为特定领域微调嵌入模型:打造专属的自然语言处理利器
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
想象一下,你在开发一个医学领域的问答系统。你希望它能够准确地检索出与用户问题相关的医学文章。但通用的嵌入模型可能会在处理高度专业化的医学术语及其细微差别时感到吃力。
这就是微调派上用场的时候啦!
在本文中,我们将深入探讨如何为特定领域(如医学、法律或金融)微调嵌入模型。我们将为你的领域生成一个专门的数据集,并用它来训练模型,使其更好地理解你所选择领域的语言模式和概念。
到文章结束时,你将拥有一个针对你的领域优化的更强大的嵌入模型,从而在你的自然语言处理任务中实现更准确的检索和更好的结果。
嵌入:理解概念
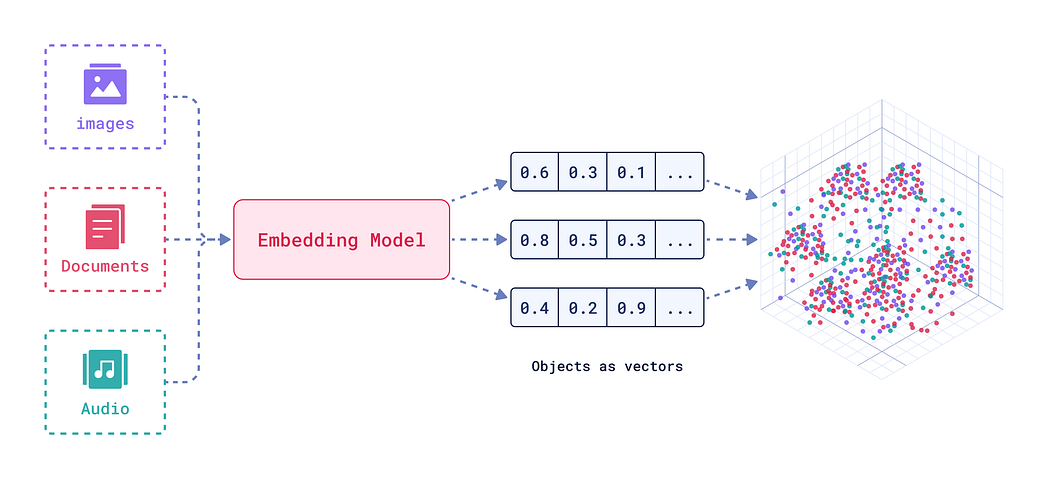
嵌入是强大的数值文本或图像表示,能够捕捉语义关系。想象一下,将文本或音频视为多维空间中的一个点,相似的单词或短语会比不相似的更接近。
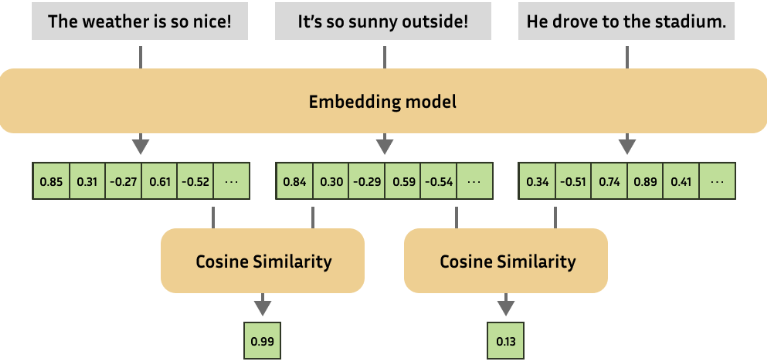
嵌入在许多自然语言处理任务中都非常重要,例如:
语义相似性:判断两段文本或图像的相似程度。
文本分类:根据文本的含义将其归类。
问答:找到最相关的文档来回答问题。
检索增强生成(RAG):结合嵌入模型用于检索和语言模型用于文本生成,以提高生成文本的质量和相关性。
套娃表示学习(Matryoshka Representation Learning)
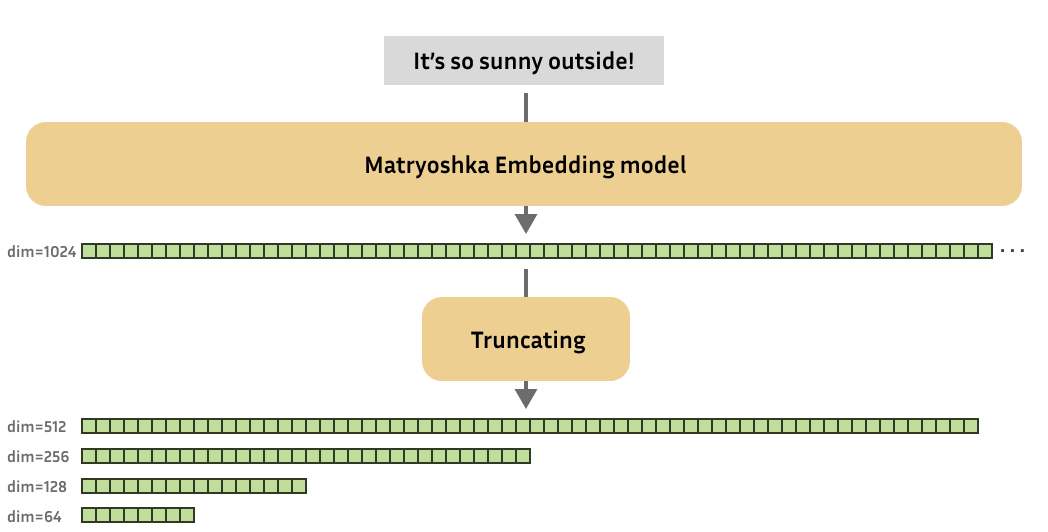
套娃表示学习(Matryoshka Representation Learning, MRL)是一种用于创建“可截断”嵌入向量的技术。想象一系列嵌套的套娃,每个套娃里面都有一个更小的套娃。MRL以这种方式嵌入文本,即前面的维度(就像外层的套娃)包含最重要的信息,后续的维度则添加细节。这使得你可以在需要时只使用嵌入向量的一部分,从而减少存储和计算成本。
Bge-base-en
由北京人工智能研究院(BAAI)开发的[BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5)模型是一个强大的文本嵌入模型。它在各种自然语言处理任务中表现出色,并且在MTEB和C-MTEB等基准测试中表现良好。bge-base-en模型是计算资源有限的应用场景(比如我的情况)的不错选择。
为什么需要微调嵌入?
为特定领域微调嵌入模型对于优化RAG系统至关重要。这一过程确保模型对相似性的理解与你领域的具体上下文和语言细微差别保持一致。经过微调的嵌入模型能够更好地检索出与问题最相关的文档,从而让你的RAG系统生成更准确、更相关的回答。
数据集格式:为微调奠定基础
你可以使用多种数据集格式进行微调。
以下是几种常见类型:
- 正样本对**:**一对相关的句子(例如问题和答案)。
- 三元组:(锚点,正样本,负样本)三元组,其中锚点与正样本相似,与负样本不相似。
- 带相似度分数的对**:**一对句子及其相似度分数,表示它们之间的关系。
- 文本与类别**:**文本及其对应的类别标签。
在本文中,我们将创建一个问题-答案对的数据集,用于微调我们的bge-base-en-v1.5模型。
损失函数:引导训练过程
损失函数对于训练嵌入模型至关重要。它们衡量模型预测与实际标签之间的差异,为模型调整权重提供信号。
不同的数据集格式适用于不同的损失函数:
- 三元组损失:用于(锚点,正样本,负样本)三元组,鼓励模型将相似的句子放得更近,不相似的句子放得更远。
- 对比损失:用于正样本和负样本对,鼓励相似的句子靠近,不相似的句子远离。
- 余弦相似性损失:用于带有相似度分数的句子对,鼓励模型生成的嵌入向量的余弦相似性与给定的分数一致。
- 套娃损失**:**一种专门用于创建套娃嵌入的损失函数,嵌入向量可以被截断。
代码示例
安装依赖项
我们首先安装必要的库。我们将使用datasets、sentence-transformers和google-generativeai来处理数据集、嵌入模型和文本生成。
apt-get -qq install poppler-utils tesseract-ocr
pip install datasets sentence-transformers google-generativeai
pip install -q --user --upgrade pillow
pip install -q unstructured["all-docs"] pi_heif
pip install -q --upgrade unstructured
pip install --upgrade nltk
我们还将安装unstructured用于PDF解析,以及nltk用于文本处理。
PDF解析和文本提取
我们将使用unstructured库从PDF文件中提取文本和表格。
import nltk
import os
from unstructured.partition.pdf import partition_pdf
from collections import Counter
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('punkt_tab') def process_pdfs_in_folder(folder_path):total_text = [] # 用于累积所有PDF中的文本pdf_files = [f for f in os.listdir(folder_path) if f.endswith('.pdf')] # 获取文件夹中所有PDF文件for pdf_file in pdf_files:pdf_path = os.path.join(folder_path, pdf_file)print(f"正在处理:{pdf_path}")elements = partition_pdf(pdf_path, strategy="auto") # 应用分割逻辑text = "\n\n".join([str(el) for el in elements]) # 将元素组合成文本total_text.append(text)return "\n\n".join(total_text)folder_path = "data"
all_text = process_pdfs_in_folder(folder_path)
我们遍历指定文件夹中的每个PDF文件,并将其内容分割为文本、表格和图表。
然后我们将文本元素组合成一个单一的文本表示。
自定义文本分块
我们将使用nltk将提取的文本分割成便于处理的块。这对于使文本更适合语言模型处理至关重要。
import nltk
nltk.download('punkt')def nltk_based_splitter(text: str, chunk_size: int, overlap: int) -> list:"""将输入文本分割成指定大小的块,可以选择是否让块之间有重叠。参数:- text:要分割的输入文本。- chunk_size:每个块的最大大小(以字符数计)。- overlap:连续块之间的重叠字符数。返回:- 一个包含文本块的列表,可以选择是否包含重叠。"""from nltk.tokenize import sent_tokenizesentences = sent_tokenize(text) # 将输入文本分割成单独的句子chunks = []current_chunk = ""for sentence in sentences:if len(current_chunk) + len(sentence) <= chunk_size:current_chunk += " " + sentenceelse:chunks.append(current_chunk.strip()) # 去掉前导空格current_chunk = sentenceif current_chunk:chunks.append(current_chunk.strip())if overlap > 0:overlapping_chunks = []for i in range(len(chunks)):if i > 0:start_overlap = max(0, len(chunks[i - 1]) - overlap)chunk_with_overlap = chunks[i - 1][start_overlap:] + " " + chunks[i]overlapping_chunks.append(chunk_with_overlap[:chunk_size])else:overlapping_chunks.append(chunks[i][:chunk_size])return overlapping_chunksreturn chunkschunks = nltk_based_splitter(text=all_text,chunk_size=2048,overlap=0)
数据集生成器
在这一部分,我们定义了两个函数:
prompt函数为Google Gemini创建一个提示,请求基于提供的文本块生成一个问题及其对应的答案。
import google.generativeai as genai
import pandas as pd# 替换为你的有效Google API密钥
GOOGLE_API_KEY = "xxxxxxxxxxxx"# 明确请求结构化输出的提示生成器
def prompt(text_chunk):return f"""根据以下文本,生成一个问题及其对应的答案。请按照以下格式输出:问题:[你的问题]答案:[你的答案]文本:{text_chunk}"""# 与Google的Gemini交互并返回QA对的函数
def generate_with_gemini(text_chunk: str, temperature: float, model_name: str):genai.configure(api_key=GOOGLE_API_KEY)generation_config = {"temperature": temperature}gen_model = genai.GenerativeModel(model_name, generation_config=generation_config)response = gen_model.generate_content(prompt(text_chunk))try:question, answer = response.text.split("答案:", 1)question = question.replace("问题:", "").strip()answer = answer.strip()except ValueError:question, answer = "N/A", "N/A" # 处理响应格式异常的情况return question, answer
generate_with_gemini函数与Gemini模型交互,使用创建的提示生成QA对。
运行QA生成
使用process_text_chunks函数,我们为每个文本块使用Gemini模型生成QA对。
def process_text_chunks(text_chunks: list, temperature: int, model_name=str):"""处理文本块列表,使用指定模型生成问题和答案。参数:- text_chunks:要处理的文本块列表。- temperature:控制生成输出随机性的采样温度。- model_name:用于生成问题和答案的模型名称。返回:- 一个包含文本块、问题和答案的Pandas DataFrame。"""results = []for chunk in text_chunks:question, answer = generate_with_gemini(chunk, temperature, model_name)results.append({"Text Chunk": chunk, "Question": question, "Answer": answer})df = pd.DataFrame(results)return df# 处理文本块并获取DataFrame
df_results = process_text_chunks(text_chunks=chunks,temperature=0.7,model_name="gemini-1.5-flash")
df_results.to_csv("generated_qa_pairs.csv", index=False)
这些结果随后被存储在一个Pandas DataFrame中。
加载数据集
接下来,我们将从CSV文件中加载生成的QA对到HuggingFace数据集,并确保数据格式适合微调。
from datasets import load_dataset# 将CSV文件加载到Hugging Face数据集
dataset = load_dataset('csv', data_files='generated_qa_pairs.csv')def process_example(example, idx):return {"id": idx, # 根据索引添加唯一ID"anchor": example["Question"],"positive": example["Answer"]}dataset = dataset.map(process_example,with_indices=True,remove_columns=["Text Chunk", "Question", "Answer"])
加载模型
我们从HuggingFace加载BAAI/bge-base-en-v1.5模型,并确保选择合适的设备(CPU或GPU)进行执行。
import torch
from sentence_transformers import SentenceTransformer
from sentence_transformers.evaluation import (InformationRetrievalEvaluator,SequentialEvaluator,
)
from sentence_transformers.util import cos_sim
from datasets import load_dataset, concatenate_datasets
from sentence_transformers.losses import MatryoshkaLoss, MultipleNegativesRankingLossmodel_id = "BAAI/bge-base-en-v1.5"# 加载模型
model = SentenceTransformer(model_id, device="cuda" if torch.cuda.is_available() else "cpu"
)
定义损失函数
这里,我们配置套娃损失函数,指定用于截断嵌入的维度。
# 重要:从大到小matryoshka_dimensions = [768, 512, 256, 128, 64]
inner_train_loss = MultipleNegativesRankingLoss(model)
train_loss = MatryoshkaLoss(model, inner_train_loss, matryoshka_dims=matryoshka_dimensions
)
内部损失函数MultipleNegativesRankingLoss帮助模型生成适合检索任务的嵌入。
定义训练参数
我们使用SentenceTransformerTrainingArguments定义训练参数。这包括输出目录、训练轮数、批量大小、学习率和评估策略。
from sentence_transformers import SentenceTransformerTrainingArguments
from sentence_transformers.training_args import BatchSamplers# 定义训练参数
args = SentenceTransformerTrainingArguments(output_dir="bge-finetuned", # 输出目录和Hugging Face模型IDnum_train_epochs=1, # 训练轮数per_device_train_batch_size=4, # 训练批量大小gradient_accumulation_steps=16, # 全局批量大小为512per_device_eval_batch_size=16, # 评估批量大小warmup_ratio=0.1, # 预热比例learning_rate=2e-5, # 学习率,2e-5是一个不错的选择lr_scheduler_type="cosine", # 使用余弦学习率调度器optim="adamw_torch_fused", # 使用融合的AdamW优化器tf32=True, # 使用TF32精度bf16=True, # 使用BF16精度batch_sampler=BatchSamplers.NO_DUPLICATES, # MultipleNegativesRankingLoss受益于批量中没有重复样本eval_strategy="epoch", # 每轮训练后评估save_strategy="epoch", # 每轮训练后保存logging_steps=10, # 每10步记录一次save_total_limit=3, # 只保存最后3个模型load_best_model_at_end=True, # 训练结束时加载最佳模型metric_for_best_model="eval_dim_128_cosine_ndcg@10", # 优化128维度的ndcg@10分数
)
注意:如果你使用的是Tesla T4并且在训练过程中遇到错误,尝试注释掉tf32=True和bf16=True这两行代码,以禁用TF32和BF16精度。
创建评估器
我们创建一个评估器,用于在训练过程中衡量模型的性能。评估器使用InformationRetrievalEvaluator评估模型在每个维度上的检索性能。
corpus = dict(zip(dataset['train']['id'],dataset['train']['positive'])
) # 我们的语料库(cid => 文档)
queries = dict(zip(dataset['train']['id'],dataset['train']['anchor'])
) # 我们的查询(qid => 问题)# 为每个查询创建相关文档的映射(1个相关文档)
relevant_docs = {}
for q_id in queries:relevant_docs[q_id] = [q_id]matryoshka_evaluators = []# 遍历不同维度
for dim in matryoshka_dimensions:ir_evaluator = InformationRetrievalEvaluator(queries=queries,corpus=corpus,relevant_docs=relevant_docs,name=f"dim_{dim}",truncate_dim=dim, # 截断到指定维度score_functions={"cosine": cos_sim},)matryoshka_evaluators.append(ir_evaluator)# 创建顺序评估器
evaluator = SequentialEvaluator(matryoshka_evaluators)
微调前评估模型
我们在微调之前评估基础模型,以获取一个性能基线。
results = evaluator(model)
for dim in matryoshka_dimensions:key = f"dim_{dim}_cosine_ndcg@10"print(f"{key}: {results[key]}")
定义训练器
我们创建一个SentenceTransformerTrainer对象,指定模型、训练参数、数据集、损失函数和评估器。
from sentence_transformers import SentenceTransformerTrainertrainer = SentenceTransformerTrainer(model=model, # 我们的嵌入模型args=args, # 上面定义的训练参数train_dataset=dataset.select_columns(["positive", "anchor"]),loss=train_loss, # 套娃损失evaluator=evaluator, # 顺序评估器
)
开始微调
trainer.train()方法启动微调过程,使用提供的数据和损失函数更新模型的权重。
# 开始训练
trainer.train()# 保存最佳模型
trainer.save_model()
训练完成后,我们将表现最佳的模型保存到指定的输出目录。
微调后评估
最后,我们加载微调后的模型,并使用相同的评估器衡量其性能提升。
from sentence_transformers import SentenceTransformerfine_tuned_model = SentenceTransformer(args.output_dir, device="cuda" if torch.cuda.is_available() else "cpu"
)
# 评估模型
results = evaluator(fine_tuned_model)
# 打印主要分数
for dim in matryoshka_dimensions:key = f"dim_{dim}_cosine_ndcg@10"print(f"{key}: {results[key]}")
通过为你的领域微调嵌入模型,你为你的自然语言处理应用赋予了对该领域语言和概念的更深入理解,这可以在问答、文档检索和文本生成等任务中带来显著的改进。
本文讨论的技术,例如利用MRL和使用强大的bge-base-en模型,为构建特定领域的嵌入模型提供了一条实用的路径。虽然我们专注于微调过程,但请记住,数据集的质量同样重要。精心策划一个准确反映你领域细微差别的数据集,对于实现最佳结果至关重要。
随着自然语言处理领域的不断发展,我们可以期待看到更强大的嵌入模型和微调策略的出现。通过保持关注并调整你的方法,你可以充分利用嵌入模型的潜力,构建高质量的自然语言处理应用,以满足你的特定需求。
祝微调愉快!