线性回归练习1
1.本次⽐赛的⽬的是预测⼀个⼈将要签到的地⽅。
1】为了本次⽐赛,Facebook创建了⼀个虚拟世界,其中包括10公⾥*10公⾥共100平⽅公⾥的约10万个地⽅。
2】对于给定的坐标集,您的任务将根据⽤户的位置,准确性和时间戳等预测⽤户下⼀次的签到位置。数据被制作成类似于来⾃移动设备的位置数据。
请注意:您只能使⽤提供的数据进⾏预测。
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split, GridSearchCV# 1. 读取数据
data = pd.read_csv("./train.csv")# 2. 数据预处理
# 2.1 缩小数据:根据给定条件筛选数据
# 仅保留 'x' 在 (1.0, 1.5) 范围内,'y' 在 (2.5, 2.75) 范围内的行
data = data.query('x>1.0 & x<1.5 & y>2.5 & y<2.75')# 2.2 将 'time' 时间戳转换为日期时间格式,转换单位为秒
time_value = pd.to_datetime(data['time'], unit='s')# 2.3 提取日期时间特征
# 提取日、小时和星期几(星期几为0-6,0表示星期一)
data['day'] = time_value.dt.day # 提取天
data['hour'] = time_value.dt.hour # 提取小时
data['weekday'] = time_value.dt.weekday # 提取星期几(0表示星期一)# 2.4 删除签到数量少于3个的目标位置
place_count = data.groupby('place_id').size() # 计算每个 place_id 出现的次数
# 选择出现次数大于 3 的 'place_id'
tf = place_count[place_count > 3].reset_index()
# 删除目标位置签到少于3个的行
data = data[data['place_id'].isin(tf['place_id'])]# 2.5 删除不需要的特征
# 删除 'row_id', 'time', 'accuracy' 列,因为它们对模型预测无直接影响
data = data.drop(['row_id', 'time', 'accuracy'], axis=1)# 查看处理后的数据
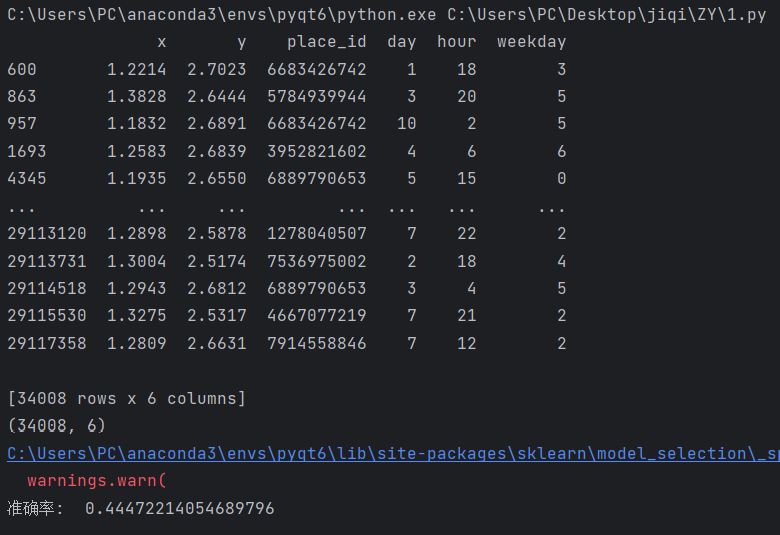
print(data.head()) # 显示数据的前几行
print(data.shape) # 打印数据的形状,确保处理后的数据是正确的# 3. 数据分割
# x: 特征数据,y: 标签数据
x = data.drop(['place_id'], axis=1) # 获取特征数据(去掉目标标签 'place_id' 列)
y = data['place_id'] # 获取目标标签数据(目标是预测 'place_id')# 将数据集拆分为训练集和测试集(80% 训练,20% 测试)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=22)# 4. 特征工程(标准化)
# 使用 StandardScaler 对特征数据进行标准化处理
std = StandardScaler()
# 对训练集和测试集的特征进行标准化处理
x_train = std.fit_transform(x_train) # 对训练集进行拟合并转化
x_test = std.transform(x_test) # 仅使用训练集的标准化参数对测试集进行转换# 5. KNN算法模型训练
# 使用 GridSearchCV 对 KNN 模型的超参数('n_neighbors')进行调优
# 选择 n_neighbors = [3, 5, 7] 进行交叉验证 (cv=3) 调参
param = [3, 5, 7]
knn_model = GridSearchCV(KNeighborsClassifier(), param_grid={'n_neighbors': param}, cv=3)# 使用训练集拟合模型
knn_model.fit(x_train, y_train)# 6. 得到预测结果
y_predict = knn_model.predict(x_test) # 在测试集上进行预测# 7. 输出模型准确率
print("准确率: ", knn_model.score(x_test, y_test)) # 计算并输出模型在测试集上的准确率
运行结果:
2. 葡萄酒质量的预测
(1)正规方程
from sklearn.datasets import load_wine # 导入 wine 数据集
import pandas as pd
from sklearn.model_selection import train_test_split # 用于数据集划分
from sklearn.preprocessing import StandardScaler # 用于特征标准化
from sklearn.linear_model import LinearRegression # 线性回归模型
from sklearn.metrics import mean_squared_error # 用于计算均方误差(MSE)# 封装函数
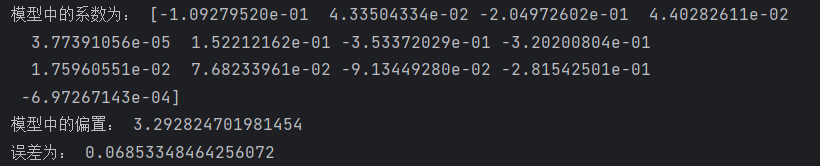
def linear_model():"""线性回归的模型:正规方程:return: None"""# 1. 获取数据集data = load_wine() # 加载 sklearn 内置的酒类数据集(该数据集包含13个特征和3个类别的目标变量)# 输出数据集的特征和目标print("数据集的特征:", data.data) # 输出数据集的特征数据(特征有13个)print("数据集的目标:", data.target) # 输出数据集的目标标签(target是不同的酒类编号)# 2. 将数据转换为 DataFrame 格式,便于查看和处理# 创建一个 DataFrame,并为每个特征命名data_df = pd.DataFrame(data.data, columns=data.feature_names) print(data_df) # 打印 DataFrame,查看数据的前几行# 将目标标签放入 DataFramedata_df["target"] = data.target # 在 DataFrame 中加入目标列(酒类的标签)print(data_df) # 打印 DataFrame,查看数据是否包含目标列# 3. 数据集是否有缺失值# 使用 isnull() 和 sum() 统计数据集中每一列的缺失值数量print("每列缺失值的总和:")print(data_df.isnull().sum()) # 如果某列有缺失值,返回的值大于0;否则为0# 4. 数据集划分# 将数据集划分为训练集和测试集(80% 用于训练,20% 用于测试)x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42)# 5. 特征工程 - 标准化# 使用 StandardScaler 对训练集和测试集的特征进行标准化处理# 标准化的目的是让每个特征的均值为 0,标准差为 1,避免某些特征因尺度不同影响模型transfer = StandardScaler() # 创建标准化器transfer.fit_transform(x_train) # 对训练集数据进行标准化transfer.fit_transform(x_test) # 对测试集数据进行标准化(注意这里应该使用 x_train 的统计量进行变换)# 6. 机器学习 - 线性回归模型(正规方程)# 使用线性回归模型进行训练estimator = LinearRegression() # 创建线性回归模型实例estimator.fit(x_train, y_train) # 在训练集上拟合模型# 输出模型的系数和偏置print("模型中的系数为:", estimator.coef_) # 输出模型训练出的系数(权重)print("模型中的偏置:", estimator.intercept_) # 输出模型的偏置(截距)# 7. 使用模型对测试集进行预测y_predict = estimator.predict(x_test) # 使用训练好的模型对测试集进行预测# 8. 回归模型评估# 计算均方误差(MSE),即预测值与实际值之间的差的平方的平均值error = mean_squared_error(y_test, y_predict) # 计算模型的误差(MSE)print("误差为:", error) # 输出模型的误差值(MSE越小表示模型越好)# 调用函数
linear_model() # 执行线性回归模型的训练和评估过程
运行结果:
(2)梯度下降法
from sklearn.datasets import load_wine
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.metrics import mean_squared_error# 封装函数
def linear_model():"""线性回归的模型:使用梯度下降(SGDRegressor):return: None"""# 1. 获取数据集# 加载自带的酒类数据集,该数据集用于分类任务,这里我们采用回归方式来预测目标变量。data = load_wine()print("数据集的特征:", data.data) # 打印数据的特征部分print("数据集的目标:", data.target) # 打印数据的目标变量部分(标签)# 创建一个DataFrame,便于查看和操作数据data_df = pd.DataFrame(data.data, columns=data.feature_names)print(data_df) # 打印特征数据# 将目标标签(target)添加到 DataFrame 中data_df["target"] = data.targetprint(data_df) # 打印包含标签的数据集# 2. 检查数据集是否存在缺失值print("每列缺失值的总和:")print(data_df.isnull().sum()) # 检查是否有缺失值# 3. 数据集划分# 将数据分为训练集和测试集,80%用于训练,20%用于测试,使用 random_state 设置随机种子保证结果可复现x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=21)# 4. 特征工程 - 标准化# 使用 StandardScaler 对数据进行标准化(即均值为0,标准差为1)transfer = StandardScaler()x_train = transfer.fit_transform(x_train) # 对训练集进行标准化x_test = transfer.transform(x_test) # 对测试集进行标准化(使用训练集的均值和标准差)# 5. 机器学习 线性回归 - 使用 SGDRegressor(随机梯度下降法)# `SGDRegressor` 是基于梯度下降的回归模型,适合大规模数据集# max_iter=1000 表示最大迭代次数为1000次estimator = SGDRegressor(max_iter=1000)# 训练模型estimator.fit(x_train, y_train)# 输出模型的系数(每个特征的权重)和偏置项(截距)print("模型中的系数为:", estimator.coef_)print("模型中的偏置:", estimator.intercept_)# 6. 使用训练好的模型对测试集进行预测y_predict = estimator.predict(x_test)# 7. 计算并输出回归模型的均方误差(MSE)# 均方误差(MSE)是衡量回归模型预测结果与真实值差异的一种常用方法error = mean_squared_error(y_test, y_predict) # 计算预测值与实际值之间的误差print("误差为:", error)# 调用函数
linear_model()
运行结果:
