【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件detect.py解读
【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件detect.py解读
文章目录
- 【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件detect.py解读
- 前言
- if name == ‘main’
- parse_opt函数
- main函数
- run函数
- 不同命令参数的推理结果
- 常规推理命令
- 推理命令(新增save-txt参数)
- 推理命令(新增save-conf参数)
- 推理命令(新增save-crop参数)
- 推理命令(新增visualize参数)
- 总结
前言
在详细解析YOLOV3网络之前,首要任务是搭建Ultralytics–YOLOV3【Windows11下YOLOV3人脸检测】所需的运行环境,并完成模型的训练和测试,展开后续工作才有意义。
本博文对detect.py代码进行解析,detect.py文件实现YOLOV3网络模型的推理。其他代码后续的博文将会陆续讲解。这里只做YOLOV3相关模块的代码解析。
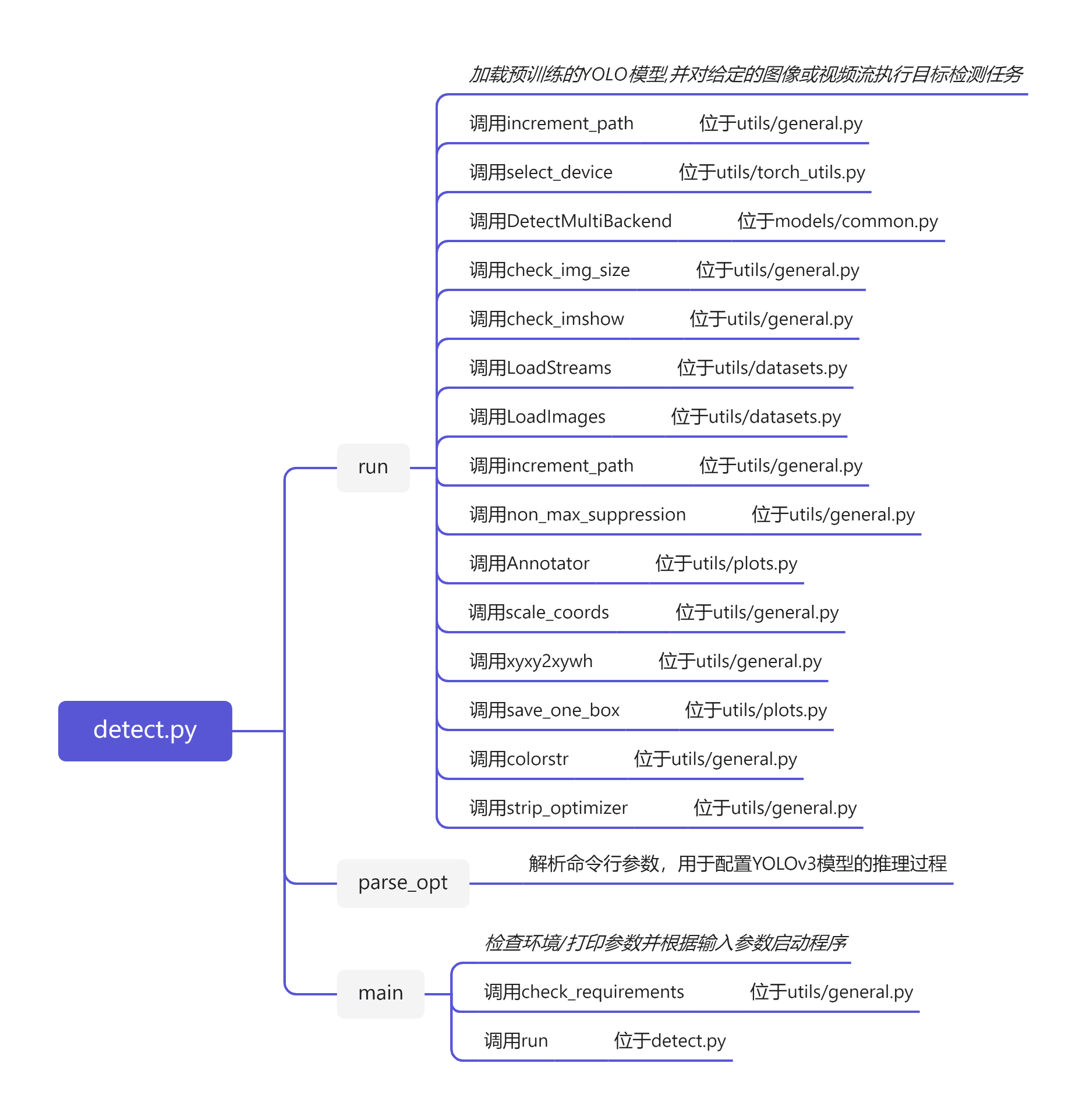
if name == ‘main’
Python脚本入口点:启动程序,调用【detect.py】的parse_opt()函数负责解析命令行参数和【detect.py】的main()函数检查依赖并调用推理函数。
if __name__ == "__main__":opt = parse_opt()main(opt)
parse_opt函数
解析命令行参数,用于配置YOLOv3模型的推理过程。
def parse_opt():"""解析命令行参数,用于配置YOLOv3模型的推理过程:return:命令行参数的对象"""parser = argparse.ArgumentParser()# weights:模型的权重地址,默认yolov3.pt nargs='+'参数选项用于指定命令行参数可以接受一个或多个值,并以列表的形式存储parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov3.pt', help='model path(s)')# source:测试数据文件(图片或视频)的保存路径,默认data/imagesparser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')# imgsz:网络输入图片的大小,默认640parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')# conf-thres:置信度阈值,默认0.25parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')# iou-thres:iou阈值(非极大值抑制NMS),默认0.45parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')# max-det:每张图片最大的目标个数,默认1000parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')# device:执行的设备cuda(单卡0或者多卡0,1,2,3)或者cpuparser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')# view-img:是否展示预测之后的图片或视频,默认Falseparser.add_argument('--view-img', action='store_true', help='show results')# save-txt:是否保存预测的边界框坐标到tx文件中,默认False,保存到runs/detect/expn/labels下每张图片的txt文件parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')# save-conf:是否保存预测目标的置信度到tx文件中,默认False,保存到runs/detect/expn/labels下每张图片的txt文件parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')# save-crop:是否需要从原图中扣出预测到的目标剪切保存,在runs/detect/expn/crops下每个类别都有自己的文件夹保存对应的剪切图片,默认Falseparser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')# nosave:是否不要保存预测后的图片,默认False,保存预测后的图片parser.add_argument('--nosave', action='store_true', help='do not save images/videos')# classes:nms是否是只保留特定的类default=[0,6,1,8,9,7],默认是None,保留所有类parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')# agnostic-nms:是否进行类别无关的nms,不区分类别直接对所有类别的边界框进行统一处理,默认Falseparser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')# augment:是否使用数据增强进行推理,默认为Falseparser.add_argument('--augment', action='store_true', help='augmented inference')# visualize:是否可视化特征图,默认为False,在runs/detect/expn下每张图片都有自己的文件夹保存的不同阶段的特征图parser.add_argument('--visualize', action='store_true', help='visualize features')# update:对所有模型进行strip_optimizer操作,从保存模型文件中移除优化器状态以及其他不必要的信息从而生成更轻量化的模型文件,默认为Falseparser.add_argument('--update', action='store_true', help='update all models')# project:当前测试结果放在哪个主文件夹下,默认runs/detectparser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')# name:当前测试结果放在run/detect下的文件名,默认是exp,exp1,exp2.... 以此类推parser.add_argument('--name', default='exp', help='save results to project/name')# exist-ok:是否覆盖已有结果,默认为Falseparser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')# line-thickness:画边界框的线条宽度,默认为3parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')# hide-labels:是否隐藏标签信息,默认为Falseparser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')# hide-conf:是否隐藏置信度信息,默认为Falseparser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')# half:是否使用半精度Float16推理(缩短推理时间),默认是Falseparser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')# dnn:是否使 OpenCV DNN进行ONNX推理,默认为Falseparser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')# 解析命令行参数,并将结果存储在opt对象中opt = parser.parse_args()# imgsz参数的长度为1则其值乘以2,否则保持不变opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1# 打印解析后的参数print_args(FILE.stem, opt) # FILE.stem是不含扩展名的文件名称:这里是detect# 返回命令行参数的对象return opt
main函数
检查环境和打印参数,并根据输入参数启动程序。
调用了【utils/general.py】的check_requirements函数;
调用了【detect.py】的run函数。
def main(opt):"""检查环境和打印参数,并根据输入参数启动程序:param opt:命令行参数的对象:return:None"""# 检查项目所需的依赖项:requrement.txt的包是否安装check_requirements(exclude=('tensorboard', 'thop')) # 排除'tensorboard'和'thop'这两个库# 调用run启动程序:命令行参数使用字典形式run(**vars(opt))
run函数
加载预训练的YOLO模型,并对给定的图像或视频流执行目标检测任务。
调用了【utils/general.py】的increment_path函数、check_img_size函数、check_imshow函数、increment_path函数、non_max_suppression函数、scale_coords函数、xyxy2xywh函数、colorstr函数和strip_optimizer函数;
调用了【utils/torch_utils.py】的select_device函数;
调用了【models/common.py】的DetectMultiBackend类;
调用了【utils/datasets.py】的LoadStreams类和LoadImages类;
调用了【utils/plots.py】的Annotator类和save_one_box函数。
- 数据准备: 主要负责数据输入的准备和验证,确保程序能够正确处理不同来源的数据(如本地文件、网络链接或摄像头流)。
# ===================================== 1.数据准备 ===================================== source = str(source) # 输入图像/视频的路径 save_img = not nosave and not source.endswith('.txt') # 保存推理图像标志:输出只要不以.txt结尾且选择保存预测结果,则都要保存预测后的图片 # .suffix用于获取文件路径中的扩展名部分 is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS) # 文件标志:检查是否为图像文件或视频文件 is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://')) # URL标志:检查是否为URL链接 # .isnumeric():是否是纯数字字符串,数字通常用来表示摄像头设备的索引 # .endswith('.txt') 是否以.txt结尾 # (is_url and not is_file)是否是URL且不是本地文件 webcam = source.isnumeric() or source.endswith('.txt') or (is_url and not is_file) # 检查是否为摄像头输入 if is_url and is_file: # 网上的图像文件或视频文件source = check_file(source) # 下载文件 # ====================================================================================== - 预测结果保持路径: 根据是否需要保存标签文件来决定是否创建子目录,它确保每次运行程序时,结果不会覆盖之前的结果,而是保存到一个独立的新目录中。
# ====================================2.预测结果保持路径======================================== save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # 递增生成的路径 (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # 创建路径 # =========================================================================================== - 模型加载: 加载目标检测模型并配置推理参数,包括设备选择、模型格式判断、图像尺寸调整和半精度设置等。
# ===================================== 3.模型加载 ===================================== device = select_device(device) # 选择设备CUDA或CPU model = DetectMultiBackend(weights, device=device, dnn=dnn) # 加载模型 # stride:推理时所用到最大步长,默认为32;names:保存预测类别对象列表;pt:加载的是否是pytorch模型;jit:加载的是否是jit格式;onnx:加载的是否是onnx模型 stride, names, pt, jit, onnx = model.stride, model.names, model.pt, model.jit, model.onnx # 获取模型属性 # 确保输入图片的尺寸imgsz能整除stride=32 imgsz = check_img_size(imgsz, s=stride)# 半精度仅支持在CUDA上运行PyTorch模型 half &= pt and device.type != 'cpu' if pt:# 将模型参数从FP32转换为FP16model.model.half() if half else model.model.float() # ==================================================================================== - 数据加载: 确保了程序能够正确处理不同类型的输入,无论是实时的摄像头流还是静态的图像或视频文件。
# ====================================4.数据加载======================================== # 不同的输入源设置不同的加载方式 if webcam: # 使用摄像头/网络视频流作为输入view_img = check_imshow() # 检测cv2.imshow()方法是否可以执行,不能执行则抛出异常cudnn.benchmark = True # 设置为True可以加速固定尺寸图像的推理dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt and not jit) # 加载输入数据流bs = len(dataset) # 批量大小,输入视频流的数量 else: # 获取本地图片/视频作为输入dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt and not jit) bs = 1 # 批量大小,单张图片或视频 # 用于保存输出视频路径和文件 vid_path, vid_writer = [None] * bs, [None] * bs # ==================================================================================== - 模型推理: 模型推理与结果处理全流程,包含了从图像预处理、模型前向传播、NMS 后处理到最终的可视化和保存。
# ====================================5.模型推理======================================== # 模型预热 if pt and device.type != 'cpu':# 对模型进行预热,以提高后续推理速度(即用一个空张量运行一次前向传播),目的是让GPU提前分配内存优化计算图等,从而提高后续推理速度# .to(device)将张量移动到指定设备(GPU或CPU);.type_as(...)匹配模型参数的数据类型# next(model.model.parameters())的作用是从模型的参数迭代器中获取第一个参数model(torch.zeros(1, 3, *imgsz).to(device).type_as(next(model.model.parameters()))) # 在后续的推理过程中会被用来记录时间(三个阶段的时间消耗)和处理的图片或视频帧数量 dt, seen = [0.0, 0.0, 0.0], 0 # 遍历数据集中的每张图片或视频帧,并进行预处理 for path, im, im0s, vid_cap, s in dataset:# ----------------5.1数据预处理-------------------t1 = time_sync() # 高精度时间函数通常用于性能测试,作为预处理阶段的起始时间im = torch.from_numpy(im).to(device) # 将NumPy数组转换为PyTorch张量并将张量移动到指定设备im = im.half() if half else im.float() # 数据类型转换,张量的数据类型使用FP16半精度或FP32单精度im /= 255 # 将像素值从[0,255]的范围归一化到[0.0,1.0]的范围if len(im.shape) == 3: # 张量的形状是三维im = im[None] # 增加一个批量维度(批量维度)t2 = time_sync() # 作为预处理阶段的结束时间dt[0] += t2 - t1 # 记录预处理阶段总耗时# ----------------------------------------------# ----------------5.2执行推理-------------------# 生成一个用于保存可视化结果的路径visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False# 输入数据进行推理,返回预测结# augment:是否启用测试时增强;visualize:是否保存网络中间层的特征图pred = model(im, augment=augment, visualize=visualize)t3 = time_sync() # 作为推理阶段的结束时间dt[1] += t3 - t2 # 记录推理阶段总耗时# --------------------------------------------# ----------------5.3NMS-------------------# 对模型的预测结果进行非极大值抑制,去除冗余的检测框,保留最优的结果pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det) # 非极大值抑制NMSdt[2] += time_sync() - t3 # 记录后处理阶段的总耗时# -----------------------------------------# Second-stage classifier (optional)# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)# 遍历每张图片的预测结果for i, det in enumerate(pred): # 每次处理一张图像或视频帧seen += 1 # 统计总共处理的图像/帧,自增1if webcam: # 摄像头/网络视频流输入 batch_size >= 1 多个摄像头或网络视频流# p:图像路径;im0:未归一化原始图像;frame:当前帧编号p, im0, frame = path[i], im0s[i].copy(), dataset.count# 通常有多个视频流输入作为批量输入,处理当前批次的那个图片序号就表示处理的是那个视频流的帧s += f'{i}: ' # 记录日志信息else: # 本地图像或视频帧输入# 从dataset对象中获取名为frame的属性值;没有定义frame属性,返回默认值0p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)p = Path(p) # 将路径转换为Path对象save_path = str(save_dir / p.name) # 保存检测结果图像的路径# 视频或摄像头流,文件名则附加_帧号后缀txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # 保存检测框标签文件的路径s += '%gx%g ' % im.shape[2:] # 日志字符串中添加当前图像的尺寸信息# 原始图像形状为(H,W,C)或(H,W),[[1,0,1,0]]提取[W,H,W,H]gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # 将检测框坐标从[0~1]归一化格式转换回原始图像像素坐标的缩放因子imc = im0.copy() if save_crop else im0 # 保存裁剪目标,复制原始图像,防止原图被修改annotator = Annotator(im0, line_width=line_thickness, example=str(names))if len(det): # 有检测结果则进行坐标映射# 将检测框坐标从模型输入尺寸640x640映射回原始图像尺寸det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()# 统计检测类别及数量# det[:, -1]:取出所有检测目标的类别编号;.unique():返回张量中的唯一值,去重后的元素for c in det[:, -1].unique(): # 遍历所有检测到的类别编号n = (det[:, -1] == c).sum() # 统计每个类别出现次数s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # 构造日志字符串# *xyxy:左上角和右下角坐标[x1,y1,x2,y2];conf:置信度;cls:类别编号for *xyxy, conf, cls in reversed(det): # 用于遍历检测结果,通常优先处理高置信度的检测框if save_txt: # 将检测框信息写入txt文件# xyxy2xywh()将[x1,y1,x2,y2]转换为[xc,yc,w,h]格式xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # 将坐标归一化到[0,1line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # 是否添加置信度# 写入文件,每行一个检测框with open(txt_path + '.txt', 'a') as f:f.write(('%g ' * len(line)).rstrip() % line + '\n')if save_img or save_crop or view_img: # 启用绘图功能,则在图像上绘制检测框和标签c = int(cls) # 类别序号# hide_labels:不显示标签;hide_conf:不显示置信度# 不显示标签则直接不显示置信度label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}') # 控制是否显示类别名和置信度annotator.box_label(xyxy, label, color=colors(c, True)) # 用于在图像上绘制边界框和标签if save_crop: # 裁剪的目标区域save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True) # 保存裁剪的目标区域到指定路径# 打印单帧图像的目标检测推理所用时间(不包括前处理和后处理)LOGGER.info(f'{s}Done. ({t3 - t2:.3f}s)')im0 = annotator.result() # 获取带有边界框标签等信息的图像if view_img: # 显示图像cv2.imshow(str(p), im0) # 将标注了检测框的结果图像显示在窗口中,用于实时查看检测效果cv2.waitKey(1) # 等待1毫秒,保持窗口更新,防止卡死if save_img: # 保存检测结果图像或视频if dataset.mode == 'image': # 图像模式cv2.imwrite(save_path, im0) # cv2.imwrite() 保存图片else: # 视频或流媒体模式if vid_path[i] != save_path: # 检查当前视频路径是否与新的保存路径不同vid_path[i] = save_path # 不同则更新路径,开始处理新的视频文件if isinstance(vid_writer[i], cv2.VideoWriter): # cv2.VideoWriter类型的对象vid_writer[i].release() # 释放旧的资源,以避免冲突if vid_cap: # 视频输入fps = vid_cap.get(cv2.CAP_PROP_FPS) # 从原视频中获取帧率# 获取视频的宽度和高度。w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))else: # 摄像头输入# 设置默认帧率为30,宽度和高度为当前帧尺寸fps, w, h = 30, im0.shape[1], im0.shape[0]save_path += '.mp4' # .mp4格式保存# save_path:保存路径;v2.VideoWriter_fourcc(*'mp4v'):MP4编码格式# fps:帧率;(w, h):视频分辨率vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h)) # 创建新的VideoWriter对象,用于写入处理后的帧vid_writer[i].write(im0) # 将当前帧写入视频文件 # ====================================================================================
完整代码
def run(weights=ROOT / 'yolov3.pt', # 训练的权重路径source=ROOT / 'data/images', # 图像/视频文件,图像目录,URL,0(摄像头)imgsz=640, # 推理图像分辨率conf_thres=0.25, # 置信度阈值iou_thres=0.45, # IOU阈值(非极大值抑制NMS)max_det=1000, # 每张图像的最大检测数device='', # CUDA单卡或多卡(0或0,1,2,3)或CPUview_img=False, # 显示结果save_txt=False, # 将结果(类别和边框大小位置)保存到txtsave_conf=False, # 将置信度保存到txtsave_crop=False, # 保存裁剪后的图像nosave=False, # 不保存图像/视频结果classes=None, # 按类别过滤筛选保留agnostic_nms=False, # 类别无关的NMSaugment=False, # 增强推理visualize=False, # 可视化特征update=False, # 更新所有模型(简洁化)project=ROOT / 'runs/detect', # 保存结果的路径name='exp', # 保存结果的名称exist_ok=False, # 覆盖现有结果,不名称递增保存line_thickness=3, # 边界框厚度(像素)hide_labels=False, # 输出结果隐藏标签hide_conf=False, # 输出结果隐藏置信度half=False, # 使用FP16半精度推理dnn=False, # 使用OpenCV DNN进行ONNX推理):"""加载预训练的YOLO模型,并对给定的图像或视频流执行目标检测任务:param weights:训练的权重路径,可以使用自己训练的权重,也可以使用官网提供的权重,默认官网的权重yolov3.pt:param source:测试数据,可以是图片/视频路径,也可以是'0'(电脑自带摄像头),也可以是rtsp等视频流,默认data/images:param imgsz: 网络模型输入图片尺寸,默认的大小是640:param conf_thres:置信度阈值,默认为0.25:param iou_thres:nms的iou阈值,默认为0.45:param max_det:保留的最大检测框数量,每张图片中检测目标的个数最多为1000:param device:设置设备CPU/CUDA/多CUDA,默认不设置:param view_img:是否界面展示检测结果(图片/视频),默认False:param save_txt:是否将预测的框坐标以txt文件形式保存,默认False,使用时在路径runs/detect/exp*/labels/*.txt下生成每张图片预测的txt文件:param save_conf:是否将置信度conf也保存到txt中,默认False,使用时在路径runs/detect/exp*/labels/*.txt下生成每张图片预测的txt文件:param save_crop:是否保存裁剪预测框图片,默认为False,使用时在runs/detect/exp*/crop/剪切类别文件夹/ 路径下会保存每个接下来的目标:param nosave:不保存图片/视频, 默认保存因此不设置,在runs/detect/exp*/保存预测的结果:param classes:设置只保留某一部分类别[0,6,1,8,9,7],默认不设置,设置时在路径runs/detect/exp*/下保存[0,6,1,8,9,7]对应的类别的图片:param agnostic_nms:进行NMS去除不同类别之间的框,默认False:param augment: 测试时增强/多尺度预测:param visualize:是否可视化网络层输出特征:param update:为True则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息,默认为False:param project:保存测试日志的文件夹路径,默认runs/detect:param name:保存测试日志文件夹的名字,所以最终是保存在project/name中:param exist_ok:是否重新创建日志文件,False时重新创建文件:param line_thickness:画框的线条粗细:param hide_labels:预测结果隐藏标签:param hide_conf:预测结果隐藏置信度:param half:是否使用F16精度推理,半进度提高检测速度:param dnn:用OpenCV DNN预测:return:None"""# ===================================== 1.数据准备 =====================================source = str(source) # 输入图像/视频的路径save_img = not nosave and not source.endswith('.txt') # 保存推理图像标志:输出只要不以.txt结尾且选择保存预测结果,则都要保存预测后的图片# .suffix用于获取文件路径中的扩展名部分is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS) # 文件标志:检查是否为图像文件或视频文件is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://')) # URL标志:检查是否为URL链接# .isnumeric():是否是纯数字字符串,数字通常用来表示摄像头设备的索引# .endswith('.txt') 是否以.txt结尾# (is_url and not is_file)是否是URL且不是本地文件webcam = source.isnumeric() or source.endswith('.txt') or (is_url and not is_file) # 检查是否为摄像头输入if is_url and is_file: # 网上的图像文件或视频文件source = check_file(source) # 下载文件# ======================================================================================# ====================================2.预测结果保持路径========================================save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # 递增生成的路径(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # 创建路径# ===========================================================================================# ===================================== 3.模型加载 =====================================device = select_device(device) # 选择设备CUDA或CPUmodel = DetectMultiBackend(weights, device=device, dnn=dnn) # 加载模型# stride:推理时所用到最大步长,默认为32;names:保存预测类别对象列表;# pt:加载的是否是pytorch模型;jit:加载的是否是jit格式;onnx:加载的是否是onnx模型stride, names, pt, jit, onnx = model.stride, model.names, model.pt, model.jit, model.onnx # 获取模型属性# 确保输入图片的尺寸imgsz能整除stride=32imgsz = check_img_size(imgsz, s=stride)# 半精度仅支持在CUDA上运行PyTorch模型half &= pt and device.type != 'cpu'if pt:# 将模型参数从FP32转换为FP16model.model.half() if half else model.model.float()# ====================================================================================# ====================================4.数据加载========================================# 不同的输入源设置不同的加载方式if webcam: # 使用摄像头/网络视频流作为输入view_img = check_imshow() # 检测cv2.imshow()方法是否可以执行,不能执行则抛出异常cudnn.benchmark = True # 设置为True可以加速固定尺寸图像的推理dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt and not jit) # 加载输入数据流bs = len(dataset) # 批量大小,输入视频流的数量else: # 获取本地图片/视频作为输入dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt and not jit)bs = 1 # 批量大小,单张图片或视频# 用于保存输出视频路径和文件vid_path, vid_writer = [None] * bs, [None] * bs# ====================================================================================# ====================================5.模型推理========================================# 模型预热if pt and device.type != 'cpu':# 对模型进行预热,以提高后续推理速度(即用一个空张量运行一次前向传播),目的是让GPU提前分配内存优化计算图等,从而提高后续推理速度# .to(device)将张量移动到指定设备(GPU或CPU);.type_as(...)匹配模型参数的数据类型# next(model.model.parameters())的作用是从模型的参数迭代器中获取第一个参数model(torch.zeros(1, 3, *imgsz).to(device).type_as(next(model.model.parameters())))# 在后续的推理过程中会被用来记录时间(三个阶段的时间消耗)和处理的图片或视频帧数量dt, seen = [0.0, 0.0, 0.0], 0# 遍历数据集中的每张图片或视频帧,并进行预处理for path, im, im0s, vid_cap, s in dataset:# ----------------5.1数据预处理-------------------t1 = time_sync() # 高精度时间函数通常用于性能测试,作为预处理阶段的起始时间im = torch.from_numpy(im).to(device) # 将NumPy数组转换为PyTorch张量并将张量移动到指定设备im = im.half() if half else im.float() # 数据类型转换,张量的数据类型使用FP16半精度或FP32单精度im /= 255 # 将像素值从[0,255]的范围归一化到[0.0,1.0]的范围if len(im.shape) == 3: # 张量的形状是三维im = im[None] # 增加一个批量维度(批量维度)t2 = time_sync() # 作为预处理阶段的结束时间dt[0] += t2 - t1 # 记录预处理阶段总耗时# ----------------------------------------------# ----------------5.2执行推理-------------------# 生成一个用于保存可视化结果的路径visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False# 输入数据进行推理,返回预测结# augment:是否启用测试时增强;visualize:是否保存网络中间层的特征图pred = model(im, augment=augment, visualize=visualize)t3 = time_sync() # 作为推理阶段的结束时间dt[1] += t3 - t2 # 记录推理阶段总耗时# --------------------------------------------# ----------------5.3NMS-------------------# 对模型的预测结果进行非极大值抑制,去除冗余的检测框,保留最优的结果pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det) # 非极大值抑制NMSdt[2] += time_sync() - t3 # 记录后处理阶段的总耗时# -----------------------------------------# Second-stage classifier (optional)# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)# 遍历每张图片的预测结果for i, det in enumerate(pred): # 每次处理一张图像或视频帧seen += 1 # 统计总共处理的图像/帧,自增1if webcam: # 摄像头/网络视频流输入 batch_size >= 1 多个摄像头或网络视频流# p:图像路径;im0:未归一化原始图像;frame:当前帧编号p, im0, frame = path[i], im0s[i].copy(), dataset.count# 通常有多个视频流输入作为批量输入,处理当前批次的那个图片序号就表示处理的是那个视频流的帧s += f'{i}: ' # 记录日志信息else: # 本地图像或视频帧输入# 从dataset对象中获取名为frame的属性值;没有定义frame属性,返回默认值0p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)p = Path(p) # 将路径转换为Path对象save_path = str(save_dir / p.name) # 保存检测结果图像的路径# 视频或摄像头流,文件名则附加_帧号后缀txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # 保存检测框标签文件的路径s += '%gx%g ' % im.shape[2:] # 日志字符串中添加当前图像的尺寸信息# 原始图像形状为(H,W,C)或(H,W),[[1,0,1,0]]提取[W,H,W,H]gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # 将检测框坐标从[0~1]归一化格式转换回原始图像像素坐标的缩放因子imc = im0.copy() if save_crop else im0 # 保存裁剪目标,复制原始图像,防止原图被修改annotator = Annotator(im0, line_width=line_thickness, example=str(names))if len(det): # 有检测结果则进行坐标映射# 将检测框坐标从模型输入尺寸640x640映射回原始图像尺寸det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()# 统计检测类别及数量# det[:, -1]:取出所有检测目标的类别编号;.unique():返回张量中的唯一值,去重后的元素for c in det[:, -1].unique(): # 遍历所有检测到的类别编号n = (det[:, -1] == c).sum() # 统计每个类别出现次数s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # 构造日志字符串# *xyxy:左上角和右下角坐标[x1,y1,x2,y2];conf:置信度;cls:类别编号for *xyxy, conf, cls in reversed(det): # 用于遍历检测结果,通常优先处理高置信度的检测框if save_txt: # 将检测框信息写入txt文件# xyxy2xywh()将[x1,y1,x2,y2]转换为[xc,yc,w,h]格式xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # 将坐标归一化到[0,1line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # 是否添加置信度# 写入文件,每行一个检测框with open(txt_path + '.txt', 'a') as f:f.write(('%g ' * len(line)).rstrip() % line + '\n')if save_img or save_crop or view_img: # 启用绘图功能,则在图像上绘制检测框和标签c = int(cls) # 类别序号# hide_labels:不显示标签;hide_conf:不显示置信度# 不显示标签则直接不显示置信度label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}') # 控制是否显示类别名和置信度annotator.box_label(xyxy, label, color=colors(c, True)) # 用于在图像上绘制边界框和标签if save_crop: # 裁剪的目标区域save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True) # 保存裁剪的目标区域到指定路径# 打印单帧图像的目标检测推理所用时间(不包括前处理和后处理)LOGGER.info(f'{s}Done. ({t3 - t2:.3f}s)')im0 = annotator.result() # 获取带有边界框标签等信息的图像if view_img: # 显示图像cv2.imshow(str(p), im0) # 将标注了检测框的结果图像显示在窗口中,用于实时查看检测效果cv2.waitKey(1) # 等待1毫秒,保持窗口更新,防止卡死if save_img: # 保存检测结果图像或视频if dataset.mode == 'image': # 图像模式cv2.imwrite(save_path, im0) # cv2.imwrite() 保存图片else: # 视频或流媒体模式if vid_path[i] != save_path: # 检查当前视频路径是否与新的保存路径不同vid_path[i] = save_path # 不同则更新路径,开始处理新的视频文件if isinstance(vid_writer[i], cv2.VideoWriter): # cv2.VideoWriter类型的对象vid_writer[i].release() # 释放旧的资源,以避免冲突if vid_cap: # 视频输入fps = vid_cap.get(cv2.CAP_PROP_FPS) # 从原视频中获取帧率# 获取视频的宽度和高度。w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))else: # 摄像头输入# 设置默认帧率为30,宽度和高度为当前帧尺寸fps, w, h = 30, im0.shape[1], im0.shape[0]save_path += '.mp4' # .mp4格式保存# save_path:保存路径;v2.VideoWriter_fourcc(*'mp4v'):MP4编码格式# fps:帧率;(w, h):视频分辨率vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h)) # 创建新的VideoWriter对象,用于写入处理后的帧vid_writer[i].write(im0) # 将当前帧写入视频文件# ====================================================================================t = tuple(x / seen * 1E3 for x in dt) # 计算每个阶段(预处理、推理、NMS)每张图像所花费的平均时间# 使用日志记录器输出模型的速度信息LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)if save_txt or save_img: # 保存文本标签或者保存图像# save_dir.glob('labels/*.txt'):查找指定目录下所有.txt文件;s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''# 显示保存了多少个标签文件,否则为空字符串LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")if update: # 设置了更新标志# 移除模型中的优化器状态从而减小模型大小,并避免警告strip_optimizer(weights) # update model (to fix SourceChangeWarning)
不同命令参数的推理结果
一些常用命令参数的使用情况,并展示和说明其输出结果。
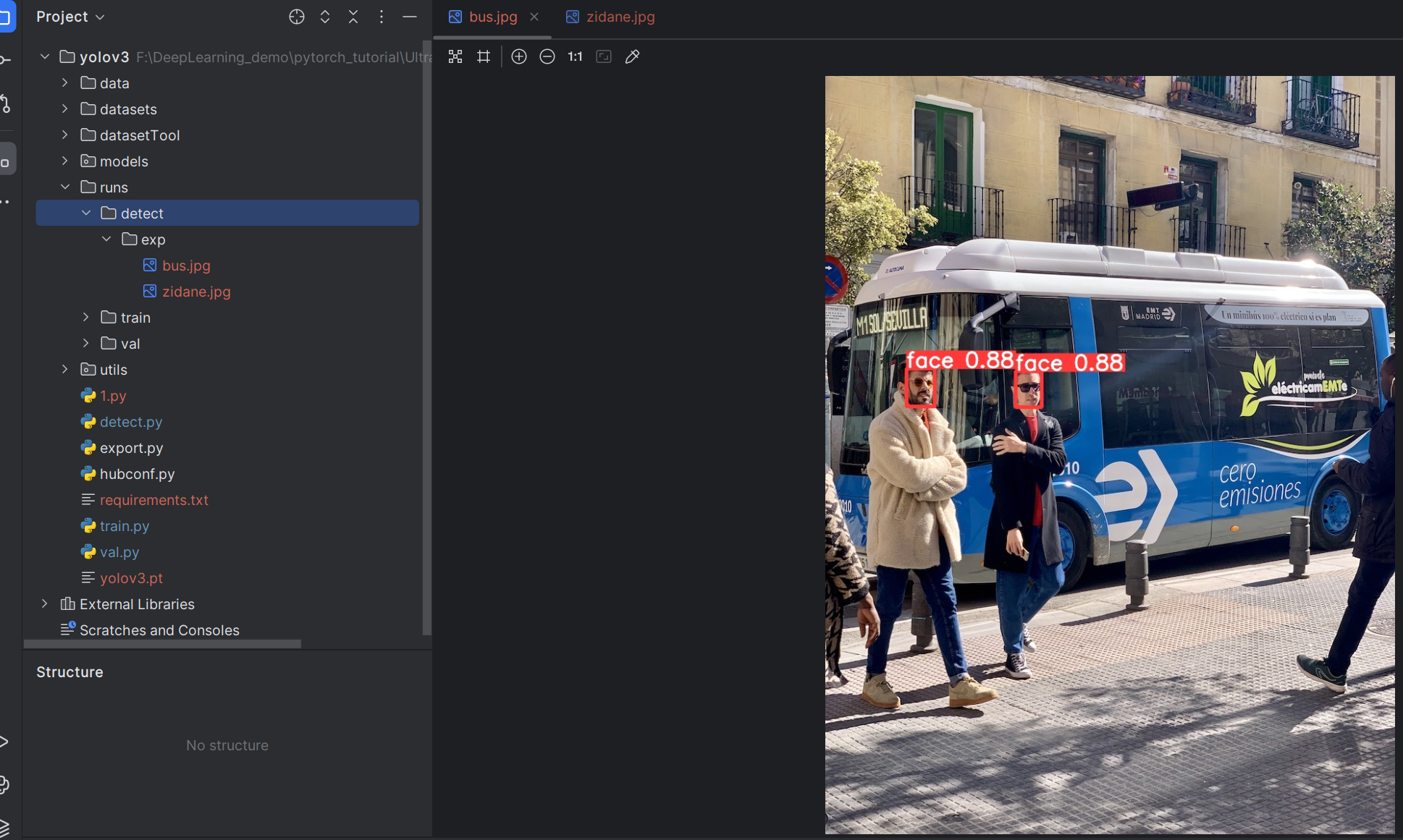
常规推理命令
只进行最基础的设置:
–weights指定模型权重文件路径,用于加载训练好的模型进行推理;
–source:指定要检测的数据源,可以是图片、视频、摄像头等;
–device:指定运行设备:0 表示使用 GPU(CUDA),也可以指定多个GPU如 0,1,或者使用 cpu;
–conf-thres:设置置信度阈值(confidence threshold),只有置信度高于该值的目标才会被保留;
–iou-thres:设置 NMS(非极大值抑制)的 IoU 阈值,用于去除重叠过多的预测框。
python detect.py --weights runs/train/exp/weights/best.pt --source data/images --device 0 --conf-thres 0.7 --iou-thres 0.3
控制台输出结果:

文件保存内容:
推理命令(新增save-txt参数)
–save-txt:保存预测边界框信息到文本文件中。
python detect.py --weights runs/train/exp/weights/best.pt --source data/images --device 0 --conf-thres 0.7 --iou-thres 0.3 --save-txt
控制台输出结果:

文件保存内容:
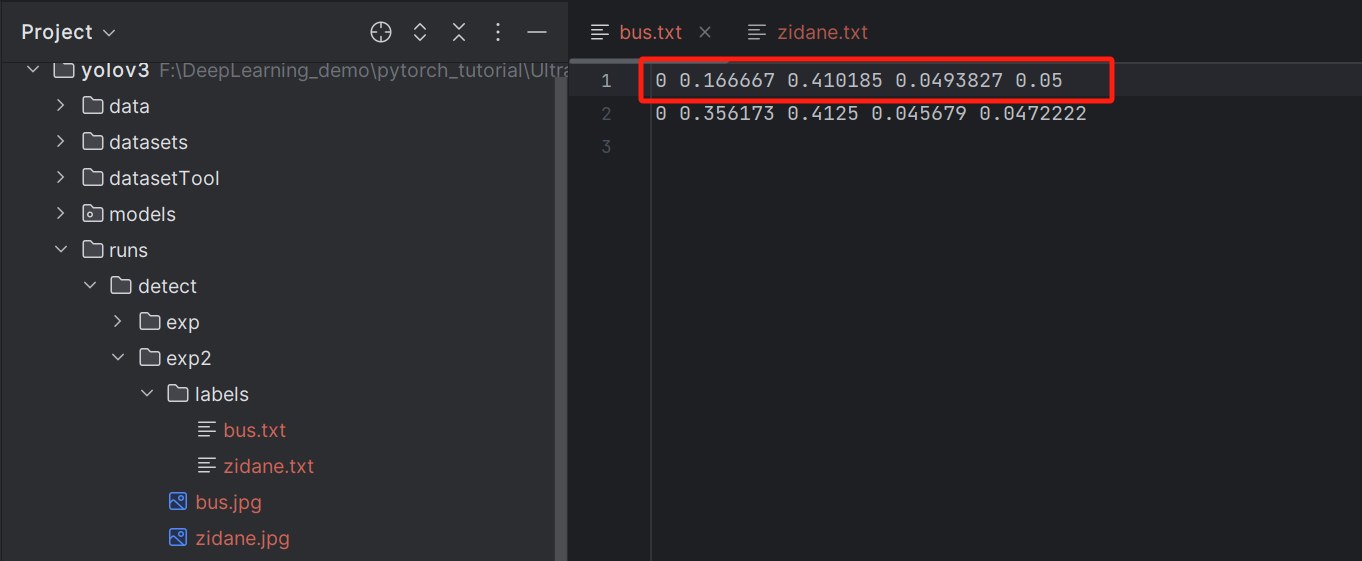
0表示标签序号;剩下的四个数值分别是框中心坐标以及框的尺寸。
推理命令(新增save-conf参数)
–save-conf:保存置信度信息到文本文件中。
python detect.py --weights runs/train/exp/weights/best.pt --source data/images --device 0 --conf-thres 0.7 --iou-thres 0.3 --save-txt --save-conf
使用–save-conf参数一定要先使用–save-txt参数,单独使用不起作用,并且保存的数据是在同一个txt文件中。
控制台输出结果:

文件保存内容:
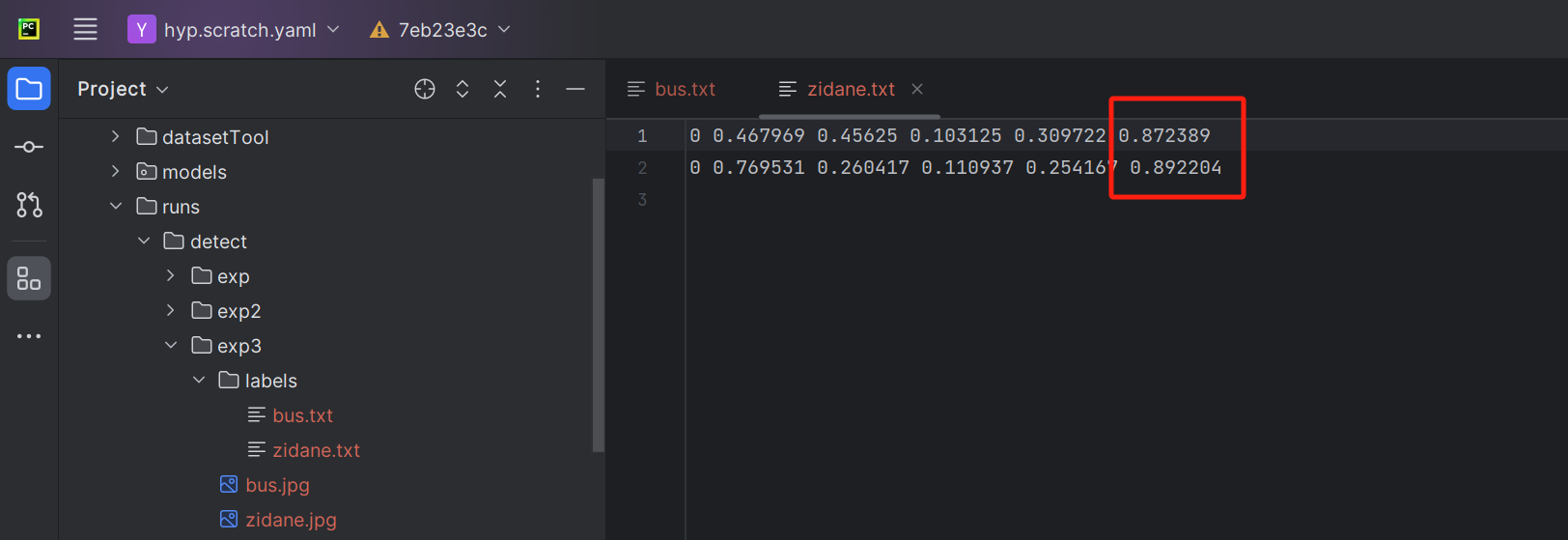
0表示标签序号;中间四个数值分别是框中心坐标以及框的尺寸;最后一个数值是置信度。
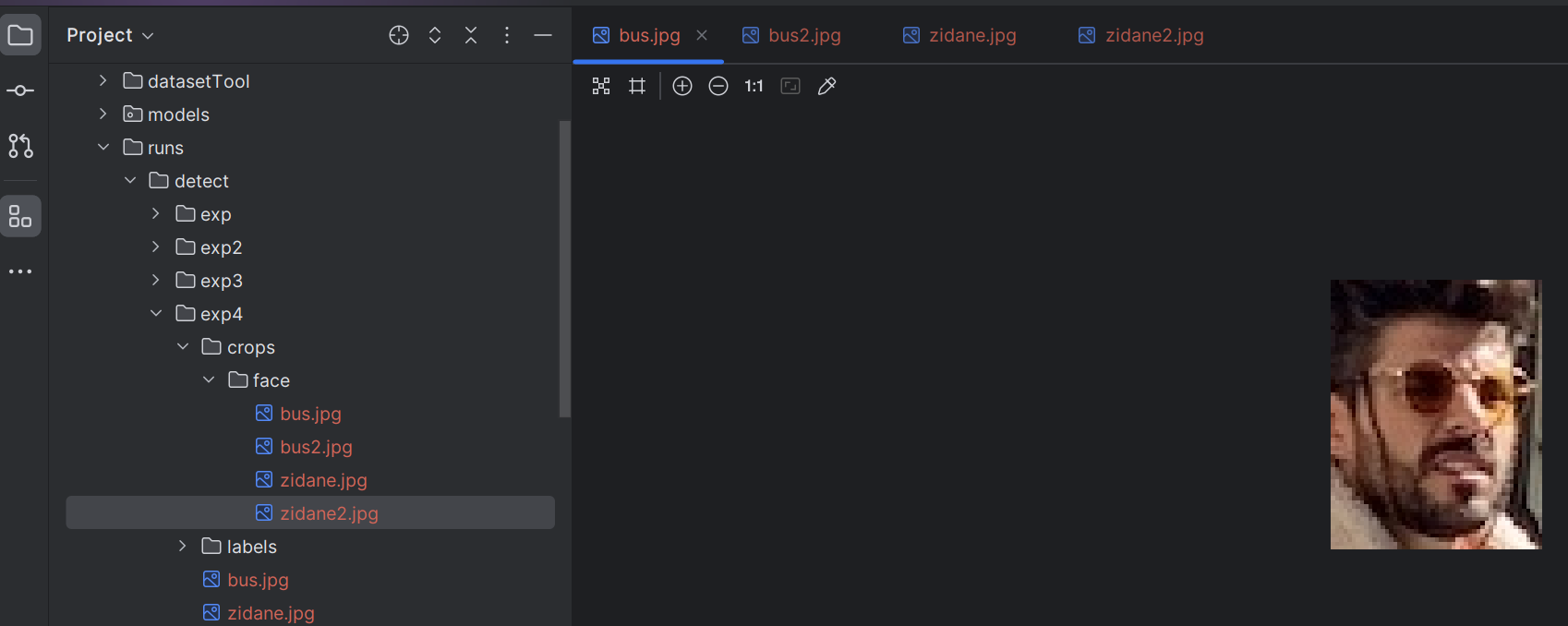
推理命令(新增save-crop参数)
–save-crop:将检测到的目标从原图中裁剪出来并单独保存。
python detect.py --weights runs/train/exp/weights/best.pt --source data/images --device 0 --conf-thres 0.7 --iou-thres 0.3 --save-txt --save-conf --save-crop
控制台输出结果:

文件保存内容:
推理命令(新增visualize参数)
–visualize:可视化模型中间层特征图。
python detect.py --weights runs/train/exp/weights/best.pt --source data/images --device 0 --conf-thres 0.7 --iou-thres 0.3 --save-txt --save-conf --save-crop --visualize
控制台输出结果:
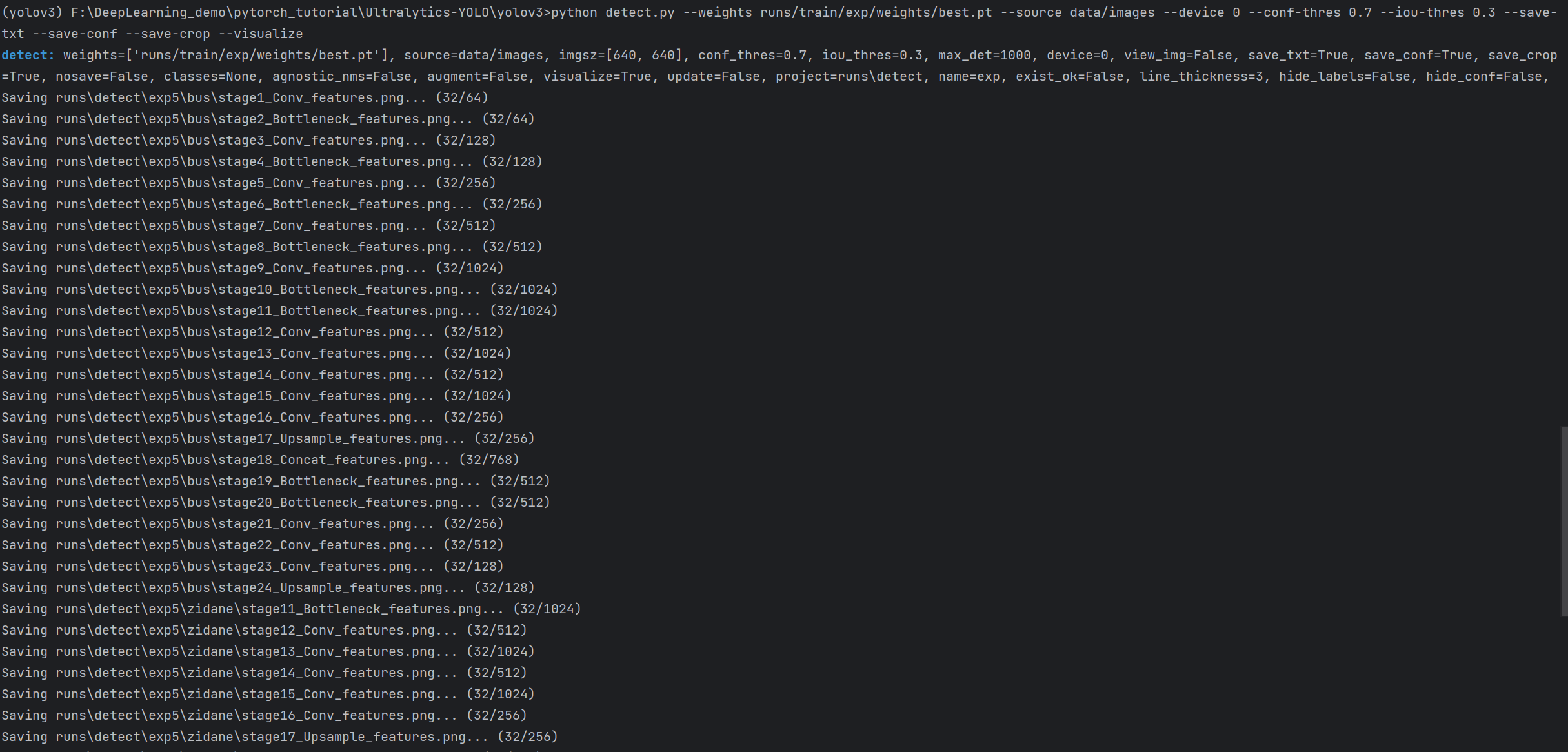
32/XXX:32是保存特征图的数量,XXX是当前网络层输出特征图的数量。
文件保存内容:
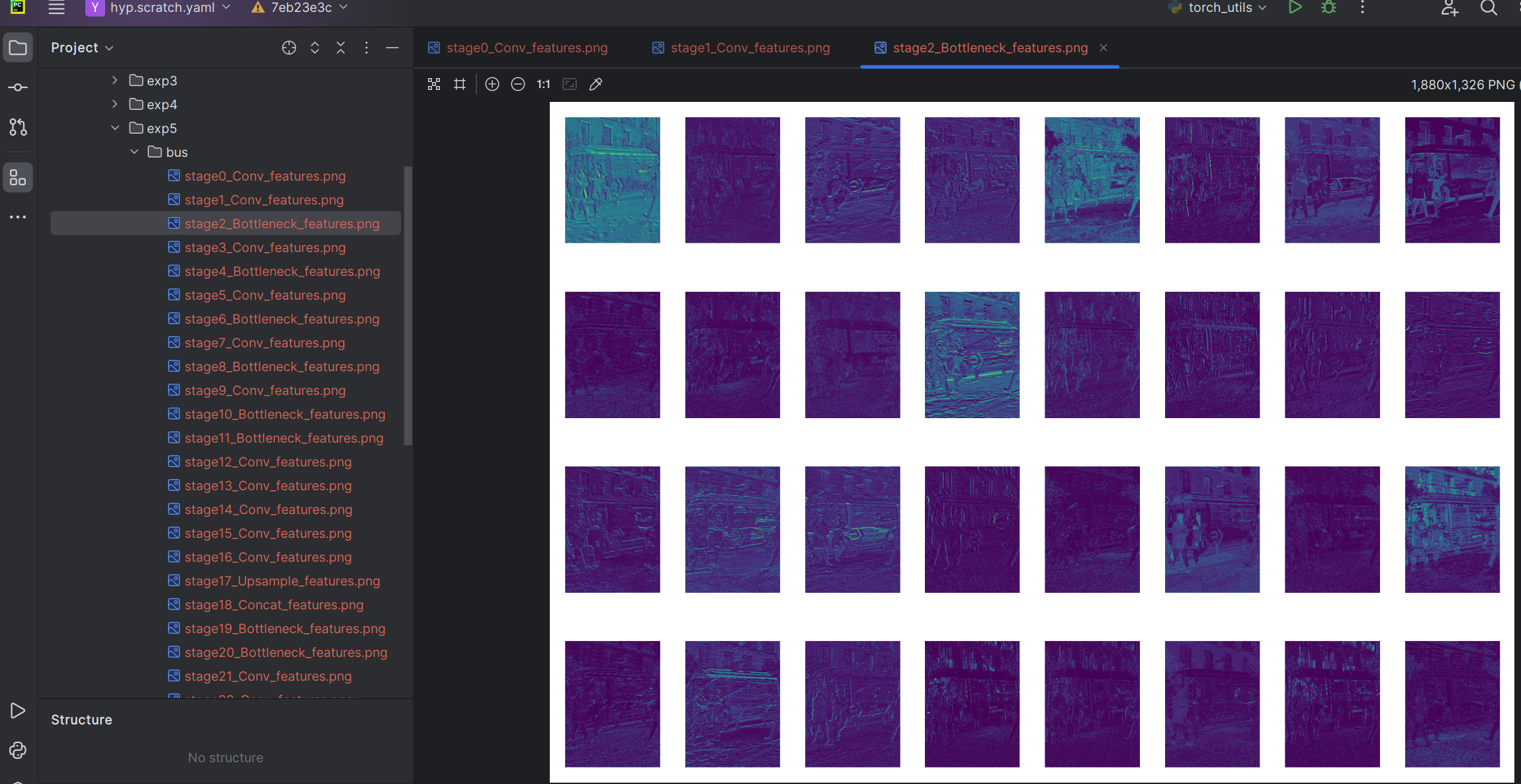
每个被检测的图像都单独生成一个以图像文件名命名的文件夹,保存不同网络层的特征图,这里每层限制保存32张特征图。
总结
尽可能简单、详细的介绍了核心文件detect.py文件的作用:根据命令行参数设置YOLOv3模型的推理流程。