基于hadoop的电商用户行为分析系统(源码+论文+部署+安装)
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,我会一一回复,希望可以帮助到大家。
一、程序背景
- 技术驱动:大数据分析、人工智能技术普及,推动电商行业变革,Hadoop 等成熟技术为海量用户行为数据处理提供支撑。
- 行业需求:电商用户规模扩大,用户在线购物行为(浏览、搜索、下单等)产生海量数据,企业需通过数据挖掘精准把握用户需求,优化营销策略与个性化推荐。
- 现有痛点:传统电商难以高效处理大规模用户数据,无法精准匹配用户偏好与商品,导致用户体验与转化率偏低,亟需专业的用户行为分析系统解决该问题。
二、程序功能
程序分为用户端和管理员端两大模块,功能覆盖用户交互、数据管理与分析全流程。
| 角色 | 核心功能 | 具体说明 |
|---|---|---|
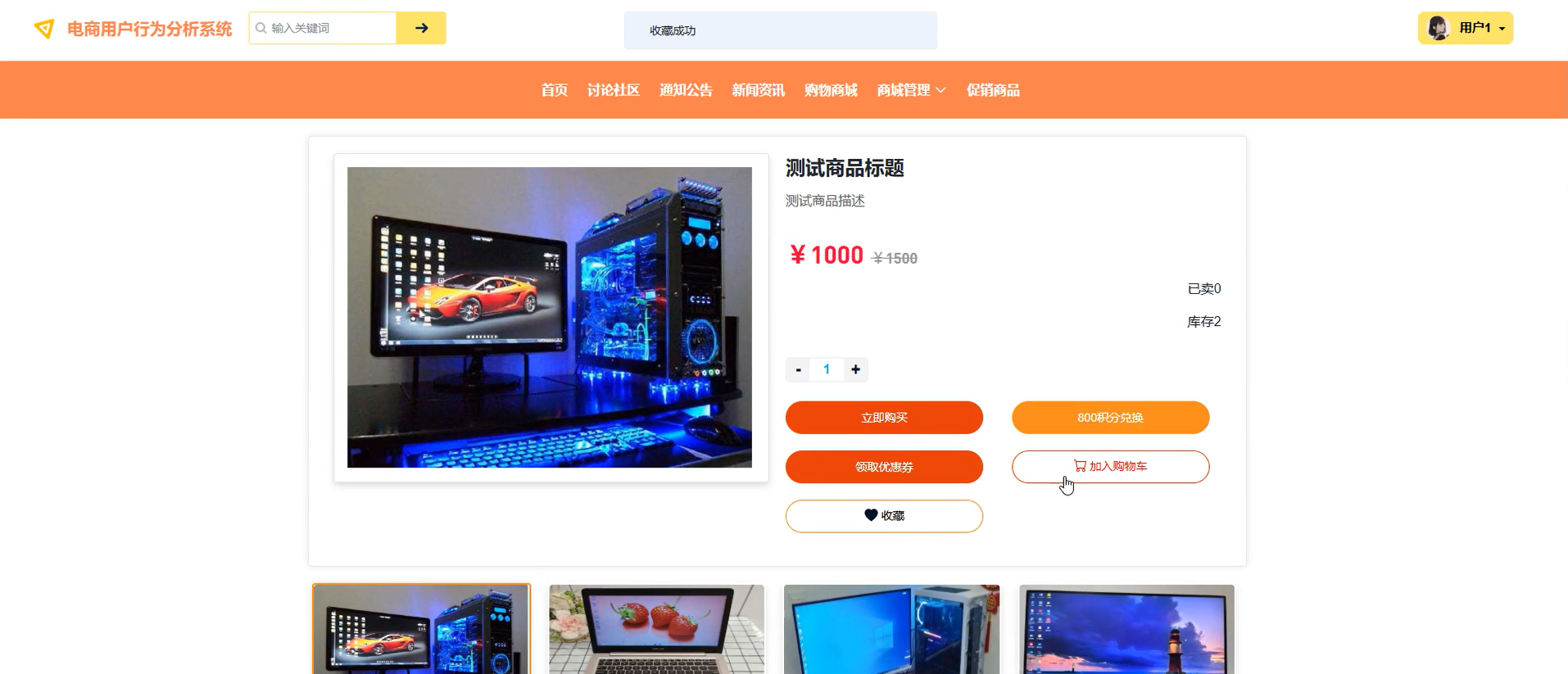
| 普通用户 | 基础购物交互 | 浏览购物商城、添加购物车、在线下单与支付,查看促销商品 |
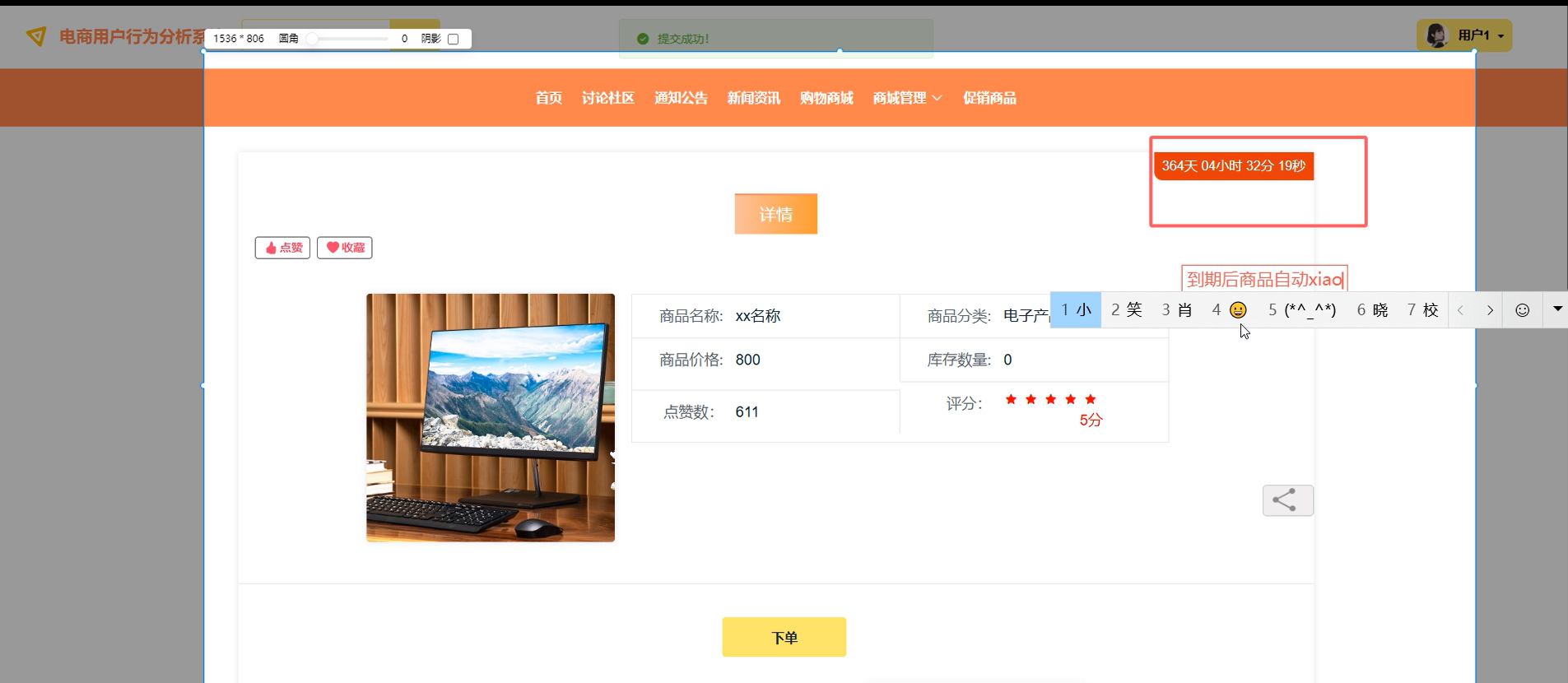
| 个性化服务 | 基于协同过滤算法接收商品推荐,发表商品评论,参与讨论社区 | |
| 信息获取 | 查看通知公告、新闻资讯,管理个人订单与收藏 | |
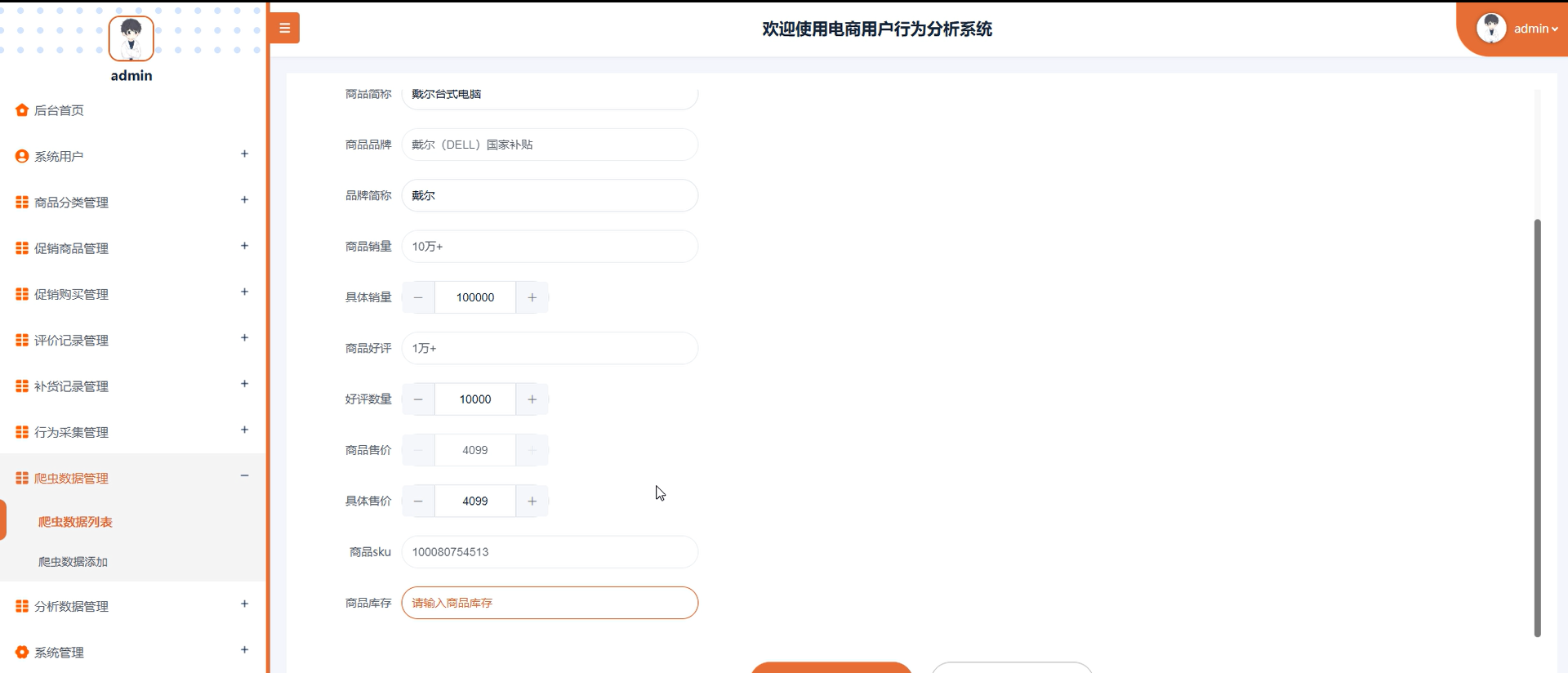
| 管理员 | 数据管理 | 管理用户信息(增删改查)、商品信息(上下架、促销设置)、爬虫数据与行为采集数据 |
| 运营管理 | 处理补货记录、评价记录、促销活动,发布通知公告 | |
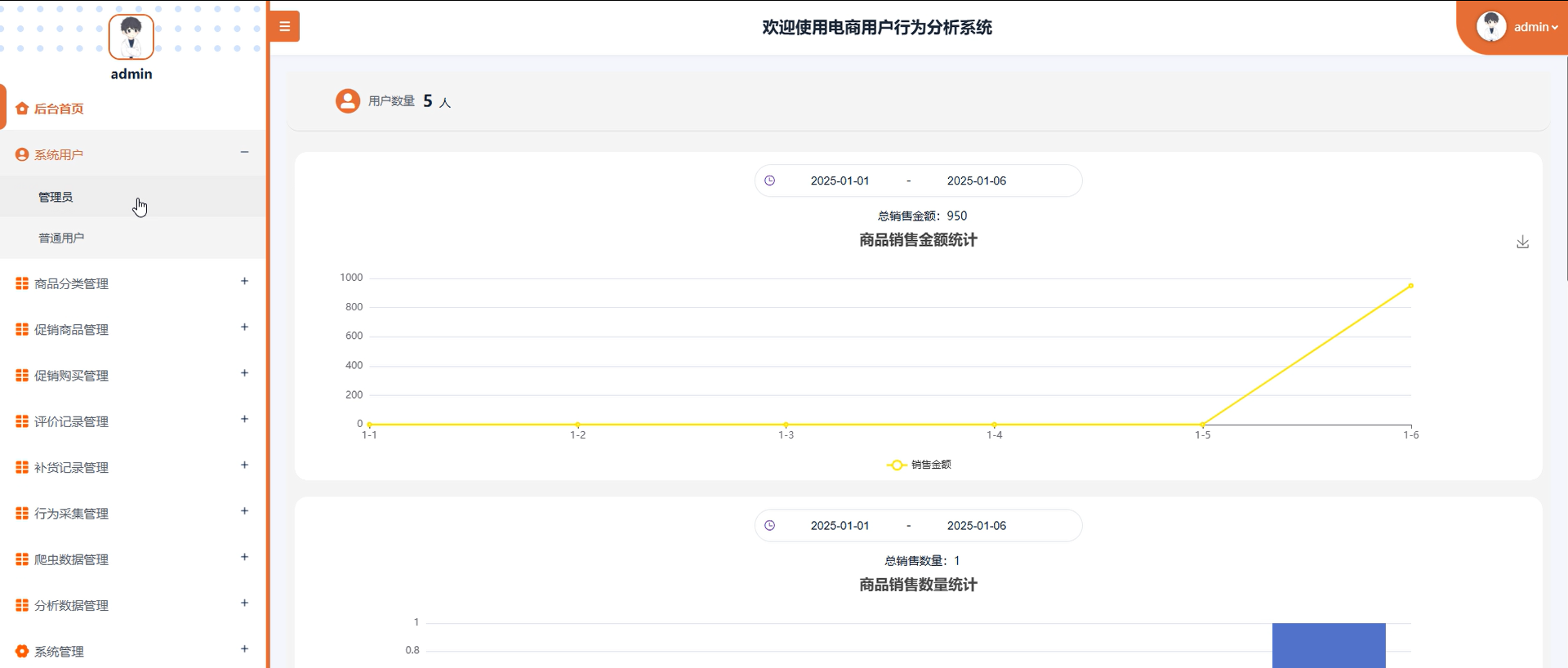
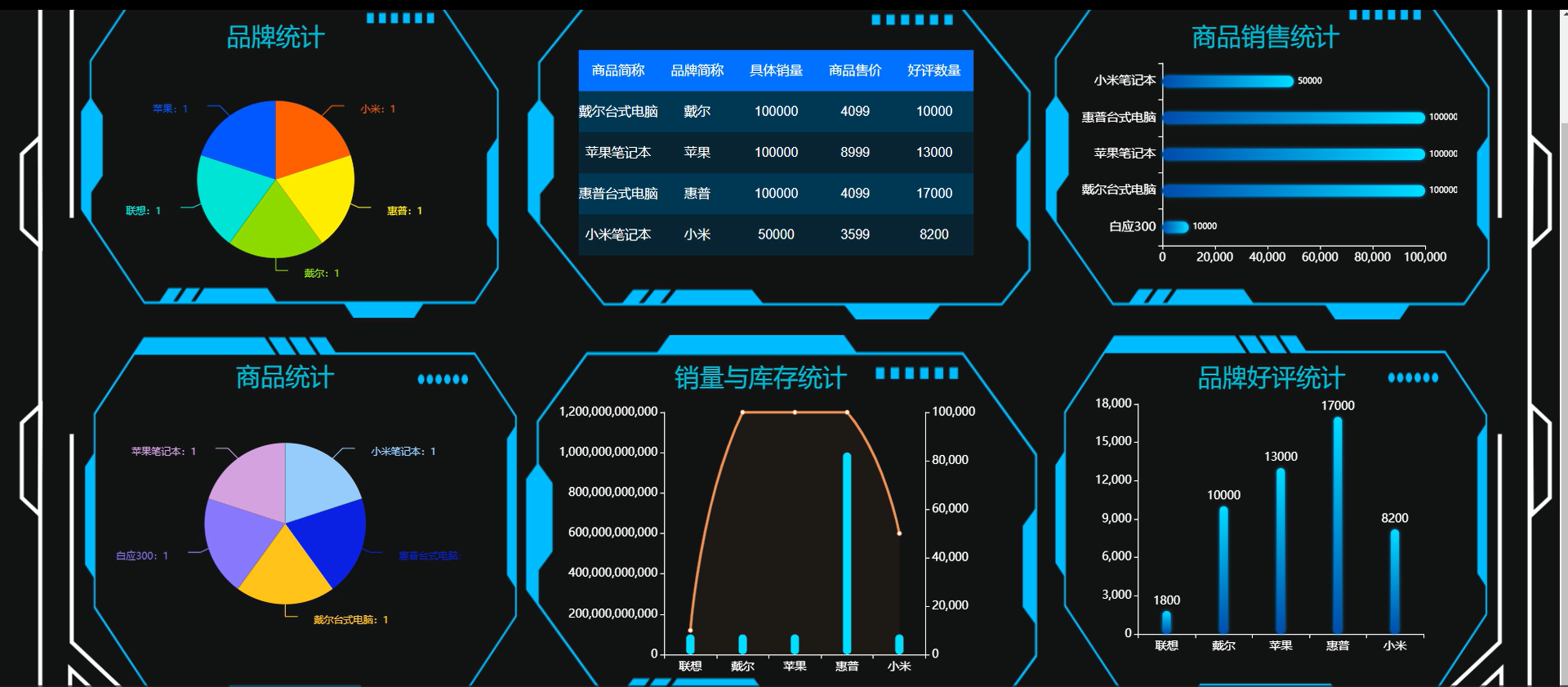
| 数据分析可视化 | 通过 ECharts 查看品牌统计、商品销量与库存统计、品牌好评统计等可视化看板 |
三、程序功能创新点
- 技术融合创新:整合 Hadoop(分布式存储)、Spark(数据处理)、Sqoop(数据迁移)、协同过滤算法,形成 “数据采集 - 清洗 - 分析 - 推荐 - 可视化” 的完整技术链,提升数据处理效率与推荐精准度。
- 双角色功能闭环:既满足普通用户 “购物 + 个性化推荐” 的需求,又为管理员提供 “数据管理 + 多维度统计可视化” 的运营工具,实现用户体验与企业管理的双向优化。
- 精准推荐机制:基于用户历史行为(收藏、点赞、评论、购买),通过协同过滤算法构建用户画像,避免传统推荐的盲目性,提升商品推荐与用户偏好的匹配度。
四、系统架构
系统采用分层架构设计,从数据处理到功能呈现形成清晰流程,核心架构分为以下四层:
数据采集层
- 通过爬虫技术(Requests 库)抓取京东商城商品数据与用户行为数据,将原始 JSON 数据解析为结构化数据。
- 支持增量数据采集,避免重复爬取,同时通过模拟浏览器请求(添加 Header)与控制访问速率(Sleep),防止被接口限制。
数据处理与存储层
- 数据清洗:使用 Spark(PySpark)处理数据重复、缺失、异常值,提升数据质量。
- 数据存储:采用 HDFS(分布式存储海量原始数据)、Hive(数据仓库)、MySQL(存储清洗后结构化数据,如用户信息、订单、商品表)三级存储架构,兼顾存储容量与查询效率。
- 数据迁移:通过 Sqoop 实现 Hadoop 生态(Hive)与 MySQL 之间的数据双向迁移,支撑后续分析与功能调用。
业务逻辑层
- 后端框架:使用 Flask 开发 API 接口,支撑用户登录、商品管理、订单处理等核心业务逻辑;通过 Vue 框架构建管理员后台可视化界面。
- 算法支撑:集成协同过滤算法,基于用户 - 物品交互矩阵计算相似度,生成个性化商品推荐列表。
可视化与交互层
- 前端交互:用户端提供简洁购物界面,管理员端提供数据管理界面。
- 数据可视化:采用 ECharts 模板,将品牌统计、销量库存、好评率等数据以图表形式展示,支持管理员直观获取运营数据。
五、功能截图