四、Hadoop 2.X vs 3.X:特性、架构与性能全解析
Hadoop 2.X 与 Hadoop 3.X 深度对比:版本特性、架构与性能剖析
在大数据处理的浪潮中,Hadoop 凭借其分布式存储与计算的强大能力,成为了业界的核心框架之一。随着技术的不断演进,Hadoop 也经历了多个重要版本的迭代。其中,Hadoop 2.X 和 Hadoop 3.X 无疑是两个具有里程碑意义的代表。本文将深入对比这两个主要版本在核心特性、架构设计以及性能表现上的差异,并结合相关架构图和性能对比图进行直观的辅助说明。
一、版本核心特性:演进与革新
Hadoop 的每一次大版本升级,都伴随着一系列关键特性的引入和优化,旨在提升其易用性、可靠性、性能和可扩展性。
(一) Hadoop 2.X:奠定现代 Hadoop 基石
Hadoop 2.X 版本是Hadoop 发展史上的一个重要转折点,它引入了诸多革命性的特性:
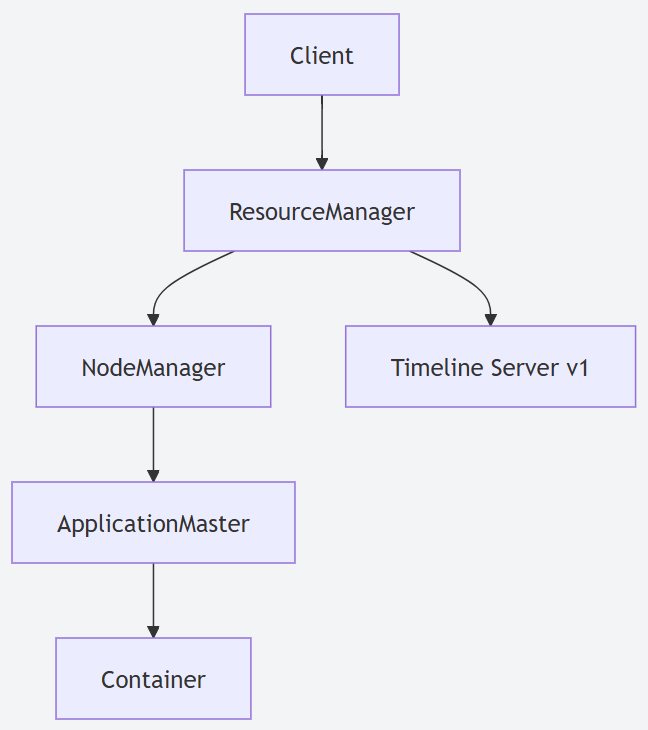
- YARN (Yet Another Resource Negotiator):这无疑是 Hadoop 2.X 最核心的变革。YARN 将资源管理 (ResourceManager) 和作业调度/监控 (ApplicationMaster) 彻底分离,使得 Hadoop 不再仅仅是 MapReduce 的专属平台。它演变为一个通用的资源管理系统,能够支持如 Spark、Flink、Tez 等多种计算框架在同一个集群上高效运行,极大地提升了集群的资源利用率和灵活性。
-
HDFS NameNode 高可用 (High Availability):针对 Hadoop 1.X 中 NameNode 的单点故障问题,Hadoop 2.X 引入了Active-Standby NameNode 架构。通过共享存储 (如 QJM - Quorum Journal Manager 或 NFS) 同步元数据,当Active NameNode 发生故障时,Standby NameNode 能够快速接管,保证了 HDFS 服务的连续性和高可用性。
-
HDFS 快照 (Snapshots):提供了对文件系统特定时间点的只读镜像创建功能。快照可以用于数据备份、灾难恢复以及防止用户误操作导致的数据丢失。
-
支持多种计算模型并存:得益于 YARN,Hadoop 2.X 生态得以蓬勃发展,除了传统的 MapReduce,更高效的DAG 执行引擎 Tez、内存计算框架 Spark 等都能在 YARN 上良好运行,满足了日益多样化的数据处理需求。
(二) Hadoop 3.X:全面优化与特性增强
Hadoop 3.X 在继承 Hadoop 2.X 优秀特性的基础上,进行了更深层次的优化和功能增强:
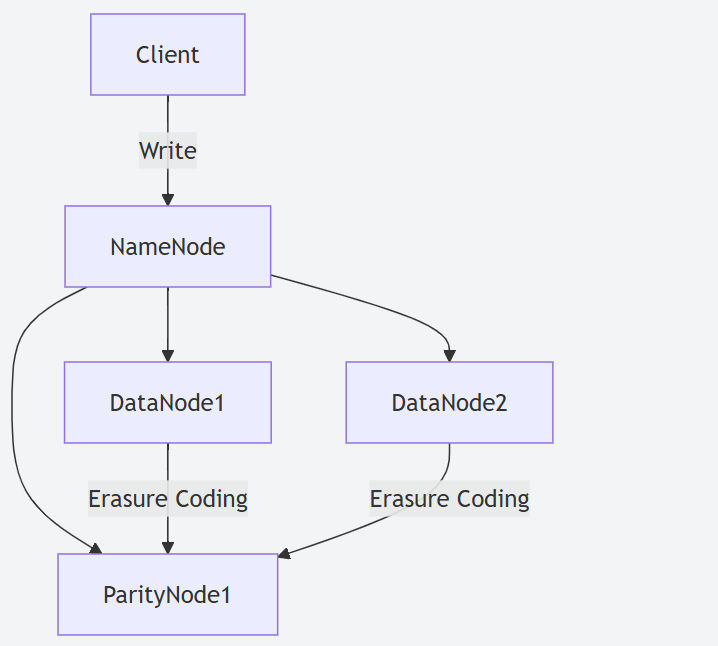
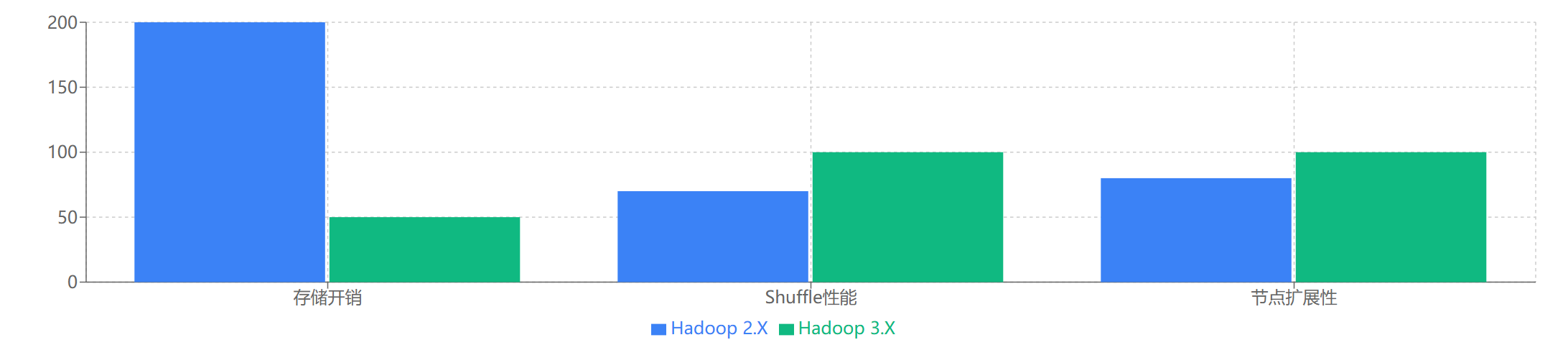
- HDFS 纠删码 (Erasure Coding):这是 Hadoop 3.X 最具吸引力的存储特性之一。相比传统的3副本策略,纠删码可以在保证同等数据可靠性 (甚至更高) 的前提下,显著降低存储开销 (通常可节省约 50% 的存储空间)。例如,采用 (6,3) 策略 (6个数据块,3个校验块) 存储数据,其存储冗余度远低于3副本。
-
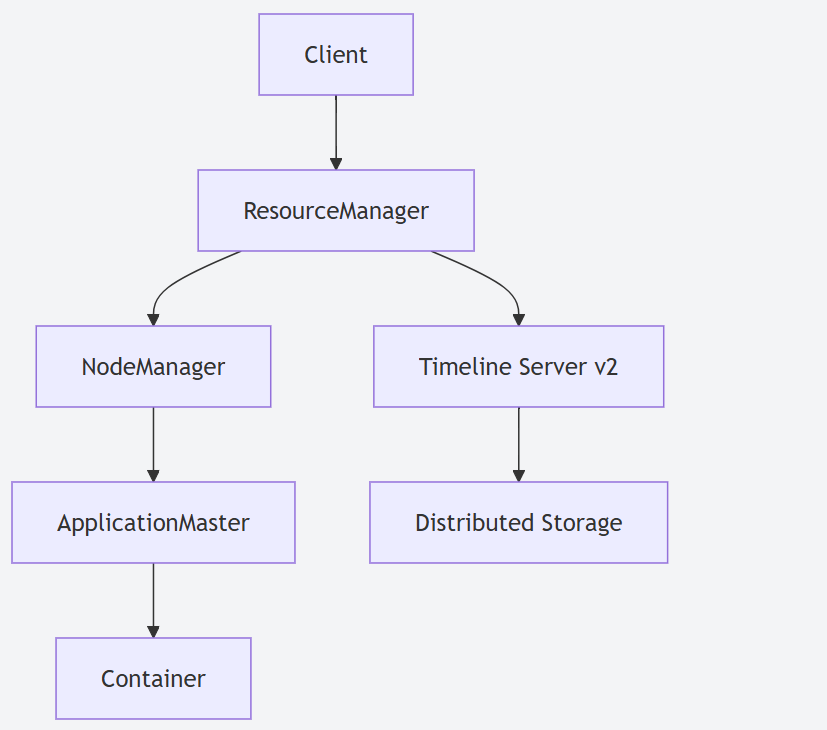
更强的 NameNode 高可用性:Hadoop 3.X 支持多个 Standby NameNode (例如,一个 Active,两个 Standby),进一步提升了 NameNode 故障切换的可靠性和容错能力。
-
YARN Timeline Service v2 (ATSv2):对应用程序历史信息的存储和查询服务进行了重构和增强。ATSv2 提供了更好的可扩展性、可靠性和性能,使用可插拔的存储后端 (如 HBase),能够更有效地管理大量应用程序的历史元数据。
-
MapReduce 性能优化:针对Shuffle密集型作业,MapReduce 的map output collector (包括 Spill, Sort, IFile 等) 可以切换到C/C++ 实现,据称可带来高达30% 的性能提升。同时,MapReduce 任务的内存参数可以自动推断,简化了配置并避免了资源浪费。
-
精简内核与依赖管理:Hadoop 3.X 移除了过时的 API 和实现,优化了默认组件。引入了Classpath Isolation机制,有效避免了不同版本 JAR 包 (如 Guava) 之间的冲突问题,增强了生态组件的兼容性。
-
Shell 脚本重构与默认端口变更:对管理脚本进行了重构,修复了bug并增加了新特性。多个服务的默认端口被移出了Linux 临时端口范围,减少了端口冲突的可能性。
二、核心架构差异:存储与资源管理
Hadoop 2.X 和 3.X 在底层架构层面也存在一些显著差异,主要体现在存储机制和资源管理服务的演进上。
(一) 存储架构的进化:从副本到纠删码
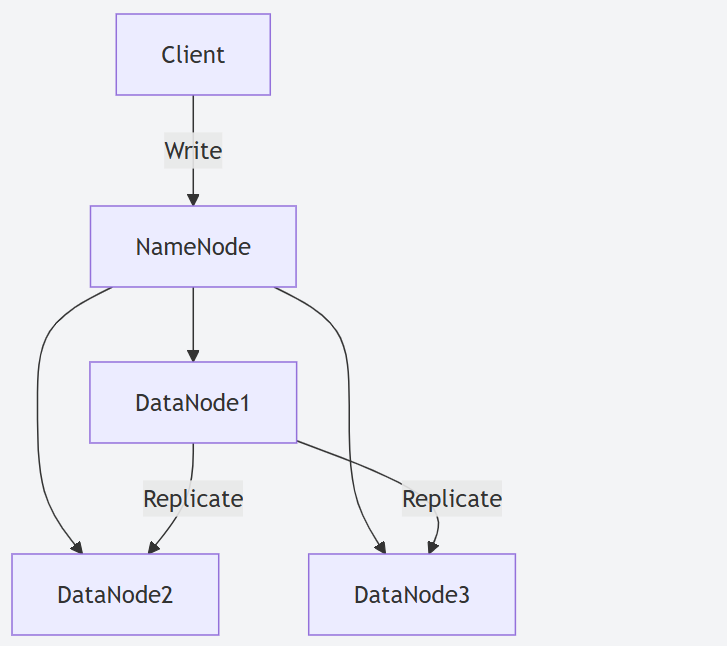
- Hadoop 2.X 存储:依赖于经典的三副本策略来保证数据可靠性。这意味着每份数据在集群中存储三份,存储开销高达 200%。虽然可靠性高,但存储成本也相应较高。
- Hadoop 3.X 存储:引入了HDFS 纠删码 (Erasure Coding)。通过数学编码的方式,可以用更少的冗余数据 (校验块) 来实现同等甚至更高的数据容错能力。这使得存储开销可以大幅降低 (例如,从 200% 降至 50% 左右),对于大规模冷数据存储尤其具有吸引力。
(二) 资源管理与历史服务的升级
-
Hadoop 2.X 资源管理:YARN 虽然带来了革命性的资源统一管理,但其早期的Timeline Service v1 (ATSv1) 在可扩展性和可靠性方面存在一些不足,尤其是在超大规模集群和大量应用的场景下可能成为瓶颈。
-
Hadoop 3.X 资源管理:全面采用了YARN Timeline Service v2 (ATSv2)。ATSv2 经过重新设计,显著提升了写入和读取应用程序历史数据的性能和可扩展性,并支持更灵活的数据存储后端,更好地服务于集群的监控和诊断。
三、性能表现对比:效率与扩展的提升
性能是衡量大数据框架优劣的关键指标。Hadoop 3.X 在多个方面都展现出相较于 2.X 的性能优势。
(一) 存储效率与开销
- Hadoop 2.X:三副本策略导致存储利用率低 (仅约 33%),网络带宽消耗也较大 (写入一份数据需要传输三份)。
- Hadoop 3.X:纠删码的引入大幅提高了存储利用率 (例如,(6,3) 策略下利用率可达 66%),显著减少了存储成本和网络I/O。
(二) 计算性能 (以 MapReduce 为例)
- Hadoop 2.X:MapReduce 在Shuffle阶段的性能以及内存管理方面存在优化空间。
- Hadoop 3.X:通过可选的 C/C++ 实现的 map output collector 和自动推断的内存参数,MapReduce 作业 (尤其是 Shuffle 密集型) 的执行效率得到了明显提升。
(三) 集群可扩展性
- Hadoop 2.X:理论上,YARN 支持上万节点的集群,但 NameNode 的元数据管理能力 (尤其是内存限制) 和 ATSv1 的扩展性可能成为实际瓶颈。
- Hadoop 3.X:通过多 Standby NameNode、ATSv2 的改进以及其他优化,Hadoop 3.X 能够更好地支持和管理更大规模的集群 (官方宣称可支持超过 10000 个节点,并持续优化中)。
四、组件信息概览 (简要对比)
| 核心关注点 | Hadoop 2.X | Hadoop 3.X |
|---|---|---|
| HDFS 可靠性 | 双 NameNode (Active/Standby), 3副本 | 多 Standby NameNode, 纠删码 + 副本可选 |
| HDFS 存储成本 | 高 (200% 冗余) | 低 (纠删码下约 50% 冗余) |
| YARN 核心服务 | ResourceManager, NodeManager, ATSv1 | ResourceManager, NodeManager, ATSv2 (更优) |
| MapReduce 性能 | Java 实现 Shuffle, 手动内存配置 | 可选 C/C++ 实现 Shuffle, 自动内存推断 |
| 依赖冲突 | 可能存在 (如 Guava 版本) | Classpath Isolation 机制缓解 |
| 集群规模支持 | 良好,但可能受 NameNode/ATSv1 限制 | 更优,设计上支持更大规模 |
五、总结与选择建议
毋庸置疑,Hadoop 3.X 在存储效率、计算性能、可扩展性、可靠性以及易用性等多个维度都对 Hadoop 2.X 进行了显著的优化和增强。对于新建的大数据平台,或者对存储成本、性能有较高要求的现有集群,升级或选择 Hadoop 3.X 无疑是更具前瞻性的决策。
然而,版本升级并非轻而易举,企业在决策时仍需综合考量:
- 现有系统兼容性:评估上层应用和生态组件与 Hadoop 3.X 的兼容情况。
- 升级成本与风险:包括人力投入、时间成本、数据迁移以及潜在的稳定性风险。
- 团队技术栈与运维能力:新特性可能需要团队学习新的知识和积累运维经验。
如果现有 Hadoop 2.X 集群运行稳定,且当前性能和存储成本仍在可接受范围内,维持现状或分阶段、小范围试点升级可能是更稳妥的策略。但长远来看,Hadoop 3.X 代表了更先进的技术方向和更优的综合效益。