人脸真假检测:SVM 与 ResNet18 的实战对比
在人工智能蓬勃发展的当下,人脸相关技术广泛应用于安防、金融、娱乐等诸多领域。然而,随着人脸合成技术的日益成熟,人脸真假检测成为保障这些应用安全的关键环节。本文将深入探讨基于支持向量机(SVM)结合局部二值模式(LBP)特征,以及基于 ResNet18 神经网络的人脸真假检测方法,并通过 Python 代码实战进行详细分析与对比。
一、技术原理
(一)SVM 与 LBP 特征
LBP 特征提取:LBP 是一种用于描述图像局部纹理特征的算子。其基本原理是对图像每个像素点,以其为中心,设定邻域像素点个数(如本文中的 8 个邻域点)和半径(本文为 1)。将邻域像素点的灰度值与中心像素点灰度值进行比较,大于等于中心像素点灰度值的邻域点记为 1,小于则记为 0,这些二进制值按顺时针或逆时针顺序排列形成一个二进制码,该码就是中心像素点的 LBP 值。对整幅图像计算 LBP 值后,通过统计不同 LBP 值出现的频率(即直方图),得到图像的 LBP 特征。这种特征对光照变化具有一定的鲁棒性,能有效捕捉图像的纹理细节 。
SVM 模型:支持向量机是一种二分类模型,旨在寻找一个最优分类超平面,使得不同类别的样本点尽可能地远离该超平面。在本文中,采用径向基函数(RBF)作为核函数,它能够将低维空间中的数据映射到高维空间,从而更好地处理非线性分类问题。利用提取的 LBP 特征训练 SVM 模型,实现对人脸真假的分类预测。
(二)ResNet18 神经网络
ResNet18 架构:ResNet(残差网络)是深度学习领域的经典网络结构,通过引入残差块解决了深度神经网络训练过程中的梯度消失和梯度爆炸问题,使得网络可以训练得更深。ResNet18 包含 18 层卷积层和全连接层,能够自动学习图像的高级特征。
模型修改与训练:在本文中,对预训练的 ResNet18 模型进行了修改,将最后一层全连接层的输出特征数量调整为 1,并添加了 Sigmoid 激活函数,使其输出为 0 到 1 之间的概率值,用于二分类任务(判断人脸真假)。训练过程中,使用交叉熵损失函数(BCELoss)衡量预测结果与真实标签之间的差异,通过 Adam 优化器调整模型参数,逐步降低损失,提高模型的准确性。
二、代码实现
(一)环境设置与库导入
首先,需要导入一系列必要的库,包括用于图像处理的 OpenCV、NumPy、scikit - image,用于深度学习的 PyTorch 及其相关工具,以及用于数据处理和评估的 scikit - learn 等:
import os
import cv2
import numpy as np
from skimage.feature import local_binary_pattern
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, models
from PIL import Image
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
import random
(二)SVM 模型实现
LBP 特征提取函数:extract_lbp_features函数负责读取图像并提取其 LBP 特征。首先将图像转换为灰度图,调整大小为指定尺寸,计算 LBP 值并生成直方图,最后对直方图进行归一化处理:
def extract_lbp_features(image_path, target_size=(64, 64)):try:image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)if image is None:return Noneimage = cv2.resize(image, target_size)lbp = local_binary_pattern(image, 8, 1, method='uniform')(hist, _) = np.histogram(lbp.ravel(), bins=np.arange(0, 10), range=(0, 10))hist = hist.astype("float")hist /= (hist.sum() + 1e-7)return histexcept:return None
数据加载函数:load_svm_data函数从指定的真假人脸图像文件夹中读取图像,提取 LBP 特征,并为每个样本标记对应的标签(0 表示假脸,1 表示真脸):
def load_svm_data(fake_dir, real_dir):X, y = [], []for img_name in os.listdir(fake_dir):img_path = os.path.join(fake_dir, img_name)features = extract_lbp_features(img_path)if features is not None:X.append(features)y.append(0)for img_name in os.listdir(real_dir):img_path = os.path.join(real_dir, img_name)features = extract_lbp_features(img_path)if features is not None:X.append(features)y.append(1)return np.array(X), np.array(y)
模型训练与评估函数:train_svm函数加载训练数据和测试数据,训练 SVM 模型,并对模型进行评估,输出准确率和分类报告:
def train_svm():X_train, y_train = load_svm_data("training_fake", "training_real")X_test, y_test = load_svm_data("testing_fake", "testing_real")svm = SVC(kernel='rbf', random_state=42)svm.fit(X_train, y_train)y_pred = svm.predict(X_test)accuracy = accuracy_score(y_test, y_pred)print("\n支持向量机模型评估结果:")print("准确率:", accuracy)print(classification_report(y_test, y_pred))return accuracy
(三)ResNet18 模型实现
自定义数据集类:FaceDataset类继承自Dataset,用于加载真假人脸图像数据。在初始化时,将图像路径和对应的标签存储起来,并支持数据增强操作(如随机水平翻转):
class FaceDataset(Dataset):def __init__(self, fake_dir, real_dir, transform=None):self.image_paths = []self.labels = []for img_name in os.listdir(fake_dir):self.image_paths.append(os.path.join(fake_dir, img_name))self.labels.append(0)for img_name in os.listdir(real_dir):self.image_paths.append(os.path.join(real_dir, img_name))self.labels.append(1)self.transform = transformdef __len__(self):return len(self.image_paths)def __getitem__(self, idx):try:image = Image.open(self.image_paths[idx]).convert("RGB")label = self.labels[idx]if self.transform:image = self.transform(image)return image, labelexcept:return None
ResNet18 模型定义与修改:get_resnet18函数获取预训练的 ResNet18 模型,并修改其最后一层全连接层和添加 Sigmoid 激活函数:
def get_resnet18():model = models.resnet18(pretrained=True)num_ftrs = model.fc.in_featuresmodel.fc = nn.Linear(num_ftrs, 1)model = nn.Sequential(model, nn.Sigmoid())return model
训练与评估函数:train_resnet18函数对数据进行预处理,创建数据集和数据加载器,初始化模型、损失函数和优化器,进行模型训练和测试评估,并绘制训练过程中的损失和准确率曲线:
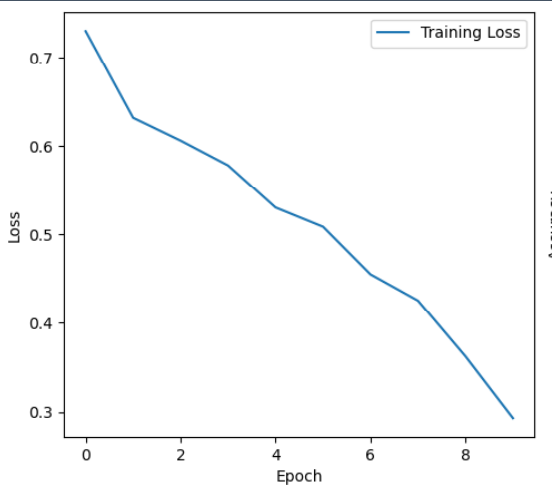
def train_resnet18():transform = transforms.Compose([transforms.Resize((224, 224)),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])def create_dataset(fake_dir, real_dir, transform):dataset = FaceDataset(fake_dir, real_dir, transform)valid_indices = [i for i in range(len(dataset)) if dataset[i] is not None]return torch.utils.data.Subset(dataset, valid_indices)train_dataset = create_dataset("training_fake", "training_real", transform)test_dataset = create_dataset("testing_fake", "testing_real", transform)train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4)test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False, num_workers=4)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = get_resnet18().to(device)criterion = nn.BCELoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.001)losses = []accuracies = []model.train()for epoch in range(10):running_loss = 0.0for images, labels in train_loader:images, labels = images.to(device), labels.float().to(device).unsqueeze(1)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()epoch_loss = running_loss / len(train_loader)losses.append(epoch_loss)print(f"Epoch {epoch + 1}/10, Loss: {epoch_loss:.4f}")model.eval()correct, total = 0, 0test_images = []test_labels = []test_predictions = []with torch.no_grad():for images, labels in test_loader:test_images.extend(images.cpu().numpy())test_labels.extend(labels.cpu().numpy())images, labels = images.to(device), labels.float().to(device).unsqueeze(1)outputs = model(images)predicted = (outputs > 0.5).float()total += labels.size(0)correct += (predicted == labels).sum().item()test_predictions.extend(predicted.cpu().numpy())accuracy = correct / totalprint("\nResNet18模型评估结果:")print(f"准确率: {accuracy:.4f}")plt.figure(figsize=(12, 5))plt.subplot(1, 2, 1)plt.plot(losses, label='Training Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.subplot(1, 2, 2)plt.plot(accuracies, label='Training Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.show()return accuracy, test_images, test_labels, test_predictions
可视化随机五张识别结果:visualize_random_five函数从测试数据中随机选取五张图像,展示其真实标签和预测结果:
def visualize_random_five(test_images, test_labels, test_predictions):indices = random.sample(range(len(test_images)), 5)plt.figure(figsize=(15, 7))for i, idx in enumerate(indices):img = np.transpose(test_images[idx], (1, 2, 0))img = (img - np.min(img)) / (np.max(img) - np.min(img))label = 'Real' if test_labels[idx] == 1 else 'Fake'prediction = 'Real' if test_predictions[idx] == 1 else 'Fake'plt.subplot(1, 5, i + 1)plt.imshow(img)plt.title(f'Label: {label}\nPred: {prediction}')plt.axis('off')plt.show()
(四)主程序入口
在主程序中,依次训练 SVM 模型和 ResNet18 模型,比较两个模型的准确率并进行可视化,同时可视化 ResNet18 模型随机五张测试图像的识别结果:
if __name__ == "__main__":print("正在训练支持向量机模型...")svm_accuracy = train_svm()print("\n正在训练ResNet18模型...")resnet_accuracy, test_images, test_labels, test_predictions = train_resnet18()models = ['SVM', 'ResNet18']accuracies = [svm_accuracy, resnet_accuracy]plt.bar(models, accuracies)plt.xlabel('Models')plt.ylabel('Accuracy')plt.title('Model Accuracy Comparison')for i, v in enumerate(accuracies):plt.text(i, v, str(round(v, 4)), ha='center')plt.show()visualize_random_five(test_images, test_labels, test_predictions)
三、实验结果与分析
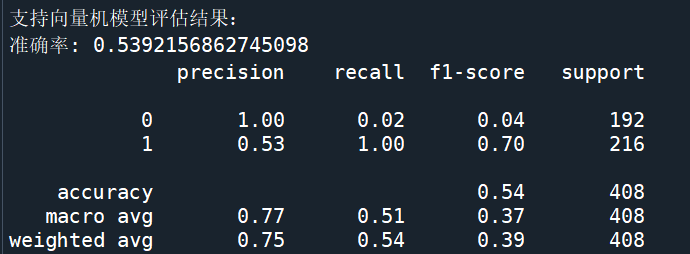
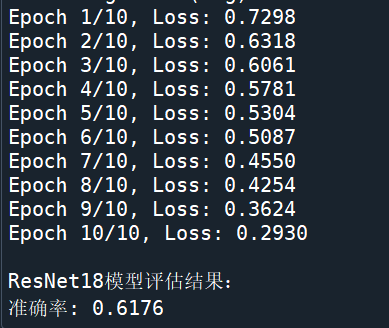

从训练过程输出的日志来看,ResNet18 模型在 10 个训练轮次(Epoch)中,损失(Loss)不断下降,从 Epoch 1 的 0.7298 逐步降低到 Epoch 10 的 0.2930 ,这表明模型在训练过程中不断学习,对训练数据的拟合能力逐渐增强。最终在测试集上得到的准确率为 0.6176 。
对比 SVM 模型与 ResNet18 模型的准确率柱状图,SVM 模型的准确率为 0.5392,而 ResNet18 模型的准确率为 0.6176,ResNet18 模型的准确率相对更高。这是因为 ResNet18 作为深度神经网络,具备强大的自动特征提取能力,能够从大量图像数据中学习到更复杂、更具区分性的特征表示,从而在分类任务中表现更优。而 SVM 虽然在处理一些简单特征和小规模数据时表现良好,但在面对人脸真假检测这种复杂的图像分类任务时,其特征表示能力相对有限,导致准确率略低。
观察 ResNet18 模型训练损失曲线,其呈现出持续下降的趋势,说明模型在训练过程中能够有效优化,不断调整参数以降低损失。但从下降的速率和幅度来看,在前期下降较快,后期下降逐渐变缓,这可能意味着模型在后期逐渐接近收敛状态,进一步提升的难度增大。同时,由于未给出测试集上的损失或准确率随 Epoch 的变化情况,暂时无法确定是否存在过拟合现象。不过仅从当前训练损失持续下降且测试准确率有所提升来看,模型在一定程度上能够泛化到测试数据,但后续仍需进一步分析验证。
从这五张随机选取的测试图像可视化结果来看,模型在部分样本上预测准确,但也存在误判情况。其中,第一张、第二张和第四张图像真实标签为 “Real”,模型预测也为 “Real” ,说明对于这类图像,模型能够较好地提取特征并做出正确判断。第五张图像真实标签为 “Fake”,模型预测也为 “Fake”,表明模型在识别这类假脸图像时具备一定能力。
然而,第三张图像真实标签为 “Fake”,但模型却预测为 “Real” ,出现了误判。这可能是由于该假脸图像具有一些与真脸相似的特征,或者其合成技术较为特殊,导致模型提取的特征不足以准确区分真假。通过对这类误判样本的深入分析,我们可以针对性地改进模型。比如,进一步挖掘该图像中模型未能有效捕捉的特征差异,调整模型结构或训练策略,以增强模型对这类特殊样本的识别能力。这也再次强调了在实际应用中,不能仅依赖模型的准确率指标,还需关注模型在具体样本上的预测表现,通过对误判样本的研究来不断优化模型性能。
四、总结与展望
本文通过代码实现并对比了 SVM 结合 LBP 特征与 ResNet18 神经网络在人脸真假检测任务中的应用。实验结果表明,ResNet18 在准确率上优于 SVM,展现出深度神经网络在图像分类任务中的强大性能。SVM 结合 LBP 特征的方法虽然计算相对简单,但在复杂图像特征提取方面存在不足,导致准确率受限。
在实际应用中,对于计算资源有限、数据规模较小的场景,SVM 方法可作为一种轻量级的解决方案;而对于追求高准确率、数据量充足的场景,ResNet18 等深度神经网络更为合适。未来可尝试将两者结合,比如先用 SVM 进行初步筛选,再利用 ResNet18 进行精细分类,发挥各自优势,提升检测性能。
此外,当前模型的准确率仍有提升空间。未来可从以下几方面改进:一是进一步优化模型结构,如调整 ResNet18 的层数、参数,或尝试其他更先进的神经网络架构;二是扩充数据集,引入更多不同场景、光照条件、合成技术的人脸图像,增强模型的泛化能力。