MindSpore框架学习项目-ResNet药物分类-模型训练
目录
3.模型训练
3.1模型训练
3.1.1 定义优化器和损失函数
定义优化器和损失函数代码解析
3.1.2定义训练、推理函数
定义训练、推理函数代码解释
3.2模型保存
模型保存代码说明
3.3绘制acc和loss的曲线
本项目可以在华为云modelart上租一个实例进行,也可以在配置至少为单卡3060的设备上进行
https://console.huaweicloud.com/modelarts/
Ascend环境也适用,但是注意修改device_target参数
需要本地编译器的一些代码传输、修改等可以勾上ssh远程开发
说明:项目使用的数据集来自华为云的数据资源。项目以深度学习任务构建的一般流程展开(数据导入、处理 > 模型选择、构建 > 模型训练 > 模型评估 > 模型优化)。
主线为‘一般流程’,同时代码中会标注出一些要点(# 要点1-1-1:设置使用的设备
)作为支线,帮助学习mindspore框架在进行深度学习任务时一些与pytorch的差异。
可以只看目录中带数字标签的部分来快速查阅代码。
本系列
MindSpore框架学习项目-ResNet药物分类-数据增强-CSDN博客
MindSpore框架学习项目-ResNet药物分类-构建模型-CSDN博客
MindSpore框架学习项目-ResNet药物分类-模型训练-CSDN博客
MindSpore框架学习项目-ResNet药物分类-模型评估-CSDN博客
MindSpore框架学习项目-ResNet药物分类-模型优化-CSDN博客
参考内容:https://www.mindspore.cn/华为自研的国产AI框架,训推一体,支持动态图、静态图,全场景适用,有着不错的生态
本项目可以在华为云modelart上租一个实例进行,也可以在配置至少为单卡3060的设备上进行
https://console.huaweicloud.com/modelarts/
Ascend环境也适用,但是注意修改device_target参数
需要本地编译器的一些代码传输、修改等可以勾上ssh远程开发
说明:项目使用的数据集来自华为云的数据资源。项目以深度学习任务构建的一般流程展开(数据导入、处理 > 模型选择、构建 > 模型训练 > 模型评估 > 模型优化)。
主线为‘一般流程’,同时代码中会标注出一些要点(# 要点1-1-1:设置使用的设备
)作为支线,帮助学习mindspore框架在进行深度学习任务时一些与pytorch的差异。
可以只看目录中带数字标签的部分来快速查阅代码。
3.模型训练
3.1模型训练
要求:
补充如下代码的空白处
主要完成:
1. 定义优化器为Momentum优化器
2. 定义损失函数为SoftmaxCrossEntropyWithLogits损失函数,sparse=True, reduction='mean'
3. 模型编译:利用函数式编程实现loss的计算,并返回loss和模型预测值logits
4. 利用value_and_grad API定义反向传播函数
5. 设置模型为预测模式
3.1.1 定义优化器和损失函数
定义优化器为Momentum优化器,定义损失函数为SoftmaxCrossEntropyWithLogits损失函数,sparse=True, reduction='mean'
num_epochs = 3
patience = 5 #用于早停的阈值,如果模在5轮都没有提高性能(精度)就结束训练
lr = nn.cosine_decay_lr(min_lr=0.00001, max_lr=0.001, total_step=step_size_train * num_epochs,
step_per_epoch=step_size_train, decay_epoch=num_epochs)# 要点3-1-1:定义优化器为Momentum优化器, 动量因子设置为0.9
opt = nn.Momentum(params=network.trainable_params(), learning_rate=lr, momentum=0.9)# 要点3-1-2:定义损失函数为SoftmaxCrossEntropyWithLogits损失函数,sparse=True, reduction='mean'
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
model = ms.Model(network, loss_fn, opt, metrics={'acc'})best_acc = 0
best_ckpt_dir = "./BestCheckpoint"
best_ckpt_path = "./BestCheckpoint/resnet50-best.ckpt"
定义优化器和损失函数代码解析
1. 学习率调度(余弦衰减)
lr = nn.cosine_decay_lr(...) 生成余弦衰减学习率序列:
参数:初始学习率 max_lr=0.001,最终学习率 min_lr=0.00001,总步数 step_size_train*num_epochs(总训练步数 = 每轮步数 × 轮数)。
作用:训练初期使用较大学习率快速收敛,后期逐步降低学习率精细调整,避免震荡,提升模型收敛稳定性。
2. 优化器定义(Momentum)
opt = nn.Momentum(...) 定义动量优化器:
参数:params=network.trainable_params():优化网络的可训练参数。
learning_rate=lr:使用上述余弦衰减学习率。
momentum=0.9:动量因子(历史梯度的加权系数),0.9 表示保留 90% 的历史梯度方向,10% 当前梯度,加速收敛并抑制噪声。
3. 损失函数定义(交叉熵)
loss_fn = nn.SoftmaxCrossEntropyWithLogits(...) 定义分类任务损失函数:
特性:sparse=True:标签为稀疏整数(如[0, 1, 2]),无需独热编码,减少内存占用。
reduction='mean':对批量样本的损失取平均,输出标量值,便于反向传播计算梯度。
4. 模型封装与评估指标
model = ms.Model(...) 封装训练组件:
参数:网络network、损失函数loss_fn、优化器opt、评估指标{'acc'}(准确率)。
作用:整合训练所需的所有组件,支持调用model.train()和model.eval()完成训练与评估流程。
5. 最佳模型保存配置
best_acc、best_ckpt_dir等变量记录训练过程中验证集最高准确率及对应模型路径,用于训练结束后保存最优模型参数(如resnet50-best.ckpt),避免过拟合,保留泛化能力最佳的模型。
3.1.2定义训练、推理函数
模型编译:利用函数式编程实现loss的计算,并返回loss和模型预测值logits;利用value_and_grad API定义反向传播函数
训练函数train_loop
def train_loop(model, dataset, loss_fn, optimizer):
# 要点3-1-3:模型编译:利用函数式编程实现loss的计算,并返回loss和模型预测值logits
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits,label)
return loss, logits # 要点3-1-4:利用value_and_grad API定义反向传播函数
grad_fn = ms.ops.value_and_grad(forward_fn, None, opt.parameters, has_aux=True) def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
loss = ops.depend(loss, optimizer(grads))
return loss
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label) if batch % 100 == 0 or batch == step_size_train - 1:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")测试函数test_loop
from sklearn.metrics import classification_reportdef test_loop(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size()
# 要点3-1-5:设置模型为预测模式
model.set_train(False)
total, test_loss, correct = 0, 0, 0
y_true = []
y_pred = []
for data, label in dataset.create_tuple_iterator():
y_true.extend(label.asnumpy().tolist())
pred = model(data)
total += len(data)
test_loss += loss_fn(pred, label).asnumpy()
y_pred.extend(pred.argmax(1).asnumpy().tolist())
correct += (pred.argmax(1) == label).asnumpy().sum()
test_loss /= num_batches
correct /= total
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
print(classification_report(y_true,y_pred,target_names= list(index_label_dict.values()),digits=3))
return correct,test_loss定义训练、推理函数代码解释
1. 训练循环 train_loop
前向传播与损失计算(要点 3-1-3)
def forward_fn(data, label):
logits = model(data) # 模型前向传播,输出未归一化的预测值(logits)
loss = loss_fn(logits, label) # 计算交叉熵损失(含Softmax操作)
return loss, logits # 返回损失值和预测logits(用于后续梯度计算)
作用:定义单次前向传播流程,分离模型推理与损失计算,便于后续反向传播梯度获取。
反向传播与梯度更新(要点 3-1-4)
grad_fn = ms.ops.value_and_grad(forward_fn, None, opt.parameters, has_aux=True)
def train_step(data, label):
(loss, _), grads = grad_fn(data, label) # 同时获取损失值和参数梯度
loss = ops.depend(loss, optimizer(grads)) # 确保梯度更新完成后再返回损失(依赖控制)
return loss
value_and_grad:MindSpore 内置函数,自动计算forward_fn的输出值和参数梯度,提升反向传播效率。
梯度更新:optimizer(grads)使用 Momentum 优化器更新网络参数,ops.depend保证梯度更新与损失计算的顺序性(避免异步执行错误)。
批量训练与日志输出
size = dataset.get_dataset_size() # 训练集总样本数(用于进度显示)
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label) # 执行单步训练(前向+反向+梯度更新)
if batch % 100 == 0 or batch == step_size_train - 1:
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]") # 打印训练损失和进度
核心逻辑:按批次迭代训练数据,通过step_size_train控制打印频率,实时监控训练过程。
2. 测试循环 test_loop
模型预测模式设置(要点 3-1-5)
model.set_train(False) # 关闭训练模式(冻结BN层均值/方差,停用Dropout等)
作用:确保测试时使用稳定的统计量(如 BN 的全局均值 / 方差),而非当前批次的统计量,避免预测结果波动。
批量推理与指标计算
for data, label in dataset.create_tuple_iterator():
pred = model(data) # 模型推理,输出logits
test_loss += loss_fn(pred, label).asnumpy() # 累加批次损失
correct += (pred.argmax(1) == label).sum() # 统计正确分类样本数
y_true.extend(label.asnumpy()) # 收集真实标签(用于分类报告)
y_pred.extend(pred.argmax(1).asnumpy()) # 收集预测标签(用于分类报告)
指标计算:准确率:correct / total,反映模型整体分类能力。
平均损失:test_loss / num_batches,衡量预测值与真实标签的平均差异。
分类报告:使用sklearn.classification_report输出各分类的精确率、召回率、F1 值,便于细粒度评估模型性能。
3.2模型保存
要求:
将训练后的权重保存到代码指定路径下即可
1. 设置条件:得到训练中得到的最优模型权重
2. 利用save_checkpoint API对模型进行保存
3. 模型训练
开始训练,定义收集精确率和损失的承载对象--列表对象(acc、loss都是连续型的,并且有对应关系)
no_improvement_count = 0
acc_list = []
loss_list = []
stop_epoch = num_epochs
for t in range(num_epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(network, dataset_train, loss_fn, opt)
acc,loss = test_loop(network, dataset_val, loss_fn)
acc_list.append(acc)
loss_list.append(loss)
# 要点3-2-1:设置条件:利用计算的acc指标,得到训练中得到的最优模型权重
if best_acc < acc:
best_acc = acc
if not os.path.exists(best_ckpt_dir):
os.mkdir(best_ckpt_dir)
# 要点3-2-2:利用save_checkpoint API对模型进行保存, 保存的路径为best_ckpt_path
ms.save_checkpoint(network,best_ckpt_path)
no_improvement_count = 0
else:
no_improvement_count += 1
if no_improvement_count > patience:
print('Early stopping triggered. Restoring best weights...')
stop_epoch = t
break
print("Done!")
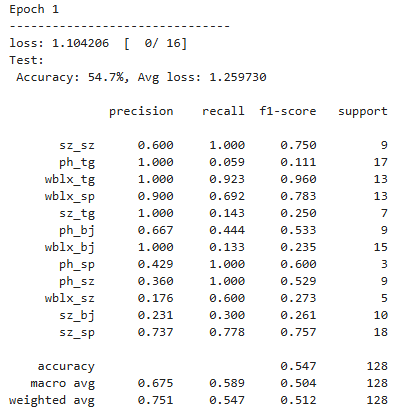
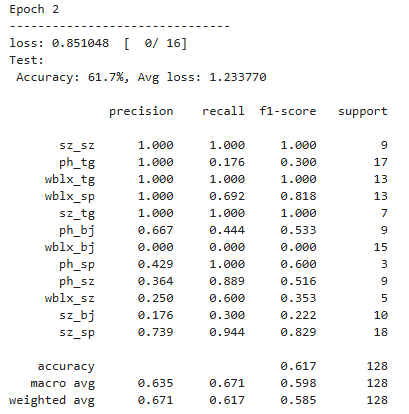
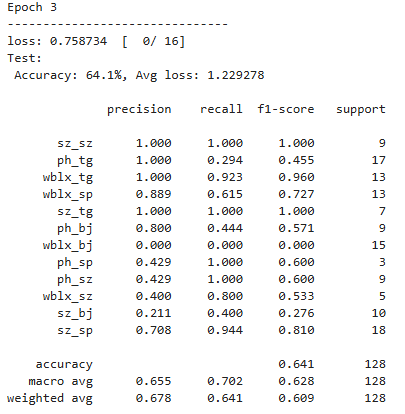
从训练过程的结果来看,每一轮的损失值都在下降,acc也在相应提高,后续增加训练轮次或者每轮训练的批次(让模型更好的拟合数据),应该可以得到更好的模型分类效果
模型保存代码说明
1. 初始化与变量定义
no_improvement_count:记录验证集准确率连续未提升的轮次数(用于早停判断)。
acc_list/loss_list:保存每轮验证集的准确率和损失(用于后续分析训练趋势)。
stop_epoch:记录提前停止时的轮次(默认等于总轮次num_epochs)。
2. 训练 - 验证主循环
for t in range(num_epochs):print(f"Epoch {t+1}\n-------------------------------")
train_loop(network, dataset_train, loss_fn, opt) # 执行第t+1轮训练
acc, loss = test_loop(network, dataset_val, loss_fn) # 验证集评估,获取准确率和损失
acc_list.append(acc) # 记录验证准确率
loss_list.append(loss) # 记录验证损失
逻辑:按总轮次num_epochs循环,每轮先调用train_loop完成训练,再调用test_loop评估验证集性能,记录指标。
3. 最佳模型保存(要点 3-2-1/3-2-2)
if best_acc < acc: # 当前轮验证准确率优于历史最佳
best_acc = acc # 更新最佳准确率if not os.path.exists(best_ckpt_dir): # 创建保存目录(若不存在)
os.mkdir(best_ckpt_dir)
ms.save_checkpoint(network, best_ckpt_path) # 保存当前模型权重到指定路径
no_improvement_count = 0 # 重置未提升计数
作用:仅当验证集准确率超过历史最佳时,保存模型权重(resnet50-best.ckpt),确保最终保留的是验证集表现最优的模型。
4. 早停机制(防止过拟合)
else: # 当前轮验证准确率未提升
no_improvement_count += 1 # 未提升计数+1if no_improvement_count > patience: # 连续未提升次数超过耐心值(如5轮)print('Early stopping triggered. Restoring best weights...')
stop_epoch = t # 记录提前停止的轮次break # 终止训练循环
逻辑:若验证集准确率连续patience轮未提升,提前终止训练,避免过拟合(模型在训练集上继续优化但验证集性能下降)。
3.3绘制acc和loss的曲线
import matplotlib.pyplot as pltdef plot_training_process(acc_list, loss_list):
epochs = range(1, len(acc_list) + 1)
plt.figure(figsize=(10, 7))# 绘制训练精度曲线
plt.subplot(121)
plt.plot(epochs, acc_list, 'b-', label='Training Accuracy')
plt.title('Training Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()# 绘制损失函数曲线
plt.subplot(122)
plt.plot(epochs, loss_list, 'r-', label='Training Loss')
plt.title('Training Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend() plt.subplots_adjust(wspace=0.4) plt.show()plot_training_process(acc_list, loss_list)
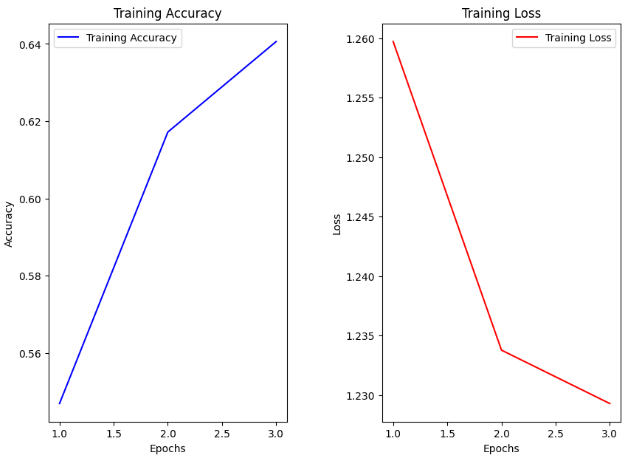
acc_list, loss_list 训练过程中记录下来的连续型数值列表