理性地倾听与表达:检索算法的语言学改进
论文标题
Rational Retrieval Acts: Leveraging Pragmatic Reasoning to Improve Sparse Retrieval
论文地址
https://arxiv.org/pdf/2505.03676
代码地址
https://github.com/arthur-75/Rational-Retrieval-Acts
作者背景
巴黎萨克雷大学,索邦大学,法国国家科学研究中心
动机
文档检索算法对用户query和候选Document进行匹配打分,从而挑选出能够回答用户问题的信息。但当前的q-D匹配算法一般只考虑词语浅层语义,缺乏对用户意图的深层理解,于是在实践中我们往往发现:再面对用户的模糊、复杂或措辞多变的问题时,难以精准找到合理的文档
对此,作者利用语言学中“理性言语行为”的思想,提出了一种迭代算法,能够模拟说话人与倾听者互相揣摩对方意图的行为,从而提高检索算法的准确性
理性言语行为
理性言语行为(Rational Speech Act model, RSA)的核心思想是:
说话者和听话者都是理性的个体,他们在交流中会基于对彼此知识、目标和意图的推测,做出最合适的语言选择和解释
RSA 是一种概率模型,它将言语交流建模为一种贝叶斯推理过程,包括以下三类参与者:
- 字面听者 L0:根据语言的语义直接解释话语
- 语用说话者 S1:根据听者可能的理解方式,选择最符合自己意图的表达
- 语用听者 L1:观察S1的话语,推断其背后可能的意图
从L0到S1再到L1,这个过程可以不断递归地迭代。但一般情况下只迭代一轮
本文方法
本文提出理性检索(Rational Retrieval Acts,RRA),将语言学中的理性言语行为模型引入稀疏检索,具体过程如下:
-
初始词典表示:首先从一个基础的稀疏检索模型出发,获取每个词和文档的基础相关性权重w(t,d),并对其做简单的平滑转换得到L(t,d),确保L>0
-
字面听者L0建模:根据单个词来判断相关文档分布,基于初始词典值的归一化分数构建,公式如下,其中P(d)是文档先验概率
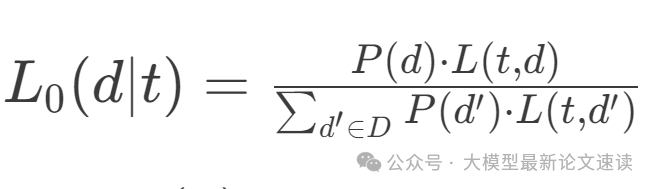
-
语用说话人S1建模:假设理性说话人想要的信息在文档d中,那么它需要使用让文档d被选中概率最大的表达,即:
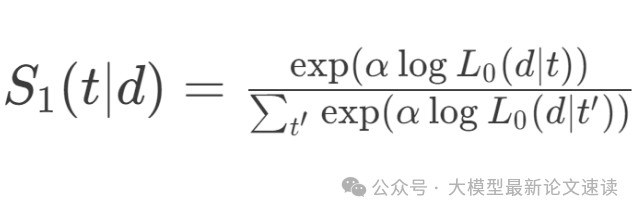
其中α是调节语用程度的超参数,α > 1时会使说话人更加偏好概率大的词, α → 0时则趋向于均匀分布(完全不讲究用词,随便表达),此公式精准刻画了理性说话人:用户具备不同词语和不同文档匹配效果的全局认知,然后从整个文档集合中挑选更能选中目标文档d的词汇
- 语用听者L1建模:与L0类似,只不过初始字典分数被替换成了理性说话人视角的词语-文档匹配分数
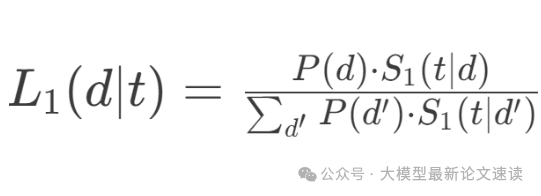
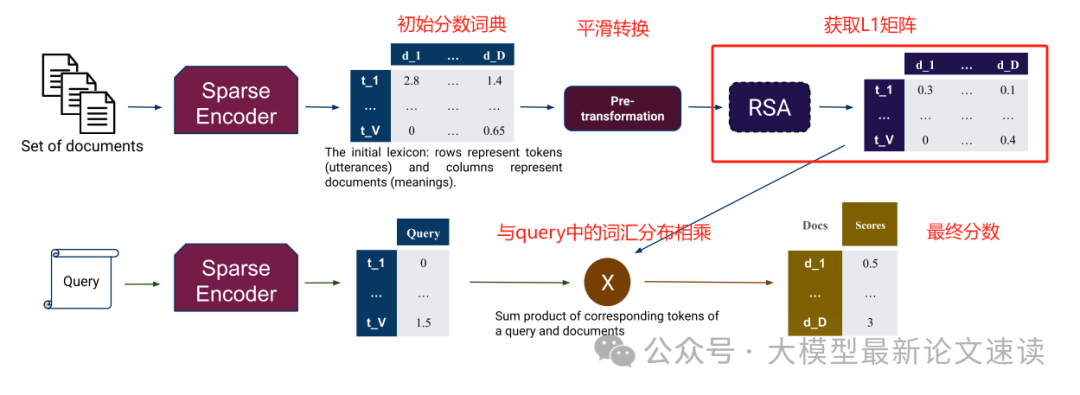
- 文档表示与检索打分:经过上述推理,我们获得了用户query中每个词汇t,相对于所有候选文档的相关性打分L1,并且这个分数是经过语用校正的。由于L1矩阵的规模很大,作者还对所有“词t未出现于文档d中”的情况进行了特殊处理:使用词t与文档d各自的全局因子相乘作为近似表示
最后,将L1与用户query中的词汇分数分布相乘,便可得到最终的检索得得分。整个流程如下图所示:
实验结果
一、引入RSA前后效果对比
将RSA融合到不同稀疏检索模型中的效果,包括SPLADEv3(训练于MS MARCO的神经稀疏模型)、SPARTA(BERT派生的稀疏模型)、DeepImpact、UniCOIL等(都没有拿测试数据微调),以及传统的BM25,采用nDCG@10指标进行评价,结果如下:
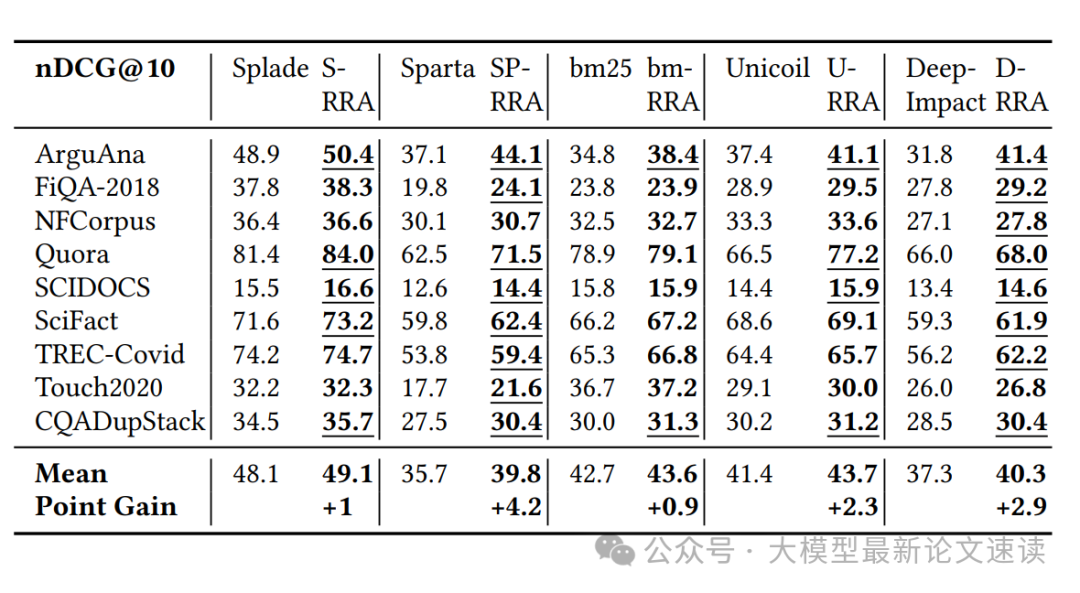
实验结果表明,引入RSA后,这些稀疏模型在所有数据集上的排序质量都有所提高。不过其中BM25上的提高较小,只有0.9,作者认为这是由于其本身已经通过IDF考虑了部分全局信息
二、与SOTA模型对比
选择上面实验中效果最好的Splade+RRA方案作为实验组,在BEIR基准上与其他增强基线策略进行对比,结果如下:
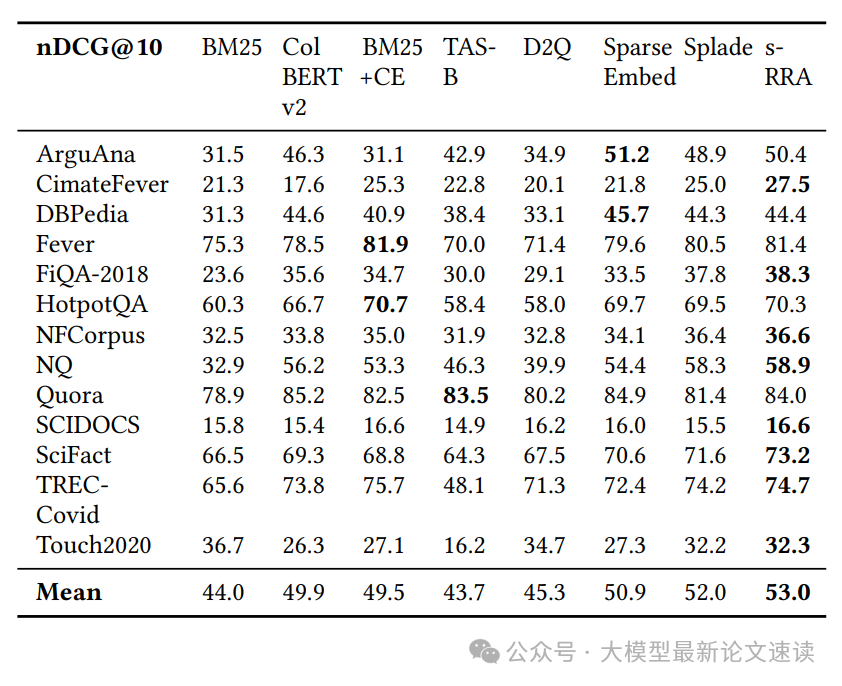
可见实验组的平均得分最高,RRA的引入使Splade方案提升了1个点
三、语用强度α影响分析
作者在不同数据集上,测试了不同α参数下Splade+RRA策略的最终效果:
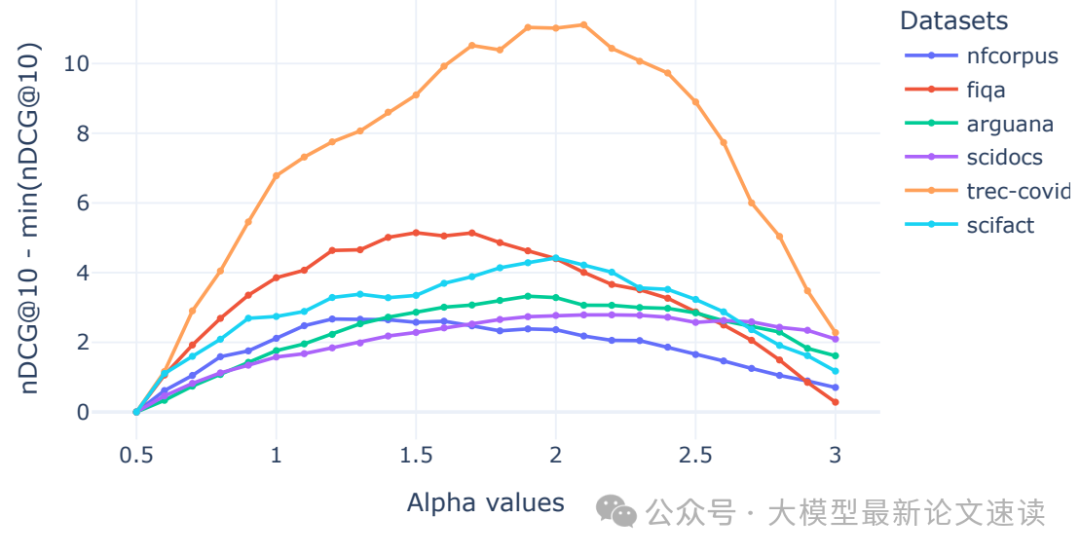
实验表明,当α太高或太低时性能都会下降(过高会使说话人过于偏执只选极少数词,过低则近似随机选词),不同数据集的最佳值略有不同,实践中可以先采样一些样本或生成伪数据来对α进行调试