隐私计算框架FATE二次开发心得整理(工业场景实践)
文章目录
- 版本介绍
- 隐私计算介绍
- 前言
- FATE架构
- 总体架构
- FateBoard架构
- 前端架构
- 后端架构
- FateClient架构
- 创建DAG方式
- DAG生成
- 任务管理
- python SDK方式
- FateFlow架构
- Eggroll架构
- FATE算法架构
- Cpn层
- FATE ML层
- 组件新增流程
- 新增组件流程
- 新增算法流程
版本介绍
WeBank的FATE开源版本 2.2.0
隐私计算介绍
(对隐私计算已经有了解的朋友可以跳过这节)
隐私计算,顾名思义,在保护隐私的前提下实现计算。
计算分为集中式计算和分布式计算,对于集中式计算的隐私包含,就是对集中式数据的保护。
1、集中式计算需要从各方收集数据,然后中心式进行计算。
目前主流的方法是采用可信执行环境,采用硬件加密的技术,建立虚拟机并对内存进行加密,并在生产环境部署后关闭虚拟机登录入口。(保证了数据对中心计算节点不可见)
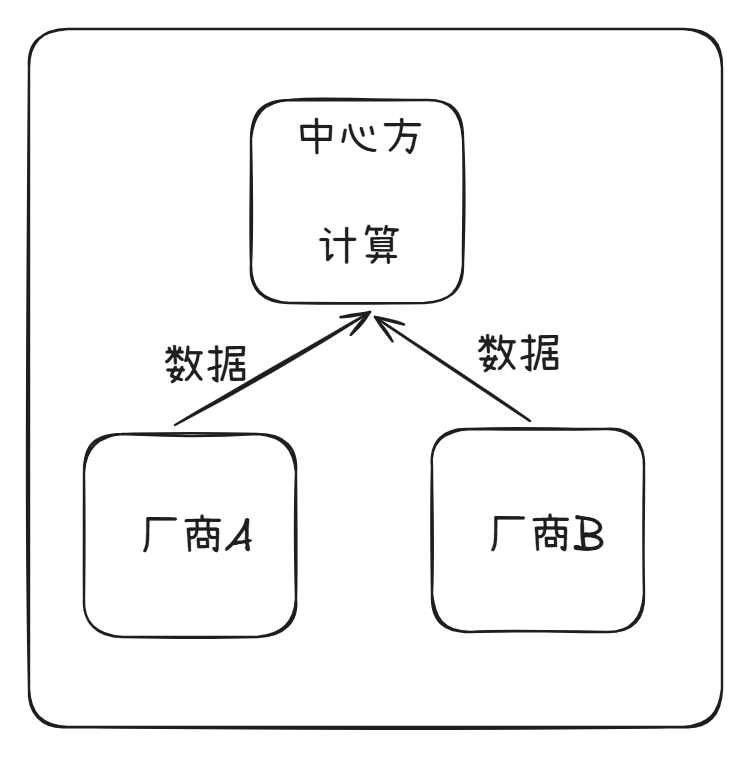
2、分布式计算则相反,不需要从各方收集数据到中心。
2.1 对于数据挖掘、模型训练等需求往往采用联邦学习(FL)的方式。
2.2 对于隐私求交、匿踪查询等需求,往往采用多方安全计算等方式,基于密码协议实现分布式计算(多方安全计算往往需要针对一类需求设计一个密码协议,目前使用仍然不广泛)。
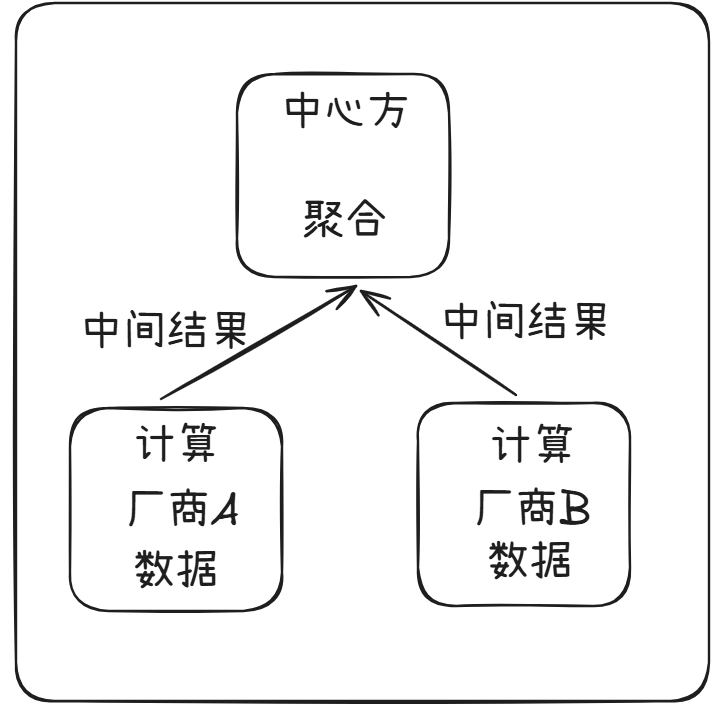
这里的中间结果,指的是对原始数据的提取信息,比如深度学习模型参数,模型梯度等信息。这些信息很难去还原原始数据信息。
前言
自从近年来隐私计算逐渐有热度以后,国内目前主流的隐私计算框架也层出不穷。
在工业界,目前开源生态较为完善的主要有微众银行的FATE和蚂蚁集团的SecretFlow等等。其中FATE主要专注于机器学习等软件层面的功能,而SecretFlow主要专注于软件、硬件一体化融合的功能。
而在学术界,目前主要是基于联邦学习(FL)pytorch进行扩展的pysyft框架(笔者读大三时发现有内存泄漏问题,不知道现在修复了没有),以及tensorflow federated(TFF)框架。还有一种简单粗暴的方式,就是直接采用本地深度学习框架进行模拟,使用串行方式来模拟并行方式,这对学术界的快速想法验证具有较好的效果。
随着国家将数据要素视为生产要素以后,以及各大数据交易所的成立,如深圳数据交易所,上海数据交易所等,这些交易所可以极大的促进数据流通,释放数据潜力。但是随着而来的就是,数据确权(两方数据计算后的中间数据属于谁?)、数据泄漏定责(数据泄漏后如何定位到具体是哪一个使用方进行的泄漏)、数据安全(使用方被攻击导致数据丢失)等一系列问题。
重点:对于数据如何安全共享的需求,隐私计算提供了一套可行且靠谱的解决方案。SecretFlow适合于二次开发需求弱,后期计划部署TEE环境的公司。FATE适合于定制化开发需求较高,且计划长期迭代开发的公司。
FATE架构
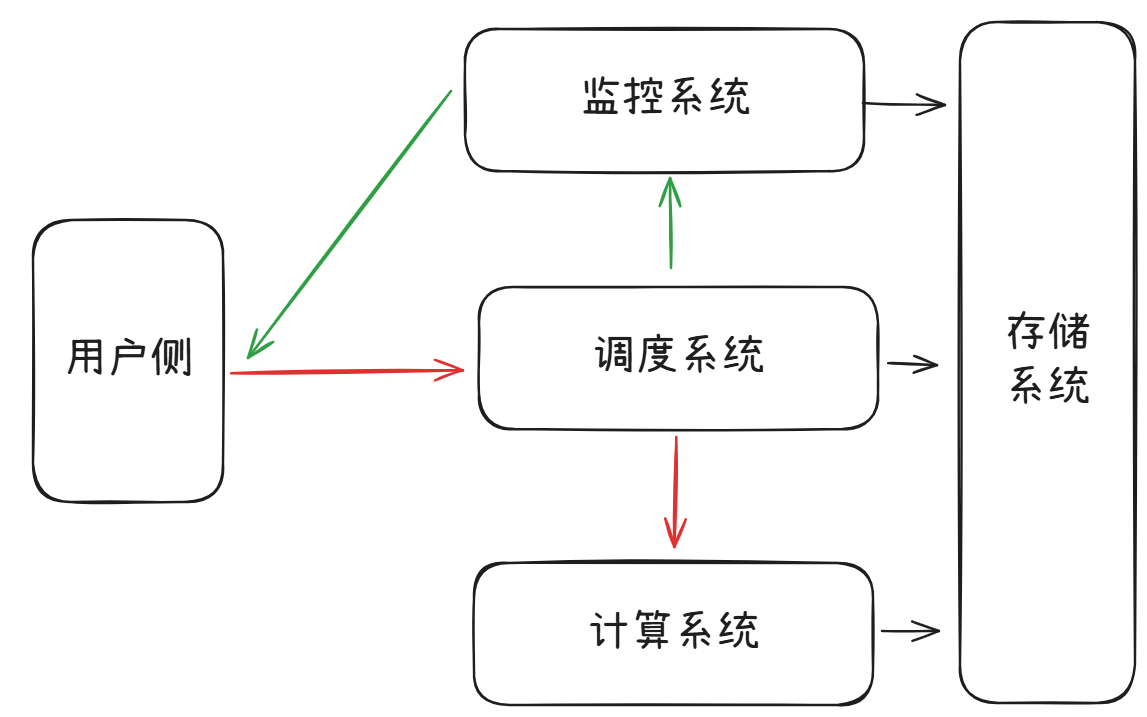
所有的分布式系统架构都可以分为四个部分
1、调度系统
2、计算系统
3、存储系统
4、监控系统
总体架构
这四个模块的关系如下:
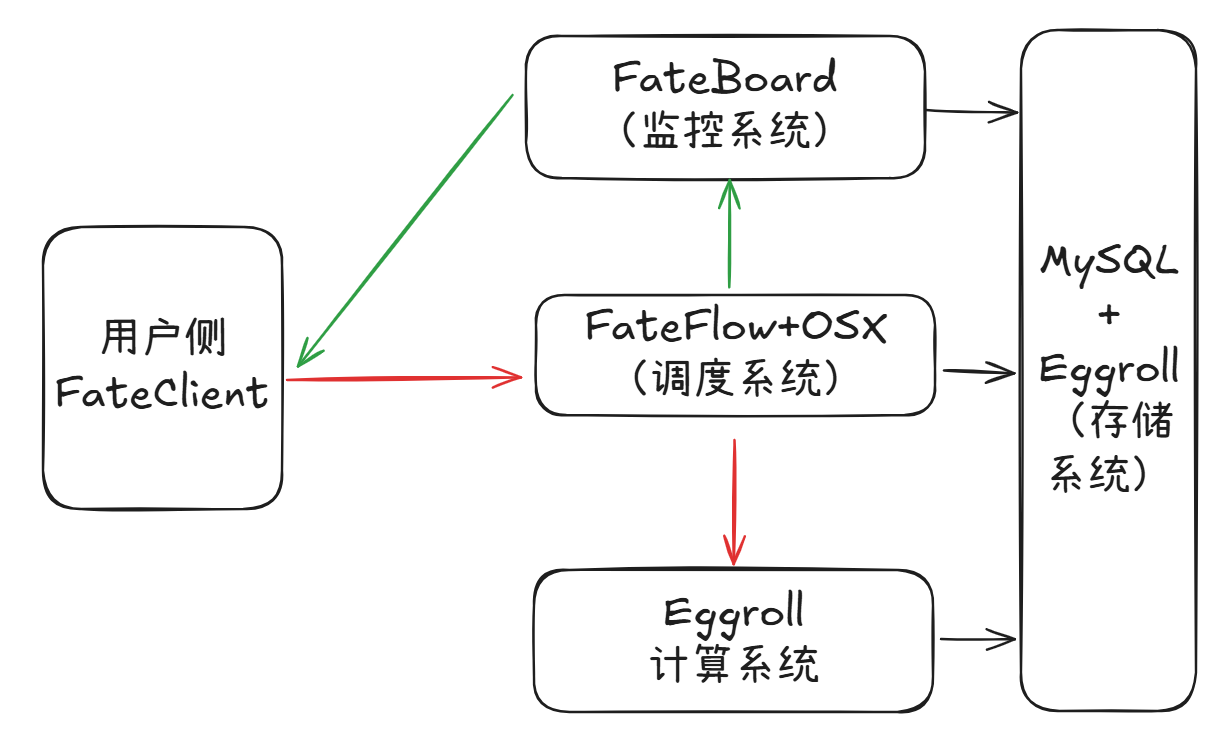
fate也不例外,FATE的基本架构如下:
在介绍各系统核心功能之前,先介绍一下任务从创建到执行的完成流程图。
1、首先,用户通过API、命令行、python SDK等方式,生成一个DAG(有向无环图)。
2、将存储DAG的yaml文件发送到FateFlow,由FateFlow进行解析调度DAG。
3、DAG由FateFlow发送到FateBoard,由FateBoard反向解析DAG,生成一张可视化的执行图。
4、Eggroll接收到FateFlow的执行命令,调用本地的Fate算法库进行执行具体计算代码。
5、任务的元信息、模型的元信息等存储到MySQL数据库中。而具体的模型参数存储到文件或Eggroll中(配置文件中指定)。
其中,各系统的核心功能如下:
FateBoard:可视化展示任务状态,展示DAG的可视化,重试、取消任务等操作的可视化。(仅仅只是可视化发送指令到Flow)
FateClient:生成需要执行的DAG的yaml文件。
FateFlow:由于是分布式计算系统,所以需要进行任务调度。其负责任务的拆解调度以及任务的具体管控等行为。
OSX:统一网关,负责鉴权,消息控制等行为。在Fate1.x中,由RabbitMq+Nginx进行解决。
Eggroll:集群存储和计算系统,用于存储训练的模型参数与MapReduce训练。在Fate1.x时,采用Spark作为分布式计算框架。
FateBoard架构
总的来说,FateBoard主要提供了一个可视化功能,将前端的请求封装为具体的FateFlow的请求进行转发。转发类为FlowFeign相关的类。由于不是核心算法相关内容,所以WeBank团队这部分做的很潦草。
前端架构
笔者不是很了解前端开发,如有错误,欢迎批评指正。
开发语言:Typescript
开发框架:Vue
功能:根据组件描述的yaml文件、以及组件间的依赖关系(JSON文件)生成可视化的执行流程。
后端架构
开发语言:java
开发框架:Spring
功能:主要是作为前端和Flow的桥梁,将task状态查询请求、DAG依赖关系查询请求等包装后发送给flow(通过REST接口的方式)。同时也具有一些简单的用户管理功能。此外,需要实时更新的请求,如Log日志、Job的执行状态则需要通过websocket协议向前端进行实时推送。
注: 采用javax的websocket协议进行ws服务管理,对于服务类中使用到的Bean是通过InitializingBean, ApplicationContextAware进行了手动注入。(因为javax产生的servlet不由spring进行管理,无法进行Bean的依赖注入)
FateClient架构
FateClient主要是用来提交任务,即提交DAG。这里可以对比一下SecretFlow,SecretFlow将FateClient和FateBoard绑在了一起,可以前端通过拖拉拽的方式构建流程图,而Fate则是FateClient构建DAG并提交,由FateBoard查看训练的状态以及结果。
创建DAG方式
目前仅支持SDK的一种方式创建DAG,但是进行任务管理时,可以有三种方式进行任务管理,分别为API、命令行、python SDK。
DAG生成
python sdk提供了类似于Java Netty框架的方式的pipeline,构建流水线类,最终生成对应的DAG文件,并提交给flow进行调度。
这里举个例子更好说明:
#
# Copyright 2019 The FATE Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.import argparse
import json
from dataclasses import asdictfrom fate_client.pipeline import FateFlowPipeline
from fate_client.pipeline.components.fate import PSI, Reader
from fate_client.pipeline.utils import test_utils# 实际上是封装了一个post请求,向flow发送消息
def main(config="../config.yaml", namespace=""):# 解析config文件,获取到各配置参数if isinstance(config, str):config = test_utils.load_job_config(config)parties = config.partiesguest = parties.guest[0]host = parties.host[0]# 创建流水线,初始化FateFlowExecutor()作为执行器,可以指定回调函数pipeline = FateFlowPipeline().set_parties(guest=guest, host=host)# 创建Reader组件,获取各方数据集reader_0 = Reader("reader_0")reader_0.guest.task_parameters(namespace=f"experiment{namespace}",name="breast_hetero_guest")reader_0.hosts[0].task_parameters(namespace=f"experiment{namespace}",name="breast_hetero_host")# 创建PSI组件,定义PSI操作# PSI进行求交的列,是在数据上传时指定的psi_0 = PSI("psi_0",hashType="sha512", input_data=reader_0.outputs["output_data"])# 将组件加入流水线中,组成一个DAG# 部署阶段可以传pipeline,训练阶段只可以传component。将component传入到一个tasks字典中,映射为[name:component]pipeline.add_tasks([reader_0, psi_0])# 依据pipeline当前的属性,内部创建DAGSpecdag = pipeline.compile().get_dag();print(dag)# 将DAG发送给flow执行,这里还需要指定当前参与方的id,对DAG进行选择性执行。下面是FateFlowExecutor()的执行逻辑。# def fit(self, dag_schema: DAGSchema, component_specs: Dict[str, ComponentSpec],# local_role: str, local_party_id: str, callback_handler: CallbackHandler) -> FateFlowModelInfo:# flow_job_invoker = FATEFlowJobInvoker()# local_party_id = self.get_site_party_id(flow_job_invoker, dag_schema, local_role, local_party_id)## return self._run(# dag_schema,# local_role,# local_party_id,# flow_job_invoker,# callback_handler,# event="fit"# )# 将DAG进行submit后,轮询监视,1s轮询一次#pipeline.fit()if __name__ == "__main__":parser = argparse.ArgumentParser("PIPELINE DEMO")parser.add_argument("--config", type=str, default="../config.yaml",help="config file")parser.add_argument("--namespace", type=str, default="",help="namespace for data stored in FATE")args = parser.parse_args()main(config=args.config, namespace=args.namespace)这段代码介绍了生成一个读取数据,并对两方数据进行psi的任务流程图。具体的介绍已经在注释中说明。生成的DAG如下:
dag:parties:- party_id: ['9999']role: guest- party_id: ['10000']role: hostparty_tasks:guest_9999:parties:- party_id: ['9999']role: guesttasks:reader_0:parameters: {name: breast_hetero_guest, namespace: experiment}host_10000:parties:- party_id: ['10000']role: hosttasks:reader_0:parameters: {name: breast_hetero_host, namespace: experiment}stage: traintasks:psi_0:component_ref: psidependent_tasks: [reader_0]inputs:data:input_data:task_output_artifact:output_artifact_key: output_dataparties:- party_id: ['9999']role: guest- party_id: ['10000']role: hostproducer_task: reader_0parameters: {hashType: sha512}stage: defaultreader_0:component_ref: readerparameters: {}stage: default
schema_version: 2.2.0任务管理
1、API方式进行管理
官方文档详细声明了API方式如何进行任务管理,也详细列出了参数,这里不做过多介绍。
2、命令行方式管理
这个方式我没有找到详细的官方文档,但是在fate的开源代码中的Fate_client包下的flow_cli中有详细的代码实现,这个也不是我关心的重点,所以我只介绍两个常用的命令。
1.数据上传命令(所有在训练过程中使用到的数据都需要将元信息进行上传,包括文件名、文件内容描述等信息)
flow data upload -c upload.json
其中,upload.json的参考格式如下:
{"file": "examples/data/breast_hetero_guest.csv", #需要上传文件的绝对路径"head": true, # 是否存在表头"partitions": 16, # 用于分布式并行计算的参数,这里默认16就好,也可以根据cpu的核心数进行配置"extend_sid": true, # 用于PSI操作,如果是纵向数据,就需要加上"meta": { # 对数据表结构的定义"delimiter": ",", # csv文件的分隔符"label_name": "y", # 声明标签列"match_id_name": "id" # 声明主键列,唯一标识数据"dtype": "str" #标识数据类型为字符串,不指定的话默认为float32},"namespace": "experiment", # 数据的命名空间"name": "breast_hetero_guest" # 通过命令空间与name可以唯一索引到数据,用于后期的Reader组件进行数据读取
}上面只是标识了一部分的常用参数,如果需要具体的定制化操作,我没有找到官方的具体文档,但是解析数据上传代码类的路径为:fate_flow/python/fate_flow/components/components/upload.py,这个py文件详细定义了数据上传时的默认参数设置。
2.任务提交命令
flow job submit -c train_lr.yaml
这个命令的作用是将存储dag的yaml文件交给flow进行解析执行。
执行的具体结果有两种方式可以查看:
一、直接访问flow的日志,路径为:fate_flow安装路径/logs/{task id}/xxxx(安装环境的时候可以用,一般不采用这种方式)
二、开启fate_board,并配置application.properties文件,将flow端口指向部署主机的9380端口。可以直接在前端通过可视化的方式查看任务的执行结果。
python SDK方式
python的SDK方式可以通过写代码的方式生成dag的yaml文件进行手动上传提交任务,也可以直接调用pipeline的fit方式,直接自动进行解析并上传到flow中。前文已经介绍过了,这里不做赘述。
FateFlow架构
关于FateFlow的架构,官方给了一张很详细的图进行说明。
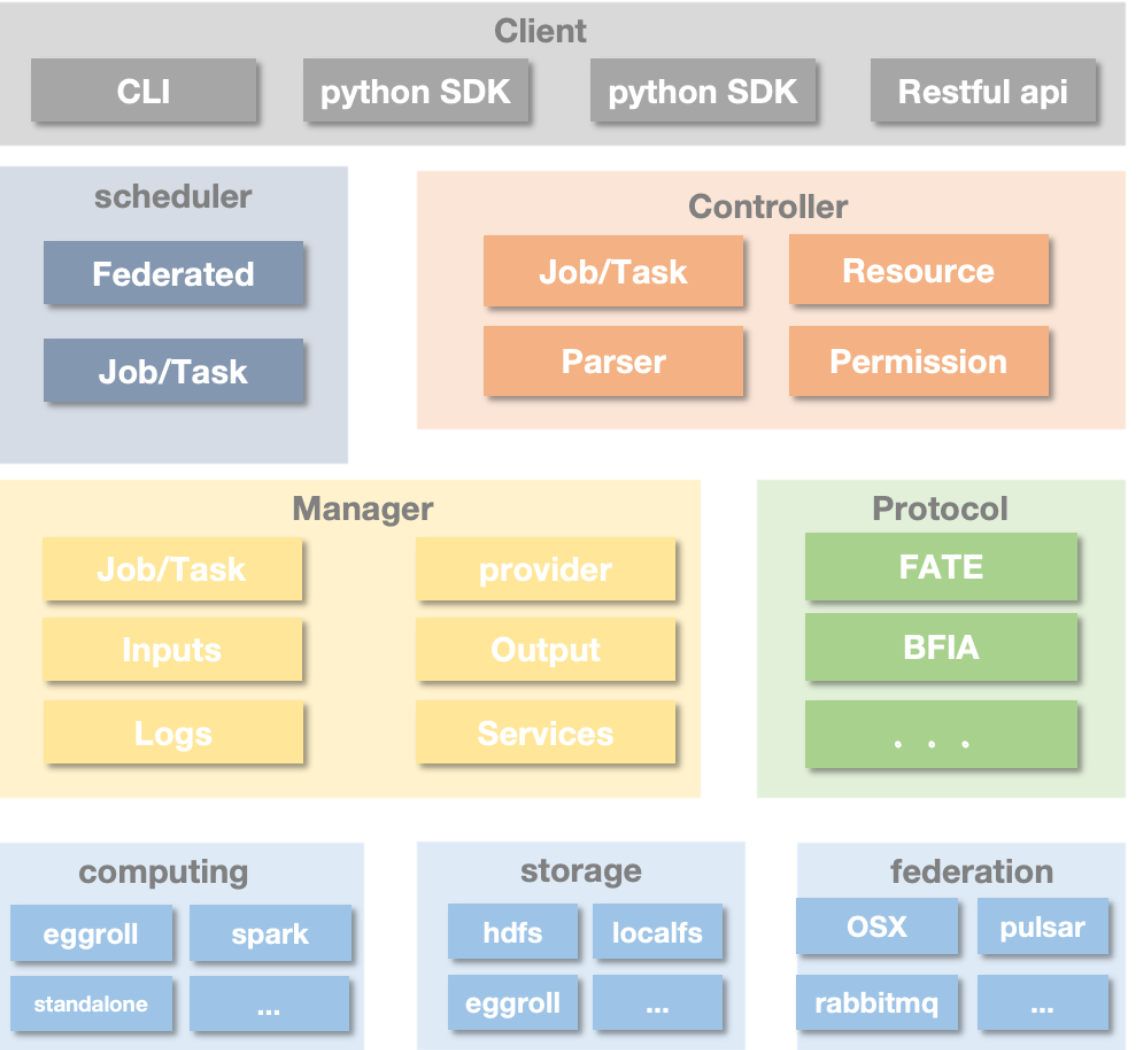
但是这张图给的细节太多了,如果第一次接触FateFlow的朋友,估计一下子很难抓住重点,所以我简化了一下,从开源代码的文件夹的角度进行介绍。
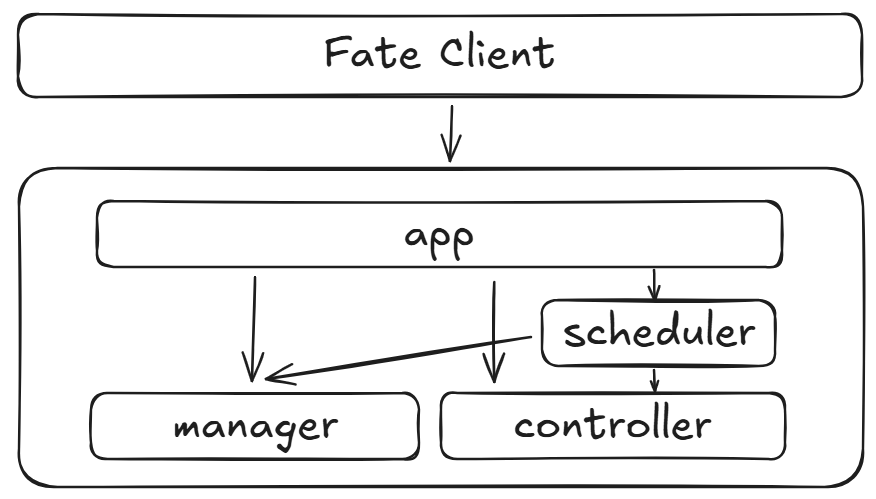
这里的几个架构我解释一下:
app: 用于对接fate client,作为fate flow的入口。
scheduler: 提供了一些关于job和task的接口,如创建job,停止job等操作。
manager: Data、Component、Log组件相关的接口会进行调用,主要是对Data、Component、Log进行管理。
controller: 其余事项的一些服务,比如DAG中组件的依赖关系的查询等。
其余的还有Eggroll和Spark存储架构,这里不是flow的重心,我这里不做介绍。
OXS目前我还不太了解,只知道时用来做网关路由的,所以先不做介绍。
Eggroll架构
Eggroll负责存储和分布式计算,但是Eggroll没有设计自己的存储引擎,Eggroll可以依托于MySQL等数据库来存储数据。Eggroll配套了对应了DashBoard可以进行监控,需要在conf/eggroll.properties文件中进行修改。
eggroll.resourcemanager.clustermanager.jdbc.driver.class.name=com.mysql.cj.jdbc.Driver
eggroll.resourcemanager.clustermanager.jdbc.url=jdbc:mysql://数据库服务器ip:端口/数据库名称?useSSL=false&serverTimezone=UTC&characterEncoding=utf8&allowPublicKeyRetrieval=true
开发语言: python(引擎部分)+java(dashboard部分)
架构概览:
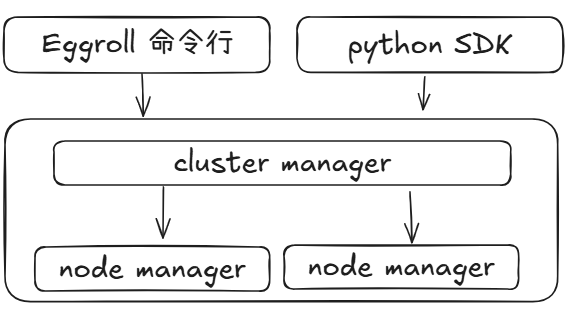
Eggroll的计算模式采用的MapReduce架构,由各分区进行并行计算,并进行结果收集后处理。
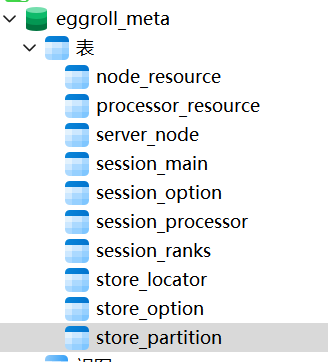
其中,MySQL中存储的主要是数据的原始信息,如store_locator中存储的是数据的分区数量,分区id等信息,而store_partition存储的是分区id以及每个分区的每个partition的id。
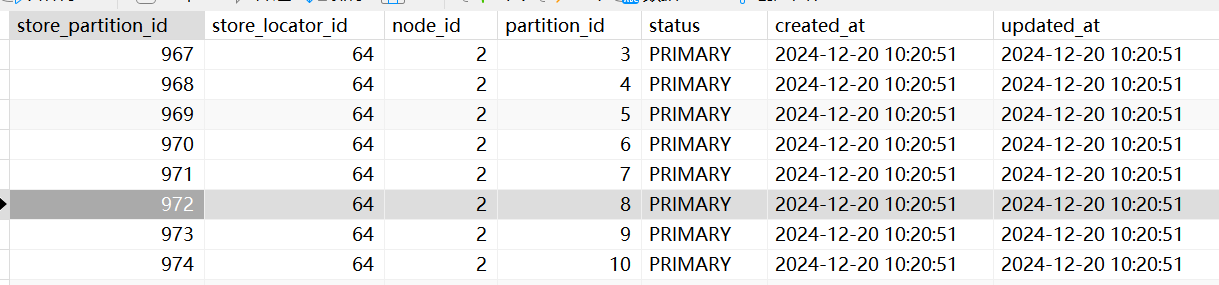
FATE算法架构
fate的算法架构官方的图片讲的较为全面,我这里就使用官方的图片进行介绍。
这里可以看到,从左往右总共分了Cpn层,FateML层,FateArch层。
Cpn层
其中Cpn是Component的简写,在fate框架中主要由components/core下的py文件来进行实现。目的是为了实现组件的注册发现于管理。在components/components包下的py文件中进行调用。这里不做具体算法的细节逻辑,更关注组件的交互流程。
cpn使用的方式较多,但是对于机器学习算法设计而言,主要使用到他的@cpn.component、@xxx.train()、@xxx.predict()三个装饰器。我这里就仅仅介绍这三个装饰器的作用。
1、@Cpn.component
这个装饰器是为了根据函数名来生成一个Component类,作为组件管理。需要会自动装配参数如下:
cpn = Component(name=cpn_name, # 组件名字roles=roles, # 当前运行方的角色provider=provider, # 组件库,默认为fateversion=version, # 组件版本description=desc, # 组件描述callback=f, # 回调函数,就是声明解释器的函数parameters=parameters,artifacts=artifacts,is_subcomponent=is_subcomponent,)
具体的使用方式如下:
@cpn.component(roles=[GUEST, HOST, ARBITER], provider="fate")
def coordinated_lr(ctx, role):...
这里需要注意,如果是不区分训练阶段于测试阶段的组件,则需要在这个函数中完成具体的逻辑设计。而对于大部分机器学习模型,往往需要针对训练阶段或测试结果进行不同的代码运行。所以,这时@xxx.train()、@xxx.predict()装饰器就派上了用场。
2、@xxx.train()与@xxx.predict()
在完成@cpn.component的组件注册时,会产生coordinated_lr这个函数,这个函数也作为装饰器进行修饰其他函数。这里针对具体的组件,对于训练的train函数,在train函数上方添加xxx.train()装饰器,而对于测试阶段的predict函数,则在predict函数上方添加xxx.predict()装饰器。
3、其余Cpn参数
Fate对所有的Component操作都进行了封装,包括了参数。所以,所有的cpn相关的参数都需要以cpn封装的形式进行提供。
举个例子:
@coordinated_lr.train()
def train(ctx: Context, # 组件上下文,往往用于流水线中传递非规格化的信息,如host向guest传递数据,向前端写入log信息等role: Role, # 当前执行组件的角色,隐私计算中guest和host执行的流程往往不同train_data: cpn.dataframe_input(roles=[GUEST, HOST]), # 训练数据,由上游组件输入validate_data: cpn.dataframe_input(roles=[GUEST, HOST], optional=True), # 验证数据,由上游组件输入...early_stop: cpn.parameter(type=params.string_choice(["weight_diff", "diff", "abs"]),default="diff",desc="early stopping criterion, choose from {weight_diff, diff, abs, val_metrics}",), # 非规格化参数,需要指定默认值,给定参数类型,参数的描述等信息。train_output_data: cpn.dataframe_output(roles=[GUEST, HOST]), # 组件的数据输出,下一个组件可以从中获取数据输入output_model: cpn.json_model_output(roles=[GUEST, HOST, ARBITER]), # 组件的模型输出warm_start_model: cpn.json_model_input(roles=[GUEST, HOST, ARBITER], optional=True), # 组件支持在预训练模型的基础上进行训练,这里可以传入之前训练好的模型
):
FATE ML层
ml层为隐私计算算法的具体逻辑实现,由Cpn层中的Components/Components下的组件进行调用。这里的大部分文件夹都可以根据名字猜出组件名字,我这里介绍一下比较重要的三个文件夹,分别为abc,aggregator,nn。
1、abc
abc是Abstract Base Classes的简写。因为python没有接口的概念,但是Fate的作者想要为所有的机器学习模型提供一种统一的抽象,以便上次cpn进行调用,所以定义了一个抽象基类module。
class Module:mode: str@typing.overloaddef fit(self, ctx: Context, input_data):...def fit(self,ctx: Context,*args,**kwargs,) -> None:...def transform(self, ctx: Context, transform_data: DataFrame) -> DataFrame: #计算一些中间结果,比如平均数等...def predict(self, ctx: Context, predict_data: DataFrame) -> DataFrame: #执行预测阶段的任务...def from_model(cls, model: Union[dict, Model]): # 将json格式或二进制格式的模型进行反序列化...def get_model(self) -> Union[dict, Model]: # 将当前模型进行序列化...由于python支持多继承机制,所以所有继承了module类的隐私计算算法类都需要重写这些方法。
2、aggregator
aggregator是很核心的一个文件夹,提供了明文聚合和安全聚合两种聚合方式,分别由两个类实现。几乎所有需要设计到聚合操作的算法,比如横向联邦学习等都需要用到这个类。聚合操作目前仅在横向聚合时才需要使用到,所以接下来分析的都是横向操作。(70%的相关调用类在nn/trainer/trainer_base.py文件夹下)
先展示一下aggregator下的__init__.py的代码:
class AggregatorType(enum.Enum):PLAINTEXT = "plaintext"SECURE_AGGREGATE = "secure_aggregate"aggregator_map = {AggregatorType.PLAINTEXT.value: (PlainTextAggregatorClient, PlainTextAggregatorServer),AggregatorType.SECURE_AGGREGATE.value: (SecureAggregatorClient, SecureAggregatorServer),
}from fate.ml.aggregator.aggregator_wrapper import AggregatorClientWrapper, AggregatorServerWrapper__all__ = ["PlainTextAggregatorClient","PlainTextAggregatorServer","SecureAggregatorClient","SecureAggregatorServer","AggregatorServerWrapper","AggregatorClientWrapper",
]这里面涉及到了多个调用关系,我画了一张类的调用关系图方便进行梳理:
文件的调用关系为:
nn/homo/fedavg.py —> nn/trainer/trainer_base.py
图片为:
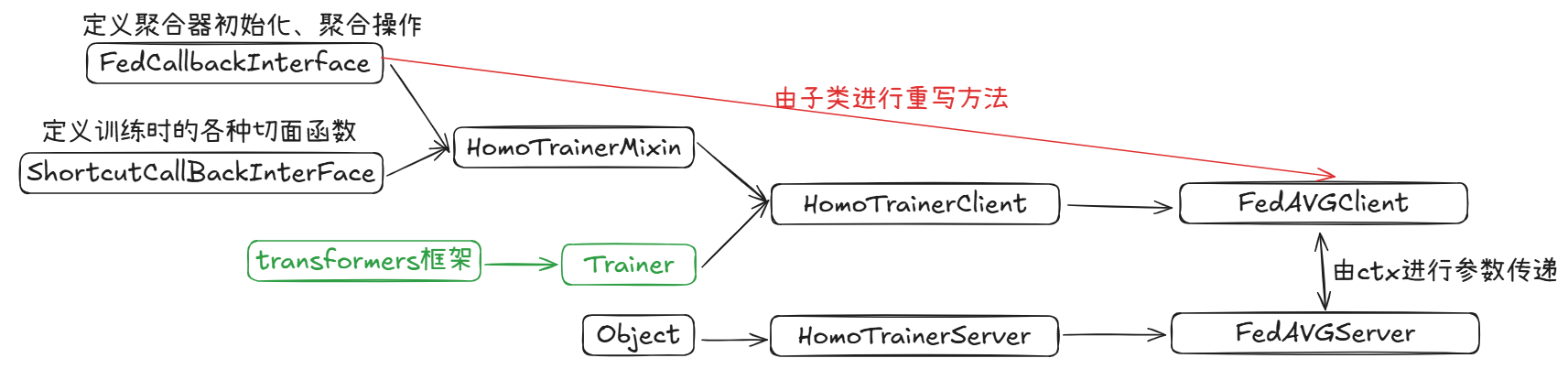
这里标绿的标识为外部框架transformers。Fate在封装算法时,为了避免大量重写已有算法,采用了大量的类继承自torch。
这里aggregator中的聚合器在FedAVGServer类进行初始化时需要传入,具体的方式采用字符串与类的绑定,降低了代码的耦合性。
3、nn
nn作为神经网络相关的最重要的一个类,下面分了好几个文件夹:
(1)datatest的作用时从本地加载数据,fate上传数据时,只是将数据的元信息存储在了MySQL中,并没有将数据纳入管控,只是得到了数据存储的绝对路径。可以根据自己的需要在这里实现dataloader,我基于自己的需求,在这里实现了时间序列数据的读取、图片数据的读取,不过fate原始只支持CSV数据的读取 。
(2)hetero的作用为封装了纵向训练的相关操作,将参与方分为了guest与host。
(3)homo文件夹下主要实现了FedAVG算法,前面已经介绍过了,这里不赘述。
(4)model_zoo中存放了所有的机器学习模型,这里需要注意,对于纵向模型需要由top模型和bottom模型,这是由fedpass算法决定的,也可以选择sshe算法进行聚合,我目前还没有试过。横向模型的化,只需要一个通用模型即可,fate会自动对模型参数进行聚合。
(5)trainer中存放的是所有和横向或者纵向训练流程相关的类。主要涉及聚合操作的类。
组件新增流程
fate官方给了一个组件新增流程,但是讲的比较粗略,我这里详细介绍一下。分别从两个方面进行介绍,新增组件流程和新增模型流程。
新增组件流程
Fate中所谓的新增组件,就是新增一个类,并且这个类可以绑定在pipeline中进行处理。
①进入fate项目,在python/fate/components/components/下新建组件(以psi为例)新建一个my_dsj.py 其内容如下:
一般开发一个组件包含以下几个部分(参考feature_scale):
#1.先定义组件
@cpn.component(roles=[GUEST, HOST], provider="fate")def 组件名称(ctx, role):...
#2. 组件实现(一般包含
@组件名称.train() 模型训练
@组件名称.predict() 模型预测
@组件名称.cross_validation()) 交叉验证 这三个装饰器实现不同的阶段,如果只有一个也可以不用任何装饰器,例如:PSI。每个阶段必须有ctx(上下文),role(角色范围),每个阶段可定义输入(cpn.dataframe_input(数据输入)| cpn.json_model_input(模型输入))与输出(cpn.dataframe_output(数据输出)| cpn.json_model_output(模型输出))。
②查看服务器conda生成fate对应的python对应的虚拟环境例如下
(venv=/data/projects/fate/common/miniconda3)
${venv}/lib/python3.10/site-packages/ fate/components/components/
然后将该文件 psi_my.py复制到该目录下.
③在python/fate/components/components/目录下在__init__.py注册组件其内容如下:
@_lazy_cpn def psi_my(self):from .psi_my import psi_myreturn psi_my
然后进入${venv}/lib/python3.10/site-packages/fate_client/pipeline/component_define目录执行以下命令生成组件描述
python -m fate.components component desc --name psi_my --save psi_my.yaml
④进入${venv}/lib/python3.10/site-packages/fate_client/pipeline/components/fate目录,新建psi_my.py文件
⑤然后在__init__.py中引入新加入的组件from .psi_my import PSI_MY完成后查询新注册的组件。
python -m fate.components component list#返回: {'buildin': ['feature_scale', 'reader', 'coordinated_lr', 'coordinated_linr', 'homo_nn', 'hetero_nn', 'homo_lr', 'hetero_secureboost', 'dataframe_transformer', 'psi', 'psi_my', 'evaluation', 'artifact_test', 'statistics', 'hetero_feature_binning', 'hetero_feature_selection', 'feature_correlation', 'union', 'sample', 'data_split', 'sshe_lr', 'sshe_linr', 'toy_example', 'dataframe_io_test', 'multi_model_test', 'cv_test2'], 'thirdparty': []}
⑥以fate自带的隐私求交为例进入examples/pipeline/psi/目录,新建test_psi_my.py
import argparsefrom fate_client.pipeline import FateFlowPipeline from fate_client.pipeline.components.fate import PSI_MY, Reader from fate_client.pipeline.utils import test_utilsdef main(config="../config.yaml", namespace=""):if isinstance(config, str):config = test_utils.load_job_config(config)parties = config.parties guest = parties.guest[0]host = parties.host[0]pipeline = FateFlowPipeline().set_parties(guest=guest, host=host) # 初始化pipelinereader_0 = Reader("reader_0")reader_0.guest.task_parameters(namespace=f"experiment{namespace}",name="breast_hetero_guest" )reader_0.hosts[0].task_parameters(namespace=f"experiment{namespace}",name="breast_hetero_host" )psi_0 = PSI_MY("psi_0", input_data=reader_0.outputs["output_data"])pipeline.add_tasks([reader_0, psi_0]) # 往pipeline中添加任务pipeline.compile() # 编译生成dag# print(pipeline.get_dag())pipeline.fit() # 上传dag到fate flow进行执行,并定时查询任务状态if __name__ == "__main__":parser = argparse.ArgumentParser("PIPELINE DEMO")parser.add_argument("--config", type=str, default="../config.yaml", # yaml文件主要是指定guest和host的idhelp="config file")parser.add_argument("--namespace", type=str, default="",help="namespace for data stored in FATE")args = parser.parse_args()main(config=args.config, namespace=args.namespace)
然后执行示例(隐私求交): python test_psi_my.py
⑦在guest端处查询到最终的结果

新增算法流程
在model_zoo中完成模型定义,如:
import torch
import torch.nn as nn
from fate_client.pipeline.components.fate.nn.torch.base import TorchModule
import logging# 定义 CNN 模型
class SimpleCNN(nn.Module):def __init__(self, in_features, out_features, height, width):super(SimpleCNN, self).__init__()self.in_features = in_featuresself.out_features = out_featuresself.height = heightself.width = width# 第一次卷积与池化self.height = (self.height - 2) // 2self.width = (self.width - 2) // 2# 第二次卷积与池化self.height = (self.height - 2) // 2self.width = (self.width - 2) // 2self.linner_in = self.height * self.width * 64self.defNetwork()def defNetwork(self):self.conv1 = nn.Conv2d(in_channels=self.in_features, out_channels=32, kernel_size=3)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(32, 64, kernel_size=3)self.fc1 = nn.Linear(self.linner_in, 64)self.fc2 = nn.Linear(64, out_features=self.out_features)def forward(self, x):x = self.pool(torch.relu(self.conv1(x)))x = self.pool(torch.relu(self.conv2(x)))x = x.view(-1, self.linner_in)x = torch.relu(self.fc1(x))x = self.fc2(x)if self.training:return xelse:softmax_out = nn.Softmax(dim=-1)(x)return softmax_outclass CNN(SimpleCNN, TorchModule):def __init__(self, in_features, out_features,height,width, **kwargs):TorchModule.__init__(self)self.param_dict["in_features"] = in_featuresself.param_dict["out_features"] = out_featuresself.param_dict["height"] = heightself.param_dict["width"] = widthself.param_dict.update(kwargs)SimpleCNN.__init__(self, **self.param_dict)这里唯一需要注意的就是,最终对外暴露的CNN,需要继承自from fate_client.pipeline.components.fate.nn.torch.base import TorchModule这个类,这个类可以理解为只重写了to_string方法(),在pipeline中组件中传递模型时,具有非常大的作用。