MySql集群架构
目录
一、主从模式
1、半同步复制
2、并行复制
二、分片集群
1、垂直切分
2、水平切分
2.1 分区
2.2 应用分表
2.3 代理分表
3、分片
3.1 分片键
3.2 分片模式
3.3 分片策略
4、部署架构
三、架构设计
1、读写分离
2、双主模式
四、参考
一、主从模式
数据可以从一个 MySQL 数据库服务器主节点复制到一个或多个从节点,默认采用异步复制方式,这样从节点不用一直访问主服务器来更新自己的数据,从节点可以复制主数据库中的所有数据库,或者特定的数据库,或者特定的表。
主从复制用途
1) 实时灾备,用于故障切换(高可用)
2) 读写分离,提供查询服务(读扩展)
3) 数据备份,避免影响业务(高可用)
主从部署必要条件
1) 主从相连
2) 主库开启 binlog 日志(设置 log-bin 参数)
3) 主从 server-id 不同
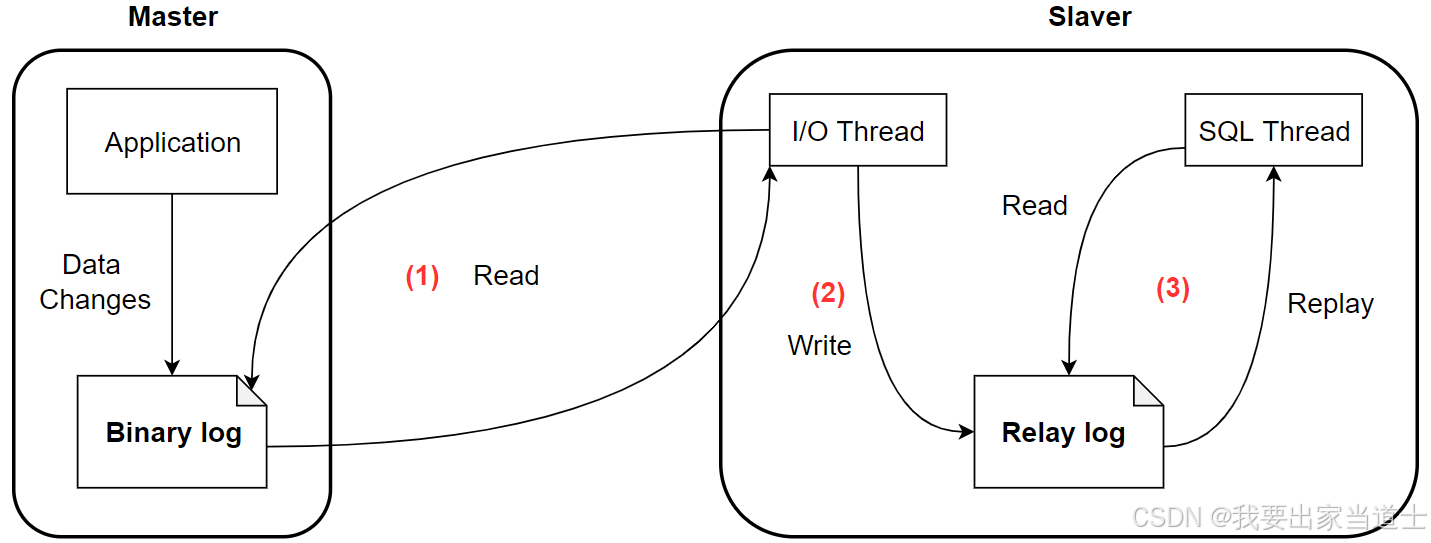
数据同步流程
1) Master 服务器对数据库更改操作记录在 Binlog 中,BinlogDump Thread 接到写入请求后,读取 Binlog 信息推送给 Slaver 的 I/O Thread;
2) Slaver 的 I/O Thread 将读取到的 Binlog 信息写入到本地 Relay Log 中;
3) Slaver 的 SQL Thread 检测到 Relay Log 的变更请求,解析 relay log 中内容在从库上执行;
存在的问题
1) 主库宕机后,数据可能丢失
2) 从库只有一个 SQL Thread,主库负载较大的场景下,数据同步很可能延时
1、半同步复制
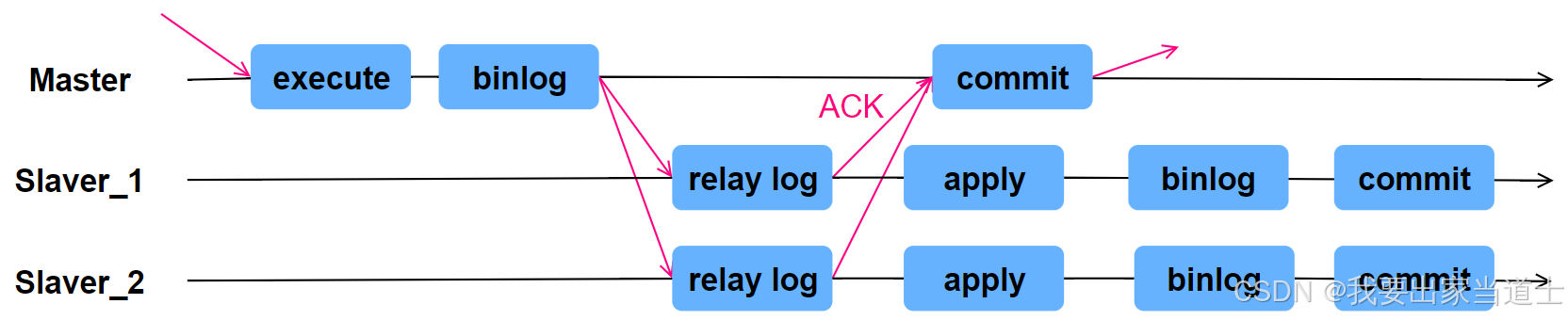
从 5.5 开始,MySQL 让 Master 在某一个时间点等待 Slaver 节点的 ACK 消息,接收到 ACK 消息后才进行事务提交,这就是半同步复制。
当 Master 不需要关注 Slaver 是否接受到 Binlog Event 时,即为传统的主从复制。
当 Master 需要在第三步等待 Slaver 返回 ACK 时,即为 after-commit,半同步复制(MySQL 5.5引入)。
当 Master 需要在第二步等待 Slaver 返回 ACK 时,即为 after-sync,增强半同步(MySQL 5.7引入)。
2、并行复制
MySQL 从 5.6 版本开始追加了并行复制功能,改善复制延迟。
5.6 版本并行复制
基于库的并行复制,也就是多线程分别执行各自库的操作,互不干扰,但是对于单库多表并发效率就不高了。
5.7 版本并行复制
基于组提交的并行复制,不再有库的并行复制限制。当事务提交时,通过在主库上的二进制日志中添加组提交信息,并将在单个操作中写入到二进制日志中。如果多个事务能同时提交成功,那么它们意味着没有冲突,因此可以在Slave上并行执行。MySQL 5.7 的并行复制基于一个前提,即所有已经处于 prepare 阶段的事务,都是可以并行提交的。(一组互相不冲突的事务,可以在 Slaver 并行执行)
InnoDB 事务提交采用的是两阶段提交模式。一个阶段是 prepare,另一个是 commit。
在 MySQL 5.7 版本中,其设计方式是将组提交的信息存放在 GTID 中。为了避免用户没有开启 GTID 功能,MySQL 5.7 又引入了称之为 Anonymous_GTID 的二进制日志event类型,即日志中具有相同的 last_committed,表示这些事务都在一组内。
8.0 并行复制
基于 write-set 的并行复制。有一个集合变量来存储事务修改的记录信息(主键哈希值),所有已经提交的事务所修改的主键值经过 hash 后都会与集合变量进行对比,来判断该行是否与其冲突,并以此来确定依赖关系,没有冲突即可并行,row 级别的粒度,类似于之前的表锁行锁差异,效率肯定更高。
二、分片集群
1、垂直切分
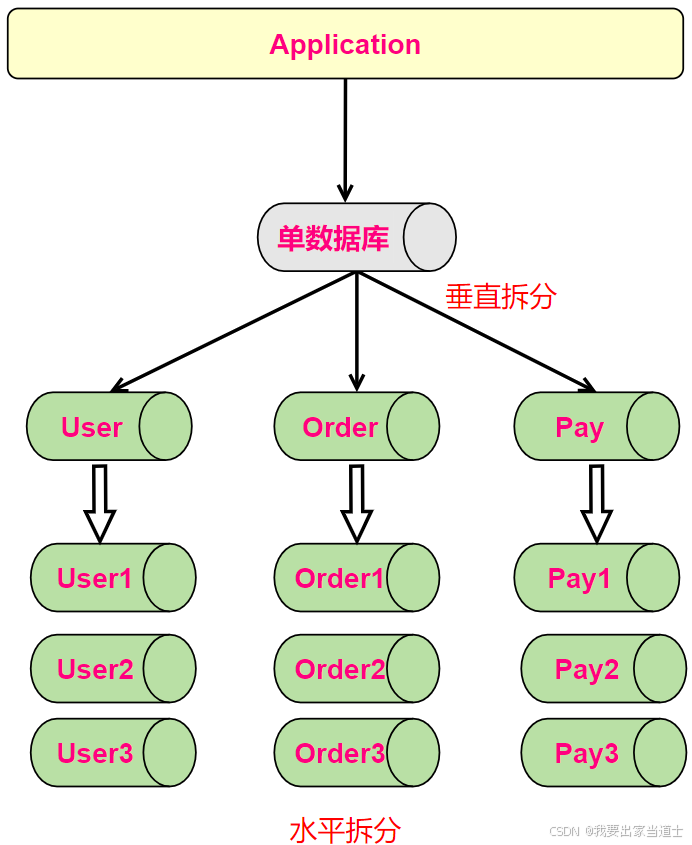
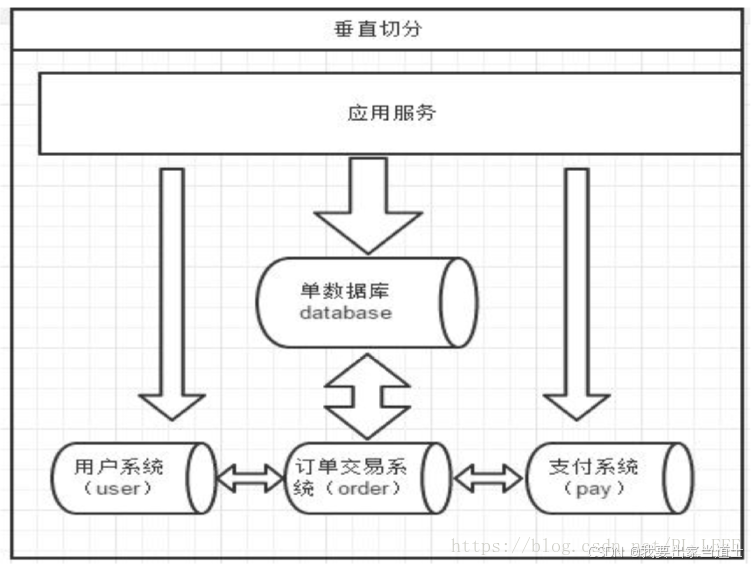
垂直切分是按照业务对数据表分类,然后把一个数据库拆分成多个独立的数据库(按照业务拆分)。
从上到下,将一个数据库拆分成多个数据库。也就是拆分成多个小系统。
垂直切分可以把数据库的并发压力,分散到不同的数据库节点。垂直切分并不能减少单表数据量。
2、水平切分
水平切分是按照某个字段的某种规则,把数据切分到多张数据表。提高并发性能。
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中。

拆分数据就需要定义分片规则。关系型数据库是行列的二维模型,拆分的第一原则是找到拆分维度。比如: 从会员的角度来分析,商户订单交易类系统中查询会员某天某月某个订单,那么就需要按照会员结合日期来拆分,不同的数据按照会员 ID 做分组,这样所有的数据查询 join 都会在单库内解决;如果从商户的角度来讲,要查询某个商家某天所有的订单数,就需要按照商户 ID 做拆分;但是如果系统既想按会员拆分,又想按商家数据,则会有一定的困难。如何找到合适的分片规则需要综合考虑衡量。
几种典型的分片规则包括:
按照用户ID求模,将数据分散到不同的数据库,具有相同数据用户的数据都被分散到一个库中;
按照日期,将不同月甚至日的数据分散到不同的库中;
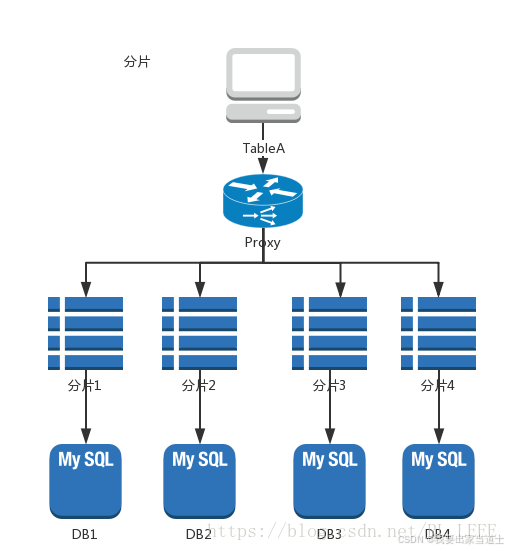
按照某个特定的字段求摸,或者根据特定范围段分散到不同的库中。 如图,切分原则都是根据业务找到适合的切分规则分散到不同的库,下面用用户ID求模举例:
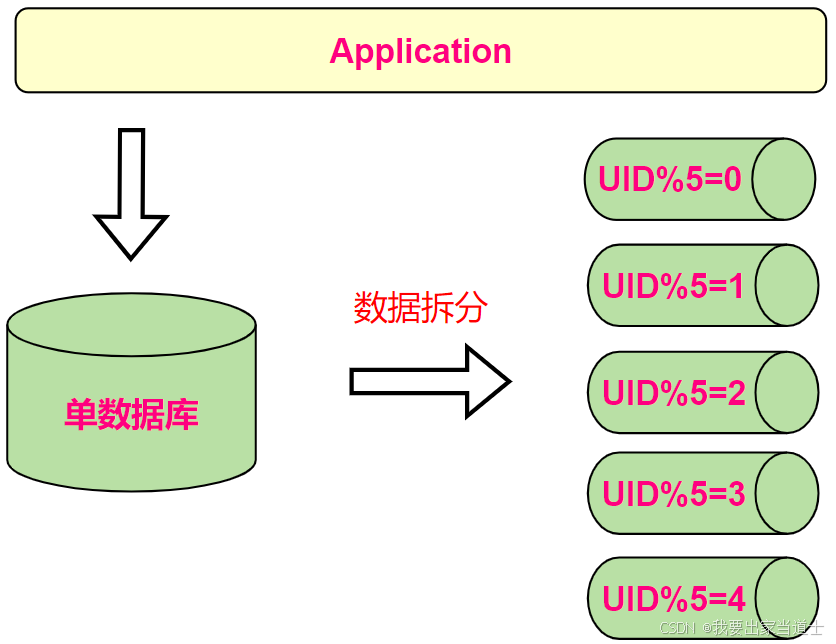
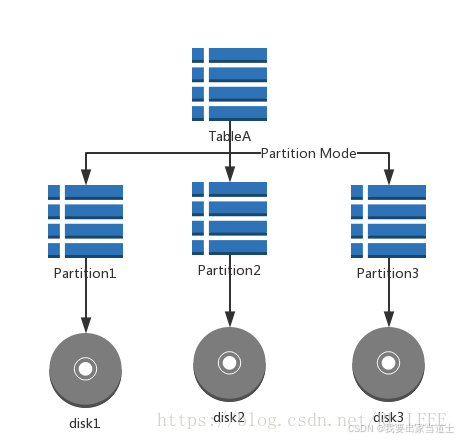
2.1 分区
局限于单一数据库节点,将一张表分散存储在不同的物理块中。MySQL5以后支持分区,但是不支持二级分区,并且单机MySQL的性能远远不如Oracle,所以分区并不能解决性能问题。
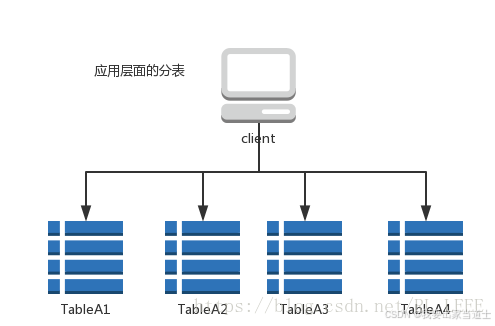
2.2 应用分表
应用层面的分表,人工把一张逻辑上完整的表分成若干个小表。比如T_PAYMENT表分为T_PAYMENT_0101…T_PAYMENT_1231。对代码不透明。
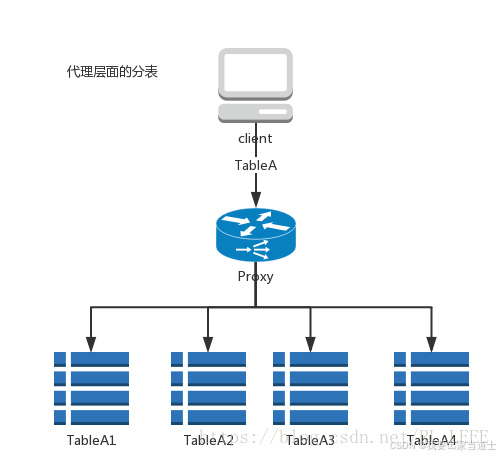
2.3 代理分表
代理层面的分表,通过MERGE引擎或者代理中间件把表分成若干的字表,对应用只保留一个“表壳”,对代码透明。
3、分片
分片就是分库+分表,属于水平切分,将表中数据按照某种规则放到多个库中,既分表又分库,就相当于原先一个库中的一个表,现在放到了好多个表里面,然后这好多个表又分散到了好多个库中。分片和分区也不冲突。
3.1 分片键
数据分片是将一张分布式表按照指定的分片键( Partition Key )和分片模式( Partition Mode )水平拆分成多个数据片,分散在多个数据存储节点中。对于分片的表,要选取一个分片键。一张分布式表只能有一个分片键,分片键是用于划分和定位表的列,不能修改。
3.2 分片模式
分片方式类似于分区方式,可以选择枚举,范围 Range 或者散列哈希。
枚举:{1 => Cluster A, 2 => Cluster B}
范围:{[1 - 100] => Cluster A, [101 - 199] => Cluster B}
散列哈希:{1024n + 1 => Cluster A, 1024n + 2 => Cluster B}
3.3 分片策略
在做分片的时候,选择合适的分片规则非常重要,将极大地避免后续数据的处理难度,有以下几点需要关注:
(1)能不分就不分,对于1000万以内的表,不建议分片,通过合适的索引,读写分离等方式,可以更好地解决性能问题。
(2)分片数量不是越多越好,数据尽量均匀分布在多个存储节点上,只在必要的时候进行扩容,增加分片数量。
(3)分片键不能为空,不能修改,所以要选择表中中最常用且不变的字段。
(4)分片键选择时尽量做到可以将事务控制在分片范围内,避免出现事务跨分片的操作。
(5)选择分片规则时,要充分考虑数据的增长模式,数据的访问模式,分片关联性问题,以及分片扩容问题。
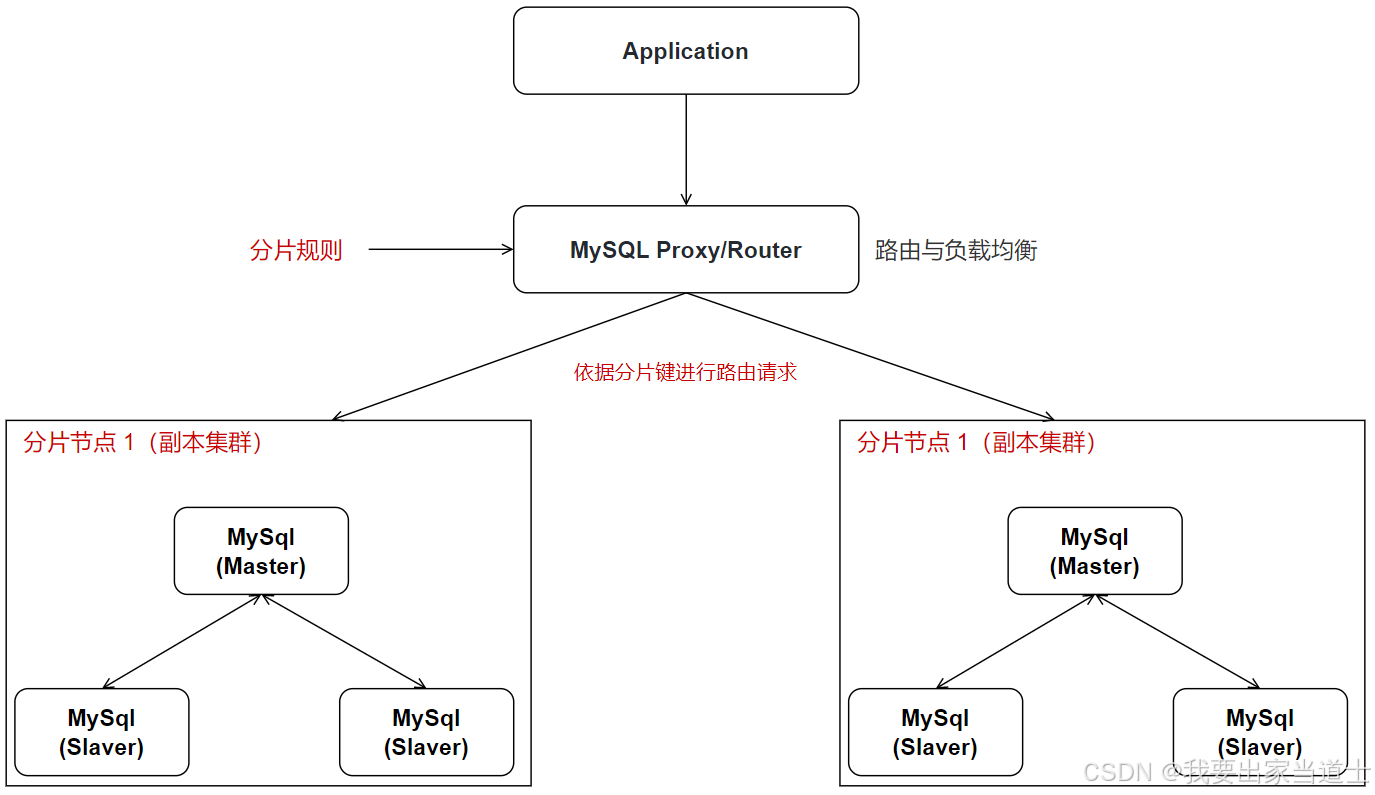
4、部署架构
主要由两部分组成:MySql Proxy/Router 和 分片节点。
其中 MySQL Proxy 部署在分片节点和应用程序之间,实现请求的路由和负载均衡。在MySQL Proxy或MySQL Router上设置分片规则,根据分片键将请求路由到对应的MySQL节点上,以确保数据的正确性和一致性。
分片节点为主从架构,保证数据的可靠性。
三、架构设计
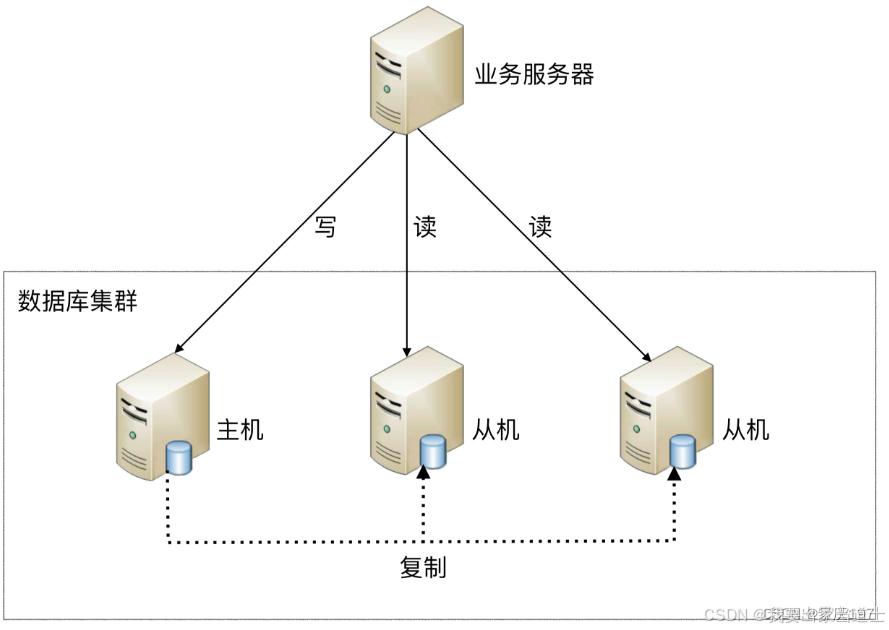
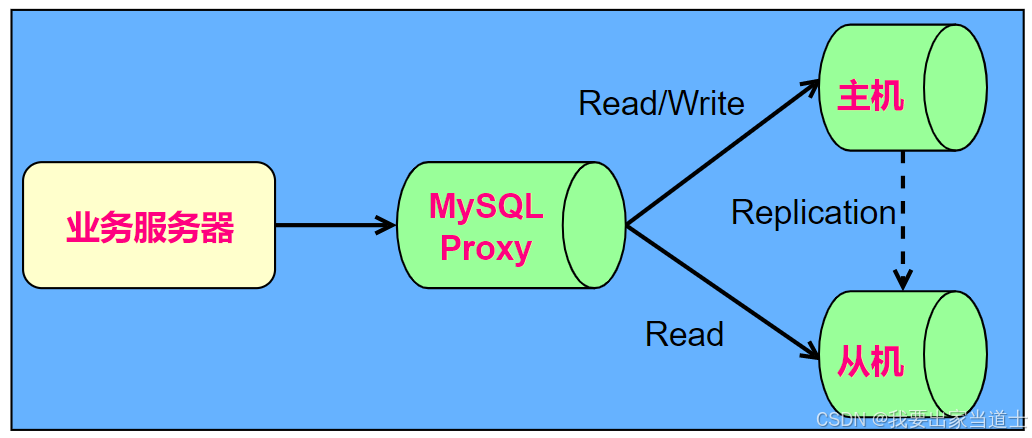
1、读写分离
大多数互联网业务基本上读多写少,因此读写分离就可以提高读的效率,读写分离首先需要将数据库分为主从库,一个主库用于写数据,多个从库完成读数据的操作,主从库之间通过主从复制机制进行数据的同步。
而且这样还可以进行主库主写,不加索引,从库主读,加索引,把两个库的效率提升到最高,不过需要解决主从同步延迟和读写分配机制。
主从同步延迟
1) 写后立刻读:在写入数据库后,一段时间内读操作去主库,之后读操作访问从库。
2) 二次查询:先去从库读取数据,找不到时就去主库进行数据读取,注意对恶意攻击限制。
3) 根据业务特殊处理:根据业务特点和重要程度进行调整,实时性高业务的数据读写都在主库,其他在从库。
读写分配机制
控制何时去主库写,何时去从库读。
1) 基于编程和配置实现:根据操作类型进行路由分配,增删改时操作主库,查询时操作从库。
2) 基于服务器端代理实现:使用中间件代理,动态分配,常用 MySQL Proxy、MyCat 以及 Shardingsphere 等。
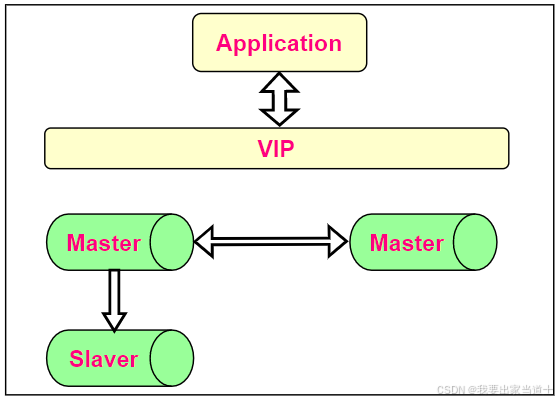
2、双主模式
主从模式,一主多从、读写分离,如果是单主模式,单主故障问题没法避免;
使用双主或者多主,增加 MySQL 入口,可以提升了主库的可用性,推荐使用双主单写,因为双主双写存在 ID 冲突和双主更新覆盖丢失问题。
四、参考
MySQL集群架构 - 知乎 (zhihu.com)
MySQL的分片(一)——分布式数据库概述_mysql分布式数据库-CSDN博客
MySQL的分片(二)——MySQL分片_mysql分片是什么-CSDN博客