AI编程: 使用Trae1小时做成的音视频工具,提取音频并识别文本
背景
在上个月,有网页咨询我怎么才能获取视频中的音频并识别成文本,我当时给他的回答是去问一下AI,让AI来给你答案。
他觉得我在敷衍他,大骂了我一顿,大家觉得我的回答对吗?
小编心里委屈,我觉得现在这个时代,什么问题都可以先咨询AI,实在没思路了再咨询专业的人。
历程
作为一个在软件开发行业摸爬滚打多年的老码农,这种工具肯定还是能手到擒来的。
说实话,之前没想过这个问题,因为从来没做过音视频相关的项目,对这方面的知识了解不多。只知道直播行业对这方面的知识要求比较高。
遇事不决,先问AI。
由于之前了解过ffmpeg用这个工具获取过视频的时长,对此这个工具有基本的认知。
这里我们打开热门的AI IDE Trae,直接用Builder模式问一下一般处理音视频用技术方案,并让他写出Markdown文档。
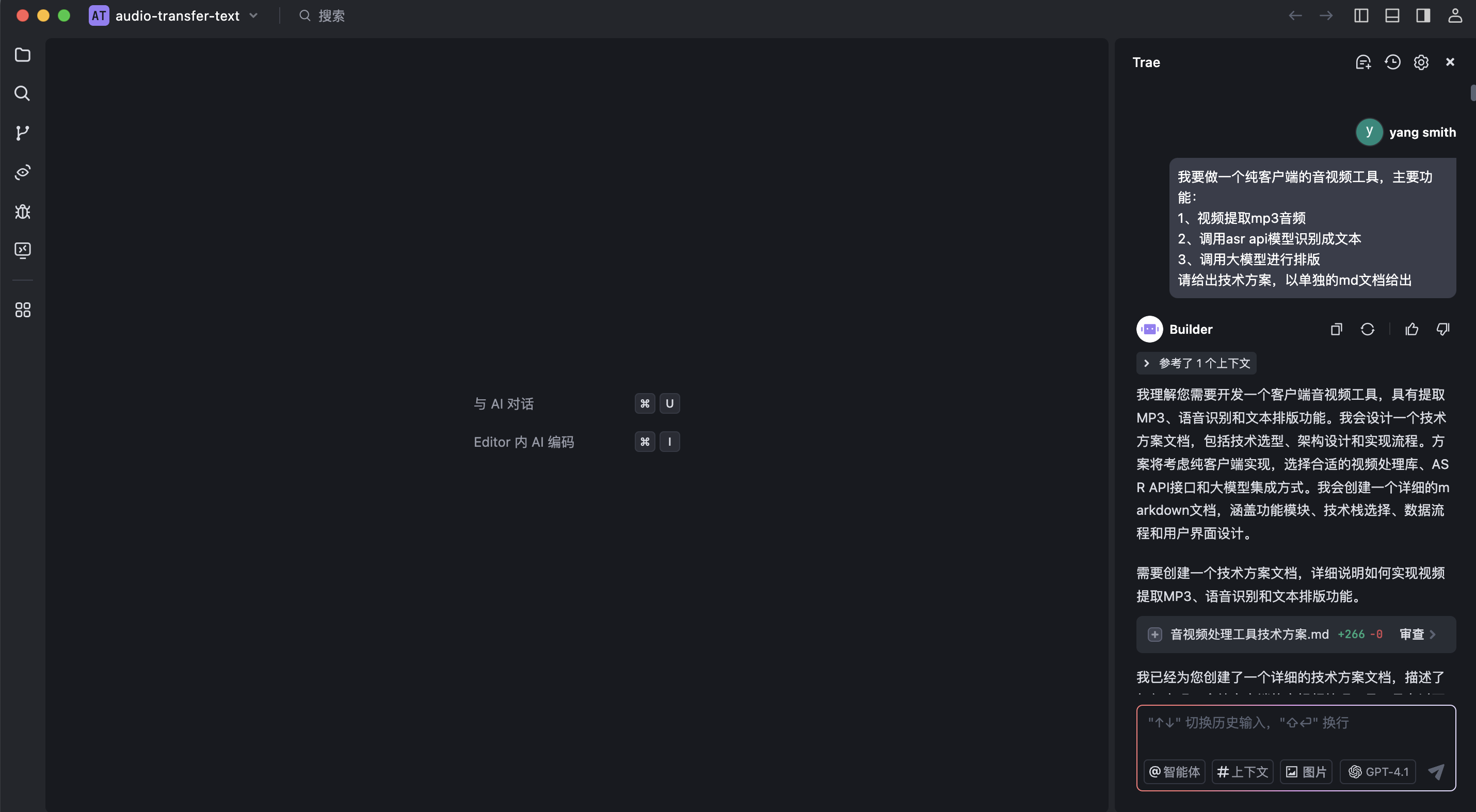
按照我的要求,给出了独立的md文档。
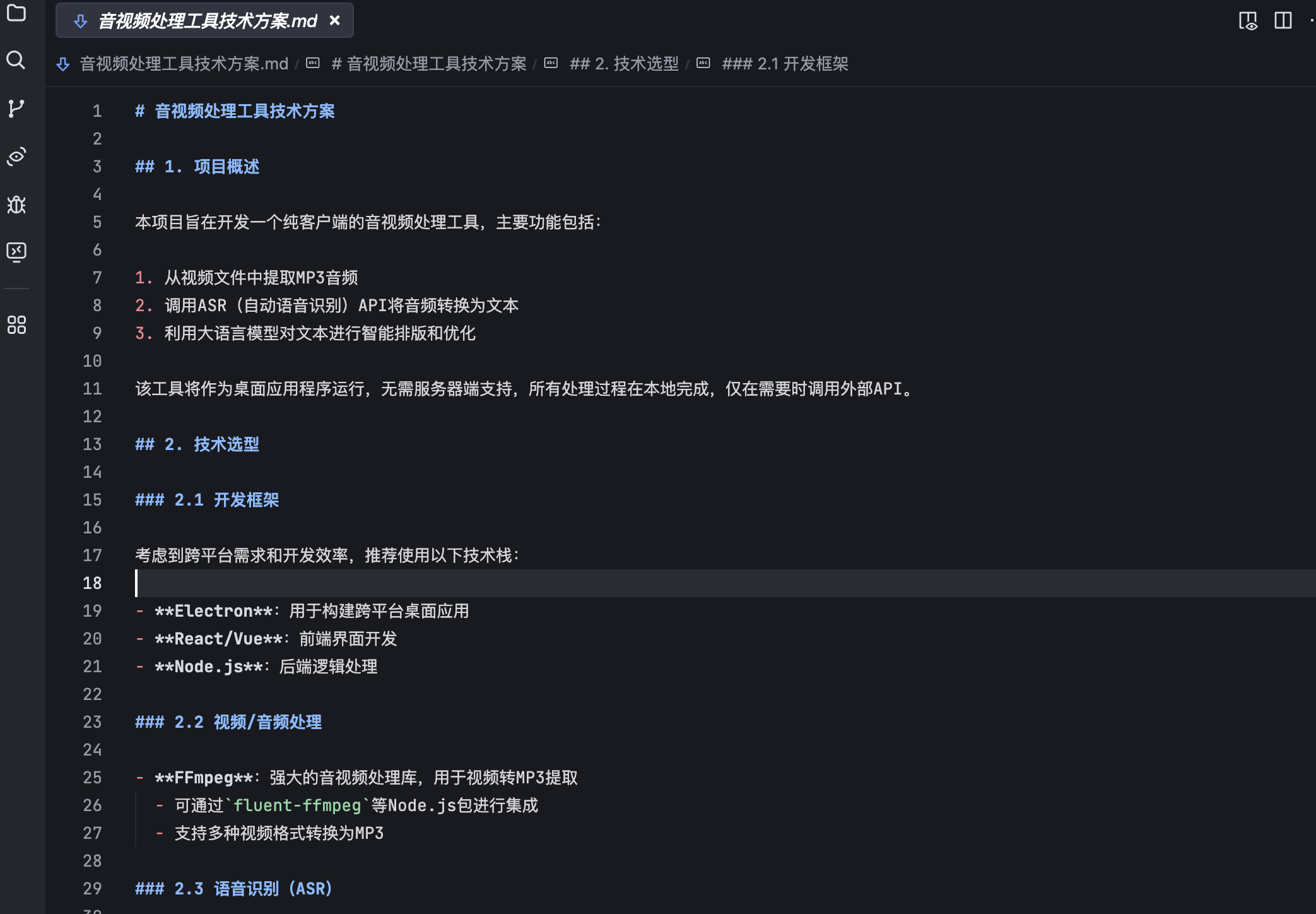
大体的浏览了一下,文档给出的还是不错的。
能给出具体的技术方案,并给出开发框架的选择。可以说文档的质量还是不错的。修改一下不满足的地方,可以作为实现的技术文档。
技术方案最终用的Electron来实现,这是比较热门的桌面端开发框架。
VSCode、Cherry Studio。
接下来就是让AI自己按照文档的要求实现了,实现的第一版,AI用简单的样式实现了。
第一版相对来说页面看起来不美观,又让ai用UI组件Element-Plus来实现。
最后的版本是这样的布局。
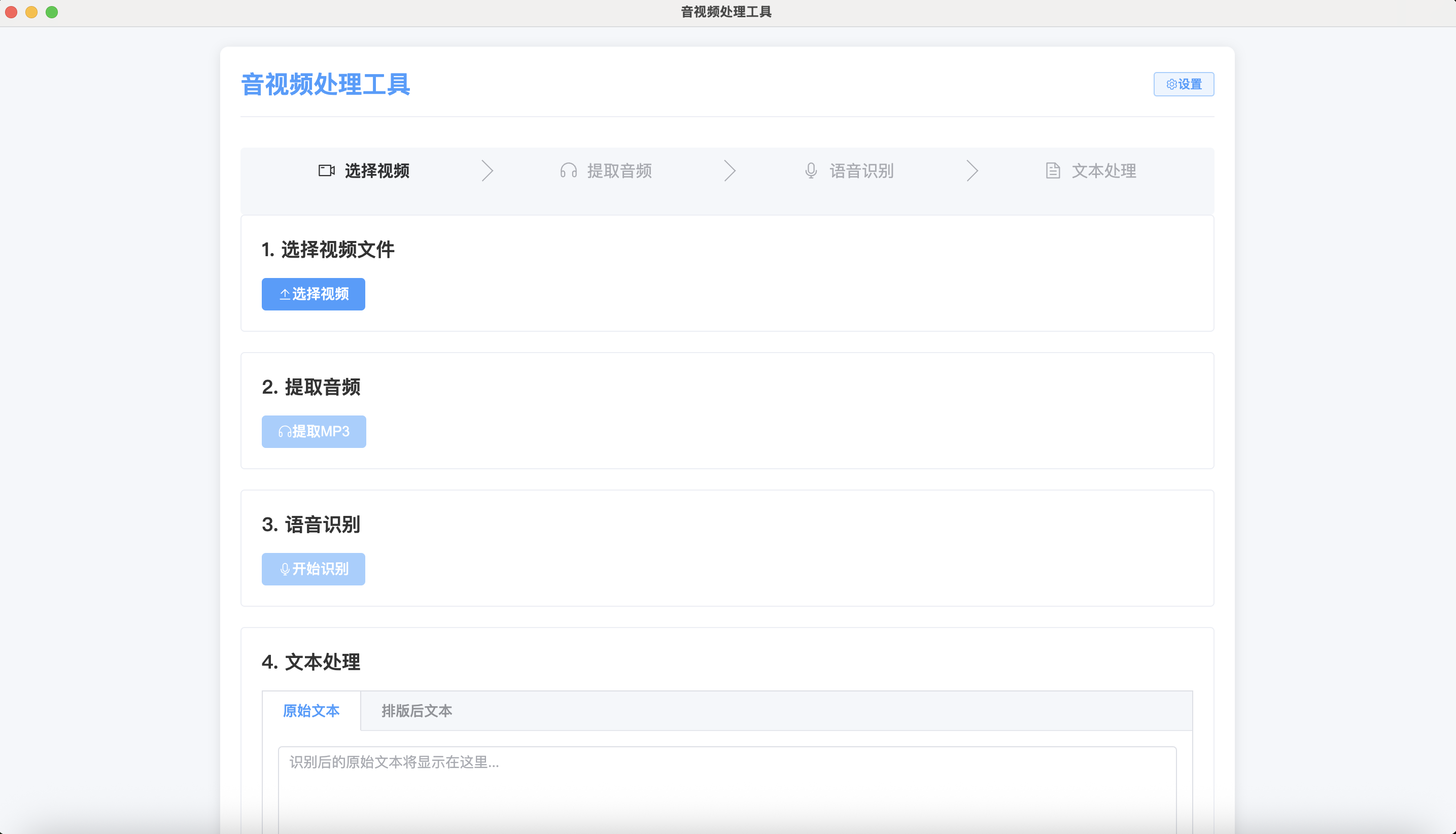
相对来说还是比较简约的,毕竟功能简单。没有太多的实现。如果要添加功能可以在左侧增加一个侧边栏。
对于我来说够用了。
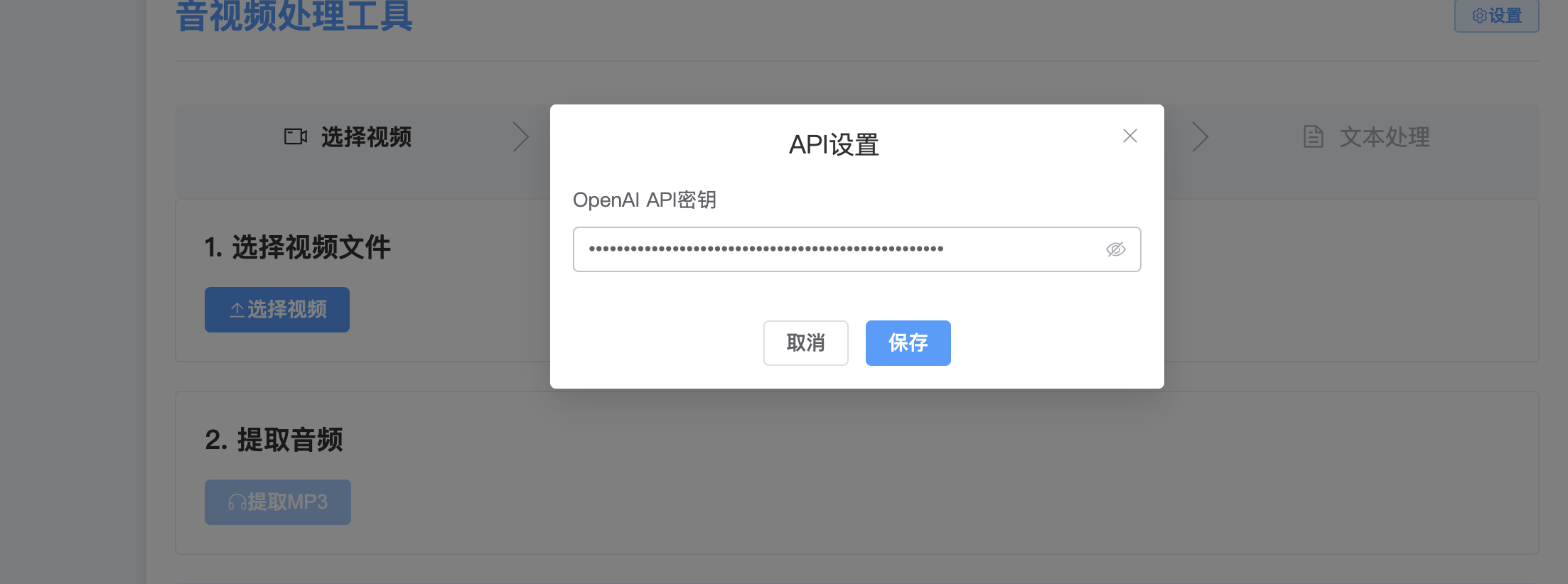
这里设置密钥,使用了硅基流动的FunAudioLLM/SenseVoiceSmall模型进行的获取,目前这个模型还是免费的,质量不错。
最后
看来我没有骗那个网友,用AI确实能解决他的问题。
技术栈
- Electron
- Element-Plus
- NodeJs
- ffmpeg