大模型微调终极方案:LoRA、QLoRA原理详解与LLaMA-Factory、Xtuner实战对比
文章目录
- 一、微调概述
- 1.1 微调步骤
- 1.2 微调场景
- 二、微调方法
- 2.1 三种方法
- 2.2 方法对比
- 2.3 关键结论
- 三、微调技术
- 3.1 微调依据
- 3.2 LoRA
- 3.2.1 原理
- 3.2.2 示例
- 3.3 QLoRA
- 3.4 适用场景
- 四、微调框架
- 4.1 LLaMA-Factory
- 4.2 Xtuner
- 4.3 对比
一、微调概述
微调(Fine-tuning)是深度学习中的一种常见方法,它通常用于在预训练模型的基础上进行进一步的训练,以适应特定的任务。微调的主要目的是利用预训练模型已经学习到的通用知识,从而提高模型在特定任务上的性能。常见的微调框架有 LLaMA-Factory 和 XTuner 等。
1.1 微调步骤
以微调 Bert 为例,微调通常包括以下几个步骤:
- 加载预训练的BERT模型。
- 修改模型结构,将最后一层全连接层的参数进行修改,以适应文本分类任务。
- 设置优化器和损失函数,例如Adam优化器和交叉熵损失函数。
- 训练模型,使用微调技巧,如学习率调整、权重衰减、数据增强和早停。
- 评估模型性能,使用测试集进行评估,计算准确率、召回率等指标。
1.2 微调场景
微调通常用于以下场景:
- 修改模型的输出层
- 修改模型的自我认知
- 改变模型的对话风格
二、微调方法
2.1 三种方法
微调模式主要分为三种:
- 增量微调:在预训练模型的基础上,仅对新增的附加参数(如Adapter层)进行训练。这种方法可以显著降低显存和算力需求,适用于资源受限的环境。
- 局部微调:在预训练模型的基础上,对模型的局部层(如输出层、注意力头)进行训练。这种方法可以在保证效果的同时,降低显存和算力需求。
- 全量微调:在预训练模型的基础上,对模型的所有参数进行训练。这种方法可以完全适配新数据,但需要较高的显存和算力需求。
2.2 方法对比
| 对比维度 | 增量微调 | 局部微调 | 全量微调 |
|---|---|---|---|
| 参数调整范围 | 仅新增的附加参数(如Adapter层) | 模型的部分层(如输出层、注意力头) | 模型全部参数 |
| 显存/算力需求 | 极低(仅需训练少量参数) | 中等(需训练部分层梯度) | 极高(需更新所有参数) |
| 训练速度 | 最快(参数少,反向传播计算量小) | 较快(部分层参与更新) | 最慢(需全局梯度计算) |
| 效果 | 较弱(依赖新增参数的能力) | 稳定(平衡性能与资源) | 最佳(完全适配新数据) |
| 过拟合风险 | 低(原始参数固定) | 中(部分参数可能过拟合) | 高(所有参数可能过拟合) |
| 适用场景 | - 资源受限(如移动端) - 快速适配小样本 | - 中等算力环境 - 任务特定层优化 | - 算力充足 - 数据分布与预训练差异大 |
| 典型技术 | LoRA、Adapter、Prefix-Tuning | 冻结部分层(如BERT的前N层) | 标准反向传播(全部参数更新) |
| 是否修改原模型 | 否(新增独立参数) | 是(修改部分原参数) | 是(修改全部参数) |
| 部署复杂度 | 低(仅需加载附加模块) | 中(需兼容部分修改层) | 高(需替换整个模型) |
2.3 关键结论
- 资源优先级:
- 算力有限 → 增量微调(如QLoRA)。
- 效果优先 → 全量微调(需4090级GPU)。
- 任务适配性:
- 小样本/领域适配 → 局部微调(如仅调整分类头)。
- 数据分布巨变 → 全量微调(如医疗文本→法律文本)。
- 技术趋势:
- 增量微调(如LoRA)因高效性成为主流,尤其适合大模型轻量化部署。
三、微调技术
3.1 微调依据
研究发现,大模型在微调时的权重变化往往集中在一个 低秩子空间 中。也就是说,虽然模型有上亿参数,但实际需要调整的参数是少量的。
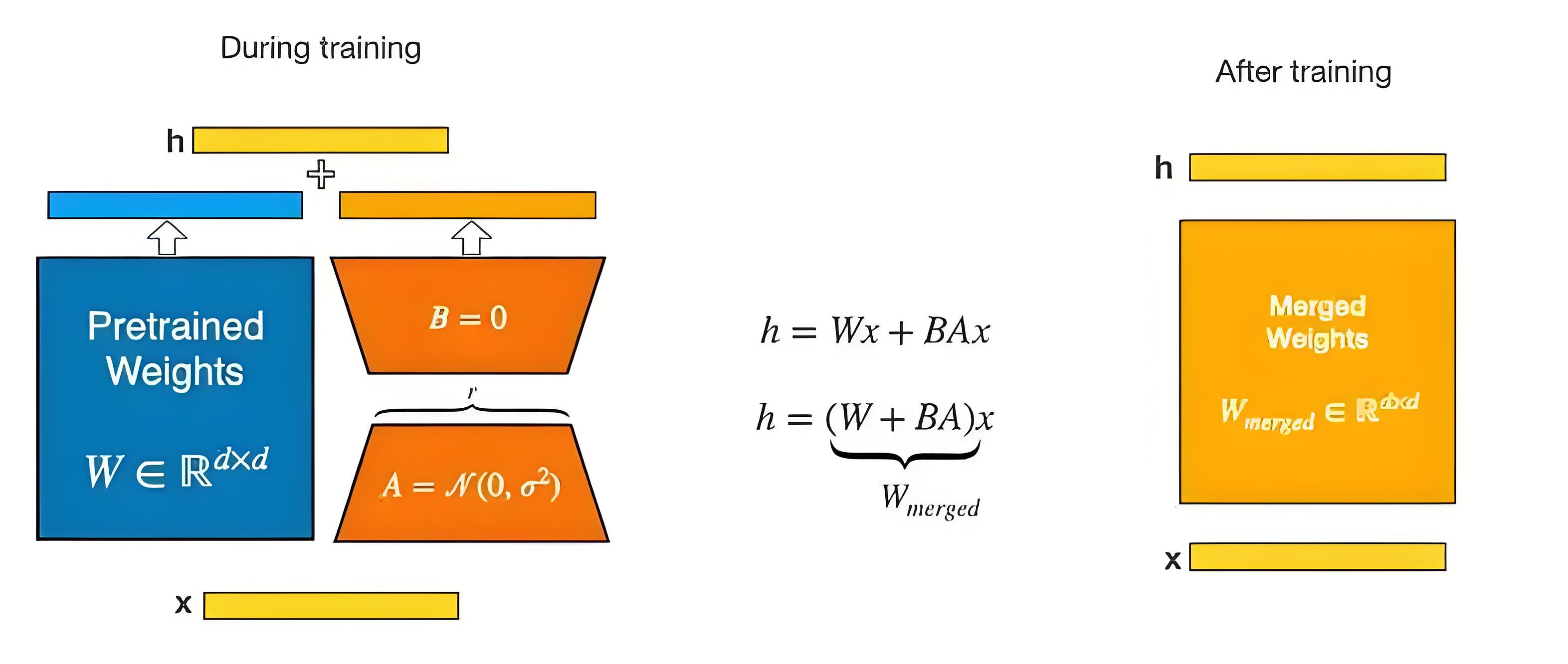
3.2 LoRA
LoRA(Low-Rank Adaptation)是一种用于微调大型预训练语言模型的轻量级方法。通过引入低秩矩阵来更新预训练模型的权重,将权重更新矩阵 ΔW 表示为两个较小矩阵 A 和 B 的乘积,只训练这些低秩矩阵,减少需要调整的参数数量,降低计算成本和防止过拟合。
W = W_0 + \Delta W = W_0 + B \cdot A
其中:
W₀是预训练模型的原始权重(冻结,不更新)。ΔW是微调过程中需要更新的权重B和A是低秩矩阵,它们的秩远小于原始矩阵的秩
3.2.1 原理
- 训练时,输入分别与原始权重和两个低秩矩阵进行计算,得到最终结果,优化则仅优化
A和B; - 训练完成后,将两个低秩矩阵与原始模型中的权重进行合并, 合并后的模型与原始模型无异。
3.2.2 示例
假设原始权重 W₀ 是 1024×1024 矩阵(约100万参数)
- 全量微调:需更新100万参数。
- LoRA微调:如果
秩(r)=8,则仅更新 B(1024×8) + A(8×1024) = 16,384参数(近似减少98%)。
3.3 QLoRA
QLoRA(Quantized LoRA)在 LoRA 基础上引入量化技术,不仅对模型引入低秩矩阵,还将低秩矩阵进行 量化,例如使用 4-bit NormalFloat(NF4) 数据类型,进一步减少内存占用和存储需求。同时,采用 Double Quantization 对量化常数进行量化,节省更多内存。
3.4 适用场景
- LoRA:适用于资源有限但对模型精度要求较高,且希望微调速度相对较快的场景,在大规模预训练模型的微调中能有效减少计算和存储开销。
- QLoRA:更适合对内存要求极为苛刻的场景,如在边缘设备、移动设备或显存较小的 GPU上运行大型预训练模型,以及需要处理大规模数据但内存资源紧张的情况。
四、微调框架
4.1 LLaMA-Factory
- 核心特点:
- 定位:专注于LLaMA系列模型(如LLaMA-2、Chinese-LLaMA)的高效微调。
- 关键技术:
- 支持 LoRA/QLoRA 低秩微调,显存占用降低50%+。
- 集成 Gradient Checkpointing(梯度检查点),支持大批次训练。
- 提供 对话模板对齐 工具,解决微调后输出格式混乱问题。
- 优势:
- 界面友好,支持一键启动微调任务。
- 针对中文优化,内置中文词表扩展和指令数据集(如Alpaca-CN)。
- 支持快速部署到消费级GPU(如RTX 3090 24GB微调7B模型)。
- 适用场景:
- 轻量化微调中文LLaMA模型。
- 小样本场景下的领域适配(如医疗、法律)。
详情可查看 大模型微调指南之 LLaMA-Factory 篇:一键启动LLaMA系列模型高效微调
4.2 Xtuner
- 核心特点:
- 定位:通用大模型微调框架,支持多种架构(LLaMA、ChatGLM、InternLM等)。
- 关键技术:
- 全参数/增量微调 灵活切换,支持 PyTorch FSDP(多卡分布式训练)。
- 内置 数据预处理流水线(自动处理文本/多模态数据)。
- 提供 量化训练(GPTQ/AWQ)和 模型压缩 工具链。
- 优势:
- 模块化设计,轻松适配新模型架构。
- 与OpenMMLab生态集成(如MMDeploy一键模型导出)。
- 适用场景:
- 全参数微调大规模模型(需A100/H100集群)。
- 工业级部署需求(如API服务、端侧推理)。
详情请查看 大模型微调指南之 Xtuner 篇:3步实现Qwen1.5中文对话模型优化
4.3 对比
| 维度 | LlaMA-Factory | Xtuner |
|---|---|---|
| 核心优势 | 轻量化中文微调,低资源需求 | 多架构支持,工业级部署 |
| 微调方式 | 主打LoRA/QLoRA | 全参数/增量/量化训练全覆盖 |
| 硬件要求 | 消费级GPU(如RTX 3090) | 需高性能GPU(如A100) |
| 典型用户 | 研究者/中小团队 | 企业级开发/云服务商 |
| 生态整合 | 中文社区活跃 | 与OpenMMLab工具链深度集成 |