多视图密集对应学习:细粒度3D分割的自监督革命
原文标题:Multi-view Dense Correspondence Learning (MvDeCor)
引言
在计算机视觉与图形学领域,3D形状分割一直是一个基础且具有挑战性的任务。如何在标注稀缺的情况下,实现对3D模型的细粒度分割?近期,斯坦福大学视觉实验室提出的"MvDeCor"方法给我们带来了启示:通过多视图密集对应学习,自监督预训练2D网络,并将2D嵌入反投影到3D,实现高精度的细粒度分割。本文将从方法原理、技术细节、实验验证及应用场景等多方面进行深入解读,并给出在CSDN发布的美观排版建议,帮助大家快速上手并冲上热搜。
背景与挑战
-
细粒度3D分割需求:
-
将3D模型按更小、更具体的部件分割(如将椅子分割为椅背、椅座、椅腿)。
-
能够捕捉微小结构差异,如螺丝、铆钉等。
-
-
标注数据稀缺:
-
手工标注3D模型成本高昂且耗时。
-
大规模标注难以推广到多类别与多场景。
-
-
3D网络难以表达高分辨率细节:
-
点云/体素网络在细节捕捉上受限。
-
普通3D自监督方法(如PointContrast)mIoU提升有限。
-
-
借助2D视觉先验的潜力:
-
2D图像领域自监督与对比学习技术成熟:ImageNet预训练、DenseCL等。
-
2D CNN具备高分辨率处理能力,可为3D任务提供丰富的特征。
-
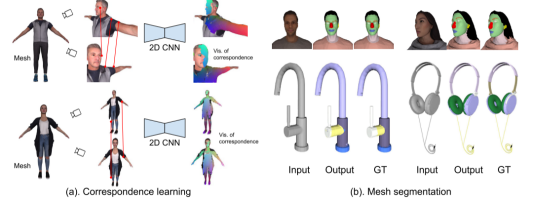
MvDeCor 方法概览
核心思想:利用多视图渲染的2D图像,在像素级别建立密集对应,通过自监督对比学习训练2D CNN,再将2D嵌入聚合为3D分割。
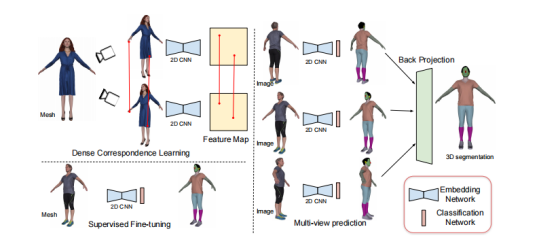
主要流程:
-
多视图渲染:从多个视角渲染3D模型,生成RGB图、深度图、法线图,以及对应的三角形索引。
-
密集对应采样:利用光线追踪记录像素对应的3D点,在不同视图中找到落在同一3D点邻域内的像素对。
-
对比学习预训练:基于InfoNCE损失,鼓励匹配像素嵌入相似,不匹配像素嵌入相异。
-
少量标注微调:在有限的带标签3D模型上,对预训练网络添加分割头,结合交叉熵与辅助自监督正则化训练。
-
多视图加权投票聚合:计算每个视图的熵权重,将2D分割结果反投影到3D三角面片,进行加权多数投票,得到最终3D语义标签。
关键技术细节
1. 自监督对比学习
-
嵌入网络Φ:基于 DeepLabV3+,输出 H×W×64 的像素级特征。
-
正负样本构造:
-
正样本:同一3D点投影到两视图的像素对 (p,q)。
-
负样本:同视图内其他像素与跨视图的不匹配像素。
-
-
InfoNCE损失:
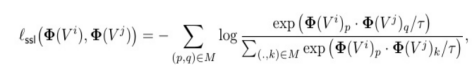
-
温度系数τ = 0.07
-
每对视图采样 ≥4K匹配点对,视图重叠 ≥15%
-
2. 微调与正则化
-
监督损失:多视图交叉熵 ℓsl\ell_{sl}。
-
辅助损失:保留 ℓssl\ell_{ssl} 正则项,权重λ = 0.001。
-
优化策略:Adam, 初始LR=0.001, 验证损失饱和时LR衰减0.5,批量归一化 + ReLU + 双线性上采样。
3. 熵加权投票聚合
-
视图权重:
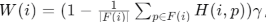
-
最终标签:
lt=argmaxc∈C∑I∈It,p∈tW(I,p)p(I,p)lt=argmaxc∈C∑I∈It,p∈tW(I,p)p(I,p),
实验验证
| 数据集 | 预训练方式 | 微调方式 | mIoU (%) | 相对提升 |
|---|---|---|---|---|
| PartNet (K=10) | DenseCL (2D) | 2D CNN微调 | 30.3 | +? |
| PointContrast (3D) | 3D CNN微调 | 31.0 | +1.6 | |
| MvDeCor (Ours) | 2D自监督+微调 | 35.9 | +4.0 | |
| RenderPeople (K=5,V=3) | ImageNet (RGB) | 2D微调 | ? | ? |
| MvDeCor (RGB) | 2D自监督+微调 | ? | ? |
应用与拓展
-
3D内容编辑:细粒度分割可用于精确选取模型局部进行纹理、变形、物理仿真等处理。
-
动画与影视制作:自动分割减少艺术家手工标注成本,加速流水线。
-
虚拟试衣与电商:人像模型分割助力服装、配饰的精准试穿效果。
-
机器人抓取与仿真:识别可抓取部件,实现更精细的操作策略。
结语与展望
MvDeCor 提出了将 2D 自监督对比学习与 3D 分割任务相结合的全新范式,显著提升了少样本条件下的细粒度分割性能。未来,可进一步探索:
-
视图选择优化:自动化选择最具信息量的视角,降低冗余计算。
-
3D-2D 互补学习:融合 3D 点云/体素的自监督损失,强化空间几何先验。
-
跨域迁移:将 MvDeCor 应用于室内场景、医疗影像、遥感等多领域。