深入理解主从数据库架构与主从复制
目录
- 前言
- 1. 主从数据库概述
- 1.1 什么是主从数据库?
- 1.2 主从数据库的应用场景
- 2. 主从数据库的工作原理
- 2.1 主从数据库的读写分离
- 2.2 数据同步机制
- 2.3 异步与同步复制模式
- 3. 主从复制的实现步骤
- 3.1 配置主库
- 3.2 配置从库
- 4. 主从数据库架构的优缺点
- 4.1 优点
- 4.2 缺点
- 5. 结语
前言
随着互联网和大数据时代的到来,数据库的性能与可扩展性变得尤为重要。在高并发、高可用的业务场景中,如何有效地分担数据库的压力、提升系统的性能和可靠性,成为了开发者和架构师们的重要课题。主从数据库架构就是一种常见的解决方案,它能够通过将读操作和写操作分离,来提高数据库的负载能力,确保数据的高可用性。
本文将深入探讨主从数据库的概念、作用以及主从复制的实现过程,帮助大家更好地理解这一架构及其在实际应用中的重要性。
1. 主从数据库概述
1.1 什么是主从数据库?
主从数据库是一种数据库架构模式,它由一台主数据库(Master)和多台从数据库(Slave)组成。在这种架构中,主数据库负责所有的数据写操作(INSERT、UPDATE、DELETE),而从数据库则主要承担数据读取任务(SELECT)。通过这种读写分离的方式,主数据库和从数据库能够高效协同工作,以提高系统的性能和可用性。
主从数据库架构的设计可以根据实际需求进行调整,其中主库通常是性能最强的一台机器,负责承载所有的写入请求,而从库则是主库的副本,它会定期从主库获取数据,并保持同步。通过多个从库的配合,系统的读操作可以被均衡分摊到不同的节点上,从而提高整体系统的性能。
1.2 主从数据库的应用场景
主从数据库架构适用于以下几种常见的场景:
- 高并发应用: 在用户访问量非常大的应用中,读请求通常占据了大部分的负载。主从架构可以通过将读操作分散到多个从库上,减少主库的负担,从而提高整体系统的吞吐量。
- 高可用性: 主从复制提供了数据冗余的机制。如果主库发生故障,可以通过切换到从库来确保服务的连续性,增强系统的容灾能力。
- 数据备份: 从库不仅仅用于读取操作,还可以作为主库数据的备份。这样,即使主库发生问题,也能够保证数据不丢失。
2. 主从数据库的工作原理
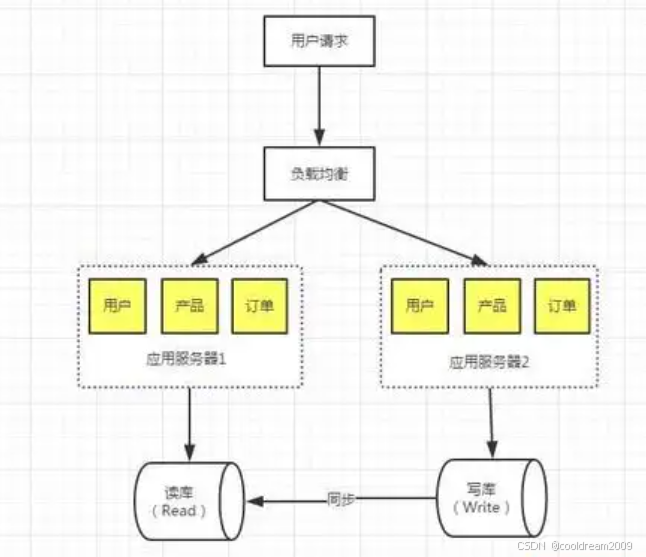
2.1 主从数据库的读写分离
主从数据库的核心优势之一就是实现了读写分离。在传统的单一数据库架构中,所有的操作(无论是读还是写)都只能依赖于单一数据库实例。随着业务的增长,这种架构将面临巨大的性能瓶颈,尤其是当系统需要处理大量的查询请求时。
主从数据库架构则通过将写操作集中到主库上,而将读操作分发到从库上,从而将读写负载分开,避免了读操作对写操作的干扰,显著提高了数据库系统的性能。
2.2 数据同步机制
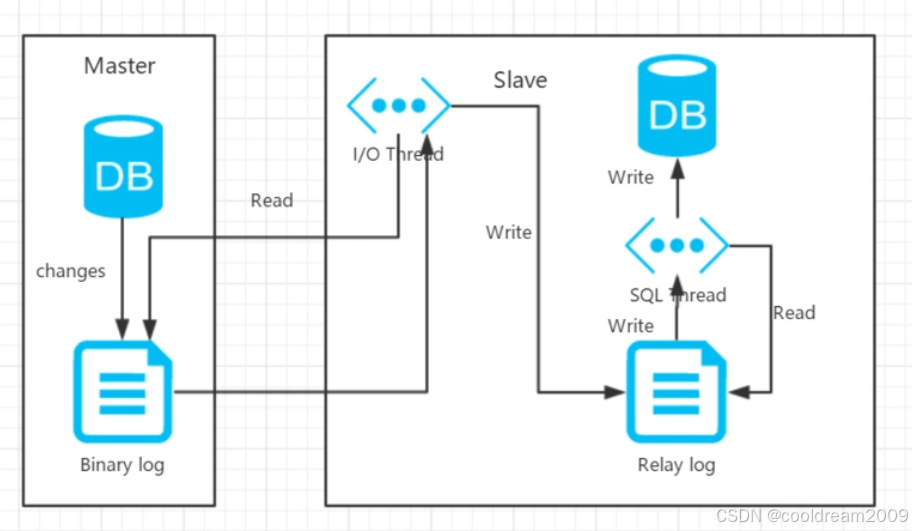
主从数据库的另一个关键特性是数据同步。主库的所有写操作都会通过主从复制的机制,自动同步到从库。这确保了从库的数据与主库保持一致,从库始终是主库的镜像。数据同步的实现通常通过以下步骤:
- 主库记录写操作: 主库的所有数据修改操作(如 INSERT、UPDATE、DELETE)会被记录到主库的二进制日志(Binlog)中,供从库读取。
- 从库拉取日志: 从库通过 I/O 线程定期向主库请求最新的 Binlog,将主库的写操作拉取到本地的中继日志(Relay Log)中。
- 从库执行写操作: 从库的 SQL 线程读取中继日志,执行相应的操作,使得从库的数据与主库保持一致。
2.3 异步与同步复制模式
根据复制的方式不同,主从复制可以分为异步复制、半同步复制和全同步复制几种模式。
- 异步复制: 这是最常见的复制方式,主库在提交事务后不会等待从库的反馈,立即返回给客户端。这种方式虽然性能较好,但在主库和从库之间存在数据同步延迟的风险,主库可能在从库还未接收到数据时就发生故障。
- 半同步复制: 在主库提交事务后,它至少会等待一个从库确认已接收到该事务的 Binlog,然后再返回给客户端。这种方式较为安全,能够减少数据丢失的风险,但仍然存在一定的延迟。
- 全同步复制: 主库会等待所有的从库都成功接收到并执行完所有的事务后,才会返回给客户端。这种方式确保了数据的一致性,但性能较差,尤其是在从库较多的情况下,延迟会显著增加。
3. 主从复制的实现步骤
3.1 配置主库
主库配置相对简单,主要的工作是启用二进制日志,并确保每次数据变更都会记录到日志中。具体步骤如下:
-
启用 Binlog: 在主库的配置文件中(
my.cnf或my.ini),启用 Binlog 并设置服务器 ID。例如:server-id = 1 log-bin = mysql-bin -
创建复制账号: 为从库创建一个专门用于复制的账号,该账号需要有
REPLICATION SLAVE权限。可以通过以下 SQL 创建:CREATE USER 'replica'@'%' IDENTIFIED BY 'password'; GRANT REPLICATION SLAVE ON *.* TO 'replica'@'%'; FLUSH PRIVILEGES; -
获取主库的日志位置: 记录当前主库的二进制日志文件名和位置,用于从库的同步起点。可以通过以下命令获取:
SHOW MASTER STATUS;
3.2 配置从库
从库需要配置连接到主库,并拉取 Binlog 进行数据同步。具体步骤如下:
-
配置服务器 ID: 在从库的配置文件中,设置唯一的服务器 ID。例如:
server-id = 2 -
连接主库: 配置从库连接主库的账号信息、主库的 IP 地址以及 Binlog 文件和位置。执行以下 SQL:
CHANGE MASTER TOMASTER_HOST='主库IP',MASTER_USER='replica',MASTER_PASSWORD='password',MASTER_LOG_FILE='记录的Binlog文件名',MASTER_LOG_POS=记录的Binlog位置; -
启动复制进程: 启动从库的 I/O 线程和 SQL 线程,开始进行数据同步:
START SLAVE; -
检查复制状态: 使用以下命令检查复制是否正常进行:
SHOW SLAVE STATUS\G
4. 主从数据库架构的优缺点
4.1 优点
- 性能优化: 主从架构可以将读操作负载分散到多个从库上,提高系统的整体吞吐量。
- 高可用性: 通过从库的冗余备份,系统在主库故障时可以迅速切换,减少系统宕机时间。
- 扩展性: 当读请求不断增加时,可以通过增加更多的从库来水平扩展系统。
- 数据备份与恢复: 从库可以用作数据备份,减少主库的备份压力,确保数据安全。
4.2 缺点
- 延迟问题: 尽管使用了复制机制,但由于网络延迟和复制延迟等因素,从库的数据可能稍有滞后,可能导致读取的结果不完全实时。
- 复杂性: 主从复制的配置和管理相对复杂,需要保证主库与从库的网络连接稳定,监控复制状态等。
- 写瓶颈: 主库仍然是所有写操作的瓶颈,若主库的负载过高,可能会影响整个系统的性能。
5. 结语
主从数据库架构是现代分布式系统中非常重要的一环。通过读写分离、负载均衡、数据备份等手段,主从架构能够显著提升数据库的性能、可靠性和可扩展性。然而,尽管主从架构有着诸多优势,我们仍然需要注意数据同步的延迟问题、配置复杂性和主库的写瓶颈等挑战。
理解主从数据库的工作原理和应用场景,能够帮助我们更好地设计和优化系统架构,在应对高并发和高可用需求时做出合理的决策。希望本文能够为你提供有价值的参考,助力你在实际工作中充分利用主从数据库架构,提升系统的整体性能和可用性。