Linux——MySQL基础
基础知识
连接服务器
mysql -h 127.0.0.1 -P 3306 -u root -p
-h 指明登录部署了myqsl服务的主机
-P 指明访问的端口号
-u 指明用户
-p 指明登录密码(可以不填写)
什么是数据库
首先,数据库是分为服务端和客户端的:
mysql是客户端,mysqld是服务端。
mysql本质就是基于CS模式的网络服务。
也就是说,mysql是一套提供数据存储服务的网络程序。
数据库一般指的是在磁盘或者内存中存储的特定结构组织的数据——将来在磁盘中存储数据的一套特定方案。
数据库服务就是mysqld。
为什么有数据库
虽然一般文件确实提供了数据存储的功能,但是站在用户角度上,文件并没有提供非常好的数据管理能力。
数据库的本质:对数据内容存取的一套解决方案,你给我数据内容,我直接给你结果。
Linux下的数据库是什么样子的?
建立数据库,在本质就是在Linux下的一个目录。
在数据库内部建立表,本质就是在Linux下创建对应的文件即可。
上面两个工作是muqsld帮我们做的。
所以说,数据库本质也是文件,只不过这些文件不由程序员直接操作,而是数据库服务帮我们操作。
这样会降低程序员维护数据的成本,如果是文件是需要程序员维护的。
服务器,数据库,表关系
所谓安装数据库服务器,只是在机器上安装了一个数据库管理系统程序,这个管理程序可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库。
为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据。
数据库服务器、数据库和表的关系如下:
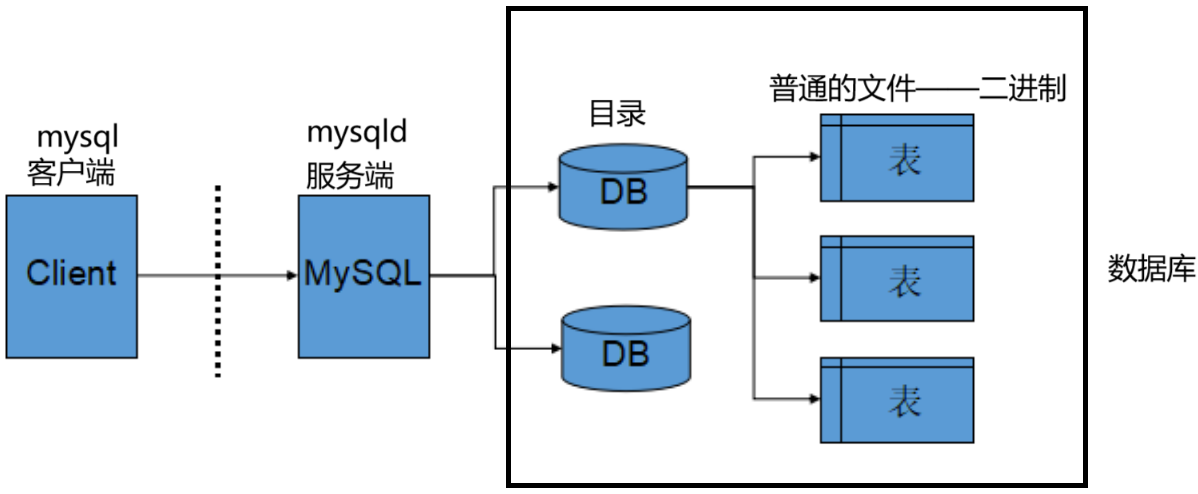
数据逻辑存储
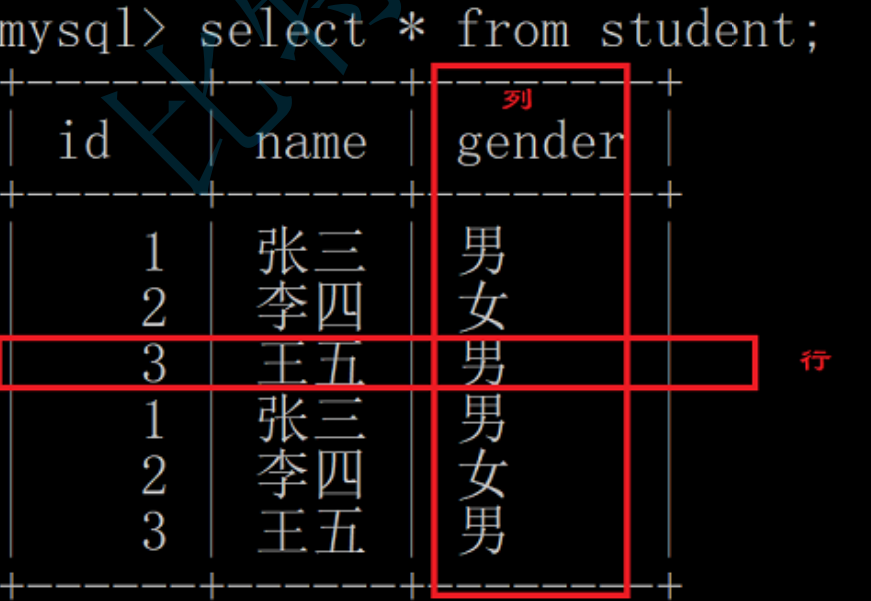
这是一张表。
MySQL架构
MySQL 是一个可移植的数据库,几乎能在当前所有的操作系统上运行,如 Unix/Linux、Windows、Mac 和 Solaris。各种系统在底层实现方面各有不同,但是 MySQL 基本上能保证在各个平台上的物理体系结构的一致性。
第一层是链接池,第二层是语法分析,第三层是存储引擎。
SQL分类
DDL【data definition language】 数据定义语言,用来维护存储数据的结构
代表指令: create, drop, alter
DML【data manipulation language】 数据操纵语言,用来对数据进行操作
代表指令: insert,delete,update(DML中又单独分了一个DQL,数据查询语言,代表指令: select)
DCL【Data Control Language】 数据控制语言,主要负责权限管理和事务
代表指令: grant,revoke,commit
存储引擎
存储引擎是:数据库管理系统如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。
MySQL的核心就是插件式存储引擎,支持多种存储引擎。
查看存储引擎:
show engines;
操作库
创建与删除
创建数据库
create database + 数据库名;(本质是在/var/lib/mysql创建一个目录)
这里和查看数据库不同,查看数据库是show databases
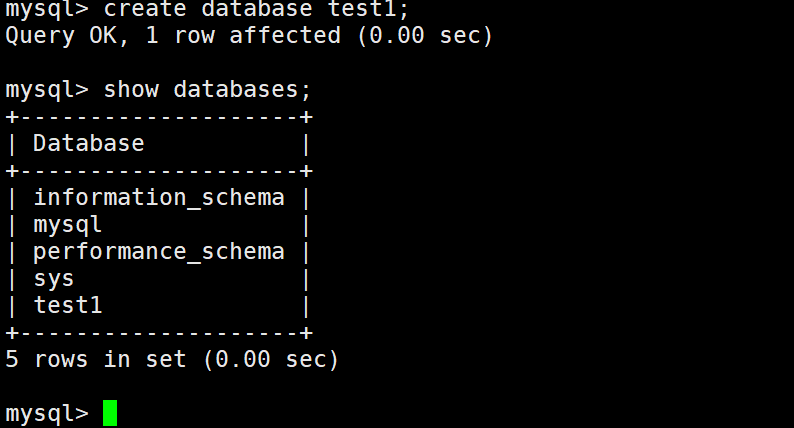
如果当前的数据库已经存在,那么就不会执行这个语句取创建数据库。
删除数据库
drop database + 要删除数据库的名字;(删除目录)
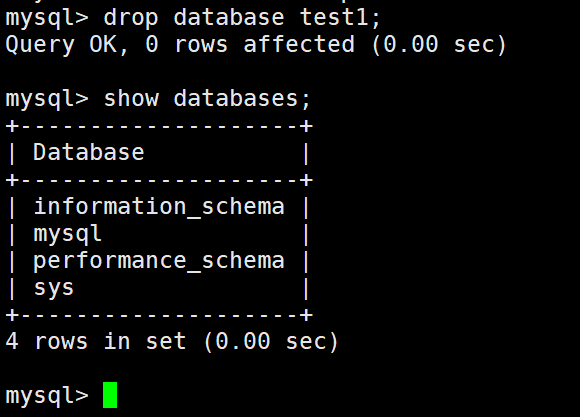
执行删除之后的结果:
1.数据库内部看不到对应的数据库。
2.对应的数据库文件夹被删除,级联删除,里面的数据表全部被删。
注意:不要随意删除数据库
字符集和校验规则
数据库创建的时候有两个编码集:
1.数据库编码集——数据库未来存储数据
2.数据库校验集——支持数据库,进行字段比较使用的编码,本质也是一种读取数据库中数据的采用的编码格式
数据库无论对数据做任何操作,都必须保证操作和编码必须是一致的。
当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则是:utf8_ general_ ci。
查看系统默认字符集以及校验规则
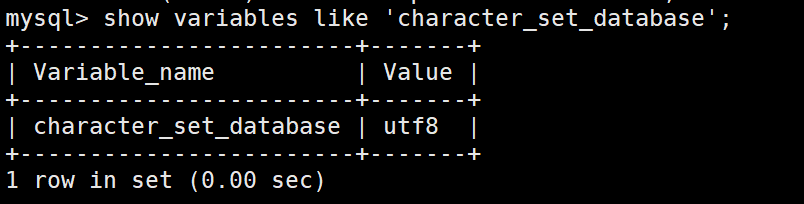
字符集:
show variables like ‘character_set_database’;
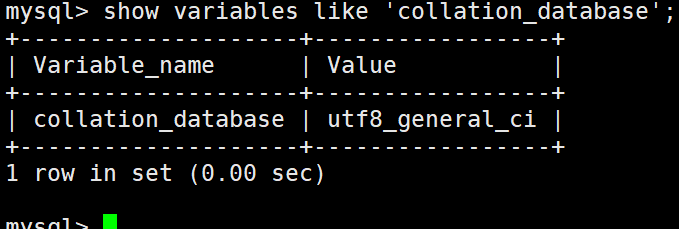
校验集:
show variables like ‘collation_database’;
查看数据库支持的字符集
show charset;
创建一个使用utf8字符集的数据库
create database 名字 charset=utf8;
create database 名字 charset= set utf8;
创建一个使用utf字符集,并带校对规则的数据库
create database 名字 charset=utf8 collate utf8_general_ci;
校验规则对数据库的影响
不区分大小写
创建一个数据库,校验规则使用utf8_ general_ ci;
create database test1 collate utf8_general_ci;
use test1;
create table person(name varchar(20));
insert into person values(‘a’);
insert into person values(‘A’);
insert into person values(‘b’);
insert into person values(‘B’);
查询结果:
mysql> use test1;
mysql> select * from person where name=‘a’;
±-----+
| name |
±-----+
| a |
| A |
±-----+
2 rows in set (0.01 sec)
排序结果:
mysql> use test1;
mysql> select * from person order by name;
±-----+
| name |
±-----+
| a |
| A |
| b |
| B |
±-----+
区分大小写
校验规则使用utf8_ bin
创建插入步骤同上。
查询结果:
mysql> use test2;
mysql> select * from person where name=‘a’;
±-----+
| name |
±-----+
| a |
±-----+
2 rows in set (0.01 sec)
排序结果:
mysql> use test2;
mysql> select * from person order by name;
±-----+
| name |
±-----+
| A |
| B |
| a |
| b |
±-----+
操纵数据库
查看数据库
show databases;
修改数据库
对数据库的修改主要指的是修改数据库的字符集,校验规则。
alter database 名字 要更改的命令;
显示创建语句
show create database 数据库名;
示例:
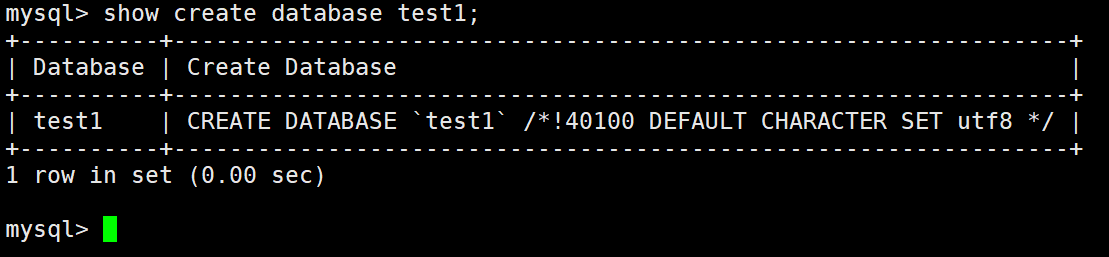
说明:
MySQL 建议我们关键字使用大写,但是不是必须的。
数据库名字的反引号``,是为了防止使用的数据库名刚好是关键字。
/*!40100 default… */ 这个不是注释,表示当前mysql版本大于4.01版本,就执行这句话。
备份和恢复
备份
注意,这个操作实在OS进行的,不是在mysql
mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径;
在备份的目录下会生成.sql后缀的文件。
如果备份的不是整个数据库,而是其中的一张表,怎么做?
mysqldump -u root -p 数据库名 表名1 表名2 > 数据库备份存储的文件路径;
同时备份多个数据库
mysqldump -u root -p -B 数据库名1 数据库名2 … > 数据库存放路径
如果备份一个数据库时,没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据库,再使用source来还原。
还原
这个操作要在musql中进行
source 对应路径的文件;
执行命令即可恢复成功。
表的操作
创建表
CREATE TABLE table_name (
field1 datatype,
field2 datatype,
field3 datatype
) character set 字符集 collate 校验规则 engine 存储引擎;
field 表示列名
datatype 表示列的类型
character set 字符集,如果没有指定字符集,则以所在数据库的字符集为准
collate 校验规则,如果没有指定校验规则,则以所在数据库的校验规则为准
不同的存储引擎,创建表的文件不一样。
表存储引擎是 MyISAM ,在数据目中有三个不同的文件,分别是:
.frm:表结构
.MYD:表数据
.MYI:表索引
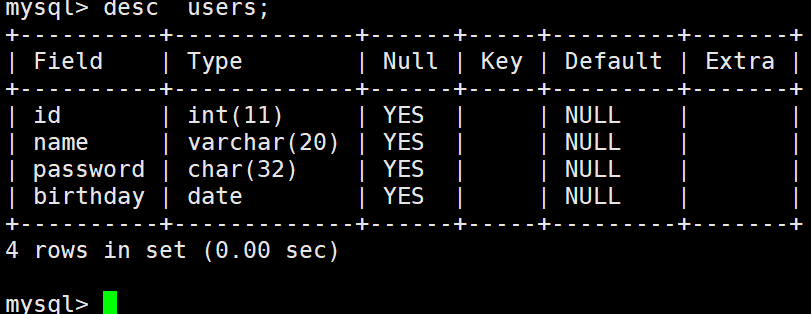
查看表
desc 表名;
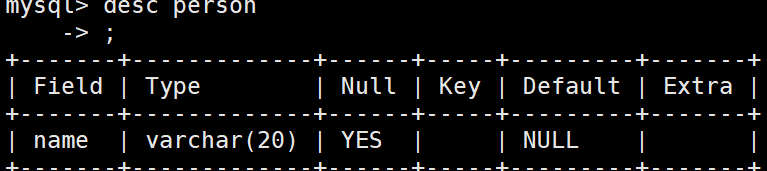
Field:字段名字
Type:字段类型
Null:是否允许为空
Key:索引类型
Default:默认值
Extra:扩充
表也可以查看创建时候表的内容。
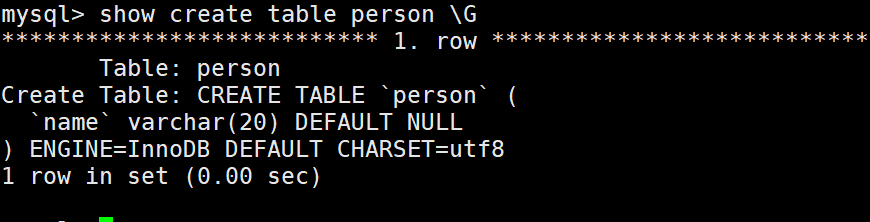
show create table 表的名字 \G;
这里的\G是为了清楚表中没有用是数据,增加可读性。
修改表
在项目实际开发中,经常修改某个表的结构,比如字段名字,字段大小,字段类型,表的字符集类型,表的存储引擎等等。我们还有需求,添加字段,删除字段等等。这时我们就需要修改表。
insert into 表名称 (想插入哪一列字段,不写默认插入所有字段)values 插入内容。
首先创建一个表。
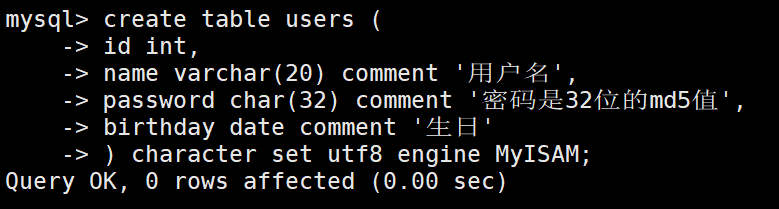


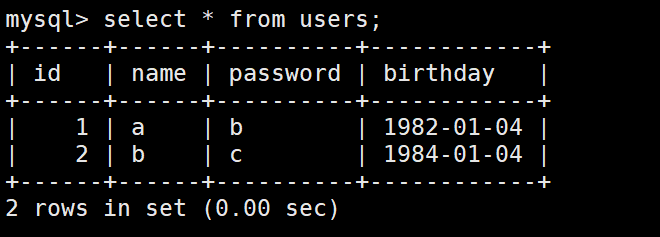
在users表添加一个字段:
alter table users add assets varchar(100) comment ‘图片路径’ after birthday;
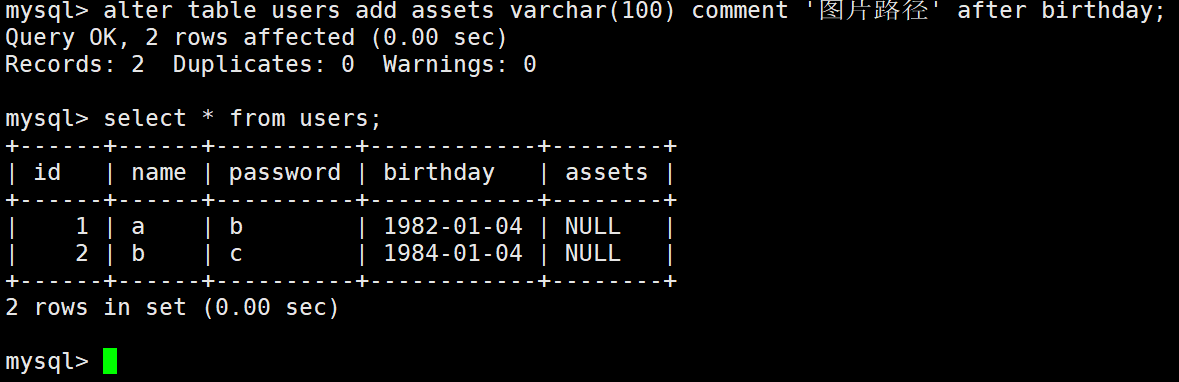
插入新字段后,对原来表中的数据没有影响:
修改name,将其长度改成60:
alter table users modify name varchar(60);

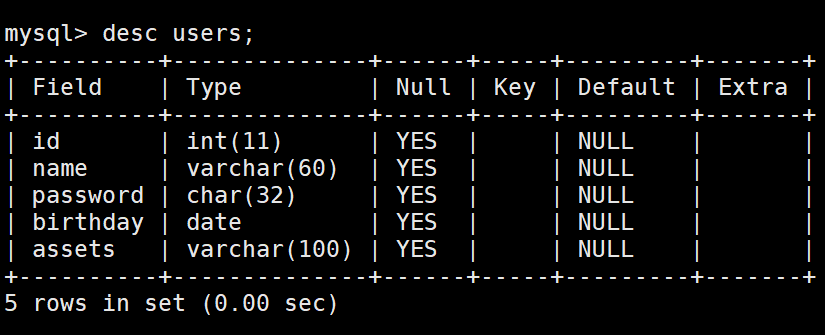
长度变成了60.
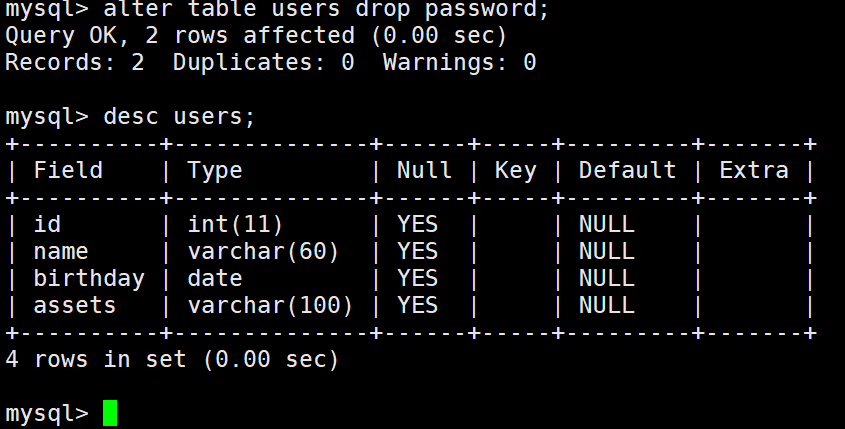
删除password列:
注意:删除字段一定要小心,删除字段及其对应的列数据都没了。
alter table users drop password;
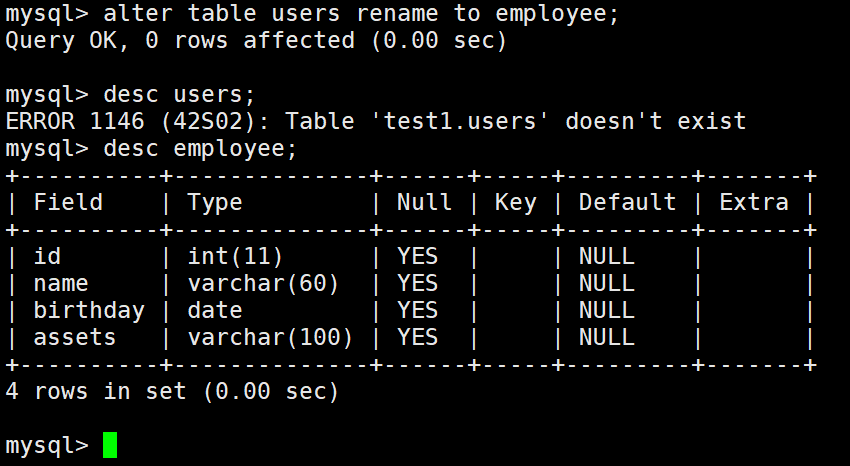
修改表名为employee:
alter table users rename to employee;
to:可以省掉
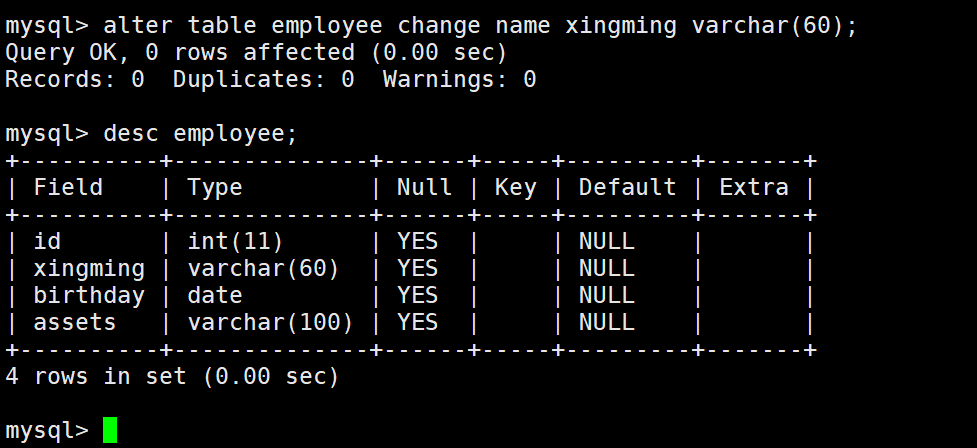
将name列修改为xingming
alter table employee change name xingming varchar(60); --新字段需要完整定义
删除表
drop table 表的名字
和数据库一样,不要轻易的删除
数据类型
数据类型分类
| 分类 | 数据类型 | 说明 |
|---|---|---|
| 数值类型 | BIT(M) | 位类型。M指定位数,默认值1,范围1-64 |
| TINYINT [UNSIGNED] | 带符号的范围-128~127,无符号范围0~255.默认有符号 | |
| BOOL | 使用0和1表示真和假 | |
| SMALLINT [UNSIGNED]] | 带符号是-2^15次方 到 2~15-1,无符号是2^16-1 | |
| INT [UNSIGNED]] | 带符号是-2~31次方到 2^31-1,无符号是2~32-1 | |
| BIGINT [UNSIGNED]] | 带符号是-2~63次方到 2^63-1,无符号是2~64-1 | |
| FLOATL [(M,D)] [UNSIGNED] | M指定显示长度,d指定小数位数,占用4字节 | |
| DOUBLE [(M,D)][UNSIGNED] | 表示比float精度更大的小数,占用空间8字节 | |
| DECIMAL [(M.D)[UNSIGNED] | 定点数M指定长度,D表示小数点的位数 | |
| 文本二进制类型 | CHAR(size) | 固定长度字符串,最大255 |
| VARCHAR (SIZE) | 可变长度字符串,最大长度65535 | |
| BLOB | 二进制数据 | |
| TEXT | 大文本,不支持全文索引,不支持默认值 | |
| 时间日期 | DATE/DATETIME/TIMESTAMP | 日期类型(yyyy-mm-dd)(yyyy-mm-dd hh:mm:ss)timestamp时间戳 |
| String类型 | ENUM类型 | ENUI是一个字符串对象,其值来自表创建时在列规定中显示枚举的一列值 |
| SET类型 | SET是一个字符串对象,可以有零或多个值,其值来自表创建时规定的允许的一列值。指定包括多个set成员的se列值时各成员之间用逗号间隔开。这样set成员值本身不能包含逗号。 |
数值类型
| 类型 | 字节 | 最小值(带符号的/无符号的) | 最大值(带符号的/无符号的) |
|---|---|---|---|
| TINYINT | 1 | -128 | 127 |
| 0 | 255 | ||
| SMALLINT | 2 | -32768 | 32767 |
| 0 | 65535 | ||
| MEDIUMINI | 3 | -8388608 | 8388607 |
| 0 | 16777215 | ||
| INT | 4 | -2147483648 | 2147483647 |
| 0 | 4294967295 | ||
| BIGINT | 8 | -9223372036854775808 | 9223372036854775807 |
| 0 | 18446744073709551615 |
tinyint类型
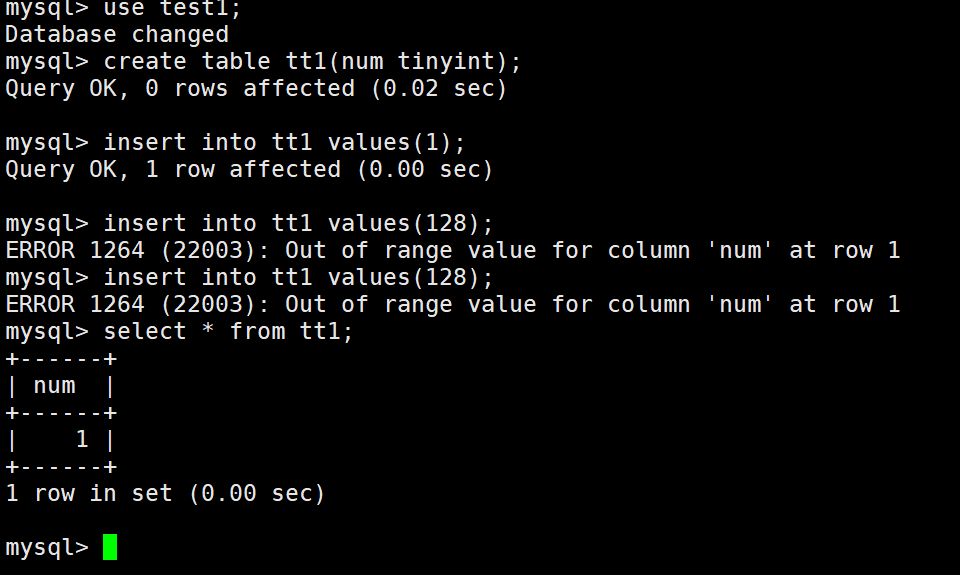
在语言层级,如果数据溢出,会进行数据截断,但是在MySQL当中就会直接报错,不会进行对应的操作。这也就说明,被插入的数据一定是合法的。
也就是说,在mysql当中,数据类型本身就是一种约束。
数据是可预期的(插入数据一定是在这个范围之内的),也是完整的。
在MySQL中,整型可以指定是有符号的和无符号的,默认是有符号的。
可以通过UNSIGNED来说明某个字段是无符号的。
例如:
insert into tt2 values(-1); – 无符号,范围是: 0 - 255
mysql建立表的方式是:
类型名 数据类型 有无符号。
注意:尽量不使用unsigned,对于int类型可能存放不下的数据,int unsigned同样可能存放不
下,与其如此,还不如设计时,将int类型提升为bigint类型。
bit类型
位字段类型。M表示每个值的位数,范围从1到64。如果M被忽略,默认为1。
bit字段在显示时,是按照ASCII码对应的值显示,所以上面没有显示内容。
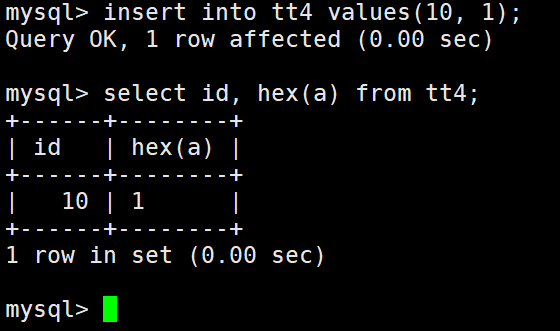
进行特殊处理才可以看得到。
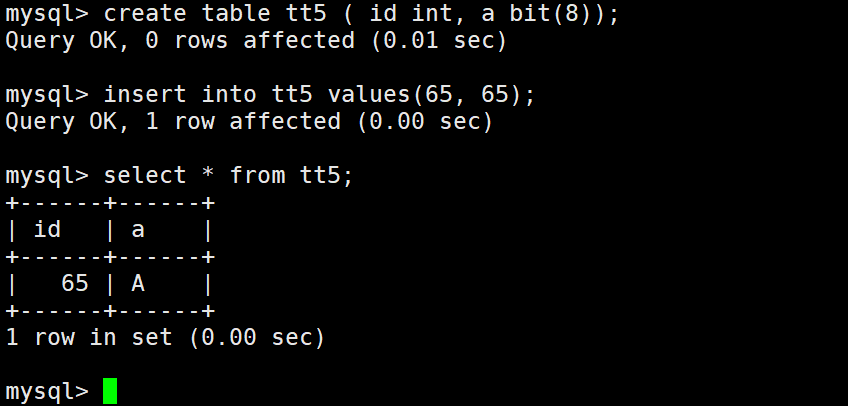
小数类型
float
float[(m, d)] [unsigned] : M指定显示长度(这个长度包含小数位数),d指定小数位数,占用空间4个字节。(精度大约是7位)
如果小数部分不够位数,那么会用0进行补全。
如果多带了一位,就会舍弃这一位进行四舍五入。(这里就不会直接拦截了)
如果定义成unsigned,那么取值范围就没有负数部分了,负数传输进去会直接报错。
decimal
decimal(m, d) [unsigned] : 定点数m指定长度,d表示小数点的位数。
decimal和float很像,但是有区别:
float和decimal表示的精度不一样,如果整数部分过大,小数点部分过长,float就会有精度损失。
decimal整数最大位数m为65。支持小数最大位数d是30。如果d被省略,默认为0.如果m被省略,
默认是10。
建议:如果希望小数的精度高,推荐使用decimal。
字符串类型
char
char(L): 固定长度字符串,L是可以存储的长度,单位为字符,最大长度值可以为255。(这里的单位为字符和C语言的不同,一个汉字在mysql当中也只算一个字符)
比如:char(2) 表示可以存放两个字符,可以是字母或汉字,但是不能超过2个, 最多只能是255。
varchar
varchar(L): 可变长度字符串,L表示字符长度,最大长度65535个字节。
关于varchar(len),len到底是多大,这个len值,和表的编码密切相关:
varchar长度可以指定为0到65535之间的值,但是有1 - 3 个字节用于记录数据大小,所以说有效字
节数是65532。(动态调整有效字符大小)
当我们的表的编码是utf8时,varchar(n)的参数n最大值是65532/3=21844[因为utf中,一个字符占
用3个字节],如果编码是gbk,varchar(n)的参数n最大是65532/2=32766(因为gbk中,一个字符
占用2字节)。
UTF8绝对不能超过21844.
** char和varchar比较**
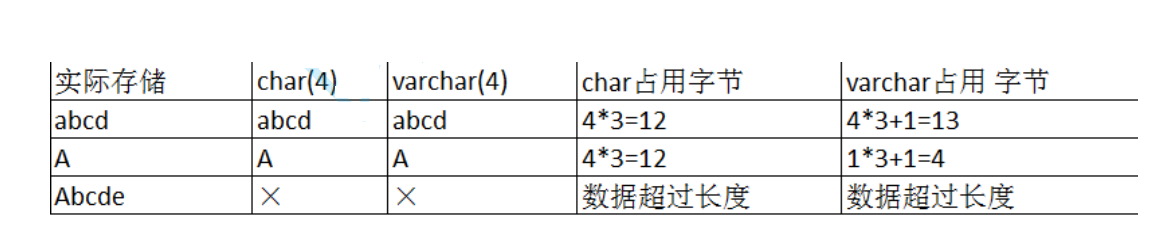
如何选择定长或变长字符串?
如果数据确定长度都一样,就使用定长(char),比如:身份证,手机号,md5
如果数据长度有变化,就使用变长(varchar), 比如:名字,地址,但是你要保证最长的能存的进去。
定长的磁盘空间比较浪费,但是效率高。
变长的磁盘空间比较节省,但是效率低。
定长的意义是,直接开辟好对应的空间
变长的意义是,在不超过自定义范围的情况下,用多少,开辟多少。
日期和时间类型
常用的日期有如下三个:
date :日期 ‘yyyy-mm-dd’ ,占用三字节。
datetime 时间日期格式 ‘yyyy-mm-dd HH:ii:ss’ 表示范围从 1000 到 9999 ,占用八字节。(允许传入自己定义的时间)
timestamp :时间戳,从1970年开始的 yyyy-mm-dd HH:ii:ss 格式和 datetime 完全一致,占用四字节。(添加数据时,时间戳自动补上当前时间)
enum和set
enum:枚举,“单选”类型;
enum(‘选项1’,‘选项2’,‘选项3’,…);
该设定只是提供了若干个选项的值,最终一个单元格中,实际只存储了其中一个值;而且出于效率考虑,这些值实际存储的是“数字”,因为这些选项的每个选项值依次对应如下数字:1,2,3,…最多65535个;当我们添加枚举值时,也可以添加对应的数字编号。(如果选择的内容错误会直接报错,不进行当前操作)
set:集合,“多选”类型;
set(‘选项值1’,‘选项值2’,‘选项值3’, …);
该设定只是提供了若干个选项的值,最终一个单元格中,设计可存储了其中任意多个值;而且出于效率考虑,这些值实际存储的是“数字”,因为这些选项的每个选项值依次对应如下数字1,2,4,8,16,32,…最多64个,类似位图,每个选项都是其中一个位,输入的十进制数哪个位为1,就会选择哪个选项。(如果选择的内容错误会直接报错,不进行当前操作,选择多种用逗号作为分隔符)
注意:不建议在添加枚举值,集合值的时候采用数字的方式,因为不利于阅读。(例如设置枚举类型的时候是“男”“女”,插入枚举类型数据的时候可以通过1或2表示“男”或“女”)
注意:插入的数据有时会是NULL,这个是为空的意思,表示什么都没有,和空串是不一样的。
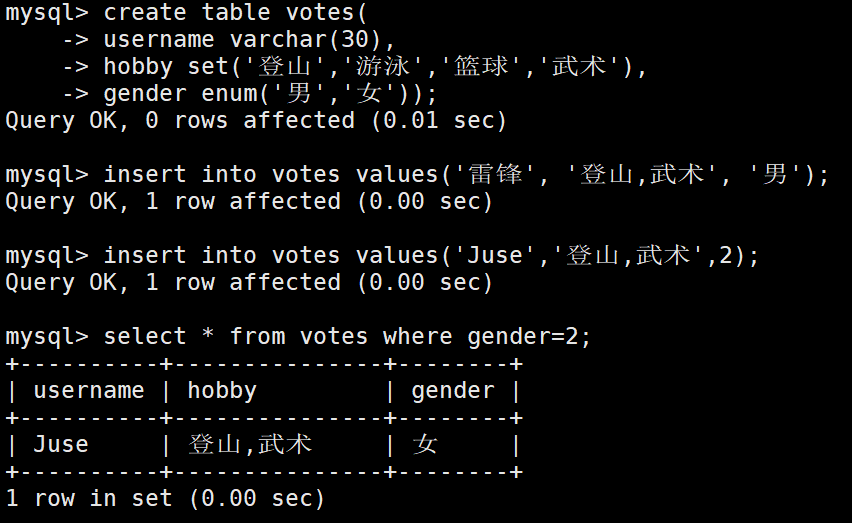
有如下数据,想查找所有喜欢登山的人:
±----------±--------------±-------+
| username | hobby | gender |
±----------±--------------±-------+
| 雷锋 | 登山,武术 | 男 |
| Juse | 登山,武术 | 女 |
| LiLei | 登山 | 男 |
| LiLei | 篮球 | 男 |
| HanMeiMei | 游泳 | 女 |
±----------±--------------±-------+
使用如下查询语句:
mysql> select * from votes where hobby=‘登山’;
±---------±-------±-------+
| username | hobby | gender |
±---------±-------±-------+
| LiLei | 登山 | 男 |
±---------±-------±-------+
不能查询出所有爱好为登山的人。
集合查询使用find_ in_ set函数:
find_in_set(sub,str_list) :如果 sub 在 str_list 中,则返回下标;如果不在,返回0;str_list 用逗号分隔的字符串。
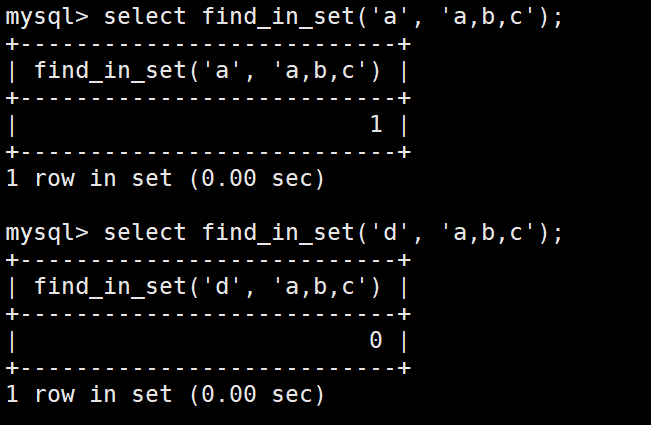
sub是要查找的内容,str_list是要查找的set数据类型表示列名。
查询爱好登山的人:
mysql> select * from votes where find_in_set(‘登山’, hobby);
±---------±--------------±-------+
| username | hobby | gender |
±---------±--------------±-------+
| 雷锋 | 登山,武术 | 男 |
| Juse | 登山,武术 | 女 |
| LiLei | 登山 | 男 |
±---------±--------------±-------+
如果想查询爱好登山和武术的人:
mysql> select * from votes where find_in_set(‘登山’, hobby) and find_in_set(‘武术’, hobby);
±---------±--------------±-------+
| username | hobby | gender |
±---------±--------------±-------+
| 雷锋 | 登山,武术 | 男 |
| Juse | 登山,武术 | 女 |
±---------±--------------±-------+