Spark应用部署模式实例
Local模式
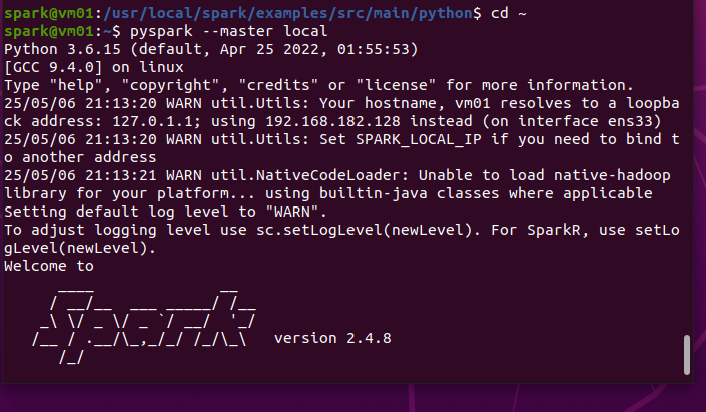
新启动一个终端
SparkSubmit # pyspark命令启动的进程,实际上就是启动了一个Spark应用程序
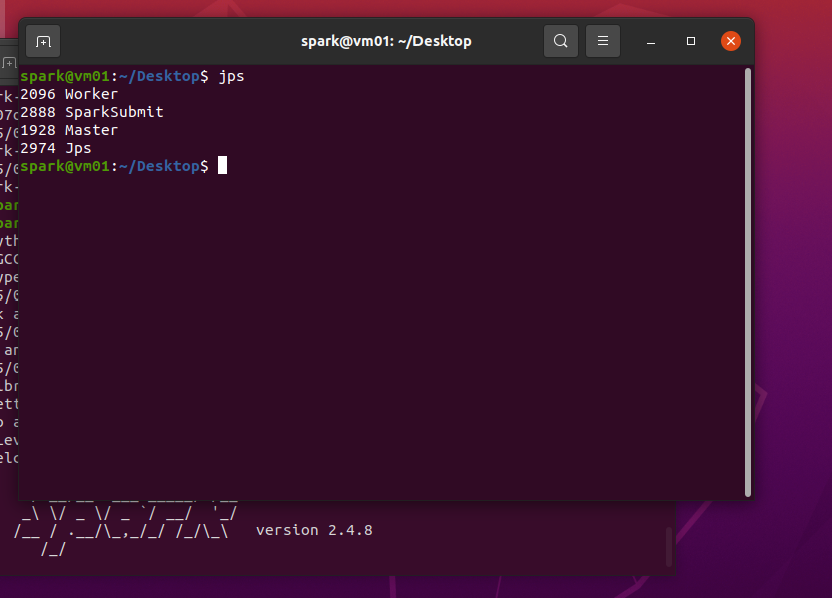
Spark Standalone模式
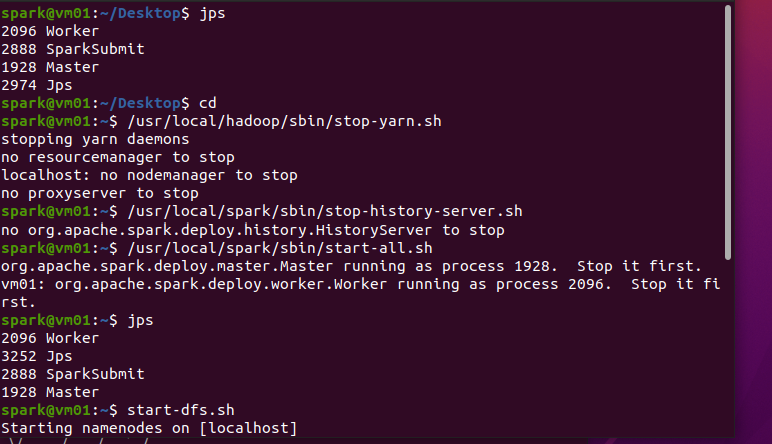
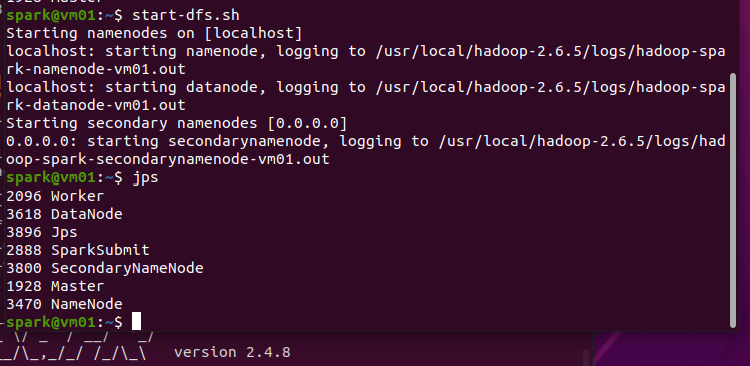
讲解:
6321 SecondaryNameNode
#hadoop中HDFS第二数据存储节点,负责定期合并 fsimage 和 edits log 文件
7475 Jps
6132 DataNode
#hadoop中HDFS的数据存储节点,负责存储实际的数据块,并响应来自客户端或 NameNode 的读写请求。
7332 Worker
#spark工作节点,负责接收 Master 节点分配的任务并在本地执行这些任务
5973 NameNode
#hadoop中HDFS的名称节点(核心组件),管理文件系统的命名空间,并控制客户端对文件的访问。
6456 ResourceManager
#hadoop中YARN的资源经理(主控服务),负责集群资源管理和调度应用的任务。
7416 HistoryServer
#历史服务进程
6761 NodeManager
#hadoop中YARN的工作节点上的代理,负责容器生命周期管理,并监控资源使用情况(如CPU、内存、磁盘、网络等)。
7180 Master
#spark主节点,负责集群管理和资源分配
Spark on YARN模式
停止Standalone服务,启动YARN服务:
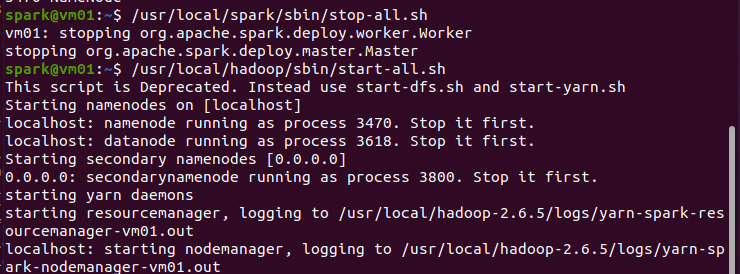
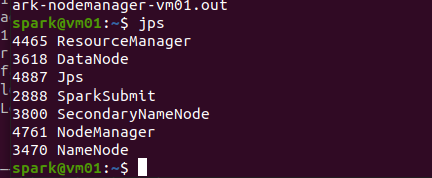
将Spark安装目录中的jars依赖库文件放到HDFS上

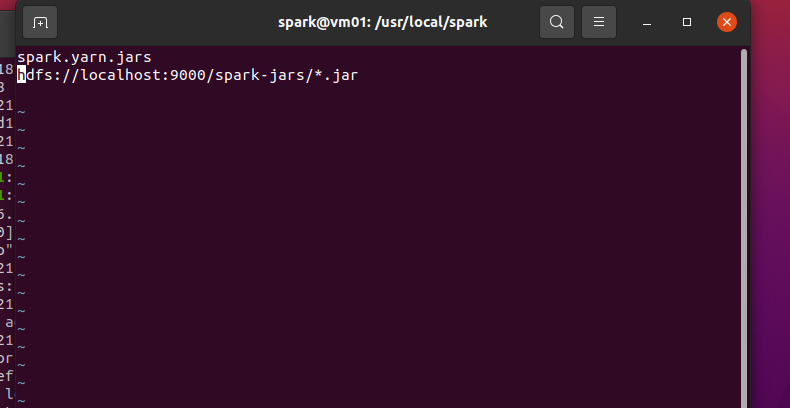
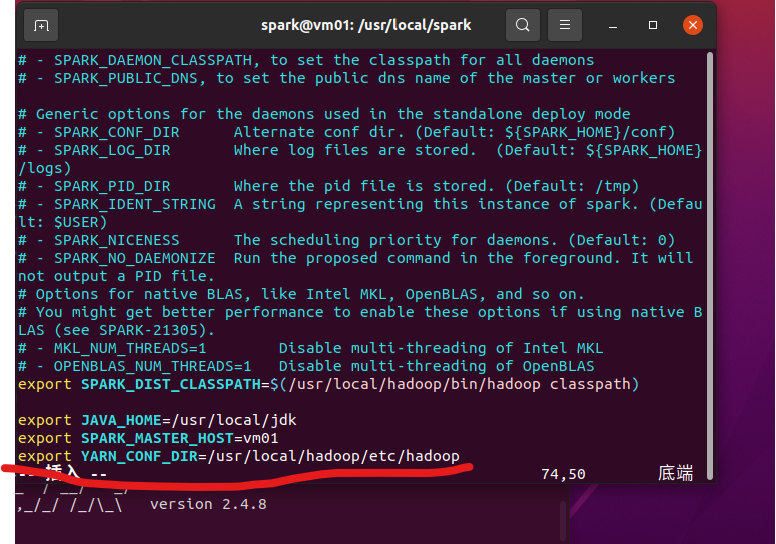
修改spark-env.sh配置文件

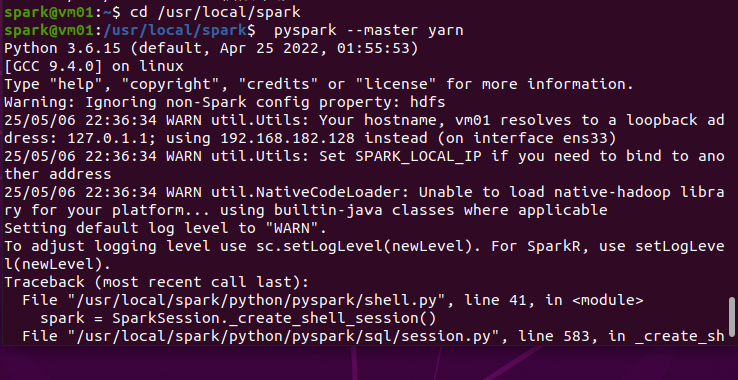
以YARN集群模式启动PySparkShell交互式编程环境
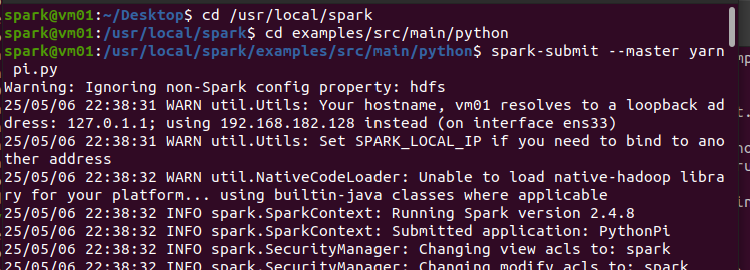
示例应用程序pi.py提交到YARN集群中运行
先关闭Local模式
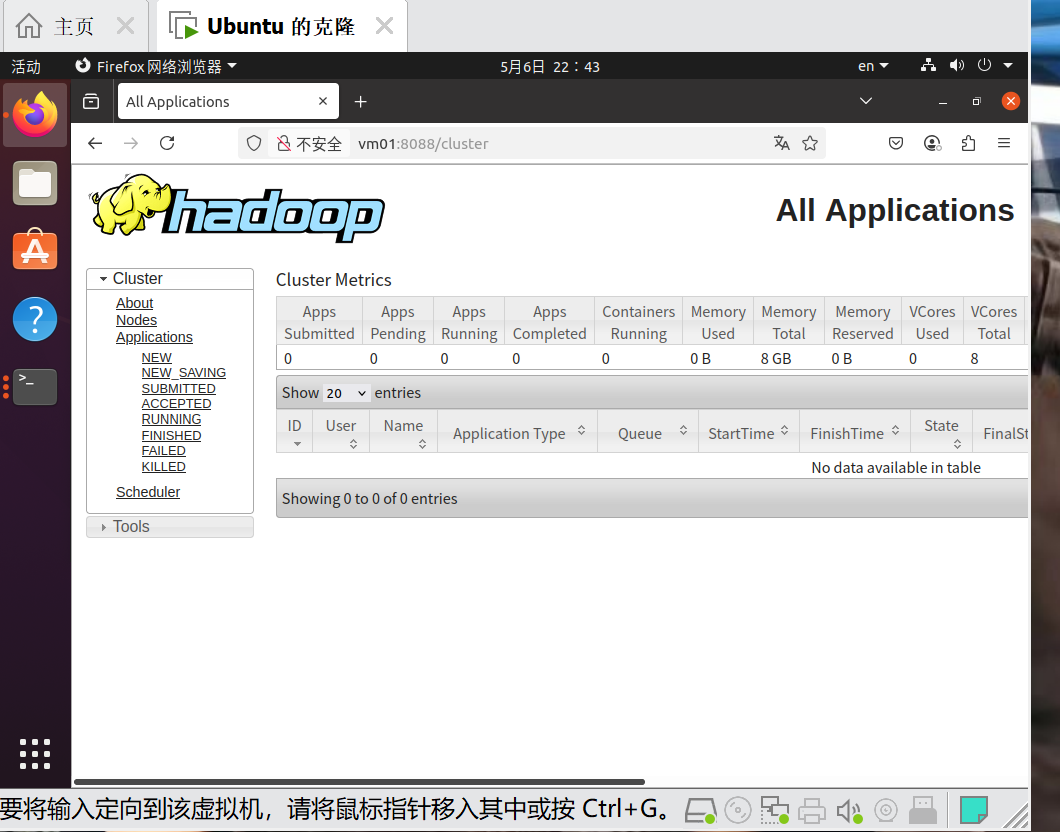
在浏览器输入:http://localhost:8088/ 查看