大模型Embedding模型介绍与使用
嵌入模型的作用
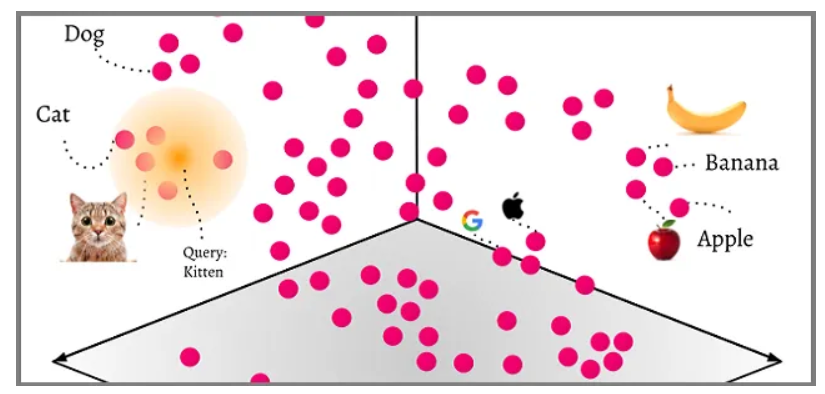
嵌入模型不仅能够编码词汇本身的含义,还能捕捉词与词之间、句子与句子之间的关联关系。这意味着在向量空间中,语义相似的词会拥有相似的位置,比如:
- "queen"和"king"在向量空间中距离相近
- "man"和"woman"在向量空间中距离相近
- 搜索"男人"可能会得到"女人"、“男孩”、"丈夫"等语义相近的词
这种语义相似性搜索是基于向量空间中的距离计算,而非简单的关键词匹配,能够更好地理解自然语言的语义关系。
几乎每一个大模型公司都开发了自己的嵌入模型,并且还在不断迭代。比如
OpenAI的嵌入模型经历了多次迭代:
-
2022年版本text-embedding-ada-002:
- 默认维度为1536
- 上下文长度8192
- 不支持直接调整维度,需要通过L2标准化等方法进行降维
-
最新版本(text-embedding-3系列)
text-embedding-3-small:更小更快的模型
text-embedding-3-large:性能最好的模型- 可以控制输出向量的维度
- text-embedding-3-small默认维度为1536(常用的维度选择:512或256,能显著减少计算量的同时保留足够的语义信息)
- text-embedding-3-large默认维度为3072(最高维度)
- 成本更低
- 支持中文
代码调用体验Embedding模型
以下是使用OpenAI的嵌入模型的基本步骤:
import openai
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity# 1. 初始化OpenAI客户端
client = openai.OpenAI(base_url="[中间商URL]", # 如果直连OpenAI官网则不需要此参数api_key="[你的API密钥]"
)# 2. 获取词语的嵌入向量
def get_embedding(text, model="text-embedding-3-large"):response = client.embeddings.create(model=model,input=text)return response.data[0].embedding# 3. 获取多个词的嵌入向量
words = ["king", "queen", "man", "woman", "boy", "husband", "男人", "女人"]
embeddings = {}for word in words:embeddings[word] = get_embedding(word)print(f"获取'{word}'的向量完成")# 4. 计算向量之间的相似度
def calculate_similarity(word1, word2):vec1 = np.array([embeddings[word1]])vec2 = np.array([embeddings[word2]])similarity = cosine_similarity(vec1, vec2)[0][0]return similarity# 5. 展示相似度示例
print("\n向量相似度比较:")
print(f"'king'和'queen'的相似度: {calculate_similarity('king', 'queen'):.4f}")
print(f"'man'和'woman'的相似度: {calculate_similarity('man', 'woman'):.4f}")
print(f"'男人'和'女人'的相似度: {calculate_similarity('男人', '女人'):.4f}")
print(f"'king'和'man'的相似度: {calculate_similarity('king', 'man'):.4f}")
print(f"'queen'和'woman'的相似度: {calculate_similarity('queen', 'woman'):.4f}")# 6. 简单的语义搜索功能
def semantic_search(query_word, all_words, top_n=3):query_embedding = embeddings[query_word]# 计算查询词与所有词的相似度similarities = {}for word in all_words:if word != query_word: # 排除查询词本身word_embedding = embeddings[word]similarity = cosine_similarity(np.array([query_embedding]), np.array([word_embedding]))[0][0]similarities[word] = similarity# 排序并返回前N个最相似的词sorted_words = sorted(similarities.items(), key=lambda x: x[1], reverse=True)return sorted_words[:top_n]# 7. 演示搜索功能
search_word = "男人"
other_words = [w for w in words if w != search_word]
results = semantic_search(search_word, other_words)print(f"\n与'{search_word}'最相似的词:")
for word, similarity in results:print(f"'{word}': 相似度 {similarity:.4f}")# 8. 向量运算示例 - 类比关系
# 例如: king - man + woman ≈ queen
def vector_analogy(a, b, c):# 实现 a - b + c 的向量运算a_vec = np.array(embeddings[a])b_vec = np.array(embeddings[b])c_vec = np.array(embeddings[c])result_vec = a_vec - b_vec + c_vec# 计算结果向量与所有词的相似度similarities = {}for word in embeddings:if word not in [a, b, c]: # 排除输入词word_vec = np.array(embeddings[word])similarity = cosine_similarity(np.array([result_vec]), np.array([word_vec]))[0][0]similarities[word] = similarity# 返回最相似的词return sorted(similarities.items(), key=lambda x: x[1], reverse=True)[0]# 9. 展示类比关系
analogy_result = vector_analogy("king", "man", "woman")
print(f"\n向量类比: king - man + woman ≈ {analogy_result[0]} (相似度: {analogy_result[1]:.4f})")
Embedding如何选择合适的
业界公认批判指标是Huggingface推出的 MTEB(Massive Text Embedding Benchmark)。
该指标体现Embedding模型在分类(Classification)、聚类(Clustering)、对分类(Pair Classification)、重排序(Reranking)、检索(Retrieval)等任务的表现
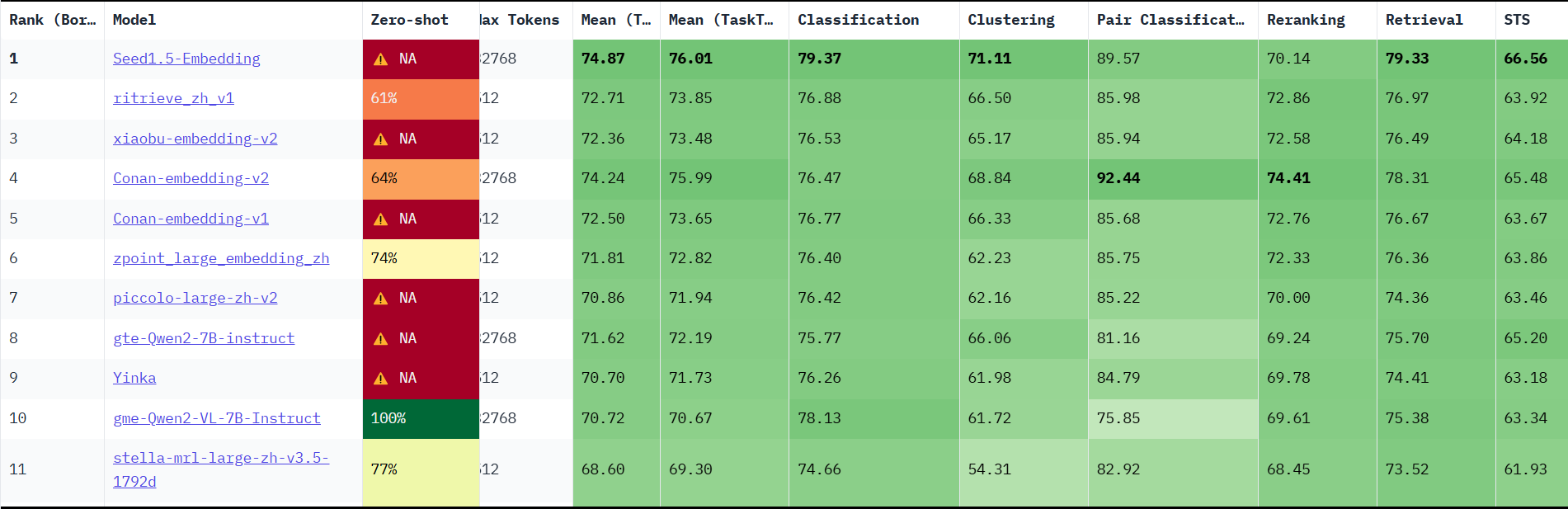
我们看到综合排在第一位的是字节跳动的Seed1.5-Embedding(截止本文发布时)。另外读者应该根据所需执行的任务排行做选择,比如对于RAG来说,检索(Retrieval)任务的指标是最重要的。因此,我们应当优先关注在检索任务下表现出色的模型。