子里面都占据有不小的相关性。
比如我们选择降维 5 个公因子,SiO2 元素在 5 个公因子里面会出现全部占有超过 0.6 的相关度。这就导致没办法解释了。因为,我们要提取共性,或者换个角度来理解,类似于聚类,我们需要把不同的变量用一个公因子来代表,而不是把每个变量都用公因子来代表。

因子旋转的方法有两种:正交旋转(如Varimax)和斜交旋转两个类别。:
-
正交旋转假设因子之间是不相关的(即因子轴相互垂直),常用的正交旋转方法是 Varimax 旋转。
-
斜交旋转允许因子之间存在相关性(即因子轴不再相互垂直)。常用的斜交旋转方法包括 Promax 旋转和 Direct Oblimin 旋转。
示例
这个示例来源于:卢文东等人发表的《因子分析在地球化学分区中的应用及指示意义——以山东省莒县—五莲地区1∶5万水系沉积物测量数据为例》。
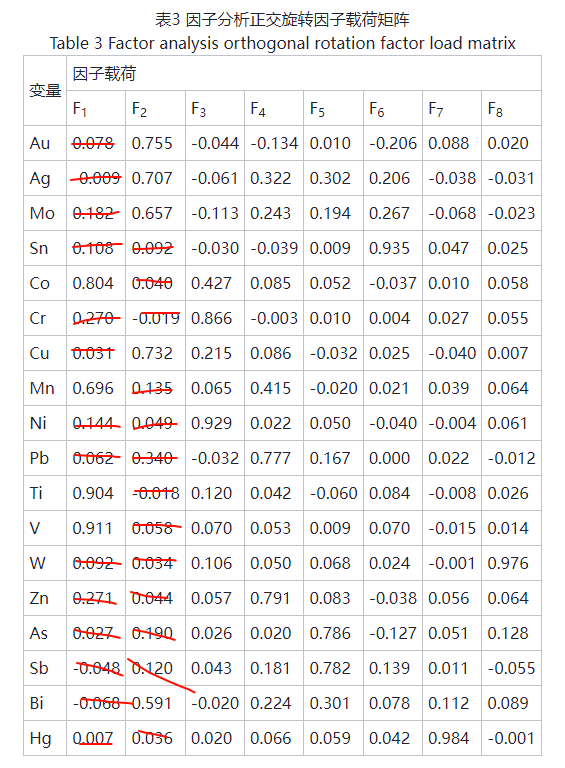
这个数据是已经进行挑选因子以及因子旋转后的结果,我们可以很清晰的了解,作者选择了 8 个公因子,通过因子旋转后的结果可以得知:F1 因子代表了元素组合 V-Ti-Co-Mn,F2 因子代表了元素组合 Au-Cu-Ag-Mo-Bi。其他省略。
对于这些元素组合的解释,就需要根据实际情况具体解释了。到此为止你就完成了数据的因子分析。
因子分析和PCA的区别
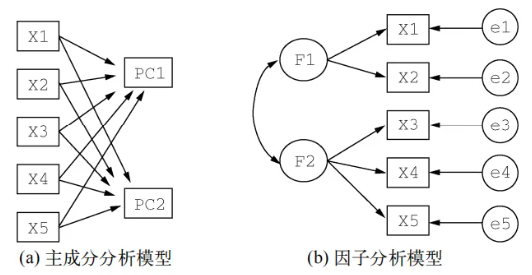
因子分析和PCA的区别可以通过上图可以清晰的了解,因子分析思想类似于聚类,他通过把一些相关性强的元素作为一组提取公因子。而PCA是通过在所有的变量数据空间中,重新定义坐标系,重新定义”新“数据来代表原来的数据。
End
记得关注唯一微信公众号:码上地球🌹
这部分内容完全是为了后续的 矿物勘探的地球化学数据的处理和解释 部分内容做的基础铺垫。后面将会更新一些深度学习成矿预测GIS的内容,内容是基于书籍《Geospatial analysis applied to mineral exploration: remote sensing, GIS, geochemical, and geophysical applications to mineral resources》。可以让做地质大数据的相关伙伴快速入门并掌握基础知识。
参考文献
-
大腿粗的小吖,2025. FA因子分析.
-
Pour, A.B., Parsa, M., Eldosouky, A.M., 2023. Geospatial analysis applied to mineral exploration: remote sensing, GIS, geochemical, and geophysical applications to mineral resources. Elsevier.
-
李硕,高洪生,吴瑾,侯建涛,周泽旭,宋淑艳,陈峥嵘,2025. 津南区土壤地球化学背景值与元素组合特征. 环境生态学, 15-22.
-
卢文东,孙斌,李光杰,魏伟,夏小兴,潘丙磊,乔娜,2025. 因子分析在地球化学分区中的应用及指示意义——以山东省莒县—五莲地区1∶5万水系沉积物测量数据为例. 物探与化探, 411-421.