强化学习PPO算法学习记录
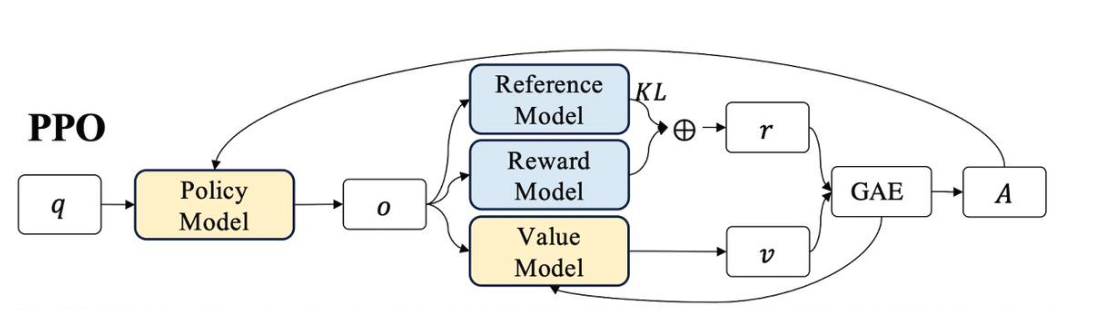
1. 四个模型:
- Policy Model:我们想要训练的目标语言模型。我们一般用SFT阶段产出的SFT模型来对它做初始化。
- Reference Model:一般也用SFT阶段得到的SFT模型做初始化,在训练过程中,它的参数是冻结的。Ref模型的主要作用是防止Actor”训歪”。(我们希望训练出来的Actor模型的输出分布和Ref模型的输出分布尽量相似,使用KL散度衡量两个输出分布的相似度,这个KL散度会用于后续loss的计算)
- Reward Model:用于计算生成token
At的即时收益,在RLHF过程中,它的参数是冻结的。 - Value Model:用于预测期望总收益
Vt,和Actor模型一样,它需要参数更新。因为在t时刻,我们给不出客观存在的总收益,只能训练一个模型去预测它。
2. r,GAE,A
图中的r或者说rt的获得:训练模型的输出分布和ref模型的输出分布的KL散度*超参数 + reward 模型的输出。
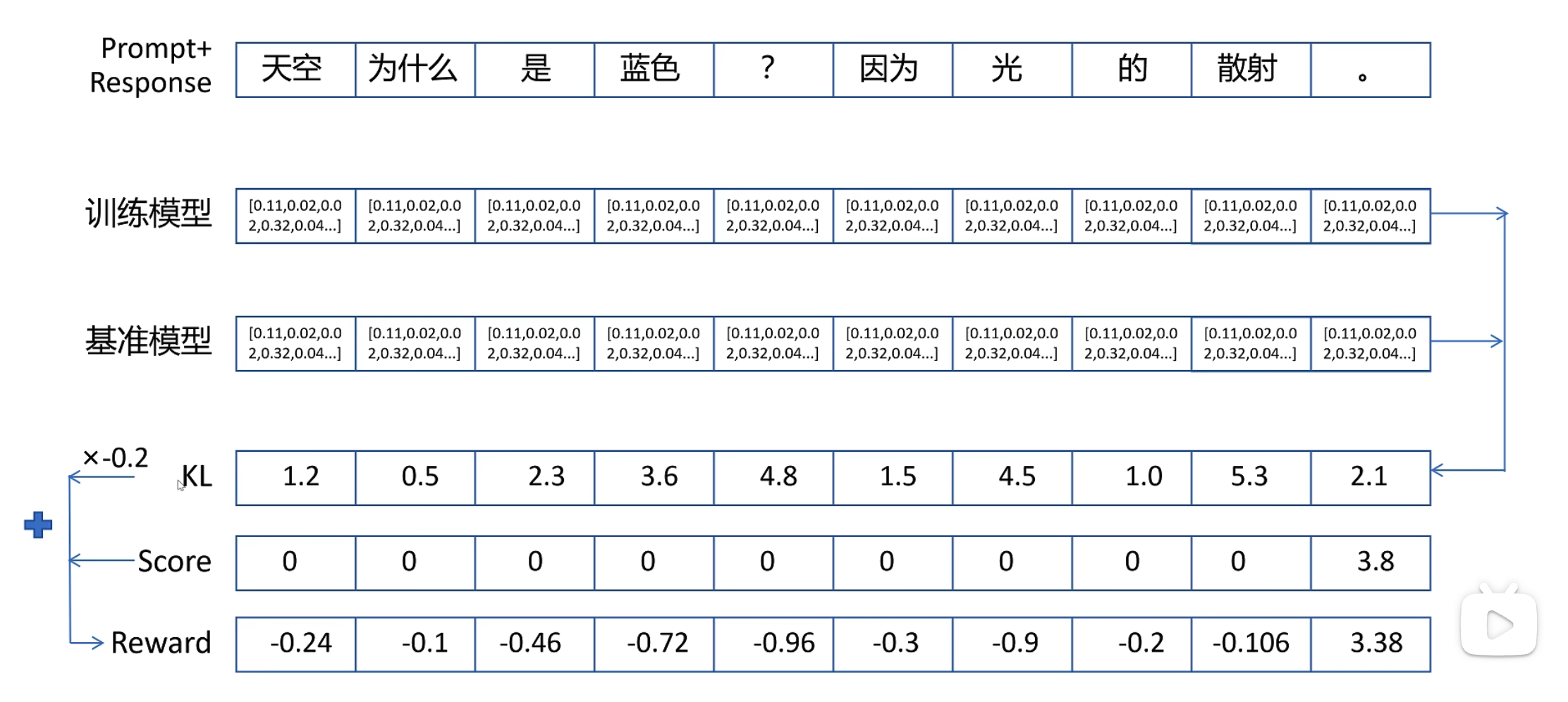

GAE整合奖励(r)与价值(v),计算优势函数 A,指导策略优化:

3. 重要性权重(新旧策略概率比)
在PPO算法中,约束重要性权重 有两种主要的约束方式:Clip机制和KL散度惩罚。

3.1 Clip机制

3.2 KL散度惩罚

将这个公式展开也就是:
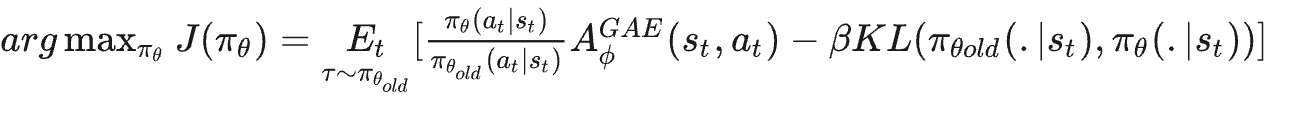
4. actor loss 和 critic loss
这两个loss 分别用于优化 policy model 和 value model
- 如果用clip限制策略更新的幅度下的actor loss:

- critic loss:
