〖 Linux 〗操作系统进程管理精讲(2)
文章目录
- 1、环境变量
- 基本概念
- 常见环境变量
- 查看环境变量方法
- 测试 PATH
- 测试 HOME
- 和环境变量相关的命令
- 环境变量的组织方式<p align="center">
- main 函数的三个参数
- 通过代码获得环境变量
- 通过系统调用获取环境变量
- 环境变量通常是具有全局属性的
- 2、程序地址空间
- 2.1 验证程序地址空间的排布
- 2.2 验证堆和栈增长方向的问题
- 2.3 如何理解 static 变量<p align="center">
- 2.4 感知虚拟地址空间的存在
- 3、进程地址空间
- 分页 & 虚拟地址空间
- 4、Linux2.6 内核进程调度队列 - (理解即可)<p align="center">
- 一个 CPU 拥有一个 runqueue
- 优先级
- 活动队列
- 过期队列
- active 指针和 expired 指针
1、环境变量
我们都清楚自己写的一串代码,经过编译后生成可执行程序,我们用./即可运行,但是系统里有些命令也是64位的可执行程序:

- 既然都是程序,那就可以把你自己的写的程序叫做指令,把系统的指令叫做命令程序 or 二进制文件。所以
自己写的程序和系统中的指令没区别,均可以称为指令、工具、可执行程序。
但是系统里的命令(ls、pwd……)可以直接用,既然你自己写的可执行程序myproc也是命令,那为什么不能像系统中的那样直接使用呢?反而要加上./才能运行。
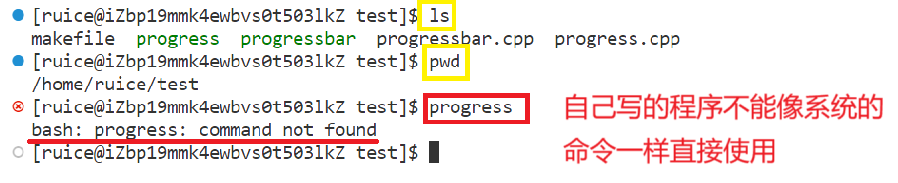
- 注意看这里的报错:command not found,就是说执行一个可执行程序,前提是要先找到它,这也就说明了系统的命令能找到它,自己写的程序却找不到它。
原因:linux系统中存在相关的环境变量,保留了程序的搜索路径的! 所以出现上面的情况。下面就来具体讲解环境变量。
基本概念
环境变量 (environment variables) 一般是指在操作系统中用来指定操作系统运行环境的一些参数。
- 如在编写 C/C++ 代码链接时,虽不知动态静态库位置,但能链接成功生成可执行程序,就是因为有相关环境变量帮助编译器查找。
环境变量通常具有某些特殊用途,且在系统当中通常具有全局特性。
常见环境变量
输入指令env能够查看所有环境变量,常见的环境变量如下:
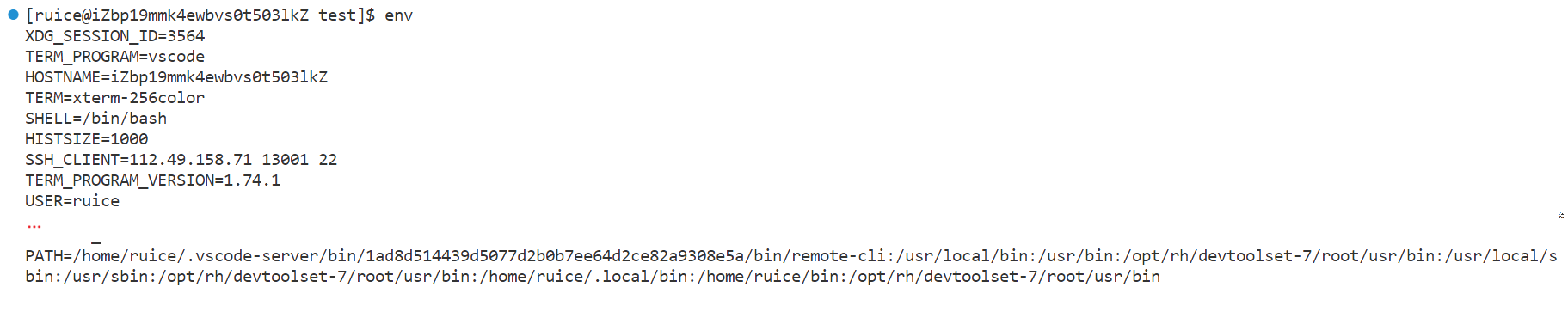
不过常见的如下:
- PATH:系统中搜索可执行程序(命令)的环境变量
- HOME:指定用户的家目录 (即用户登陆到 Linux 系统中时,默认的目录)
- SHELL:当前 Shell, 它的值通常是 /bin/bash。
如下查看系统中的PATH命令:

查看环境变量方法
通过echo命令来查看环境变量,指令格式为:
echo $NAME //NAME:你的环境变量名称
以查看具体的PATH环境变量为例:

注意这里的路径分隔符是用:间隔的,当输入ls指令时,系统会在这些路径里面逐个寻找,找到后就执行特定路径下的ls 。这也就解释了自己写的myproc程序不在此路径中,所以不能直接使用的原因。
测试 PATH
以mypro文件为例,自己写的可执行程序myproc不能像系统的命令一样直接使用,如果想要让myproc像系统中的命令一样使用,有如下两种方法:

根据我们前面的分析得知,我们不能让自己写的可执行程序myproc像系统的命令一样直接使用:
如果要让自己写的myproc像系统中的命令样使用,有如下两种方法:
- 1、手动添加到系统路径/usr/bin/里头
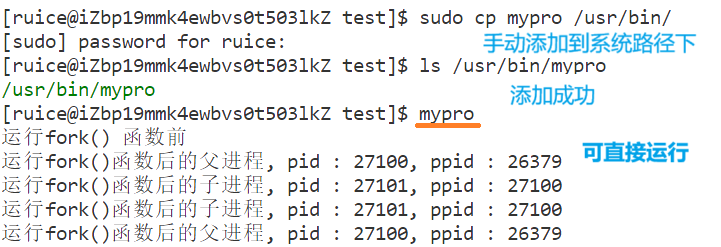
但是并不建议把你自己写的可执行程序随意添加到系统里头(会污染),所以执行下面的命令删除即可:
sudo rm /usr/bin/mypro
2、使用export命令把myproc当前所处的路径也添加到PATH环境变量里,Linux命令行也是可以定义变量的,分为两种:
1.本地变量 (不加export定义的就是本地变量,可以通过set命令查看本地变量,也可以查看环境变量:)
2.环境变量(全局属性,我们使用export可以导出环境变量,使用env显示环境变量:)
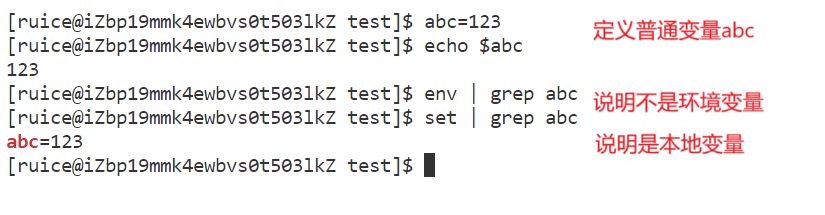
如果我们在变量前面加上export,这就是导出环境变量:

下面演示把myproc的路径导入PATH里头,输入下面的命令:
PATH=$PATH:/home/ruice/test

该命令是把所有的PATH环境变量内容提取出来放到PATH里,并在后面追加mypro的当前路径。添加后就可以像命令一样直接使用myproc,
若想删除该环境变量,执行unset命令。

测试 HOME
任何一个用户在运行系统登录时都有自己的主工作目录(家目录),环境变量HOME保存的就是该用户的主工作目录。
普通用户示例:

root超级用户示例:

和环境变量相关的命令
- 1、echo:显示某个环境变量值
- 2、export:设置一个新的环境变量
- 3、env:显示所有环境变量
- 4、unset:清除环境变量
- 5、set:显示本地定义的 shell 变量和环境变量
环境变量的组织方式
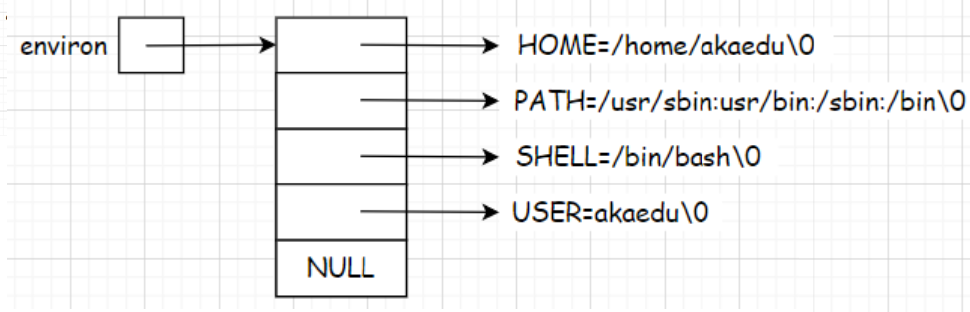
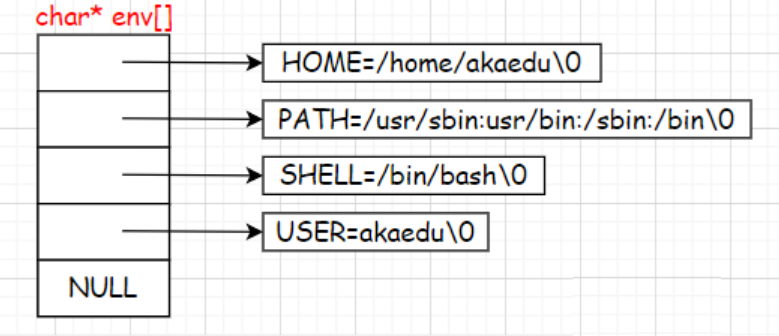
每个程序都会收到一张环境表,环境表是一个字符指针数组,每个指针指向一个以’\0’结尾的环境字符串。
main 函数的三个参数
main函数可以带 3 个参数,其形式为:int main(int argc, char* argv[], char* envp[]) ,其中:
int main(int argc, char* argv[], char* envp[])
{return 0;
}
int argc : 指针数组中元素的个数,代表命令行参数的数量(包含可执行程序名)。
char* argv[]:指针数组
int argc:数组里的元素个数
通过以下代码测试前两个参数:
#include<stdio.h>
#include<unistd.h>int main(int argc, char* argv[])
{for (int i = 0; i < argc; i++){printf("argv[%d]: %s\n", i , argv[i]);}return 0;
}
运行结果如下:
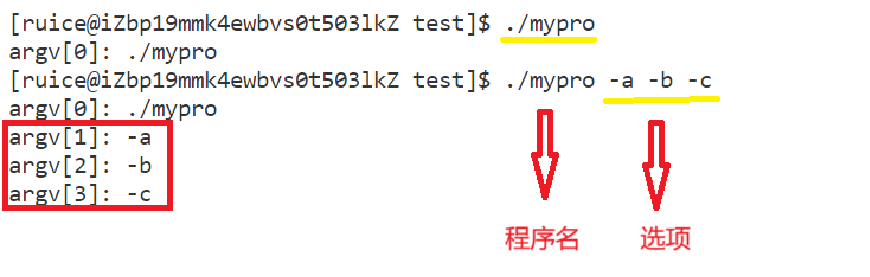
main函数的第二个参数一个字符指针数组,此时argv数组下标 0 存储的是命令行的第一个位置(可执行程序),其余字符指针存储的是命令行对应的选项,main函数的第一个参数argc存储的是数组元素个数。
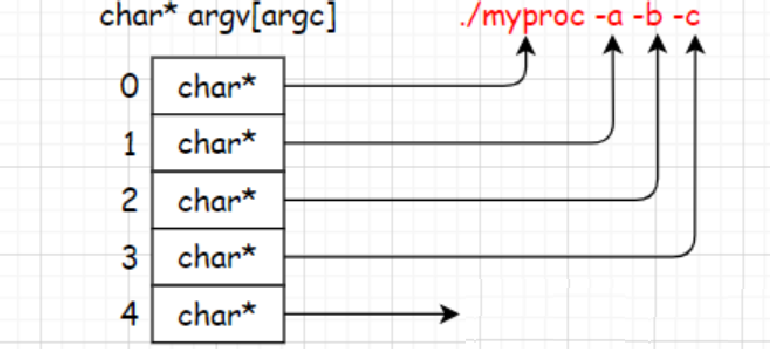
总结:我们给main函数传递的argc,char* argv[ ]是命令行参数,传递的内容是命令行中输入的程序名和选项,并且结尾以NULL结束!!!
问:main函数传这些参数的意义是什么?
假设我们现在要实现一个命令行计算器,如果输出./myproc -a 10 20,那么就是加法10+20=30,如果输出./myproc -s 10 20,那么就是减法10-20=-10……。代码如下
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<stdlib.h>int main(int argc, char* argv[])
{if (argc != 4) {printf("Usage: %s [-a|-s|-m|-d first_num second_num",argv[0]);return 0;}int x = atoi(argv[2]);int y = atoi(argv[3]);if (strcmp("-a", argv[1]) == 0){printf ("%d + %d = %d\n", x, y, x + y);}else if (strcmp("-s", argv[1]) == 0){printf ("%d - %d = %d\n", x, y, x - y);}else if (strcmp("-m", argv[1]) == 0){printf ("%d * %d = %d\n", x, y, x * y);}else if (strcmp("-d", argv[1]) == 0){printf ("%d / %d = %d\n", x, y, x / y);}else {printf("Usage: %s [-a|-s|-m|-d first_num second_num",argv[0]);}return 0;
}
此时我们就可以运行此程序并通过命令行参数来实现我们想要的计算方式:
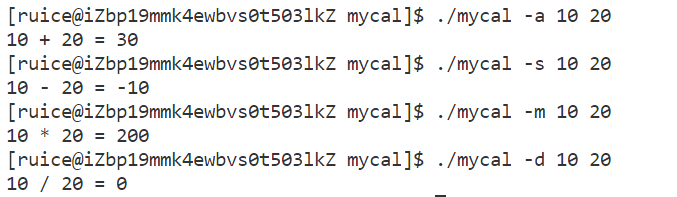
总结:
同一个程序,通过传递不同的参数,让同一个程序有不同的执行逻辑,执行结果。Linux系统中,会根据不同的选项,让不同的命令,可以有不同的表现,这就是指令中各个选项的由来和起作用的方式!!! 这也就是命令行参数的意义,同样也就是main函数参数的意义。
下面来谈下main函数的第三个参数:
int main(int argc, char* argv[], char* envp[])
{return 0;
}
char*envp就是环境变量,也是一个字符指针数组,argv指向命令行参数字符串,envp指向一个一个环境变量字符串,最后以NULL结尾。
通过以下代码测试第三个参数:
int main(int argc, char* argv[], char* env[])
{for (int i = 0; env[i]; i++){printf("env[%d]: %s\n", i, env[i]);}return 0;
}
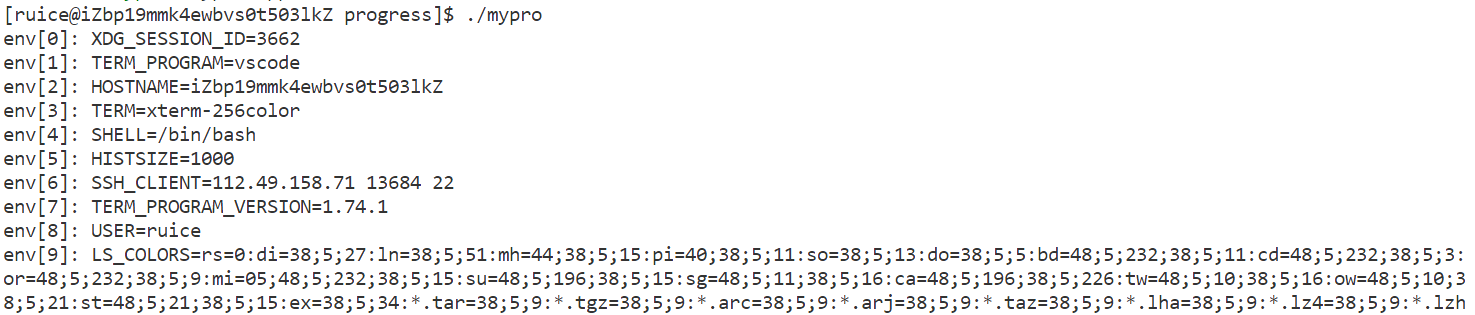
总结:一个进程是会被传入环境变量参数的。
补充:一个函数在声明和定义时无参数,实际传参时也可以传参。
通过代码获得环境变量
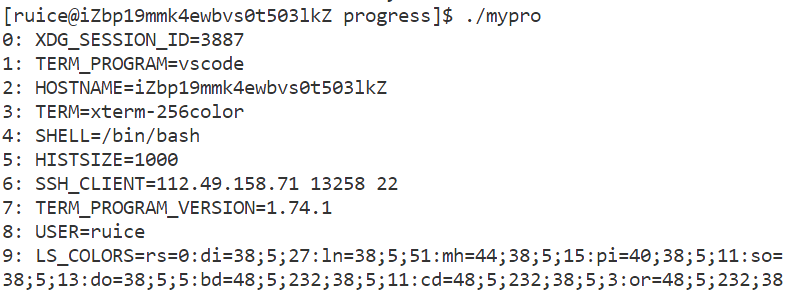
可以通过main函数的第三个参数获得环境变量,也可以通过第三方变量environ获取。
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<stdlib.h>int main()
{extern char** environ;for (int i = 0; environ[i]; i++) {printf("%d: %s\n", i, environ[i]);}return 0;
}
通过系统调用获取环境变量
除了通过main函数的第三个参数和第三方变量environ外,还可通过系统调用getenv函数获取环境变量,getenv能通过目标环境变量名查找,返回对应的字符指针,从而直接获得环境变量内容。
#include <stdio.h>
#include <stdlib.h>
int main()
{char* val = getenv("PATH");printf("%s\n", val);return 0;
}

问:我为什么要获得环境变量?
例如,假设当前用户USER为ruice,只允许自己使用,不允许rc访问,可通过获取环境变量实现访问控制。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{char* id = getenv("USER");if (strcmp(id, "ruice") != 0){printf("权限拒绝!\n");return 0;}printf("成功执行!\n");return 0;
}

综上,环境变量一定在某些地方有特殊用途,上面粗略的展示了其中一个方面。
环境变量通常是具有全局属性的
回顾bash进程:
#include<stdio.h>
#include<unistd.h>
int main()
{while (1){printf("hello Linux!,pid: %d, ppid:%d\n", getpid(), getppid());sleep(1); }return 0;
}
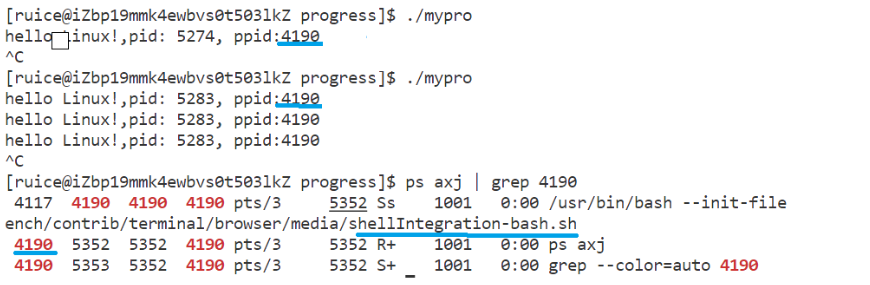
- 子进程pid每次运行结果不断变化(因进程每次运行都在重启),但父进程不变(父进程就是bash,是系统创建的命令行解释器)。
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{while (1){printf("hello Linux!,pid: %d, ppid:%d, myenv=%s\n", getpid(), getppid(),getenv("key"));sleep(1); }return 0;
}
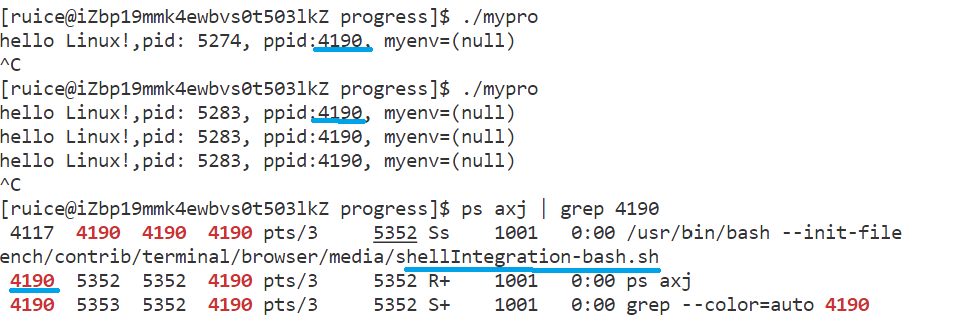
- 如果杀掉bash进程,输入任何命令都无反应,命令行直接挂掉。正常使用命令行是因为命令本身由bash进程获取,且命令行中启动的进程,父进程全都是bash。
下面来理解环境变量具有全局属性:
看如下代码:(在原有的pid和ppid基础上添加了获取环境变量)
通过代码测试发现,进程刚开始不存在环境变量,若在bash进程中导出一个环境变量,子进程运行时就能获取到该环境变量。

总结:
- 环境变量会被子进程继承,若在bash进程中创建export环境变量,该环境变量会从bash位置开始被所有子进程获取,所以环境变量具有全局属性;
- 而本地变量在bash内部定义,不会被子进程继承。
补充:

local_val是本地变量,Linux下大部分命令通过子进程方式执行,但还有部分命令由bash自己执行(调用对应函数完成特定功能),这类命令叫内建命令。
2、程序地址空间
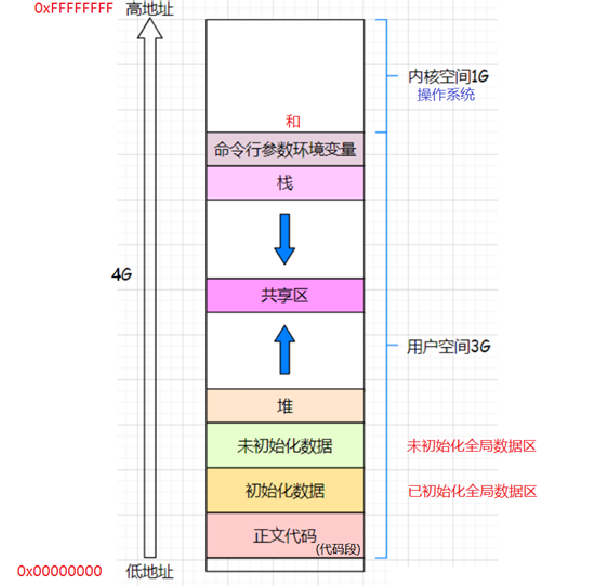
在学习 C 的过程中,常见如下程序地址空间布局图:
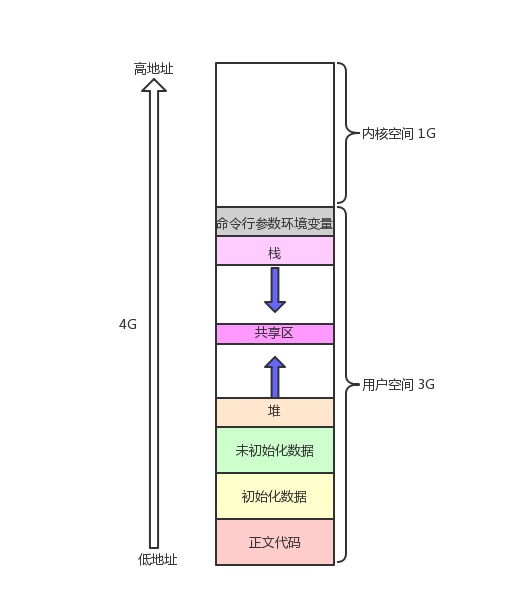
2.1 验证程序地址空间的排布
- 程序地址空间不是内存,通过以下代码在linux操作系统中对该布局进行验证:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int un_g_val;
int g_val = 100;
int main()
{printf("code addr : %p\n", main); //代码区printf("init global addr : %p\n", &g_val);//已初始化全局数据区地址printf("uninit global addr: %p\n", &un_g_val);//未初始化全局数据区地址char* m1 = (char*)malloc(100);printf("heap addr : %p\n", m1);//堆区printf("stack addr : %p\n", &m1);//栈区for(int i = 0; environ[i]; i++){printf("env addr: %p\n", environ[i]);}return 0;
}
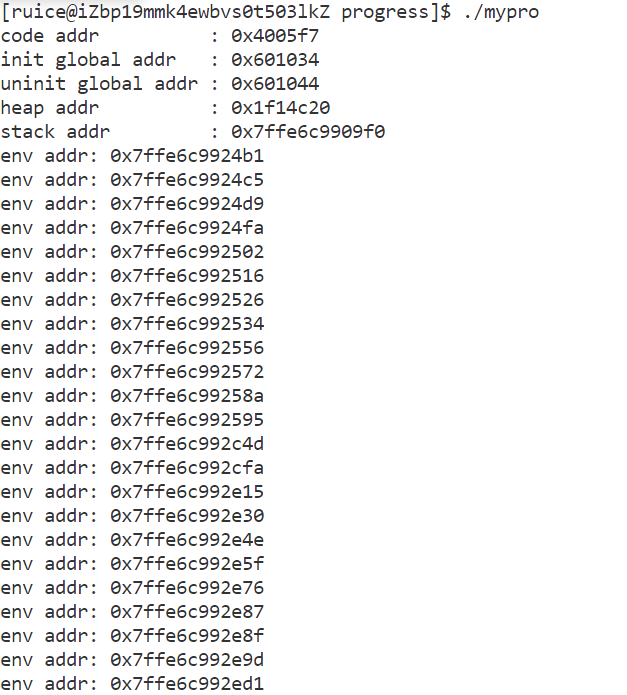
- 运行结果显示,从上到下地址逐渐增大,且栈区和堆区之间有一块非常大的镂空,证实了程序地址空间的布局符合常见布局图。
2.2 验证堆和栈增长方向的问题
堆
通过代码测试,结果表明堆区的确是向上增长。
char* m1 = (char*)malloc(100);char* m2 = (char*)malloc(100);char* m3 = (char*)malloc(100);char* m4 = (char*)malloc(100);printf("heap addr :%p\n", m1);// 堆区printf("heap addr :%p\n", m2);// 堆区printf("heap addr :%p\n", m3);// 堆区

栈
通过代码测试,从结果可以看出栈区向上减少。
char* m1 = (char*)malloc(100);char* m2 = (char*)malloc(100);char* m3 = (char*)malloc(100);char* m4 = (char*)malloc(100);printf("stack addr :%p\n", &m1);//栈区printf("stack addr :%p\n", &m2);//栈区printf("stack addr :%p\n", &m3);//栈区printf("stack addr :%p\n", &m4);//栈区

总结:
- 堆区向地址增大方向增长(箭头向上)
- 栈区向地址减少方向增长(箭头向下)
- 堆,栈相对而生
- 在 C 函数中定义的变量,通常在栈上保存,先定义的变量地址比较高(先定义先入栈,后定义后入栈)。
2.3 如何理解 static 变量
正常定义的变量符合栈的地址分布规则,后定义的变量在地址较低处。而被static修饰的变量,尽管在函数内定义,但已不在栈上,而是变为全局变量,存储在全局数据区,这就是其生命周期会随程序一直存在的原因。


总结:函数内定义的变量被static修饰,本质是编译器会把该变量编译进全局数据区内。
2.4 感知虚拟地址空间的存在
通过父子进程对全局数据操作的代码示例:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/types.h>
int un_g_val;
int g_val = 100;
int main()
{pid_t id = fork();if (id == 0){// childwhile (1){printf("我是子进程:%d, ppid:%d, g_val:%d, &g_val:%p\n\n ",getpid(), getppid(), g_val, &g_val);sleep(1);}}else if (id > 0){// childwhile (1){printf("我是父进程:%d, ppid:%d, g_val:%d, &g_val:%p\n\n ",getpid(), getppid(), g_val, &g_val);sleep(1);}}return 0;
}
当父子进程都未修改全局数据时,共享该数据。

当有一方尝试写入修改时:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/types.h>
int un_g_val;
int g_val = 100;
int main()
{pid_t id = fork();if (id == 0){int flag = 0;// childwhile (1){printf("我是子进程:%d, ppid:%d, g_val:%d, &g_val:%p\n\n ",getpid(), getppid(), g_val, &g_val);sleep(1);flag++;if (flag == 3){g_val = 200;printf("我是子进程,全局数据我已经修改了,用户注意参看!!!\n");}}}else if (id > 0){// childwhile (1){printf("我是父进程:%d, ppid:%d, g_val:%d, &g_val:%p\n\n ",getpid(), getppid(), g_val, &g_val);sleep(1);}}return 0;
}
会出现父子进程读取同一个变量(地址相同),但读取到的内容却不一样的情况。

- 这里父子进程读取同一个变量(因为地址一样),但是后续在没有人修改的情况下,父子进程读取到的内容却不一样!!!怎么会出现子进程和父进程对全局变量的地址是一样的,但是输出的内容确是不一样的呢?
结论:我们在C、C++中使用的地址,绝对不是物理地址。 因为如果是物理地址,上述现象是不可能产生的!!!这种地址我们称之为虚拟地址、线性地址、逻辑地址!!!
补充:为什么我的操作系统不让我直接看到物理内存呢?
- 因为不安全,内存就是一个硬件,不能阻拦你访问!只能被动的进行读取和写入。不能直接访问。
3、进程地址空间
之前所说的‘程序的地址空间’并不准确,准确的说法是进程地址空间。
-
每一个进程在启动时,操作系统会为其创建一个地址空间,即进程地址空间,
每个进程都有属于自己的进程地址空间。操作系统管理这些进程地址空间的方式是先描述,再组织,进程地址空间实际上是内核的一个数据结构(struct mm_struct )。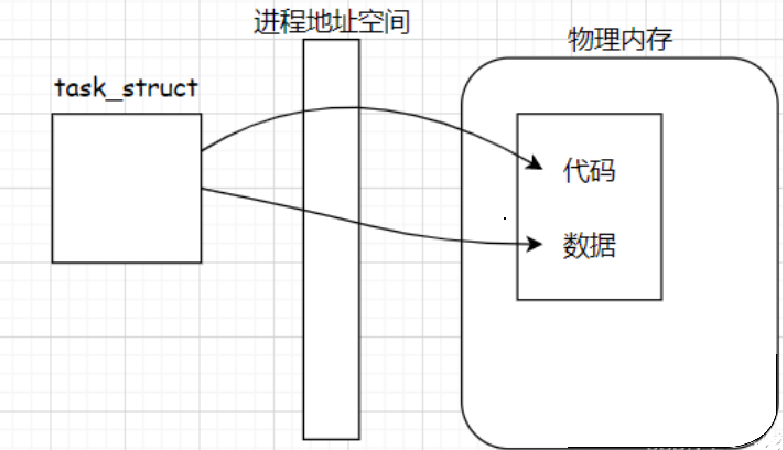
-
进程具有独立性,体现在相关的数据结构独立,进程的代码和数据独立等方面。可以类比为一位图书馆管理员(相当于操作系统)同时管理三个独立的书屋(相当于进程)。每个书屋都有自己的书籍(相当于进程的数据和代码)和管理规则。管理员确保每个书屋独立运营,每个书屋的书籍和其他资源都只供该书屋使用,不会与其他书屋混用。这样可以避免书籍混乱,保证每个书屋的独立性和秩序。
综上:进程地址空间是OS通过软件方式,为进程提供一个软件视角,让进程认为自己会独占系统的所有资源(内存)。
分页 & 虚拟地址空间
在 Linux 内核中,每个进程都有task_struct结构体,该结构体中有个指针指向mm_struct(程序地址空间)。当磁盘上的程序被加载到物理内存时,需要在虚拟地址空间和物理内存之间建立映射关系,这种映射关系由页表(映射表)完成(操作系统会为每个进程构建一个页表结构)。
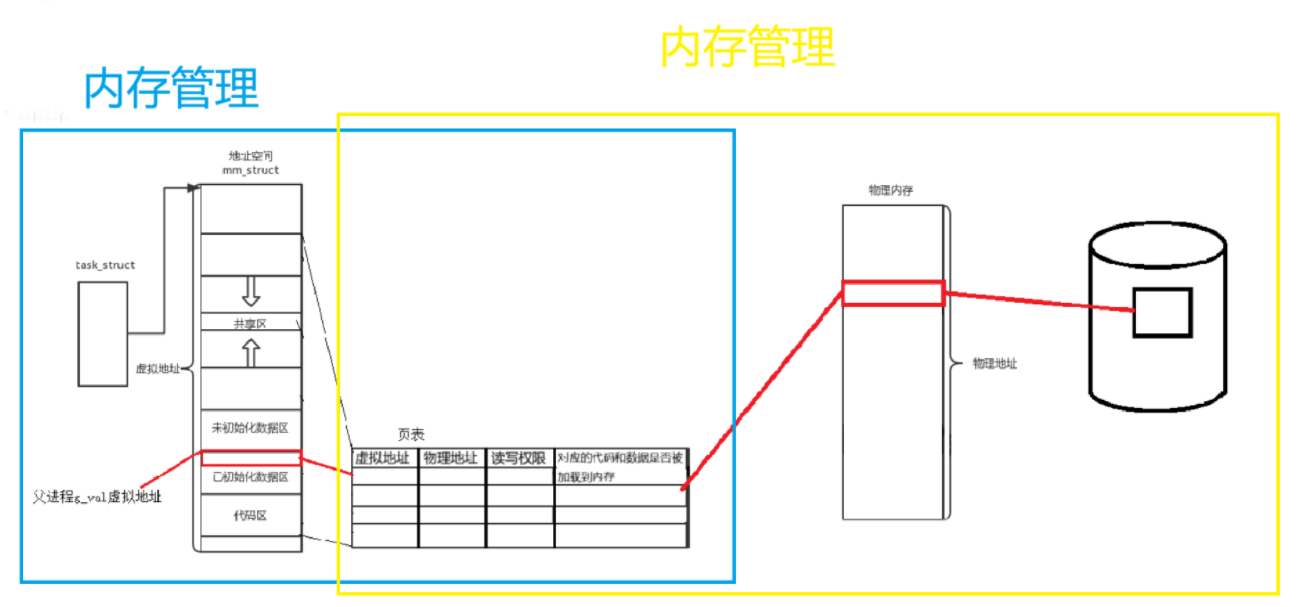
问 1:什么叫做区域(代码区……)?
- 区域类似于桌子上划分的三八线,将空间一分为二,每一半又可进一步细分,比如这块放书,这块放笔盒,这块放水杯等。mm_struct结构体也是按照类似方式进行区域划分和限制的,如下代码所示:
struct mm_struct
{long code_start;long code_end;long init_start;long init_end;long uninit_start;long uninit_end;//……
}
问 2:程序是如何变成进程的?
- 程序编译后未加载时,程序内部有地址和区域,此时地址采用相对地址形式,区域在磁盘上已划分好。程序加载就是按区域将其加载到内存的过程。
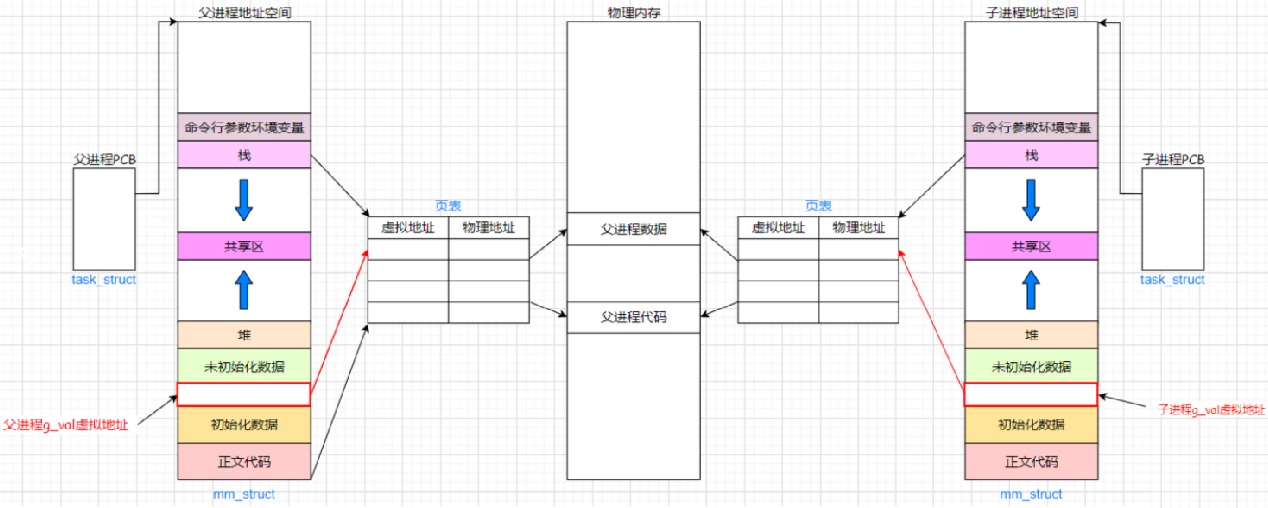
问 3:为什么先前修改一个进程时,地址是一样的,但是父子进程访问的内容却是不一样的?
-
父进程创建时,有自己的task_struct和地址空间mm_struct,地址空间通过页表映射到物理内存。使用fork创建子进程时,子进程也有自己的task_struct、地址空间mm_struct和页表 。如下:
-
子进程刚创建时,和父进程的数据、代码是共享的,即父子进程的代码和数据通过页表映射到物理内存的同一块空间,所以此时打印g_val的值和内容是一样的。
-
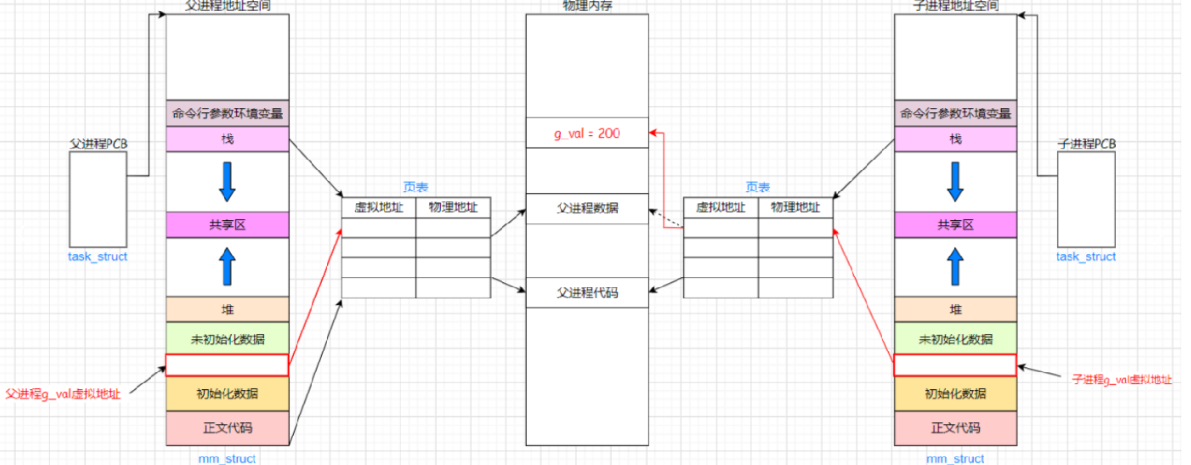
当子进程需要修改数据g_val时,结果就变了,如下图:
-
无论父进程还是子进程,因为进程具有独立性,如果子进程把变量g_val修改了,那么就会导致父进程识别此变量的时候出现问题,但是独立性的要求是互不影响,所以此时操作系统会给你子进程重新开辟一块空间,把先前g_val的值100 拷贝下来,重新给此进程建立映射关系,所以子进程的页表就不再指向父进程的数据100了,而是指向新的100,此时把100修改为200,无论怎么修改,变动的永远都是右侧,左侧页表间的关系不变, 所以最终读到的结果为子进程是200,父进程是100.
-
总结:当父子进程中有一方修改数据时,操作系统会为修改方重新开辟空间,拷贝原始数据到新空间,这种行为称为写时拷贝。通过页表,利用写时拷贝实现父子进程数据的分离,保证父子进程的独立性。
问 4:fork 有两个返回值,pid_t id,同一个变量,怎么会有不同的值?
- 一般情况下,pid_t id是父进程栈空间中定义的变量,fork内部return会被执行两次,return本质是通过寄存器将返回值写入接收返回值的变量。 当执行id = fork()时,先返回的一方会发生写时拷贝,所以同一个变量虚拟地址相同,但物理地址不同,从而有不同的内容值。
问 5:为什么要有虚拟地址空间?
- 保护内存:假设存在非法访问野指针(*p = 110),若该野指针指向其他进程甚至操作系统,直接访问物理内存会修改其他进程数据,存在安全风险。而有了虚拟地址空间,当遇到野指针时,页表不会建立映射关系,无法访问物理内存,相当于在内存访问时增加了一层软硬件审核机制,可拦截非法请求。
- 解耦功能模块:可以将 Linux 内存管理和进程管理通过地址空间进行功能模块的解耦。
- 统一视角与简化实现:让进程或程序以统一视角看待内存,便于以统一方式编译和加载所有可执行程序,简化进程本身的设计与实现。
4、Linux2.6 内核进程调度队列 - (理解即可)
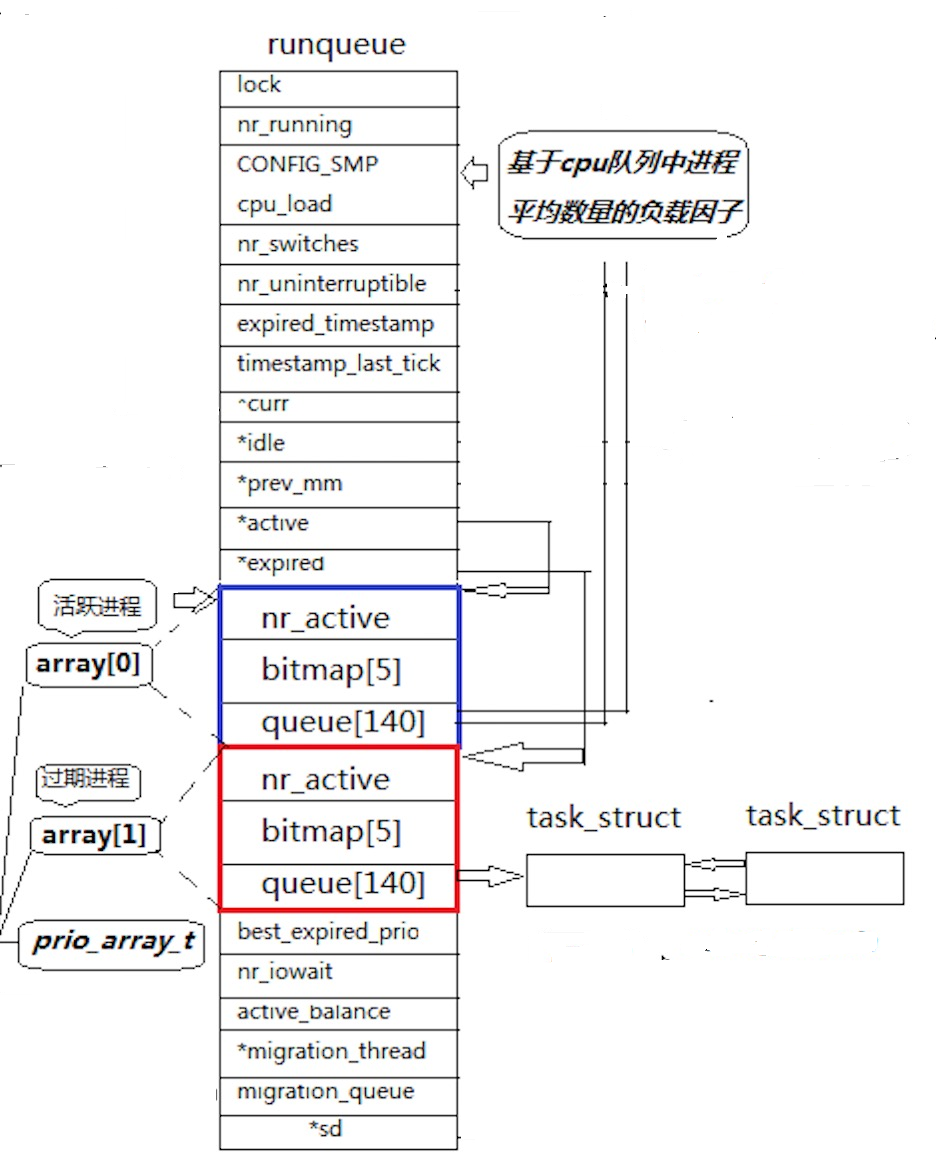
一个 CPU 拥有一个 runqueue
若存在多个 CPU,就需要考虑进程个数的负载均衡问题。
优先级
- 普通优先级:100~139(与nice值取值范围对应)
- 实时优先级:0~99(不重点关注)
活动队列
时间片还没有结束的所有进程都按照优先级放在该队列。 nr_active:表示总共有多少个运行状态的进程。
queue[140]:一个元素就是一个进程队列,相同优先级的进程按照 FIFO(先进先出)规则进行排队调度,数组下标即优先级。从该结构中选择一个最合适的进程的过程如下:
- 1、从 0 下标开始遍历queue[140]
- 2、找到第一个非空队列(该队列优先级最高)
- 3、拿到选中队列的第一个进程开始运行,完成调度。
- 4、遍历queue[140]的时间复杂度是常数,但效率仍较低。
为提高查找非空队列的效率,使用bitmap[5],用 5*32 个比特位表示队列是否为空,可大大提升查找效率。
过期队列
- 过期队列和活动队列结构一模一样,放置的是时间片耗尽的进程。
- 当活动队列上的进程都被处理完毕后,会对过期队列的进程重新计算时间片。
active 指针和 expired 指针
- active指针永远指向活动队列。
- expired指针永远指向过期队列。
- 随着进程运行,活动队列上的进程会越来越少,过期队列上的进程会越来越多。
- 在合适的时候,交换active指针和expired指针的内容,就相当于获得了一批新的活动进程。
总结
在系统中查找一个最合适调度的进程的时间复杂度是常数,不会随着进程数量增多而增加时间成本,这种进程调度方式称为进程调度 O (1)算法。