深度学习:图神经网络GNN、GCN及其在推荐系统的应用
什么是图(Graph)?
在数学和计算机科学中,图 (Graph) 是一种抽象数据结构,用于表示对象之间的成对关系。一个图通常定义为一个有序对 G = (V, E),其中:
-
V 是 顶点 (Vertices) 或 节点 (Nodes) 的集合 (Set)。顶点代表图中的实体或对象。
-
E 是 边 (Edges) 或 链接 (Links) 的集合 (Set)。每条边连接 V 中的一对顶点,表示它们之间存在某种关系。
有向图 (Directed Graph) vs. 无向图 (Undirected Graph)
无向图 (Undirected Graph): 边 (u, v) ∈ E 是无序对,表示 u 和 v 之间的关系是相互的、对称的。(u, v) 和 (v, u) 代表同一条边。
有向图 (Directed Graph / Digraph): 边 (u, v) ∈ E 是有序对,表示关系具有方向性,从顶点 u 指向顶点 v。边 (u, v) 和 (v, u) 是不同的,可能只有一个存在,或者两个都存在但意义不同。
无权图 (Unweighted Graph) vs. 加权图 (Weighted Graph)
无权图 (Unweighted Graph): 所有的边都被认为是同等重要的,或者说,它们只表示连接的存在与否。
加权图 (Weighted Graph): 每条边 e ∈ E 都关联一个数值(权重 w(e)),这个权重表示连接的强度、成本、距离、容量或重要性等。
图的表示方式
邻接矩阵 (Adjacency Matrix)
对于一个包含 N 个节点的图 G = (V, E),它的邻接矩阵 A 是一个 N x N 的方阵。矩阵中的元素 定义如下:
-
对于无权图: 如果节点 i 和节点 j 之间存在一条边,则
= 1;否则
-
对于加权图: 如果节点 i 和节点 j 之间存在一条边,则
(边的权重);否则
-
对于无向图: 邻接矩阵是对称的 (
)。
-
对于有向图: 邻接矩阵通常不是对称的 (
假设我们有 4 个节点 (1, 2, 3, 4) 的无向无权图:边: (1, 2), (1, 3), (2, 3), (3, 4)
1 2 3 4 <-- 节点编号 (列)
1 [0 1 1 0]
2 [1 0 1 0]
3 [1 1 0 1]
4 [0 0 1 0]
^
|-- 节点编号 (行)邻接表 (Adjacency List)
邻接表是一种存储图的方式,它由一个包含 N 个列表(或链表、或其他集合类型)的数组(或字典/哈希表)组成。数组的第 i 个元素(或键为 i 的条目)对应于图中的节点 i,该元素存储了一个列表,其中包含了所有与节点 i 相邻 (Adjacent) 的节点。
-
对于无权图: 列表里直接存储邻居节点的编号。
-
对于加权图: 列表里通常存储 (邻居节点编号, 边权重) 这样的元组 (pair)。
Node 1: [2, 3]
Node 2: [1, 3]
Node 3: [1, 2, 4]
Node 4: [3]GNN / GCN 核心思想
图神经网络的核心机制是消息传递 (Message Passing)。它通常是一个迭代过程,在每一层(或每一次迭代)中,图中的每个节点会执行以下两个主要步骤:
-
聚合 (Aggregate): 每个节点收集来自其邻居节点 (Neighbors) 的信息(通常是邻居节点的特征向量或“消息”)。聚合的方式可以有很多种,例如求和 (Sum)、平均 (Mean)、最大化 (Max Pooling) 等。
-
更新 (Update): 每个节点将聚合到的邻居信息与自身当前的信息(上一层的特征向量)结合起来,通过一个可学习的函数(通常是神经网络层,例如线性变换后接非线性激活函数)来更新自己的特征向量。
这个过程重复 K 层(K 次迭代),使得每个节点的最终表示(Embedding)能够编码其 K 跳邻域内的结构信息和特征信息。
GNN与GCN的训练目标
GNN/GCN 的主要训练目标是学习节点表示 (Node Representations),也称为节点嵌入 (Node Embeddings)。这些表示是低维、稠密的向量,它们应该能够编码节点自身的特征以及其在图中的局部邻域结构信息。理想情况下,这些学习到的表示对于下游任务 (Downstream Task) 是有用的。下游任务决定了具体的优化目标。
-
下游任务示例:
-
节点分类 (Node Classification): 预测每个节点的类别标签 (例如,在社交网络中预测用户的兴趣标签,或在论文引用网络中预测论文的主题)。
-
链接预测 (Link Prediction): 预测两个节点之间是否存在(或未来可能存在)边 (例如,推荐系统中的物品推荐,社交网络中的好友推荐)。
-
图分类 (Graph Classification): 预测整个图的类别标签 (例如,判断一个分子图是否具有某种化学性质)。
-
在推荐系统的场景下,最常见的任务是『链接预测』:预测一个用户(User Node)是否会与一个物品(Item Node)发生交互(形成一条边)。
Ground Truth (真实标签/基准事实)
Ground Truth 是模型在训练阶段需要学习和拟合的真实目标值。它来源于已知的、观测到的数据。
-
节点分类: 训练集中已知节点对应的真实类别标签。
-
链接预测 (推荐系统):
-
正样本 (Positive Samples): 数据集中实际存在的用户-物品交互记录(例如,用户点击、购买、评分过的物品)。这些是我们希望模型预测为“会发生”的连接。 Edge List (user_id, item_id) 就是正样本的 Ground Truth 来源。
-
负样本 (Negative Samples): 用户没有交互过的物品。由于未交互不代表一定不喜欢(可能只是没看到),如何选择负样本是一个重要的策略(例如,随机从未交互物品中采样)。这些是我们希望模型预测为“不会发生”或“发生概率低”的连接。
-
损失函数 (Loss Function) 与计算
损失函数用于量化模型预测结果与 Ground Truth 之间的差距。训练过程的目标就是通过调整模型参数(如 GNN 各层的权重 W)来最小化这个损失函数的值。
-
节点分类: 通常使用交叉熵损失 (Cross-Entropy Loss),衡量模型预测的类别概率分布与真实的 one-hot 标签之间的差异。
-
链接预测 (推荐系统):
-
隐式反馈 (Implicit Feedback - 点击/购买等):
-
二元交叉熵损失 (Binary Cross-Entropy Loss, BCE Loss): 将问题视为二分类问题。模型预测用户 u 与物品 i 交互的概率 p_ui。对于正样本 (实际交互过),目标是 p_ui 接近 1;对于负样本 (未交互过),目标是 p_ui 接近 0。BCE Loss 计算预测概率与目标值 (0 或 1) 之间的差异。
-
贝叶斯个性化排序损失 (Bayesian Personalized Ranking Loss, BPR Loss): 一种非常流行的成对损失 (Pairwise Loss)。它不直接预测交互概率,而是比较用户 u 对一个正样本物品 i 的偏好得分 score(u, i) 与对一个负样本物品 j 的偏好得分 score(u, j)。目标是让 score(u, i) 大于 score(u, j)。BPR Loss 惩罚那些 score(u, i) <= score(u, j) 的情况。这种方法更关注于项目之间的相对排序,非常适合推荐任务。
-
-
显式反馈 (Explicit Feedback - 评分):
-
均方误差损失 (Mean Squared Error Loss, MSE Loss) 或 平均绝对误差损失 (Mean Absolute Error Loss, MAE Loss): 模型直接预测用户 u 对物品 i 的评分值 r_ui。损失函数计算预测评分 r_ui 与真实评分 R_ui 之间的平方差 (MSE) 或绝对值差 (MAE)。
-
-
GNN/GCN 的推理 (Inference)
推理是指使用已经训练好的 GNN/GCN 模型对新数据或现有数据进行预测的过程。这个阶段模型参数是固定不变的。
-
加载模型: 加载训练阶段保存下来的模型参数。
-
准备输入: 提供需要进行预测的节点(或整个图)的初始特征
和图结构信息 (Ã, D̃ 或邻接表)。
-
执行前向传播: 将输入数据送入 GNN 模型,按照训练时的层级结构,使用已加载的、固定的参数进行计算,得到最终的节点嵌入
。注意:此阶段没有反向传播和参数更新。
-
生成预测: 使用得到的节点嵌入
-
节点分类: 输出每个节点属于各个类别的概率。
-
链接预测 (推荐): 对于一个给定的用户 u,计算其与所有(或候选)物品 i 的交互得分 score(u, i),然后根据得分对物品进行排序,生成 Top-K 推荐列表。
-
GNN与GCN的异同
GCN 是 GNN 家族中最著名的一种。它借鉴了图像处理中 CNN 的思想,定义了一种非常有效的邻居聚合方式。
最核心、最简单的 GCN 聚合方式可以理解为:将一个节点的所有直接邻居(包括它自己)的特征向量进行『平均』(或者更精确地说,是一种归一化的和),然后进行一次线性变换和非线性激活。
假设我们要更新节点 i 的特征向量 h_i:
-
收集 (Gather): 获取节点 i 自身当前的特征 h_i 以及它所有直接邻居 j 的特征 h_j。
-
聚合 (Aggregate): 将这些特征向量(h_i 和所有 h_j)加起来,并进行某种形式的归一化 (Normalization)。为什么要归一化呢?因为有的节点邻居多,有的少,直接求和会导致度数大的节点特征值过大。一种常用的归一化方法是:每个邻居的特征向量 h_j 除以 sqrt(degree(i) * degree(j)),节点自身的特征 h_i 除以 degree(i)。(这里的 degree 指节点的度,即邻居数量。别担心这个细节,先理解思想!)简单理解就是做个加权平均,度数高的邻居贡献可能略有调整。
-
变换 (Transform): 将这个聚合后的归一化向量乘以一个可学习的权重矩阵 W (就像普通神经网络的权重一样)。这是模型学习的关键!Aggregated_Features * W
-
激活 (Activate): 将变换后的结果通过一个非线性激活函数 (例如 ReLU)。ReLU(Aggregated_Features * W)
得到的结果就是节点 i 在下一层的新特征向量 h_i。
我们以 Kipf & Welling 提出的经典 GCN 模型为例,详细整理其消息传递方式 如下:
GCN 第 l+1 层的输出为:
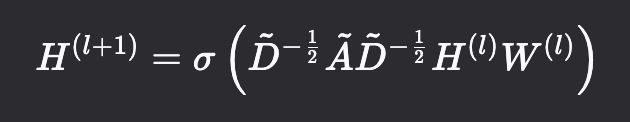
其中:

注:D̃ = D + I,即原本的度矩阵。D: 是原始邻接矩阵 A 的度矩阵。因为原本的矩阵添加自环边后,相当于每个节点都多了1个度。
总结:
GNN是处理图数据的神经网络的总称和框架 (核心是消息传递),GCN则是 GNN 框架下的一种经典且重要的具体实现,特点是其归一化的邻居平均聚合方式。
具体而言,GCN 它提出了一种特定的、受谱图理论启发的邻域聚合方式。
GCN 使用的是一种对称归一化的邻居(和自身)特征的加权和。其聚合操作符由 D̃^{-1/2} Ã D̃^{-1/2} 定义。这可以看作是一种特殊的加权平均 (Weighted Mean),权重由图的结构(节点度数)决定。它与拉普拉斯矩阵有深刻的理论联系,但实际计算是在空间域完成的。
其他 GNN 模型可以采用各种不同的聚合函数:
-
GraphSAGE: 可以用简单的均值聚合 (Mean Pooling)、最大值聚合 (Max Pooling),甚至 LSTM 聚合(将邻居视为序列)。
-
GAT (Graph Attention Network): 使用注意力机制为不同的邻居分配不同的学习到的权重进行加权求和。
-
GIN (Graph Isomorphism Network): 使用求和聚合 (Sum Aggregation) 并结合 MLP,理论上表达能力更强。
-
NGCF: 使用它自己设计的特定消息聚合方式(包含 W1, W2, ⊙)。
数学公式对比:
通用 GNN 范式
a_u^(l)是节点u在第l层聚合邻居信息的结果。AGGREGATE可选:如MEAN,SUM,MAX,ATTENTION等。UPDATE可选:如MLP,GRU,LSTM,Concat + Linear等。
GCN 的具体实现 (一层传播):
其中:
- A~=A+I:添加自环后的邻接矩阵;
- D~:A~ 对应的度矩阵;
- W(l):可学习参数矩阵;
- σ:非线性激活函数(如 ReLU);
可以理解为:
即:
- 聚合时使用基于度数的固定权重;
- 更新是线性变换 + 激活。
GNNs的评价指标
召回率 (Recall@K)
召回率@K (Recall at K) 衡量的是推荐系统找回的相关物品占所有用户真正相关物品的比例,通常关注于推荐列表的前 K 个位置。
其计算公式为:
Recall@K = (推荐列表前 K 个物品中属于用户真正相关的物品数量) / (用户所有真正相关的物品总数)
这里的“用户真正相关的物品”通常指测试集中用户实际有过交互(如点击、购买、评分等)的物品 (Ground Truth)。
通俗易懂 (Simple Explanation) 😄:
想象一下,你去一个大池塘钓鱼,池塘里有 10 条你真正想要的特定种类的鱼(这些是所有相关的物品)。你甩竿钓了 5 次(推荐了 K=5 个物品),钓上来的鱼里有 3 条是你想要的鱼。
那么你的召回率@5 就是:你钓到的目标鱼数量 (3) / 池塘里所有目标鱼的总数 (10) = 3 / 10 = 30%。
简单说,Recall@K 就是问:“你应该找到的所有好东西里,你在推荐的前 K 个里成功找到了多少比例?” 它关心的是有没有漏掉应该推荐的好东西。
NDCG@K (Normalized Discounted Cumulative Gain)
NDCG@K (Normalized Discounted Cumulative Gain at K) 是一个衡量排名质量 (Ranking Quality) 的指标。它不仅考虑推荐列表前 K 个物品的相关性 (Gain),还考虑了物品在列表中的位置 (Position)。核心思想是:相关的物品排在越前面越好。
计算步骤:
-
Gain (G): 为每个推荐物品分配一个相关性得分。最简单是二元相关性 (相关=1, 不相关=0),也可以是多元或连续得分 (如评分 1-5)。
-
Discounted Gain (DG): 对位置 i 上的物品的 Gain 进行“打折”,位置越靠后,折扣越大。通常用 Gain_i / log2(i+1) 计算。位置 1 的折扣是 1,位置 2 是 log2(3),以此类推。这表示用户更倾向于关注列表顶部的物品。
-
Cumulative Gain (CG@K): 累加前 K 个位置的 Gain。不考虑位置。
-
Discounted Cumulative Gain (DCG@K): 累加前 K 个位置的 Discounted Gain。DCG@K = Σ (Gain_i / log2(i+1)),从 i=1 到 K。
-
Ideal DCG (IDCG@K): 假设存在一个“完美”的排序(所有最相关的物品排在最前面),计算这个完美排序的 DCG@K。这是 DCG@K 可能达到的最大值。
-
Normalized DCG (NDCG@K): 将实际的 DCG@K 除以理想的 IDCG@K。NDCG@K = DCG@K / IDCG@K。结果在 0 到 1 之间,越接近 1 表示排名质量越好。
通俗易懂 (Simple Explanation) 😄:
想象一下搜索引擎给你返回结果,或者音乐 App 给你推荐歌曲列表。
-
首先,你希望结果里确实有好东西 (Gain)。
-
其次,你更希望最好的东西排在最前面!🥇 第一名比第十名重要得多。NDCG 就是奖励这种“把好钢用在刀刃上”的行为。
-
"Discounted" 就是说,排在后面的好东西,价值要打个折,因为你可能懒得往后翻了。
-
"Cumulative" 就是把前面 K 个位置的好东西(打折后)的价值加起来。
-
"Normalized" 是为了公平比较。比如用户 A 可能只对 3 首歌感兴趣,用户 B 对 10 首歌感兴趣,直接比较他们推荐列表的累计价值不公平。归一化后(都除以各自的“完美得分”),得到 0-1 之间的分数,就可以公平地看谁的推荐列表排序更合理。
简单说,NDCG 就是问:“你的推荐列表不仅东西对,而且顺序排得好不好?是不是把最应该推荐的放在最前面了?”
推荐系统的发展简史 & GNN 的切入点
1. 早期 - 基于内容 (Content-Based Filtering):
- 思想: "如果你喜欢 A,那么和 A 内容相似的 B 可能也适合你。" 主要依赖用户和物品的自身属性/特征(比如电影的类型、演员,用户的年龄、偏好标签)。
- 优点: 可解释性强,不需要其他用户的数据。
- 缺点: 需要丰富的特征工程,难以发现新颖/跨领域的兴趣 (Serendipity),冷启动问题(新用户/新物品特征少)。
- 类比: 只根据你读过的科幻小说,就一直给你推荐科幻小说。
2. 中期 - 协同过滤 (Collaborative Filtering, CF):
- 思想: "找到和你口味相似的用户,看看他们还喜欢什么 (User-based CF)" 或者 "找到和物品 A 经常被一同喜欢的物品 B (Item-based CF)"。核心是利用群体的行为模式。
- 优点: 能发现新颖兴趣,不依赖物品内容特征。
- 缺点: 数据稀疏性问题(用户交互的物品很少),冷启动问题(新用户/新物品无交互记录),难以利用辅助信息。
- 类比: "和你一样喜欢 A、B 电影的人,也喜欢 C 电影,你要不要试试?"
3. 成熟期 - 矩阵分解 (Matrix Factorization, MF):
- 思想: 将巨大的、稀疏的 "用户-物品" 交互矩阵分解为两个低维的潜在因子 (Latent Factor) 矩阵:用户因子矩阵和物品因子矩阵。每个用户和物品都被表示为一个稠密的向量 (Embedding)。预测用户对物品的喜好程度 ≈ 用户向量和物品向量的点积。代表作:SVD, FunkSVD, NMF。
- 优点: 有效处理稀疏性,模型相对简单高效,泛化能力强。成为多年来的主流方法!
- 缺点: 点积操作可能不足以捕捉复杂的用户-物品交互模式,融合辅助信息(特征)不够灵活。
- 类比: 给每个用户和电影打上一些隐藏的“标签”(比如“文艺片爱好者”,“动作片成分”,“轻松幽默度”),看用户标签和电影标签匹不匹配。
4. 深度学习时代 (Pre-GNN):
- 思想: 利用深度神经网络(如 MLP, CNN, RNN, Autoencoders, Attention)来学习用户和物品的表示,或者直接建模复杂的交互函数。代表作:NCF (Neural Collaborative Filtering), DeepFM, DIN (Deep Interest Network)。
- 优点: 能自动学习复杂的特征交互,端到端学习,灵活性高。
- 缺点: 有些模型可能忽略了协同过滤信号中的高阶连接(比如 A->X->B->Y->C 这种传递关系),或者没有显式地将用户-物品交互建模为图结构。
- 类比: 用非常强大的通用工具(DNN)来处理用户特征、物品特征和交互历史。
5. GNN 时代 - 图视角下的推荐:
核心洞察: 用户和物品的交互天然就是一个图 (Graph)!通常是二部图 (Bipartite Graph),一边是用户节点,一边是物品节点,边代表交互。
GNN 的优势:
- 自然建模交互: 直接在用户-物品交互图上进行学习,符合数据本质。
- 捕获高阶信息: 通过多层 GNN 的消息传递,可以显式地捕获用户和物品之间的高阶连接(“朋友的朋友”,“相似物品的相似物品”),这是 MF 和一些浅层 DNN 难以做到的。这被认为是 GNN 相比传统 CF 或 MF 的核心优势之一!
- 融合异构信息: 可以自然地将节点特征(用户画像、物品属性)和图结构信息(交互关系)结合起来学习 Embedding。
- 端到端学习表示: 直接从图结构学习用于推荐任务的 Embedding,无需手动设计复杂的特征组合。
- 类比: 不再仅仅看用户和物品本身,或者只看直接的连接,而是把整个“用户-物品关系网”铺开,看信息是如何在这张网上流动的,从而理解每个节点(用户/物品)在网络中的角色和偏好。
GNN/GCN 在推荐系统中的应用方式
基本的思路通常如下:
-
构建图: 将用户和物品视为节点,它们之间的交互(点击、购买、评分等)视为边,构建一个(通常是二部的)用户-物品交互图。还可以加入其他节点类型(如属性、类别)或边类型(如社交关系)构成异构图。
-
初始化节点特征: 为用户和物品节点分配初始特征向量
-
可以是简单的 ID Embedding(类似 MF,每个 user/item 有一个可学习的初始向量)。
-
也可以是利用 Side Information(如用户画像特征、物品的内容特征)得到的向量。
-
-
GNN 传播: 应用 GNN(如 GCN、GraphSAGE、GAT 或其变种)在图上进行 L 层消息传递/邻域聚合。
-
每一层,用户节点会聚合其交互过的物品节点的信息来更新自身表示。
-
同时,物品节点也会聚合与其交互过的用户节点的信息来更新自身表示。
-
经过 L 层,每个节点的最终表示
-
-
预测: 使用最终的用户嵌入和物品嵌入来预测用户 u 对物品 i 的偏好。
-
常用方法是点积:
-
也可以用多层感知机 (MLP):
-
-
训练: 定义损失函数(如 BPR Loss 或 BCE Loss,基于正负样本),通过反向传播优化 GNN 模型的参数(各层的 W 和 b)以及可能的初始节点嵌入。
推荐系统中的经典GNNs
LightGCN 详解
LightGCN抛弃了传统GCNs中的W权重矩阵和激活函数,只通过邻域聚合来学习Item/User的Emedding,实现了轻量级的推荐图网络。
1. 核心动机与哲学:大道至简
-
背景: 标准 GCN 在节点分类等任务上很成功,它在每一层都包含三个关键操作:邻域聚合、特征变换 (乘以权重矩阵 W) 和非线性激活 (如 ReLU)。
-
LightGCN 的洞察: 作者 He Xiangnan 等人认为,对于推荐系统中的协同过滤 (CF) 任务而言,特征变换和非线性激活这两个操作可能是多余的 (redundant),甚至可能有害 (detrimental)。
-
特征变换 W: 在 CF 中,我们主要关心的是用户和物品的 ID 嵌入如何通过交互图传播和细化,以捕捉协同信号。对每一层都进行复杂的特征变换可能会增加过拟合风险,并且对于主要依赖 ID 的 CF 任务来说不是必需的。
-
非线性激活 σ: 非线性激活函数是增加模型表达能力的关键,但在 CF 这种相对“平滑”的场景(预测偏好),过多的非线性变换可能会过度扭曲嵌入空间,反而不利于捕捉用户-物品间的线性关系(如点积)。移除它可以让嵌入的传播更直接。
-
-
核心思想: LightGCN 移除了标准 GCN 在传播过程中的特征变换 (W) 和非线性激活 (σ),只保留了最核心的邻域聚合操作。它认为在推荐场景下,GNN 的主要作用应该是利用图结构来平滑和精炼嵌入 (smooth and refine embeddings),而不是进行复杂的特征提取。
2. 数学形式:纯粹的聚合与组合
层级传播规则:LightGCN的第 k + 1 层Embedding 使用过聚合第k层
得到的:
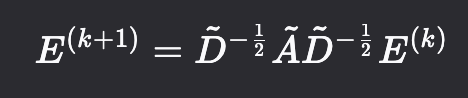
符号说明:

⚠️ 关键区别 :这个传播过程中没有可学习参数 W(k) ,也没有非线性激活函数 σ 。它只是基于图结构对当前层嵌入进行一次加权平均。使用 Adam 或其他优化器,通过反向传播只更新 Embedding Layer。
最终嵌入生成(Embedding Combination):LightGCN 不仅使用最后一层 ,而是将所有层(从第 0 层到第 L 层)的嵌入进行组合,通常是加权求和:
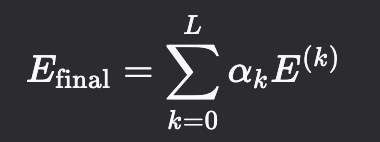
符号说明:

分离用户和物品嵌入 :

预测层(Prediction Layer):预测用户 u 对物品 i 的偏好得分,使用内积(点积):
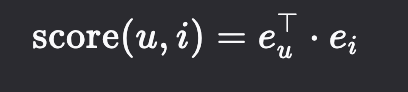
其中: eu∈Rd:用户 u 的最终嵌入向量;ei∈Rd:物品 i 的最终嵌入向量。
总结:LightGCN 是一个简化版的 GCN 模型,去除了非线性激活和权重矩阵,专注于通过多层图传播获得更鲁棒的嵌入,并通过加权组合保留个性化信息,在推荐系统中取得了优异表现。
MMGCN 详解
MMGCN 的核心思想与框架:
MMGCN 提出,要深入理解用户偏好,必须区分并考虑用户在不同模态上的特定偏好。它利用 图神经网络 (GNN) 的消息传递机制,在每个模态上构建用户-物品二部图,并学习模态特定的用户和物品表示 (modal-specific representations)。
框架: MMGCN 主要包含三个组件,并且通常会堆叠多层:
-
模态感知的用户-物品图 (Modality-aware User-Item Graphs): 这是基础。将原始的用户-物品交互二部图 G,根据物品在不同模态 m (visual, acoustic, textual) 上的特征,拆分成多个模态特定的图
。这意味着在图
-
聚合层 (Aggregation Layer): 在每个模态图上,利用 GCN 的消息传递思想,聚合邻居节点的信息来更新中心节点的表示。这一步旨在编码拓扑结构和邻居特征。
-
用户节点 u 会聚合其交互过的物品邻居 i 在模态 m 上的特征。
-
物品节点 i 也会聚合其交互过的用户邻居 u 的表示。
-
-
组合层 (Combination Layer): 聚合层得到的表示 (
) 只包含了邻居信息。组合层的作用是将这个聚合来的信息 (
) 以及一个跨模态连接的 ID 嵌入 (
) 结合起来,生成该层最终的、更丰富的模态特定表示。这一步是为了融合结构信息、自身信息和跨模态身份信息。
-
模型预测 (Model Prediction): 重复 L 次聚合和组合操作,得到用户在每个模态 m 下的最终表示。
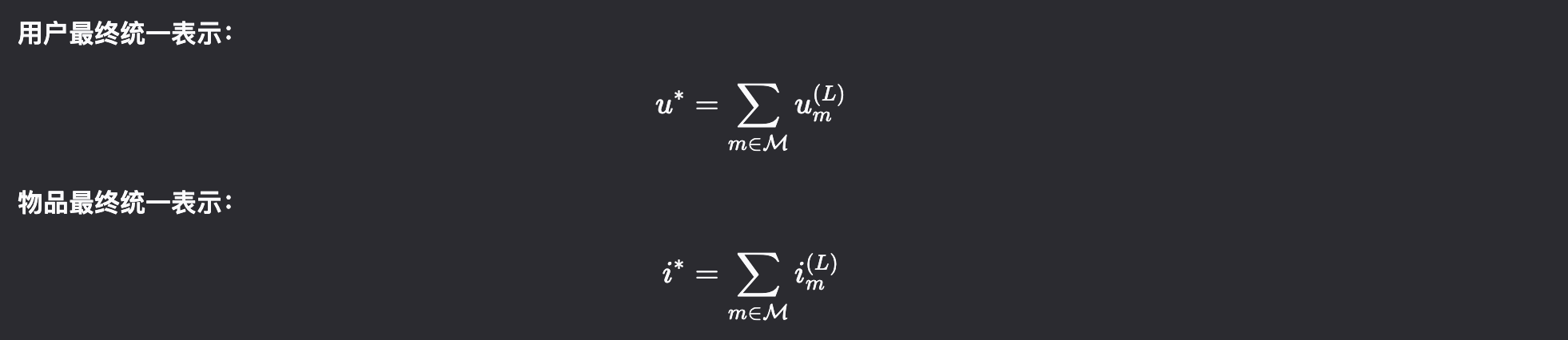

注意:这里的“求和”是一种简单的线性组合方式,也可以替换为加权求和(例如不同模态赋予不同权重)。
使用点积来预测用户对物品的偏好得分:
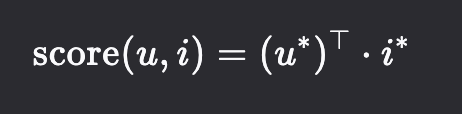
-
优化:使用BPR Loss
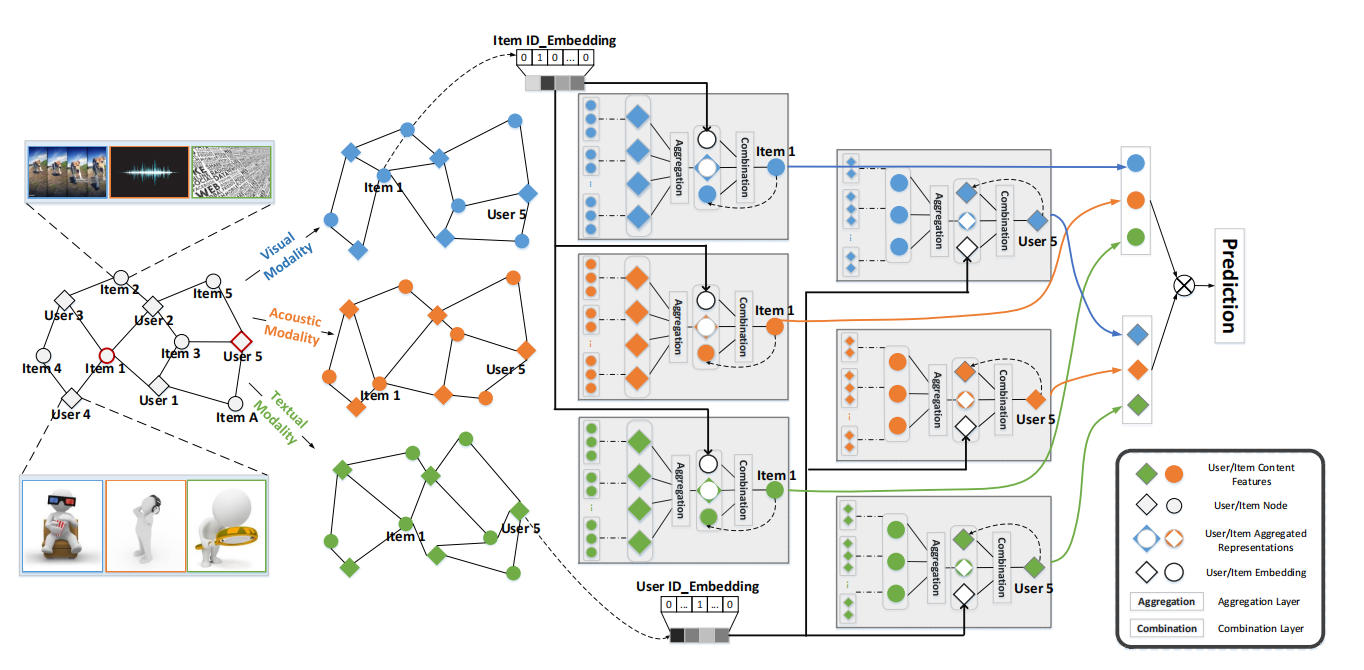
总结:在 MMGCN 中,用户和物品在每种模态下分别构建图并进行图传播,得到各模态下的最终嵌入,再通过简单求和融合为统一表示,最后使用内积预测推荐得分。