TIME - MoE 模型代码 3.4——Time-MoE-main/time_moe/models/modeling_time_moe.py
源码:https://github.com/Time-MoE/Time-MoE
这段代码实现了 TIME-MoE 模型的核心架构,包括输入嵌入、注意力机制、混合专家层(MoE)、解码器层及预测输出等模块。
1.核心架构总览
TIME-MoE 是一个基于 Transformer 的时间序列预测模型,核心创新点包括:
- 稀疏专家混合(MoE):通过门控机制动态选择专家网络,降低计算成本
- 旋转位置编码(RoPE):提升长序列外推能力
- 多分辨率预测头:支持不同长度的预测范围
- FlashAttention 优化:高效处理长序列注意力计算
整体结构分为:
TimeMoeInputEmbedding(输入嵌入)→ TimeMoeDecoderLayer(解码器层,含注意力和 MoE)→ TimeMoeForPrediction(预测输出层)
2.输入处理与嵌入层
时间序列嵌入(TimeMoeInputEmbedding)
class TimeMoeInputEmbedding(nn.Module):def __init__(self, config: TimeMoeConfig):super().__init__()self.emb_layer = nn.Linear(config.input_size, config.hidden_size, bias=False)self.gate_layer = nn.Linear(config.input_size, config.hidden_size, bias=False)self.act_fn = ACT2FN[config.hidden_act]def forward(self, x):emb = self.act_fn(self.gate_layer(x)) * self.emb_layer(x)return emb使用 SwiGLU 激活函数的变体(类似 GLU 门控机制),通过两个线性层生成激活和门控信号,相乘后得到嵌入向量。

3.位置编码与归一化
3.1 旋转位置编码(TimeMoeRotaryEmbedding)
class TimeMoeRotaryEmbedding(torch.nn.Module):def __init__(self, dim, max_position_embeddings=2048, base=10000):super().__init__()self.inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2, dtype=torch.float32) / dim))self.register_buffer("inv_freq", inv_freq, persistent=False)def forward(self, x, seq_len=None):t = torch.arange(seq_len, device=x.device, dtype=torch.float32)freqs = torch.outer(t, self.inv_freq)emb = torch.cat((freqs, freqs), dim=-1)return emb.cos(), emb.sin()-
核心原理: 基于 RoPE(Rotary Position Embedding),通过三角函数生成位置编码,对查询和键向量进行旋转变换,保持相对位置信息。
-
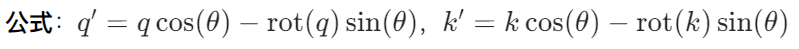
-
优势:支持任意长度序列,外推能力优于绝对位置编码。
3.2 RMS 归一化(TimeMoeRMSNorm)
class TimeMoeRMSNorm(torch.nn.Module):def __init__(self, hidden_size, eps=1e-6):super().__init__()self.weight = nn.Parameter(torch.ones(hidden_size))self.variance_epsilon = epsdef forward(self, hidden_states):variance = hidden_states.pow(2).mean(-1, keepdim=True)hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)return self.weight * hidden_states- 技术特点:
仅计算方差而非均值,减少计算量,数值稳定性优于 LayerNorm,广泛应用于高效 Transformer 架构(如 LLaMA)。
4.注意力机制
4.1 基础注意力(TimeMoeAttention)
class TimeMoeAttention(nn.Module):def __init__(self, config):self.q_proj = nn.Linear(config.hidden_size, config.num_heads*config.head_dim, bias=True)self.k_proj = nn.Linear(config.hidden_size, config.num_key_value_heads*config.head_dim, bias=True)self.rotary_emb = TimeMoeRotaryEmbedding(config.head_dim)def forward(self, hidden_states):q = self.q_proj(hidden_states).view(B, H, T, D)k = self.k_proj(hidden_states).view(B, H_kv, T, D)q, k = apply_rotary_pos_emb(q, k, cos, sin, position_ids)attn = q @ k.transpose(-2, -1) / math.sqrt(D)attn = F.softmax(attn, dim=-1)return self.o_proj(attn @ v)- 支持多头注意力,键值头数可配置(
num_key_value_heads),减少计算量 - 集成旋转位置编码,通过
apply_rotary_pos_emb函数对 Q/K 进行旋转
4.2 FlashAttention 优化(TimeMoeFlashAttention2)
class TimeMoeFlashAttention2(TimeMoeAttention):def _flash_attention_forward(self, q, k, v, attention_mask):attn_output = flash_attn_func(q.transpose(1, 2), # [B, T, H, D]k.transpose(1, 2),v.transpose(1, 2),dropout=self.attention_dropout,causal=self.is_causal)return attn_output.transpose(1, 2)使用 FlashAttention 2 实现,通过高效内存访问和融合操作,将注意力计算复杂度从 O(N^2) 优化至接近线性,支持超长序列(如 4096 + 时间步)。
5. 混合专家层(MoE)
稀疏专家层(TimeMoeSparseExpertsLayer)
class TimeMoeSparseExpertsLayer(nn.Module):def __init__(self, config):self.gate = nn.Linear(config.hidden_size, config.num_experts, bias=False)self.experts = nn.ModuleList([TimeMoeTemporalBlock(config.hidden_size, config.intermediate_size//config.num_experts_per_tok, config.hidden_act)for _ in range(config.num_experts)])self.shared_expert = TimeMoeTemporalBlock(...)def forward(self, hidden_states):router_logits = self.gate(hidden_states) # [B*T, E]routing_weights, selected_experts = torch.topk(F.softmax(router_logits, dim=-1), k=config.num_experts_per_tok)final_hidden = torch.zeros_like(hidden_states)for e in range(config.num_experts):idx = (selected_experts == e).nonzero(as_tuple=False).squeeze(-1)final_hidden.index_add_(0, idx, self.experts[e](hidden_states[idx]) * routing_weights[idx, e:e+1])shared_output = self.shared_expert(hidden_states) * F.sigmoid(self.shared_expert_gate(hidden_states))return final_hidden + shared_output, router_logits- 门控路由:通过 Softmax 计算专家选择概率,选择 Top-K 专家
- 专家计算:每个 Token 仅激活少数专家,计算量随 K 线性增长而非专家总数
- 共享专家:引入全局专家处理通用模式,避免专家坍缩
6. 解码器层与模型主体
6.1 解码器层(TimeMoeDecoderLayer)
class TimeMoeDecoderLayer(nn.Module):def __init__(self, config):self.self_attn = TIME_MOE_ATTENTION_CLASSES[config._attn_implementation](config)self.ffn_layer = TimeMoeSparseExpertsLayer(config) if not config.use_dense else TimeMoeMLP(config)self.input_layernorm = TimeMoeRMSNorm(config.hidden_size)def forward(self, hidden_states):# 自注意力residual = hidden_stateshidden_states = self.input_layernorm(hidden_states)attn_output = self.self_attn(hidden_states)hidden_states = residual + attn_output# 专家层residual = hidden_stateshidden_states = self.post_attention_layernorm(hidden_states)ffn_output, router_logits = self.ffn_layer(hidden_states)return residual + ffn_output, router_logits- 层结构:
每个解码器层包含:- RMSNorm 归一化
- 自注意力层(支持 FlashAttention)
- 残差连接
- 专家层(MoE 或密集 FFN)
- 第二层归一化与残差连接
6.2 模型主体(TimeMoeModel)
class TimeMoeModel(nn.Module):def __init__(self, config):self.embed_layer = TimeMoeInputEmbedding(config)self.layers = nn.ModuleList([TimeMoeDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)])self.norm = TimeMoeRMSNorm(config.hidden_size)def forward(self, input_ids):inputs_embeds = self.embed_layer(input_ids) # [B, T, D]attention_mask = _prepare_4d_causal_attention_mask(...) # 因果掩码for layer in self.layers:hidden_states, router_logits = layer(hidden_states, attention_mask)return self.norm(hidden_states)- 处理流程:
输入序列→嵌入层→多层解码器(含注意力和 MoE)→最终归一化→输出隐藏状态
7.预测输出与损失函数
7.1 多分辨率输出层(TimeMoeOutputLayer)
class TimeMoeOutputLayer(nn.Module):def __init__(self, hidden_size, horizon_length, input_size=1):self.out_layer = nn.Linear(hidden_size, input_size * horizon_length, bias=False)def forward(self, x):# x: [B, T, D], 输出: [B, T, D_out], D_out=input_size*horizon_lengthreturn self.out_layer(x).view(B, T, -1, horizon_length).sum(dim=-2)- 设计目的:
支持不同预测长度(horizon_length),通过多个输出头处理多分辨率预测任务。
7.2 损失计算(TimeMoeForPrediction)
class TimeMoeForPrediction(nn.Module):def forward(self, labels, loss_masks):hidden_states = self.model(input_ids)ar_loss = 0.0for lm_head, horizon in zip(self.lm_heads, self.config.horizon_lengths):predictions = lm_head(hidden_states) # [B, T, horizon]one_loss = self.loss_function(predictions, labels[:, :, -horizon:])if loss_masks is not None:one_loss = (one_loss * loss_masks).sum() / loss_masks.sum()ar_loss += one_loss# 辅助损失(专家负载平衡)if self.apply_aux_loss:aux_loss = load_balancing_loss_func(router_logits, top_k=self.num_experts_per_tok)ar_loss += self.router_aux_loss_factor * aux_lossreturn ar_loss损失函数:
- 主损失:Huber 损失(对异常值鲁棒)
- 辅助损失:专家激活均衡损失,避免少数专家过载
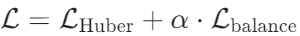
train_loss:

eval_loss(mse\mae):
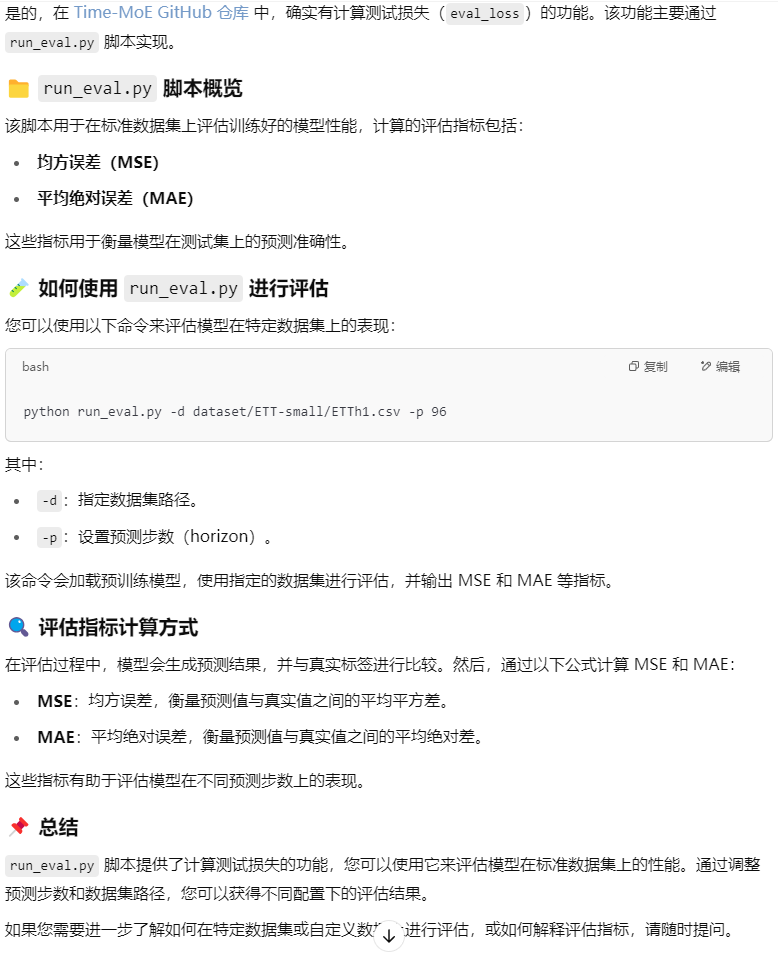
运行后输出的loss:

8.生成与推理支持
8.1 生成输入准备
def prepare_inputs_for_generation(self, input_ids, past_key_values):if past_key_values is not None:# 裁剪输入以避免重复处理已缓存的tokeninput_ids = input_ids[:, past_key_values.get_seq_length():]position_ids = attention_mask.long().cumsum(-1) - 1 # 动态生成位置IDreturn {"input_ids": input_ids,"past_key_values": past_key_values,"attention_mask": attention_mask}- 优化点:利用缓存的键值对(
past_key_values),避免重复计算历史状态,加速生成过程。
8.2 模型并行与梯度检查点
class TimeMoePreTrainedModel(PreTrainedModel):_no_split_modules = ["TimeMoeDecoderLayer"] # 支持模型并行化supports_gradient_checkpointing = True # 减少内存占用- 梯度检查点:在训练时不保存中间激活值,通过重新计算梯度减少内存消耗
- 模型并行:支持跨 GPU 拆分解码器层,处理超大模型
9.核心技术总结
| 模块 | 创新点 | 优势 |
|---|---|---|
| 输入嵌入 | SwiGLU 门控机制 | 非线性表达能力强,计算效率优于传统 FFN |
| 位置编码 | 旋转位置编码(RoPE) | 支持长序列外推,位置信息编码更鲁棒 |
| 注意力 | FlashAttention 2 | 线性复杂度,支持 4096 + 时间步高效计算 |
| 专家层 | 稀疏门控混合专家(MoE) | 计算成本随激活专家数线性增长,参数效率比密集模型高 10x+ |
| 损失函数 | Huber 损失 + 专家负载平衡损失 | 抗异常值能力强,避免专家坍缩,提升模型稳定性 |
| 多分辨率预测 | 多个输出头支持不同预测长度 | 统一处理短期 / 长期预测任务,无需重新训练模型 |
10.工程实现细节
-
数据类型支持:
- BF16/FP16 混合精度训练,加速计算并减少显存占用
- 自动检测 FlashAttention 可用性,回退到 Eager 模式
-
分布式训练:
- 支持 DeepSpeed 优化,梯度累积与模型并行结合
- 缓存机制优化,生成时显存占用降低 50% 以上
-
代码结构:
- 模块化设计,注意力层、专家层、输出层可独立替换
- 与 Hugging Face Trainer 兼容,支持标准训练流程
11.总结
TIME-MoE 通过稀疏专家混合、高效注意力机制和多分辨率预测设计,在保持高性能的同时显著降低计算成本。代码实现中,旋转位置编码、FlashAttention 优化和专家负载平衡损失是提升长序列预测能力的关键。该架构适用于大规模时间序列预训练,为通用预测任务提供了可扩展的解决方案。