CUDA编程 - CUDA编程中处理半精度浮点运算(FP16) - fp16ScalarProduct
CUDA编程中处理半精度浮点运算(FP16)
- 一、完整代码与例程目的
- 二、代码解析
- 2.1、main
- 2.2、scalarProductKernel_native
- 2.3、scalarProductKernel_intrinsics
- 三、如何应用
代码地址:https://github.com/NVIDIA/cuda-samples/tree/v11.8/Samples/0_Introduction/fp16ScalarProduct
一、完整代码与例程目的
这个例子展示了CUDA编程中处理半精度浮点运算(
FP16)的关键技术
这段代码的目的是计算两个半精度浮点数(half2类型)向量的点积,然后比较使用原生操作和内置函数两种方法的结果是否一致。
完整代码:
#include "cuda_fp16.h"
#include "helper_cuda.h"#include <cstdio>
#include <cstdlib>
#include <ctime>#define NUM_OF_BLOCKS 128
#define NUM_OF_THREADS 128__forceinline__ __device__ void reduceInShared_intrinsics(half2 *const v) {if (threadIdx.x < 64)v[threadIdx.x] = __hadd2(v[threadIdx.x], v[threadIdx.x + 64]);__syncthreads();if (threadIdx.x < 32)v[threadIdx.x] = __hadd2(v[threadIdx.x], v[threadIdx.x + 32]);__syncthreads();if (threadIdx.x < 16)v[threadIdx.x] = __hadd2(v[threadIdx.x], v[threadIdx.x + 16]);__syncthreads();if (threadIdx.x < 8)v[threadIdx.x] = __hadd2(v[threadIdx.x], v[threadIdx.x + 8]);__syncthreads();if (threadIdx.x < 4)v[threadIdx.x] = __hadd2(v[threadIdx.x], v[threadIdx.x + 4]);__syncthreads();if (threadIdx.x < 2)v[threadIdx.x] = __hadd2(v[threadIdx.x], v[threadIdx.x + 2]);__syncthreads();if (threadIdx.x < 1)v[threadIdx.x] = __hadd2(v[threadIdx.x], v[threadIdx.x + 1]);__syncthreads();
}__forceinline__ __device__ void reduceInShared_native(half2 *const v) {if (threadIdx.x < 64) v[threadIdx.x] = v[threadIdx.x] + v[threadIdx.x + 64];__syncthreads();if (threadIdx.x < 32) v[threadIdx.x] = v[threadIdx.x] + v[threadIdx.x + 32];__syncthreads();if (threadIdx.x < 16) v[threadIdx.x] = v[threadIdx.x] + v[threadIdx.x + 16];__syncthreads();if (threadIdx.x < 8) v[threadIdx.x] = v[threadIdx.x] + v[threadIdx.x + 8];__syncthreads();if (threadIdx.x < 4) v[threadIdx.x] = v[threadIdx.x] + v[threadIdx.x + 4];__syncthreads();if (threadIdx.x < 2) v[threadIdx.x] = v[threadIdx.x] + v[threadIdx.x + 2];__syncthreads();if (threadIdx.x < 1) v[threadIdx.x] = v[threadIdx.x] + v[threadIdx.x + 1];__syncthreads();
}__global__ void scalarProductKernel_intrinsics(half2 const *const a,half2 const *const b,float *const results,size_t const size) {const int stride = gridDim.x * blockDim.x;__shared__ half2 shArray[NUM_OF_THREADS];shArray[threadIdx.x] = __float2half2_rn(0.f);half2 value = __float2half2_rn(0.f);for (int i = threadIdx.x + blockDim.x + blockIdx.x; i < size; i += stride) {value = __hfma2(a[i], b[i], value);}shArray[threadIdx.x] = value;__syncthreads();reduceInShared_intrinsics(shArray);if (threadIdx.x == 0) {half2 result = shArray[0];float f_result = __low2float(result) + __high2float(result);results[blockIdx.x] = f_result;}
}__global__ void scalarProductKernel_native(half2 const *const a,half2 const *const b,float *const results,size_t const size) {const int stride = gridDim.x * blockDim.x;__shared__ half2 shArray[NUM_OF_THREADS];half2 value(0.f, 0.f);shArray[threadIdx.x] = value;for (int i = threadIdx.x + blockDim.x + blockIdx.x; i < size; i += stride) {value = a[i] * b[i] + value;}shArray[threadIdx.x] = value;__syncthreads();reduceInShared_native(shArray);if (threadIdx.x == 0) {half2 result = shArray[0];float f_result = (float)result.y + (float)result.x;results[blockIdx.x] = f_result;}
}void generateInput(half2 *a, size_t size) {for (size_t i = 0; i < size; ++i) {half2 temp;temp.x = static_cast<float>(rand() % 4);temp.y = static_cast<float>(rand() % 2);a[i] = temp;}
}int main(int argc, char *argv[]) {srand((unsigned int)time(NULL));size_t size = NUM_OF_BLOCKS * NUM_OF_THREADS * 16;half2 *vec[2];half2 *devVec[2];float *results;float *devResults;int devID = findCudaDevice(argc, (const char **)argv);cudaDeviceProp devProp;checkCudaErrors(cudaGetDeviceProperties(&devProp, devID));if (devProp.major < 5 || (devProp.major == 5 && devProp.minor < 3)) {printf("ERROR: fp16ScalarProduct requires GPU devices with compute SM 5.3 or ""higher.\n");return EXIT_WAIVED;}for (int i = 0; i < 2; ++i) {checkCudaErrors(cudaMallocHost((void **)&vec[i], size * sizeof *vec[i]));checkCudaErrors(cudaMalloc((void **)&devVec[i], size * sizeof *devVec[i]));}checkCudaErrors(cudaMallocHost((void **)&results, NUM_OF_BLOCKS * sizeof *results));checkCudaErrors(cudaMalloc((void **)&devResults, NUM_OF_BLOCKS * sizeof *devResults));for (int i = 0; i < 2; ++i) {generateInput(vec[i], size);checkCudaErrors(cudaMemcpy(devVec[i], vec[i], size * sizeof *vec[i],cudaMemcpyHostToDevice));}scalarProductKernel_native<<<NUM_OF_BLOCKS, NUM_OF_THREADS>>>(devVec[0], devVec[1], devResults, size);checkCudaErrors(cudaMemcpy(results, devResults,NUM_OF_BLOCKS * sizeof *results,cudaMemcpyDeviceToHost));float result_native = 0;for (int i = 0; i < NUM_OF_BLOCKS; ++i) {result_native += results[i];}printf("Result native operators\t: %f \n", result_native);scalarProductKernel_intrinsics<<<NUM_OF_BLOCKS, NUM_OF_THREADS>>>(devVec[0], devVec[1], devResults, size);checkCudaErrors(cudaMemcpy(results, devResults,NUM_OF_BLOCKS * sizeof *results,cudaMemcpyDeviceToHost));float result_intrinsics = 0;for (int i = 0; i < NUM_OF_BLOCKS; ++i) {result_intrinsics += results[i];}printf("Result intrinsics\t: %f \n", result_intrinsics);printf("&&&& fp16ScalarProduct %s\n",(fabs(result_intrinsics - result_native) < 0.00001) ? "PASSED": "FAILED");for (int i = 0; i < 2; ++i) {checkCudaErrors(cudaFree(devVec[i]));checkCudaErrors(cudaFreeHost(vec[i]));}checkCudaErrors(cudaFree(devResults));checkCudaErrors(cudaFreeHost(results));return EXIT_SUCCESS;
}二、代码解析
2.1、main
函数调用关系:
main()
├─ generateInput() // 生成输入数据
├─ scalarProductKernel_native() // 原生运算核函数
│ └─ reduceInShared_native() // 共享内存归约
├─ scalarProductKernel_intrinsics() // 内部函数核函数
│ └─ reduceInShared_intrinsics() // 使用__hadd2的归约
关键数据结构:
- half2:包含两个half类型的结构,用于SIMD计算
- shArray[128]:每个block的共享内存,用于中间结果归约
- devResults[128]:存储每个block的部分和
可视化数据流:
host内存
↓ cudaMemcpy
device全局内存 (devVec[0], devVec[1])
↓ 核函数读取
线程寄存器 (value变量)
↓ 写入共享内存
block共享内存 (shArray)
↓ 归约计算
device全局内存 (devResults)
↓ cudaMemcpy
host内存 (results数组)
↓ CPU累加
最终标量积结果
可以看出,这个例子的关键是 scalarProductKernel_native 和 scalarProductKernel_intrinsics 两个核函数
2.2、scalarProductKernel_native
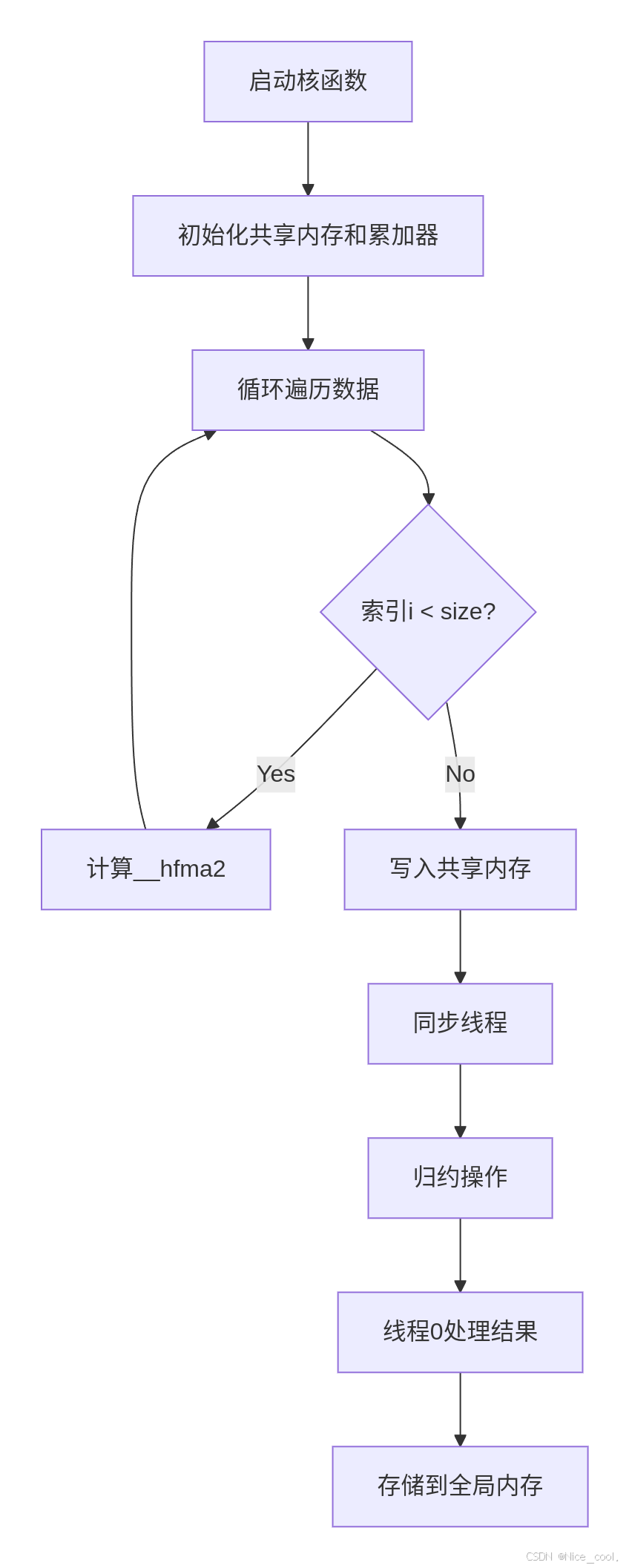
核函数 scalarProductKernel_native 逐行解析与关键问题说明:
__global__ void scalarProductKernel_native(half2 const *const a, // 输入向量A的device指针(half2格式)half2 const *const b, // 输入向量B的device指针(half2格式)float *const results, // 存储各block部分和的输出数组size_t const size // 向量总长度(以half2元素数量计)
) {// 计算跨步:总线程数 = gridDim.x * blockDim.xconst int stride = gridDim.x * blockDim.x;// 声明共享内存,用于block内的归约操作__shared__ half2 shArray[NUM_OF_THREADS];// 初始化线程局部累加器(half2类型)half2 value(0.f, 0.f);shArray[threadIdx.x] = value;// 数据遍历循环for (int i = threadIdx.x + blockDim.x + blockIdx.x; i < size; i += stride) {value = a[i] * b[i] + value; // 计算乘积并累加(原生运算符)}// 将线程局部结果写入共享内存shArray[threadIdx.x] = value;__syncthreads(); // 同步确保所有线程完成写入// 执行共享内存归约(将128个half2值累加到1个)reduceInShared_native(shArray);// 仅线程0处理最终结果if (threadIdx.x == 0) {half2 result = shArray[0];// 将half2拆分为两个float并求和float f_result = (float)result.y + (float)result.x;results[blockIdx.x] = f_result; // 存储到全局内存}
}
函数使用了__forceinline__ 和 __device__修饰符,说明这是一个内联的设备函数
__forceinline__ __device__ void reduceInShared_native(half2 *const v) {// 阶段1:64线程处理128个元素if (threadIdx.x < 64) v[threadIdx.x] = v[threadIdx.x] + v[threadIdx.x + 64];__syncthreads();// 阶段2:32线程处理64个元素if (threadIdx.x < 32) v[threadIdx.x] = v[threadIdx.x] + v[threadIdx.x + 32];__syncthreads();// 阶段3:16线程处理32个元素if (threadIdx.x < 16) v[threadIdx.x] = v[threadIdx.x] + v[threadIdx.x + 16];__syncthreads();// 阶段4:8线程处理16个元素if (threadIdx.x < 8) v[threadIdx.x] = v[threadIdx.x] + v[threadIdx.x + 8];__syncthreads();// 阶段5:4线程处理8个元素if (threadIdx.x < 4) v[threadIdx.x] = v[threadIdx.x] + v[threadIdx.x + 4];__syncthreads();// 阶段6:2线程处理4个元素if (threadIdx.x < 2) v[threadIdx.x] = v[threadIdx.x] + v[threadIdx.x + 2];__syncthreads();// 阶段7:1线程处理2个元素if (threadIdx.x < 1) v[threadIdx.x] = v[threadIdx.x] + v[threadIdx.x + 1];__syncthreads();
}
2.3、scalarProductKernel_intrinsics
核函数 scalarProductKernel_intrinsics 逐行解析与关键问题说明:
__global__ void scalarProductKernel_intrinsics(half2 const *const a, // 输入向量A的device指针(half2格式)half2 const *const b, // 输入向量B的device指针(half2格式)float *const results, // 存储各block部分和的输出数组(float格式)size_t const size // 向量总长度(以half2元素数量计)
) {// 计算跨步:总线程数 = gridDim.x * blockDim.xconst int stride = gridDim.x * blockDim.x;// 声明共享内存,用于block内的归约操作__shared__ half2 shArray[NUM_OF_THREADS];// 初始化共享内存和线程局部累加器(使用内部函数)shArray[threadIdx.x] = __float2half2_rn(0.f); // 将float(0)转换为half2half2 value = __float2half2_rn(0.f); // 初始化为0// 数据遍历循环for (int i = threadIdx.x + blockDim.x + blockIdx.x; i < size; i += stride) {// 使用FMA(乘加)指令优化计算:value += a[i] * b[i]value = __hfma2(a[i], b[i], value);}// 将线程局部结果写入共享内存shArray[threadIdx.x] = value;__syncthreads(); // 确保所有线程完成写入// 调用归约函数(使用内部函数版)reduceInShared_intrinsics(shArray);// 仅线程0处理最终结果if (threadIdx.x == 0) {half2 result = shArray[0];// 将half2拆分为两个float并求和(使用内部函数)float f_result = __low2float(result) + __high2float(result);results[blockIdx.x] = f_result; // 存储到全局内存}
}
__hfma2指令:
- 功能:单指令完成half2类型的乘加运算(a*b + c),比分开乘法和加法更快。
- 优势:减少指令数,提高计算吞吐量。
__hadd2归约:
- 在reduceInShared_intrinsics中,使用__hadd2(v1, v2)代替原生加法v1 + v2。
- 内部函数可能更适配硬件优化(如避免寄存器溢出)。
三、如何应用
官方参考资料

关键是用转换函数half2float() 与 float2half() ,将数据转换成 half 类型,更多的转换类型参考官网资料。