DeepResearch深度搜索实现方法调研
DeepResearch深度搜索实现方法调研
Deep Research 有三个核心能力
- 能力一:自主规划解决问题的搜索路径(生成子问题,queries,检索)
- 能力二:在探索路径时动态调整搜索方向(刘亦菲最好的一部电影是什么?如何定义好?已有信息是否足够?)
- 能力三:对多源的信息进行验证,整合(一个文档说 37 岁,另一个文档说 27 岁,怎么分辨?)
非强化学习方法:
《Search-o1: Agentic Search-Enhanced Large Reasoning Models》(能力二)
作者:人大+清华
https://github.com/sunnynexus/Search-o1 (Star 800)
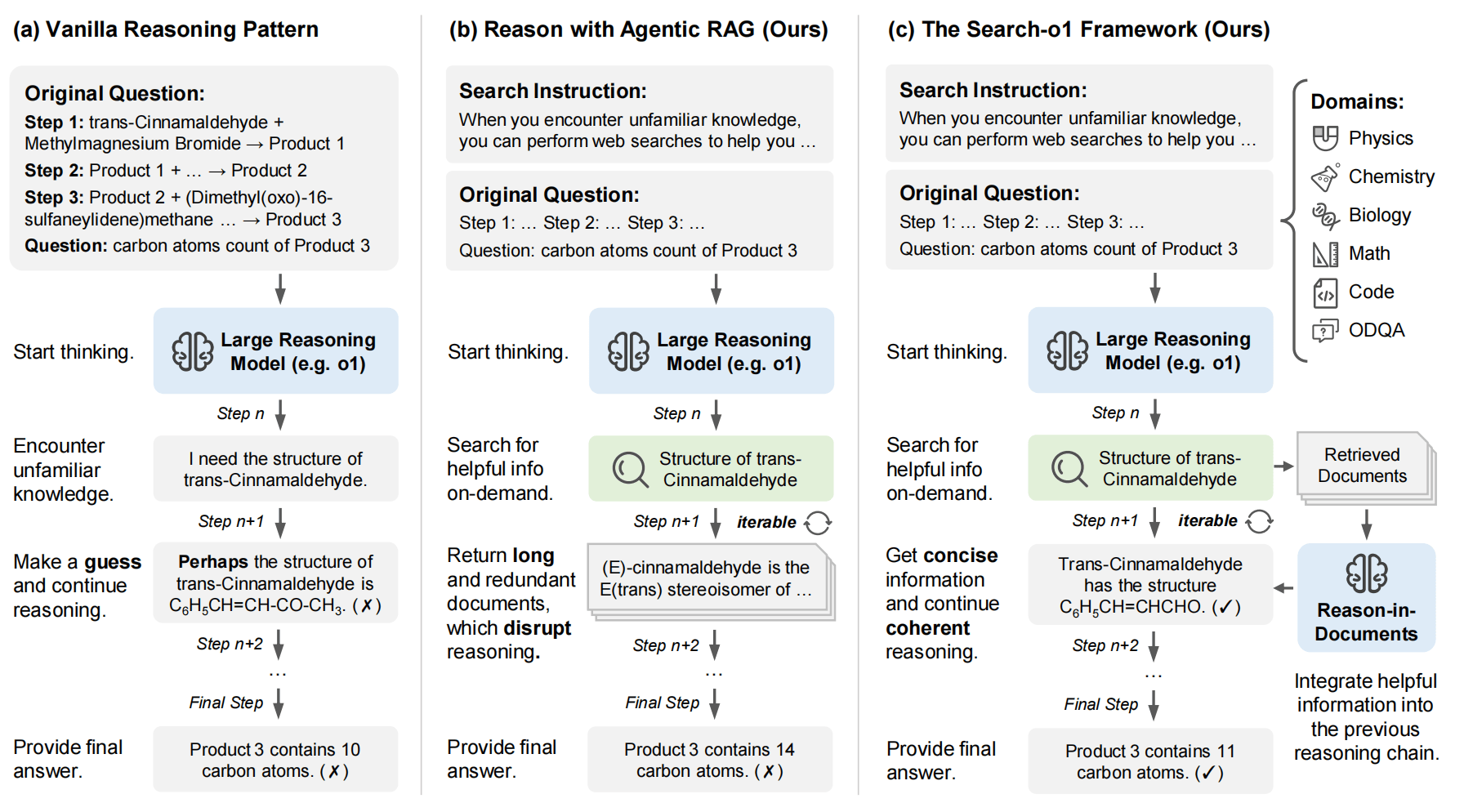
- 当遇到知识不确定的情况时,模型会自动生成搜索查询,格式为
<|begin_search_query|>搜索词<|end_search_query|> - 系统检测到这一标记后,暂停模型推理,执行网络搜索
- 搜索结果被包装在
<|begin_search_result|>检索到的内容<|end_search_result|>标记中返回给模型 - 如果检索到的结果特别长,就用大语言模型对其进行精炼,再放进推理链条中。
优势:
检索触发机制:传统 RAG 是静态的、预先定义的;Search-o1 是动态的、由模型主动触发的,可以在一定程度上实现能力二。
Deep-Searcher
https://github.com/zilliztech/deep-searcher
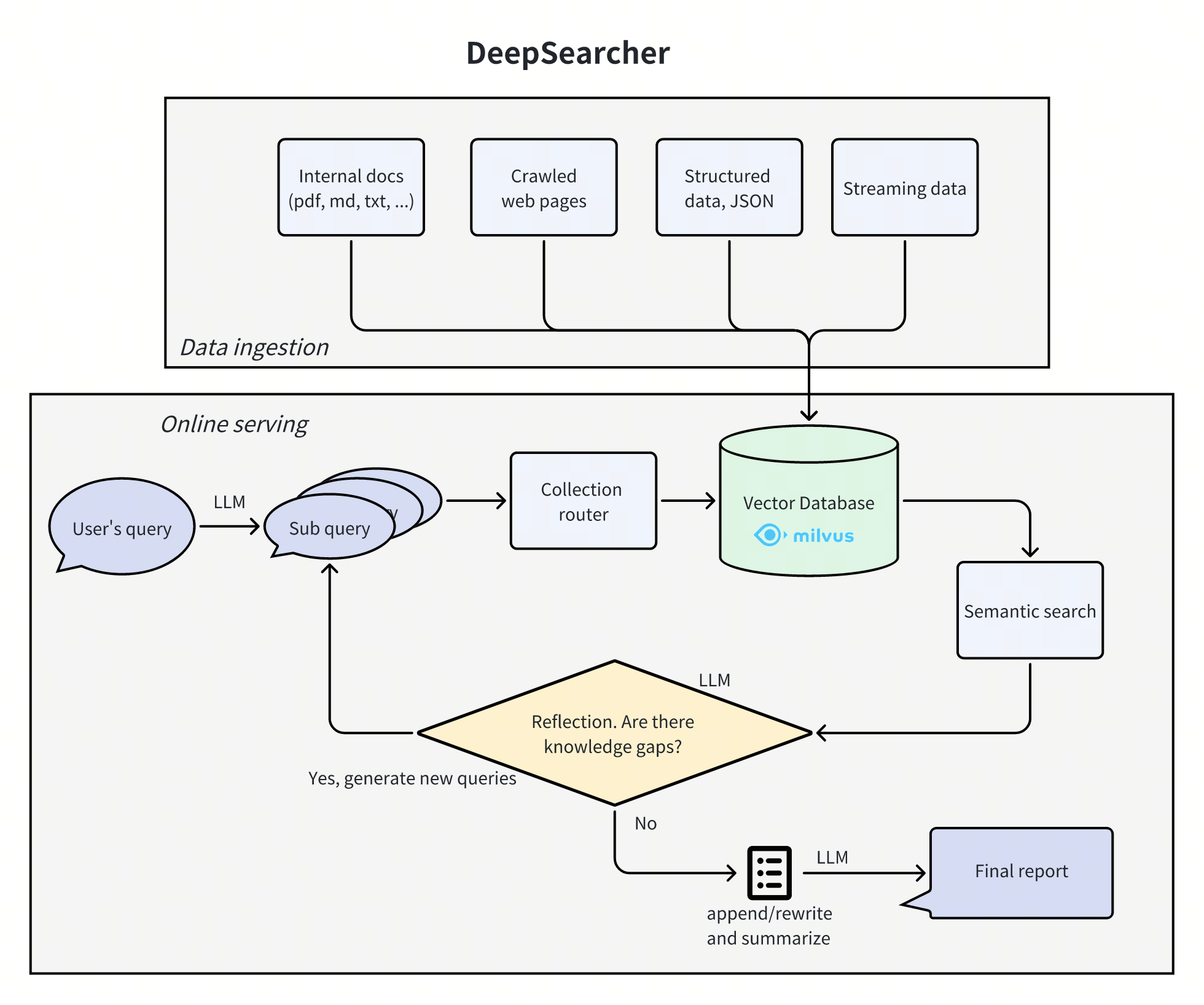
基本流程:
- 将原始问题进行拆解,分成多个子问题。
- 子问题分别进行检索,得到对应的答案。
- 子问题和答案进行整合,由模型生成下一轮子问题。
- 达到指定检索轮数后,汇总最终的答案。
OpenDeepResearcher
https://github.com/mshumer/OpenDeepResearcher
- 用户输入一个研究主题后,LLM会生成最多四个不同的搜索关键词。
- 每个搜索关键词都通过调用SERPAPI接口进行搜索。
- 将所有获取到的链接进行聚合和去重处理。
- 对每个唯一链接调用JINA网页内容解析接口,利用LLM评估网页的有用性,如果页面被判定为有效,则提取相关文本内容。
- 汇总所有信息,判断是否需要进一步生成新的搜索关键词。如果需要,则生成新的查询;否则,循环终止。
- 将所有收集到的上下文信息整合后,由LLM生成一份全面、详尽的报告。
deep-research
https://github.com/dzhng/deep-research
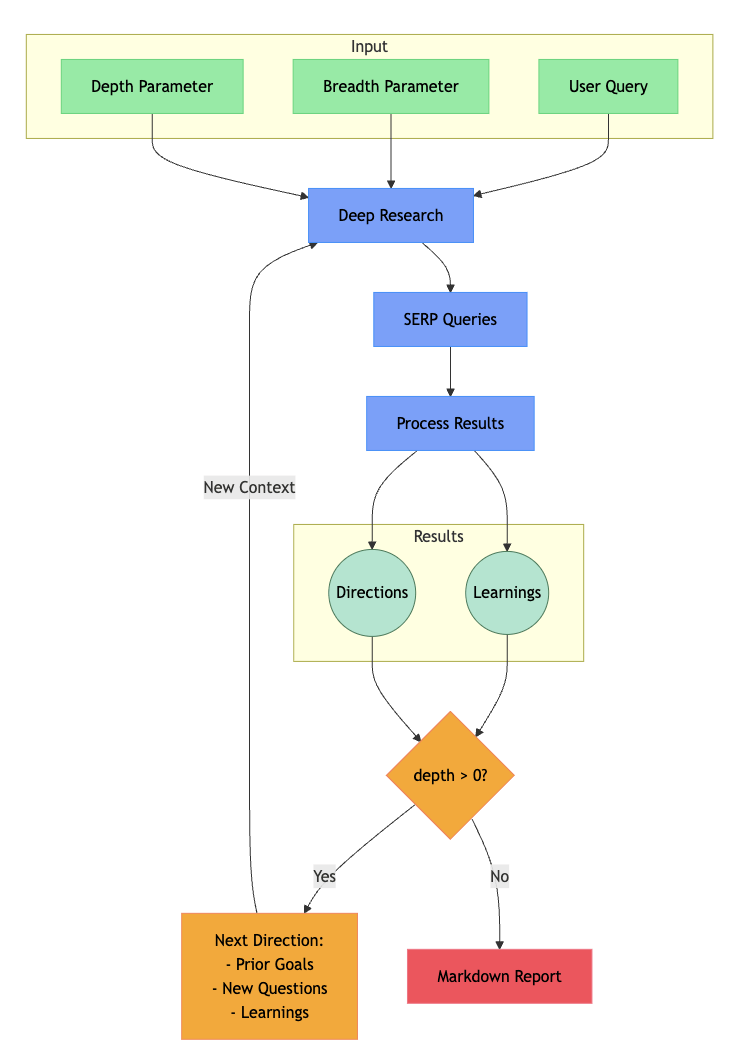
- 获取用户的查询和研究参数(广度与深度)并生成SERP查询。
- 处理搜索结果,提取关键内容用于生成后续研究方向。
- 如果深度 > 0,则根据新的研究方向继续探索。
- 将所有上下文汇总成一份全面的Markdown报告。
强化学习方法:
《DeepRetrieval: Hacking Real Search Engines and Retrievers with Large Language Models via Reinforcement Learning》(能力一)
作者:伊利诺伊大学香槟分校+高丽大学
https://github.com/pat-jj/DeepRetrieval (Star 360)
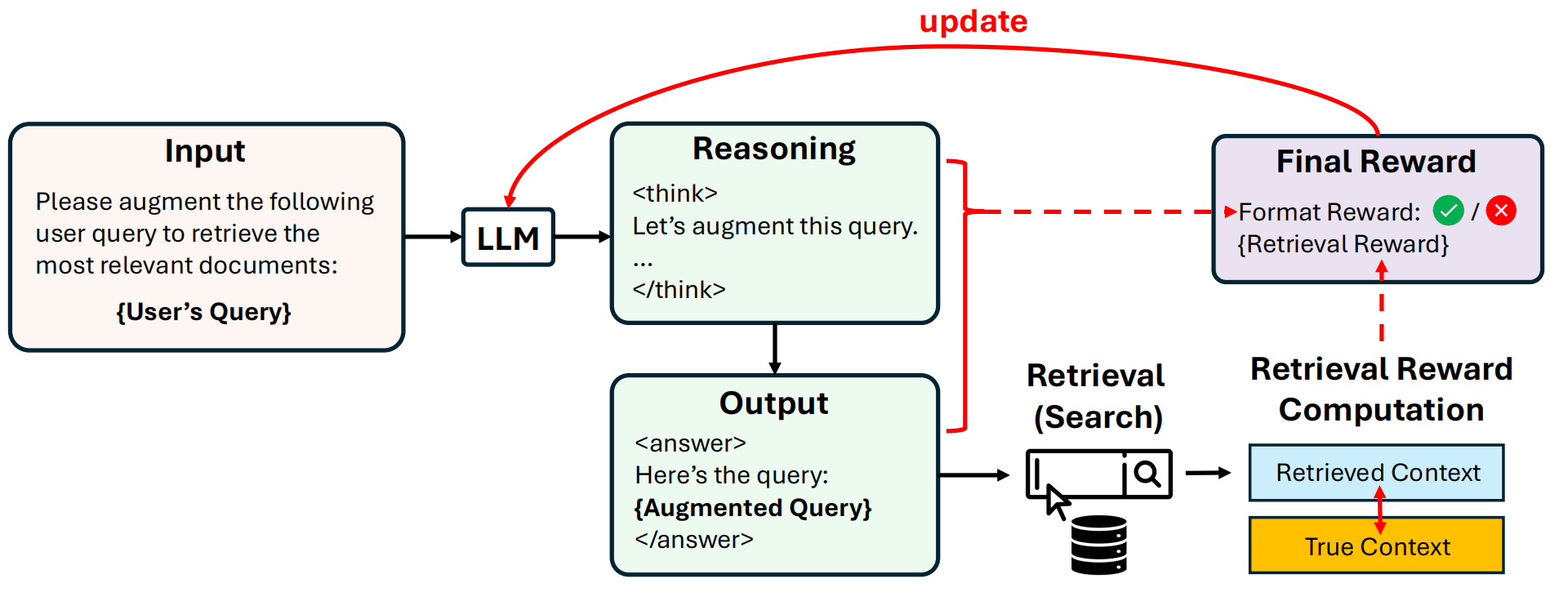
query改写已被证实是检索流程中的关键步骤。当用户提交问题时,大型语言模型(LLM)通常会对其进行重新表述(称为增强查询),然后再执行检索。DeepRetrieval采用创新方法,利用强化学习(RL)而非传统的监督式微调(SFT)来优化这一关键步骤。
DeepRetrieval的突出之处在于它能够通过"试错"方式直接学习,使用检索指标作为奖励,无需昂贵的监督数据。这种方法使模型能够针对实际性能指标进行优化,而不仅仅是模仿人工编写的查询。
训练策略使用 PPO。



数据集:PubMed、ClinicalTrials.gov…公开数据集
《Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning》(能力一、二、三)
伊利诺伊大学香槟分校
https://github.com/PeterGriffinJin/Search-R1
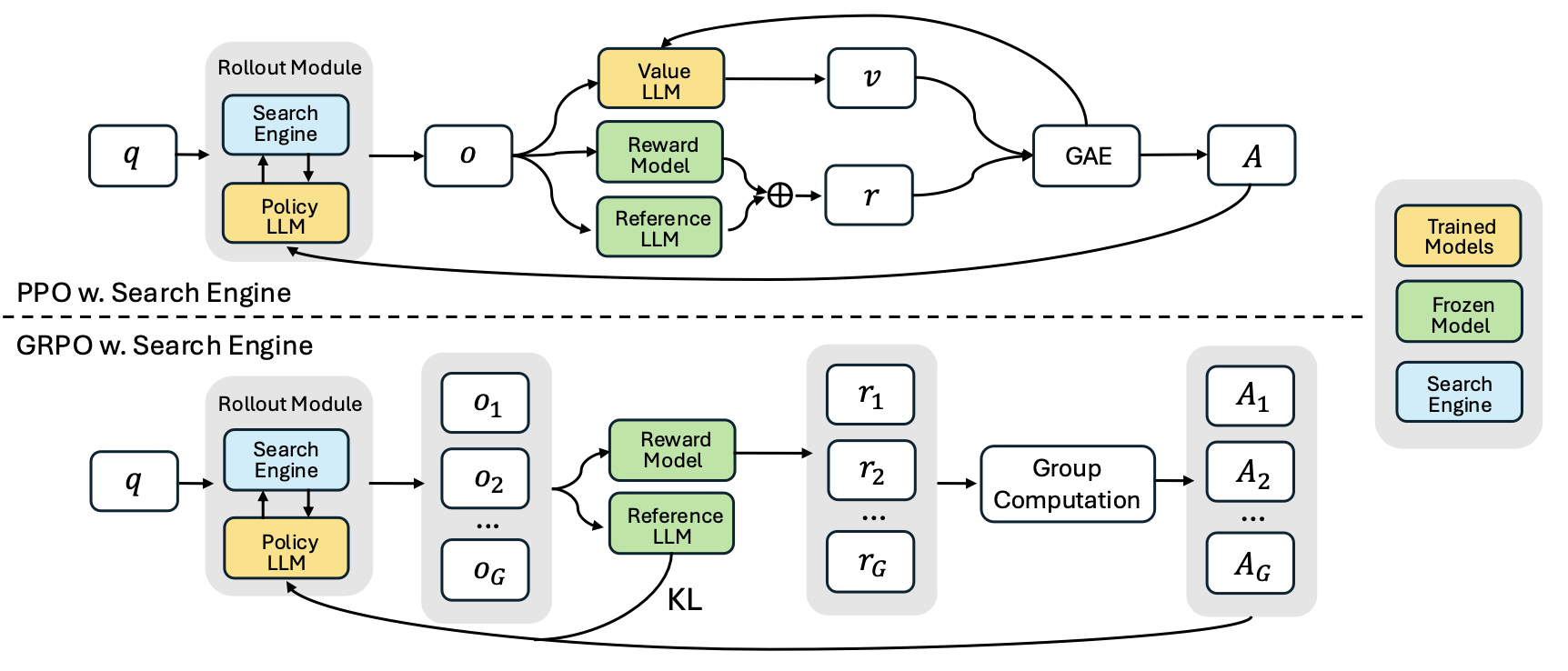
- 将搜索引擎建模为环境的一部分 模型可以在生成中插入
<search>query</search>指令,系统则响应<information>results</information>,最终答案用<answer>标签输出,推理过程包裹在<think>中。 - 支持多轮思考-检索循环 模型可以识别信息缺口并主动发起下一轮搜索,而不是一次性拼接上下文。
- 基于强化学习策略学习 训练采用 PPO (Proximal Policy Optimization)或 GRPO (Group Relative Policy Optimization)算法,奖励信号基于最终结果(如 Exact Match)而非过程监督。
- 避免优化干扰的技术细节 引入 Retrieved Token Loss Masking,对搜索返回内容不反向传播,从而保持训练稳定。
从下图来看,它用 7B 模型就能超越 Search-o1 和 680B 参数的 R1?这种“小模型大能力”的背后,正是 RL 训练出的搜索策略弥补了知识覆盖和参数规模的不足。
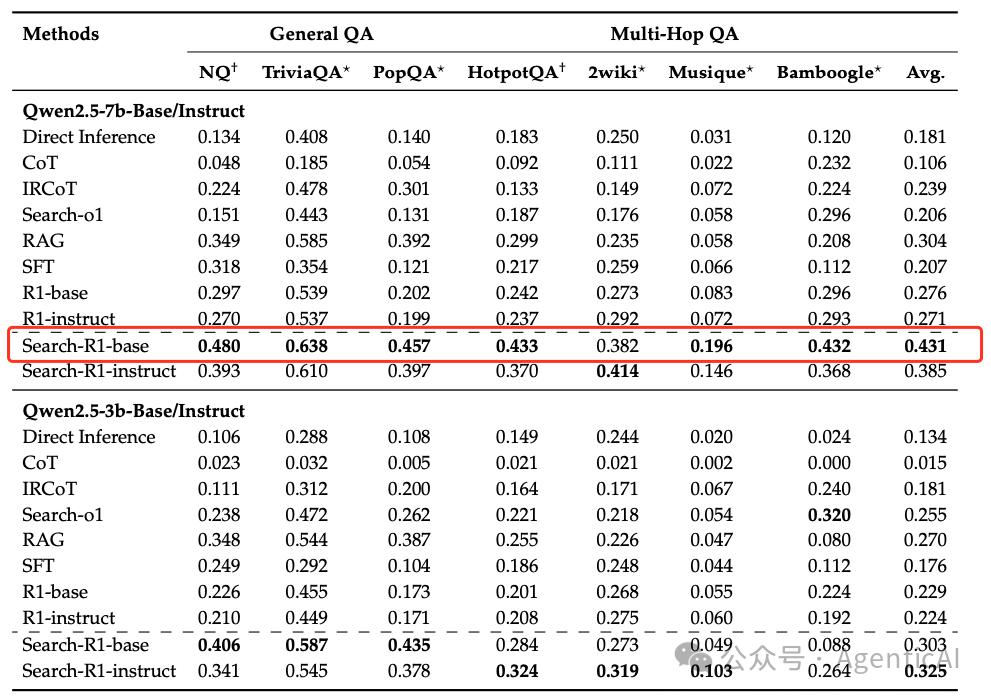
- 数据集:在七个问答数据集上进行评估,包括一般问答(NQ、TriviaQA、PopQA)和多跳问答(HotpotQA、2WikiMultiHopQA、Musique、Bamboogle)。
- 基线比较:与多种方法进行比较,包括无检索的推理、检索增强生成(RAG)、工具调用方法(如IRCoT和Search-o1)、监督微调(SFT)和基于RL的微调(R1)。
- 模型和检索设置:使用Qwen-2.5-3B和Qwen-2.5-7B模型,以2018年维基百科转储作为知识源,E5作为检索器,每次检索返回3个段落。
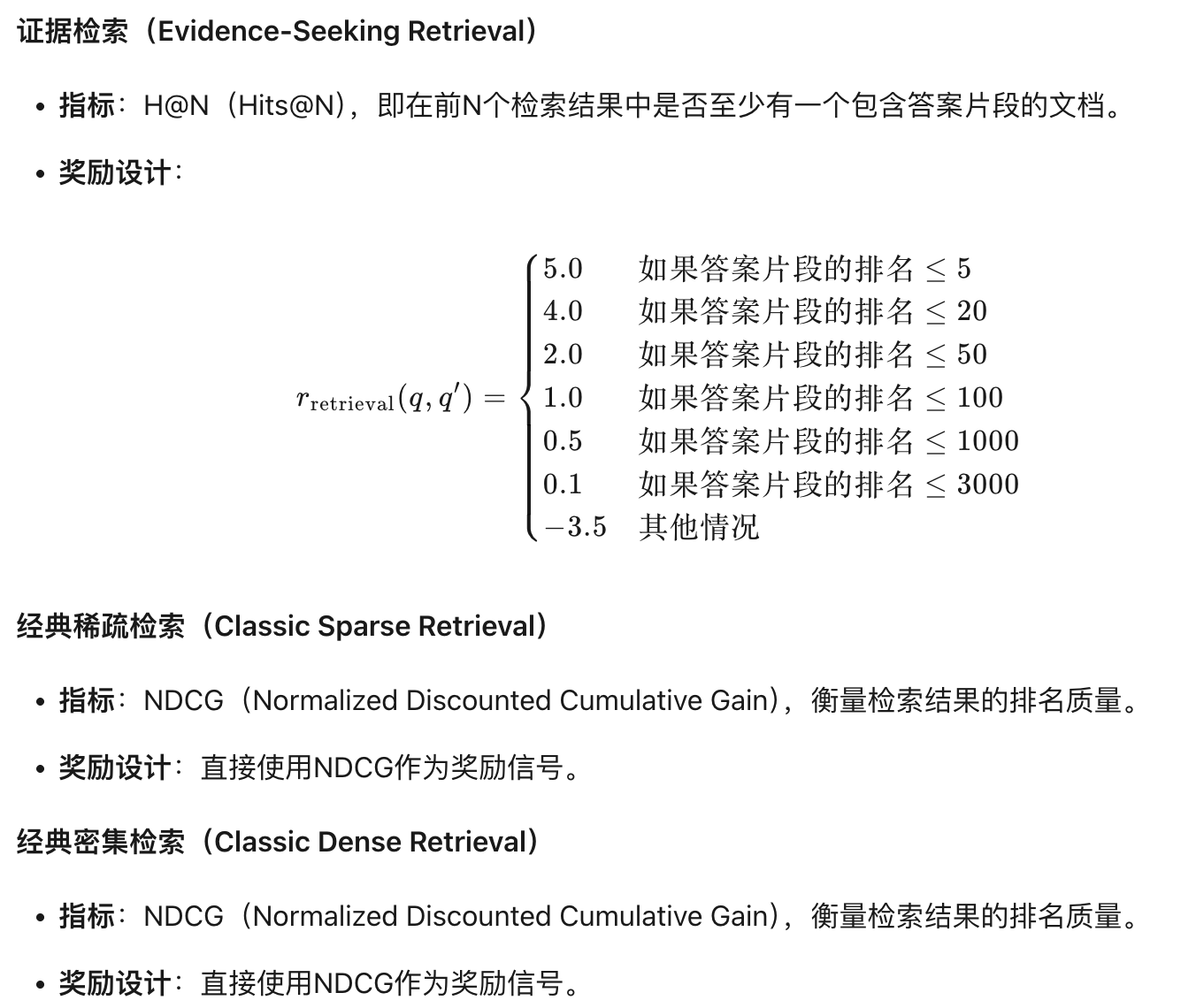
奖励函数:

总结
- 非强化学习方法从技术上来看技术路线都是一样的,即使用推理模型分析,结合联网搜索以及ReAct机制,根据用户输入扩展问题,再对每个问题进行多次联网查找,推理、再查找的过程,最终输出一个综合性的答案。这套方法也比较容易复现。
- 使用强化学习对整体进行进行端到端训练固然可以提升效果,用小模型代替大模型。但缺点也很明显,依赖于高质量的数据,会限制其应用范围,比如无法支持多种模型。
- 使用强化学习对个别流程进行针对性训练的是比较有可行性的,比如针对query生成专门训练。
- 当前的方法主要讨论的都是能力一、二,对能力三较少有针对性优化。