MYSQL 快速解析

一、基础知识
1、数据库范式
-
第一范式(1NF):表中每一列都是
不可分割的原子数据项。 -
第二范式(2NF):在1NF的基础上,表中的每一列都和
主键相关,不能只与主键的某一部分相关(比如联合主键)。 -
第三范式(3NF):在2NF基础上,表中的每一列数据都和主键
直接相关,不能间接相关。
2、数据库连表
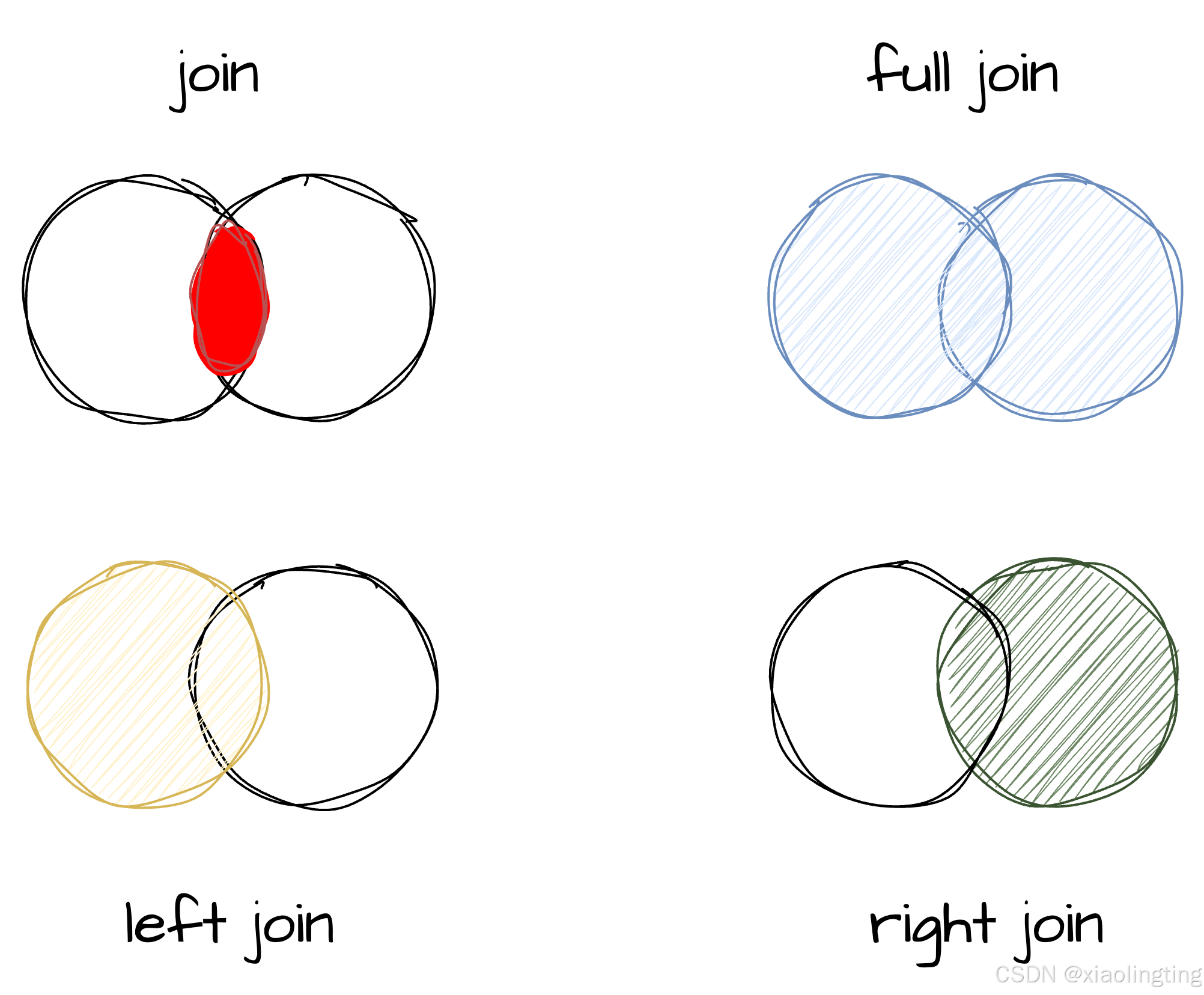
MySQL中,FULL JOIN 需要使用
LEFG JOIN + RIGHT JOIN + UNION来实现。
SELECT * FROM tb_a LEFT JOIN tb_b ON tb_a.id = tb_b.idUNION // 去除重复行SELECT * FROM tb_a RIGHT JOIN tb_b ON tb_a.id = tb_b.id
3、MySQL函数
3.1、字符串函数
CONCAT(str1, str2, ……)LENGTH(str)SUBSTRING(str, pos, len)REPLACE(str, from_str, to_str)LOWER(str)
3.2、数值函数
POWER(num, exponent)ABS(num)
3.3、日期函数
NOW()CURDATE()
3.4、聚合函数
COUNT(column)SUM(column)AVG(column)MAX(column)MIN(column)
4、SQL语句执行顺序
FROM与JOIN
优先确定数据来源,处理所有表的笛卡尔积(FROM table1, table2)或连接操作(JOIN … ON)。
若有多个表,按从左到右顺序逐步合并,生成中间虚拟表。
WHERE
对虚拟表进行行级过滤,仅保留满足条件的行。
注意:此时无法使用 SELECT 中的别名或聚合函数(如 SUM)。
GROUP BY
按指定列分组,生成分组后的数据集。
若未分组,默认将整个结果视为一个组。
HAVING
对分组后的结果进行过滤,可包含聚合函数(如 HAVING COUNT(*) > 10)。
与 WHERE 的区别:WHERE 过滤行,HAVING 过滤组。
SELECT
选择最终输出的列,计算表达式或别名。
此时才会处理列别名,因此别名不能在 WHERE 或 GROUP BY 中使用。
DISTINCT
去除重复行,基于 SELECT 后的结果进行去重。
ORDER BY
对结果排序,可使用列别名或聚合函数结果(如 ORDER BY total DESC)。
LIMIT
限制返回行数或分页,最后执行(优化性能的关键步骤)。
5、联和索引&最左匹配原则
-
联合索引进行索引查询,可能存在部分字段用到联合索引,部分字段没有用到联合索引的情况,比如:范围查询。
联合索引的最左匹配原则会一直向右匹配直到遇到
范围查询就会停止匹配。即范围查询的字段可以用到联合索引,但是在范围查询字段的后面的字段无法用到联合索引。 -
建立联合索引时,要把区分度大的字段排在前面,这样区分度大的字段越有可能被更多的 SQL 使用到。
6、主键选取规则
- 非空、唯一性;
- 趋势递增(无序会引发页分裂和合并,进而引发性能问题)
Mysql 选取主键规则:
- 用户指定主键;
- 用户未指定主键,则选择第一个不包含NULL,且值唯一的列作为主键;
- 前面两条都失败了,则默认生成一个隐式自增id作为主键。
7、索引建立规则
where条件字段order by字段group by字段- 具备唯一性字段
8、索引失效场景
- 索引列运算
- 数值运算
- 函数运算
- 显示函数运算:函数详见第3节;
- 隐式函数运算:类型转换,如索引列为字符串,参数却是数字,索引列发生隐式转换【字符串会转数字】;
- 违反最左匹配原则
- 联合索引
like‘%XX’
where子句中,or一侧没有索引
9、explain 执行计划
explain 执行后,其中type可以显示查询效率:
- all
全表扫描;
- index
全索引扫描,不需要回表;
- range
索引范围扫描,where 子句中使用 < 、>、in、between 等关键词会采用range;
- ref
非唯一索引扫描,索引有序,故而在小范围内快速查找; - eq_ref
唯一索引扫描,扫描一条满足条件即可停止;- 多表联查中,连接条件为唯一索引时,会采用eq_ref;
- const
唯一索引查找,where 条件为常量。
extra 中应避免出现 Using filesort 、Using temporary,当出现 Using index 意味着无需回表,即使用了覆盖索引。
二、进阶知识
1、WITH 子句
在MySQL中,WITH子句(公共表表达式,Common Table Expressions,CTE)用于定义临时结果集,简化复杂查询的编写,并提升可读性和维护性。
WITH cte_name1 AS (SELECT ...), cte_name2 AS (SELECT ...)
SELECT ... FROM cte_name1, cte_name2 ...;
2、ROW_NUMBER 窗口函数
2.1 定义
MySQL ROW_NUMBER()从8.0版开始引入,ROW_NUMBER()是一个窗口函数,它为从 1 开始应用的每一行分配一个序号。
ROW_NUMBER() OVER (<partition_definition> <order_definition>)
-
PARTITION BY <expression>,[{,<expression>}...]使用PARTITION BY子句时,每个分区也可以被视为一个窗口
-
ORDER BY <expression> [ASC|DESC],[{,<expression>}...]ORDER BY子句的目的是设置行的顺序
2.2 举例
2.2.1 整个表作为一个窗口
SELECT ROW_NUMBER() OVER (ORDER BY department // 省略 窗口 ) row_num,department,departNo
FROM depart
ORDER BY department;
| row_num | department | departNo |
|---|---|---|
| 1 | alibaba | 009 |
| 2 | amazon | 012 |
| 3 | baidu | 004 |
| 4 | jingdong | 007 |
| …… |
2.2.1 某一列聚合作为一个窗口
SELECT ROW_NUMBER() OVER (PARTITION BY country ORDER BY country // 添加窗口条件) row_num,country,department,departNo
FROM depart
ORDER BY country;
| row_num | country | department | departNo |
|---|---|---|---|
| 1 | America | amazon | 012 |
| 1 | China | baidu | 004 |
| 2 | China | jingdong | 007 |
| 3 | China | alibaba | 009 |
| 1 | Germany | Siemens | 123 |
| …… |
3、RANK 窗口函数
MySql 8.0 之后增加窗口函数rank():
- 并列排名:相同值的行分配相同名次,但后续名次会跳跃(如 1,1,3)。
- 跳跃性:若存在并列名次,下一个名次会跳过对应数量的序号。
-- 详见 2、ROW_NUMBER 窗口函数
RANK() OVER (<partition_definition> <order_definition>)
| 函数 | 行为特点 | 示例名次(输入:100,100,90,80) |
|---|---|---|
| RANK | 并列跳跃(1,1,3,4) | 1,1,3,4 |
| DENSE_RANK | 并列连续(1,1,2,3) | 1,1,2,3 |
| ROW_NUMBER | 连续唯一(1,2,3,4) | 1,2,3,4 |
4、条件语句 case…when…then
4.1、定义
CASE 语句遍历条件并在满足第一个条件时返回一个值(如 IF-THEN-ELSE 语句)。 因此,一旦条件为真,它将停止读取并返回结果。
如果没有条件为真,它将返回 ELSE 子句中的值。
如果没有ELSE部分且没有条件为真,则返回NULL。
CASE case_expressionWHEN when_expression_1 THEN commandsWHEN when_expression_2 THEN commands...ELSE commands
END CASE;
4.2、举例
SELECT CustomerName, City, Country
FROM Customers
ORDER BY
(CASEWHEN City IS NULL THEN CountryELSE City
END);
5、mysql引擎
| 引擎名字 | 事务 | 外键 | 行锁 | 表锁 | 默认索引类型 | 使用场景 |
|---|---|---|---|---|---|---|
| Innodb | Y | Y | Y | Y | B+树 | 高并发读写、需要事务、崩溃恢复 |
| MYISAM | N | N | N | Y | B+树 | 读多写少 |
| Memory | N | N | N | Y | 哈希索引, B+树可选 | 高性能,内存存储,没有持久化,临时表、缓存 |
6、事务与并发控制
6.1、ACID特性
- 原子性:通过
UNDO LOG实现事务回滚。 - 一致性:确保数据从一致状态转换到另一一致状态。
- 隔离性:通过锁(共享锁S、排他锁X)和MVCC(多版本并发控制)实现。
- 持久性:通过
REDO LOG保证事务提交后数据不丢失。
6.2、事务隔离级别
- 读未提交(RU):允许读取未提交数据(脏读)。
- 读已提交(RC):禁止脏读,但允许不可重复读。
- 可重复读(RR):禁止脏读和不可重复读(MySQL默认)。
- 串行化(Serializable):完全禁止并发,确保事务顺序执行。
7、mysql并发问题解决方案
- 锁:行锁、表锁
- 事务隔离级别:RU、RC、RR(默认)、serializable
- mvcc(多版本并发控制)
8、mysql 幻读问题
mysql幻读是通过MVCC和临键锁、间隙锁避免的(详见RR(Repeatable Read)级别如何防止幻读),但在一些特殊场景下,还是会出现幻读问题:事务中快照读和当前读同时存在时就会出现幻读问题。
-- 事务A
BEGIN;
SELECT * FROM user WHERE age > 20; -- 快照读,未加锁
-- 事务B插入age=25的数据并提交
-- 事务A执行当前读
SELECT * FROM user WHERE age > 20 FOR UPDATE; -- 当前读,返回包含事务B插入的新数据,发生幻读
9、长事务
9.1、定义
长事务通常指执行时间超过阈值(如几分钟到几小时)的事务,可能涉及大量数据操作或复杂逻辑。
9.2、常见原因
- 业务逻辑复杂:多表操作、批量数据更新或复杂查询导致事务执行时间延长。
- 锁竞争:事务因等待其他锁资源(如行锁、MDL锁)而阻塞,延长执行时间。
- 设置问题:
SET autocommit=0导致连接默认开启事务,未显式提交时形成意外长事务。 - 外部依赖:事务中包含外部接口调用,响应时间不可控。
9.3、长事务的影响
- 资源占用
- 锁资源:长时间持有行锁或MDL锁,导致其他事务阻塞,降低并发性能。
- 存储空间:回滚段(Undo Log)因旧版本数据无法清理而膨胀,可能占用大量磁盘空间。
- 内存与日志:事务日志(Redo Log)持续写入,增加I/O压力。
- 数据问题
- 死锁风险:长事务增加死锁概率,尤其是涉及多表操作时。
- 主从延迟:主库的长事务可能延迟从库同步,影响数据一致性。
- 系统稳定性
- 拖垮数据库:极端情况下,长事务可能导致数据库响应变慢甚至崩溃。
9.4、优化事务逻辑
- 拆分事务:将大事务拆分为多个小事务,减少锁持有时间。
- 异步处理:将耗时操作(如批量更新)放入消息队列或后台任务。
- 索引优化:为查询条件添加索引,避免全表扫描。
10、mysql 双写缓冲区(DWB, double write buffer)
10.1、定义
mysql 页大小默认为16KB,linux操作系统页大小为默认4KB(详见Linux之【文件系统】前世今生(一)),所以 mysql 页刷盘需要4次才可以完成。
问题来了:这4次刷盘必须为原子操作,使用DWB可以保证原子性。
DWB 是磁盘文件,采用连续存储,顺序写,故而性能很高。
- 当脏页刷盘时,假如刷到第2次,宕机了,意味着 16KB 数据完整性出问题了。
- redo log 恢复时基于mysql 页完整性的,所以这种情况下,redo log 无法恢复损坏的 16KB 数据。
10.2、脏页刷盘步骤
1、BufferPool中脏页在刷回磁盘前会先写DWB,确保DWB写完后,才会异步刷新磁盘。
2、如果写DWB途中宕机,出现异常,此时磁盘数据库仍为旧数据,没有损坏,可以使用redo log 进行崩溃恢复。
3、如果异步刷新磁盘途中宕机了,可以使用DWB进行恢复。
11、MySql 数据量
约定
- B+树中, 页大小16KB,一个索引字段 8Byte,页指针 8Byte;
- 则一页可以存放索引数量为1K(16KB / (8 + 8));
- 一行数据1KB,则一页可以存放数据行数量为16(16KB/1KB)。
结论
按照 3 层 B+ 树统计,可以存放约16,000,000数据。
1K * 1K * 16 = 16M,约16,000,000;
三、实战演练
1、IP地址(IPv4)存储在数据库中使用什么类型
-
使用 INT UNSIGNED 类型 4个字节;
- IP地址每个数字在(0,255),一共4个数字,刚好4个字节依次存储;
- 范围比较容易;
- ipv6 使用 BIGINT
public static int ipToLong(String ip) {String[] parts = ip.split("\\.");return (Integer.parseInt(parts[0]) << 24) +(Integer.parseInt(parts[1]) << 16) +(Integer.parseInt(parts[2]) << 8) +Integer.parseInt(parts[3]); } -
使用varchar(15),占用15个字节。
- IPv4用VARCHAR(15),IPv6用VARCHAR(45)
2、在mysql中实现可重入锁
- 锁:意味着互斥;
- 可重入:意味着同一线程可多次获取已获取的锁;
- 表1:
tbl_lock, 加锁,解锁
| 字段 | 备注 |
|---|---|
| lock_id | 锁id,主键 |
| owner | 锁持有者,即对应线程 |
| reenter_cnt | 重入次数 |
- 表2:
tbl_lock_cfg,锁配置
| 字段 | 备注 |
|---|---|
| lock_id | 锁id,主键 |
| lock_name | 锁名字 |
加锁:
begin // 事务开启// 在表 tbl_lock_cfg 中根据 锁名 查询锁ID;
// 在表 tbl_lock 根据 锁ID 查询锁记录;select …… for update;
// if 表 tbl_lock 中没有锁记录, 插入锁记录;
// else if 表 tbl_lock 中有锁记录,且锁持有者为当前线程,增加重入次数;
// else 获取锁失败commit // 事务提交
解锁:
begin // 事务开启// 在表 tbl_lock_cfg 中根据 锁名 查询锁ID;
// 在表 tbl_lock 根据 锁ID 查询锁记录;select …… for update;
// if 表 tbl_lock 中有锁记录, 且锁持有者为当前线程,减少重入次数;
// if 重入次数 <= 0:删除锁记录commit // 事务提交
3、mysql 表数据行转列
同一列下多行的不同内容作为多个字段。
3.1、使用group by + case…when…then 进行行转列
将表3.1 转为表 3.2。
表 3.1
| id | user_id | subject | score |
|---|---|---|---|
| 1 | 001 | 语文 | 90 |
| 2 | 001 | 数学 | 99 |
| 3 | 002 | 语文 | 88 |
| 4 | 002 | 数学 | 66 |
表 3.2
| user_id | 语文 | 数学 |
|---|---|---|
| 001 | 90 | 99 |
| 002 | 88 | 66 |
SELECT user_id,SUM(CASE `subject` WHEN '语文' THEN `score` ELSE 0 END) AS '语文', // 也可以使用IF: IF(`subject`='语文',score,0)SUM(CASE `subject` WHEN '数学' THEN `score` ELSE 0 END) AS '数学' // SUM 无实际意义,只是配合 Group by 使用聚合函数
FROMtb_score
GROUP BY user_id;
3.2、使用group by + group_concat 进行行转列
将表3.1 转为表 3.3。
表 3.3
| user_id | subject:score |
|---|---|
| 001 | 语文:90,数学:99 |
| 002 | 语文:88,数学:66 |
SELECT name,GROUP_CONCAT(subject,':',score separator ',') as 'subject:score'
FROM tb_score
GROUP BY name;
4、mysql 表数据列转行
4.1 同一行多列分割后作为多行
UNION ALL
例:将表3.2 【多列】 转为表 3.1【多行】
SELECT user_id, `语文` AS subject, // `语文`为字符串语文 AS score // 语文 为表中列名
FROM tb_score UNION ALLSELECT user_id, `数学` AS subject,数学 AS score
FROM tb_score
4.2 同一行某一列分割后作为多行
例:将表3.3 【多列】 转为表 3.4【多行】
substring_index(str, delim, count)
- count 为正数,则从左往右数第|count|个分隔符左边的内容;
- count 为负数,则从右往左数第|count|个分隔符右边的内容;
通过2次嵌套调用即可分割到一个字符。
SELECT x.user_id,substring_index(substring_index(x.scores, ',', y.help_topic_id + 1), ',', -1) as 'score'
FROMtb_score as x
JOINmysql.help_topic y // 方便利用系统表mysql.help_topic 中连续的 help_topic_id,如: 0,1,2,3,4,……
ONy.help_topic_id < (length(x.scores) - length(replace(x.scores, ',', '')) + 1); // 可以循环使用 0 ~ n
表 3.4
| user_id | score |
|---|---|
| 001 | 语文:90 |
| 001 | 数学:99 |
| 002 | 语文:88 |
| 002 | 语文:88 |
例:将表3.4 【多列】 转为表 3.1【多行】
SELECT user_id,substring_index(tb_score.score, ':', 1) AS subject, // 语文substring_index(tb_score.score, ':', -1) AS score , // 99
FROMtb_score