STL之stackqueue
stack的介绍(可以想象成栈)
1.stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作
2.stack是作为容器适配器被实现的,容器适配器即是对特点类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素,将特定类作为其底层,元素特定容器的尾部(即栈顶)被压入和弹出
3.stack的底层容器可以是任何标准的容器类模板或者是一些其他特定的容器类,这些容器类应该支持以下操作:
empty() / back / push_back / pop_back
4.标准容器vector/list/deque均符合这些需求,默认情况下,如果没有stack指定特定的底层容器,就使用deque(等会会介绍)
stack的使用
它是一个适配器,就是通过别的容器转换过来的,只是提供一些特定的接口,让其具有栈的特性

特性:LIFO(last-in first-out,后进先出)

可以看到默认使用的模板容器类是deque
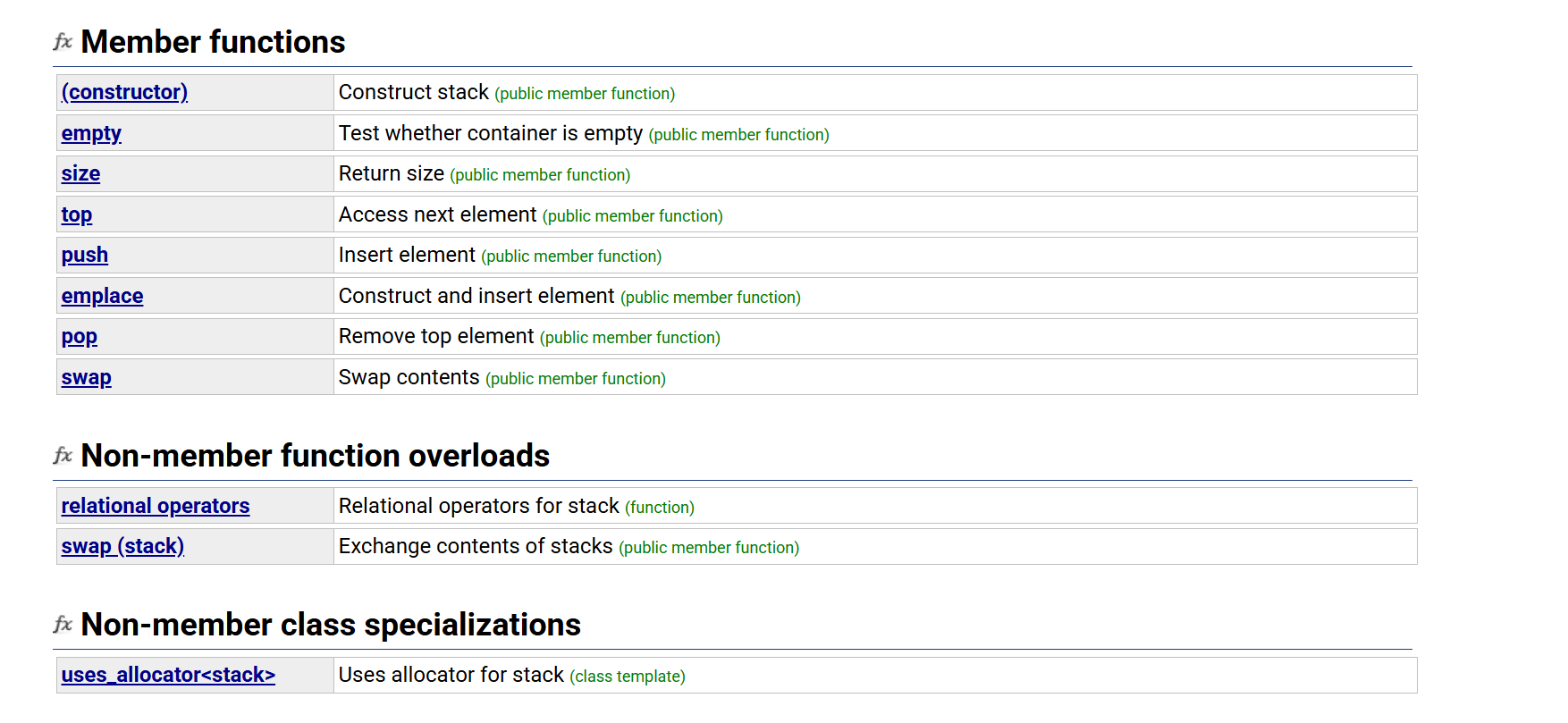
constructor
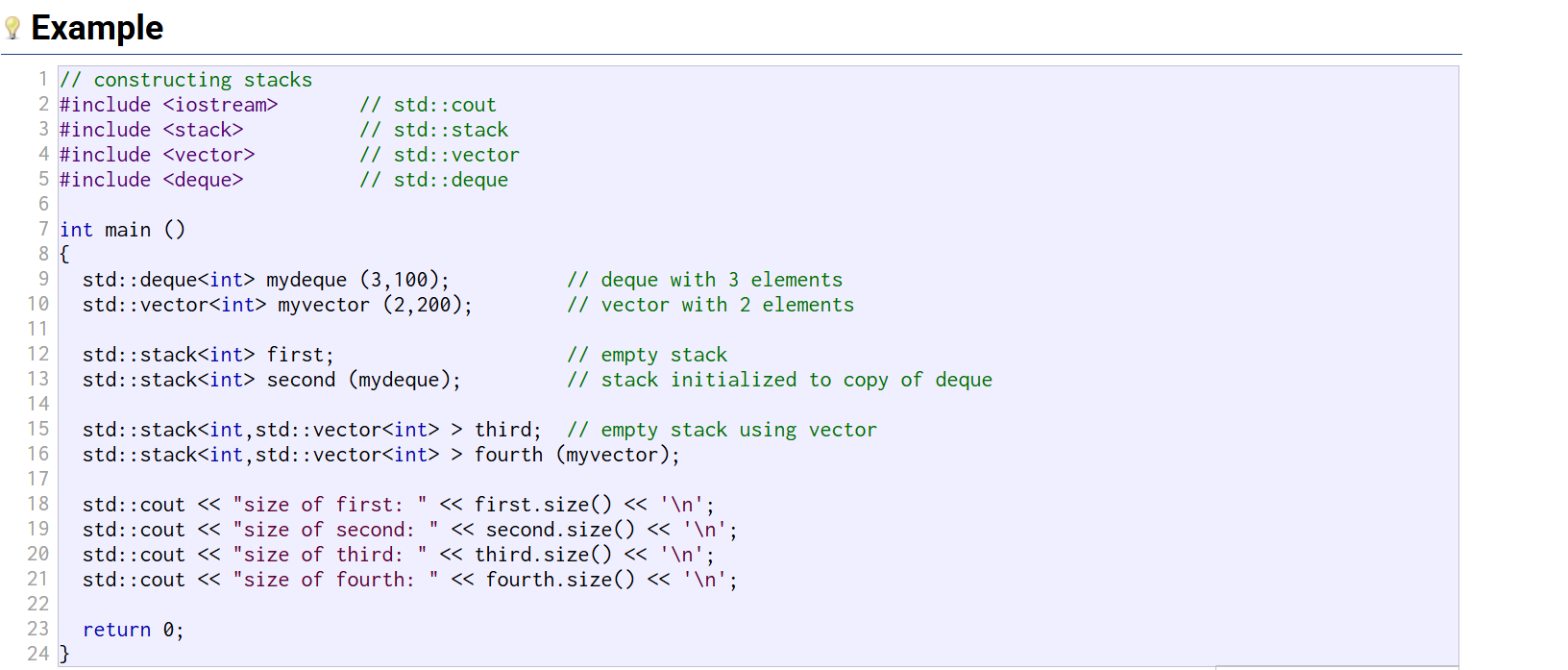
stack<int> s;//构造一个空的对象
如果你想指定你的stack使用的底层容器可以stack<int,vector<int>> s;
三种构造方式:1.构造空的stack对象
2.使用一个模板容器构造,例如你已经构造vector v1对象了,传参可以传v1
3.拷贝构造函数,传一个stack对象
其他重要函数接口
empty():判断是否为空
size():返回栈的元素的个数(返回栈的大小)
top():取栈顶的元素
push():将元素val压入stack中
pop():将栈顶的元素val删除
swap():交换两个栈
总结
1.栈是没有迭代器的,因为栈的特性是先进后出,不能随便访问,所以不支持迭代器
2.如何遍历?先判断为不为空,不为就取栈顶的数据,取完之后pop就行
3.为什么没有析构函数?因为它底层是别的容器,当stack出了作用域自动销毁时会调底层容器的析构函数
queue的介绍(想象成队列):
1.队列是一种容器适配器,专门用于在FIFO(先进先出)中操作,其中从容器的一段插入元素,另一端提取元素
2.队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素,元素从队尾入队列,从对头出队列
3.底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类,该底层容器至少要满足以下操作
empty/ size / front / back /push_back / pop_front
4.deque/list都满足这些要求,如果没有指定,默认使用deque
queue的使用
队列就是一种容器适配器,是基于一些容器实现的特定的接口以满足先进先出的特性

默认使用deque容器
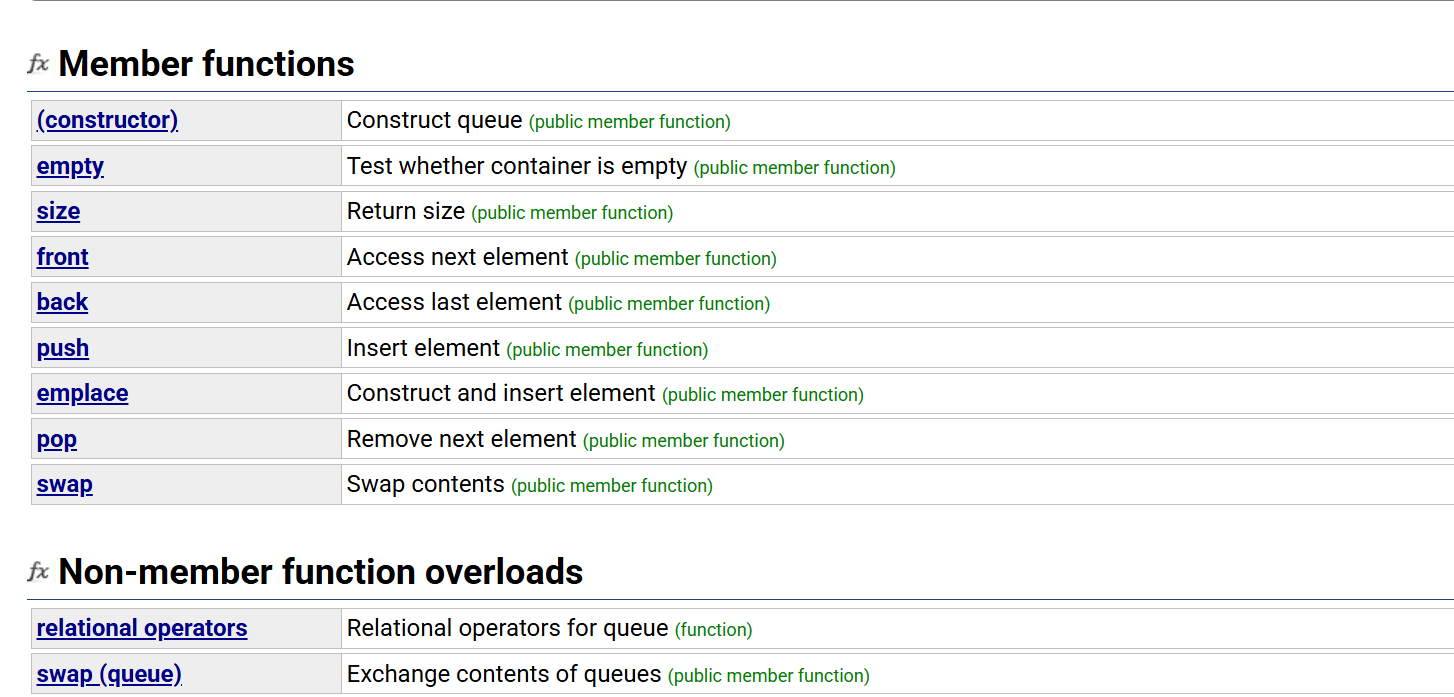
几乎和栈没差别,构造函数,还有一些其他函数接口也几乎一样
区别在于,stack使用top取栈顶数据
queue可以取队头也可以取队尾的数据
front队头,back队尾,top栈顶
而且注意这些都是返回引用,也就是你可以修改
总结:
队列也没有实现迭代器,因为不能支持随机访问,否则就保持不了队列的先进先出的特性
deque的介绍
deque:双端队列,与queue没关系,不要联想到一起,它是一种容器,没有队列先进先出的特性
STL标准库中stack和queue的底层结构:
虽然stack和queue都可以存放元素,但STL并没有将其划入容器的行列,而是将其称为容器适配器,这是因为stack和queue只是对其他容器的的接口进行了包装,STL中的stack和queue默认使用deque
deque(双端队列):是一种双开口的“连续”空间的数据结构,双开口的含义:可以在头尾双端进行插入和删除操作,且时间复杂度为O(1),与vector相比,头插效率高,不需要挪动数据;与list相比,空间利用率比较高
duque的使用
 可以看到它支持头插尾插头删尾删
可以看到它支持头插尾插头删尾删
 可以看到支持迭代器
可以看到支持迭代器
 支持随机访问
支持随机访问
关于deque的使用可以去官网看详细解释,这里只要学明白为什么stack和queue底层用deque
deque的原理
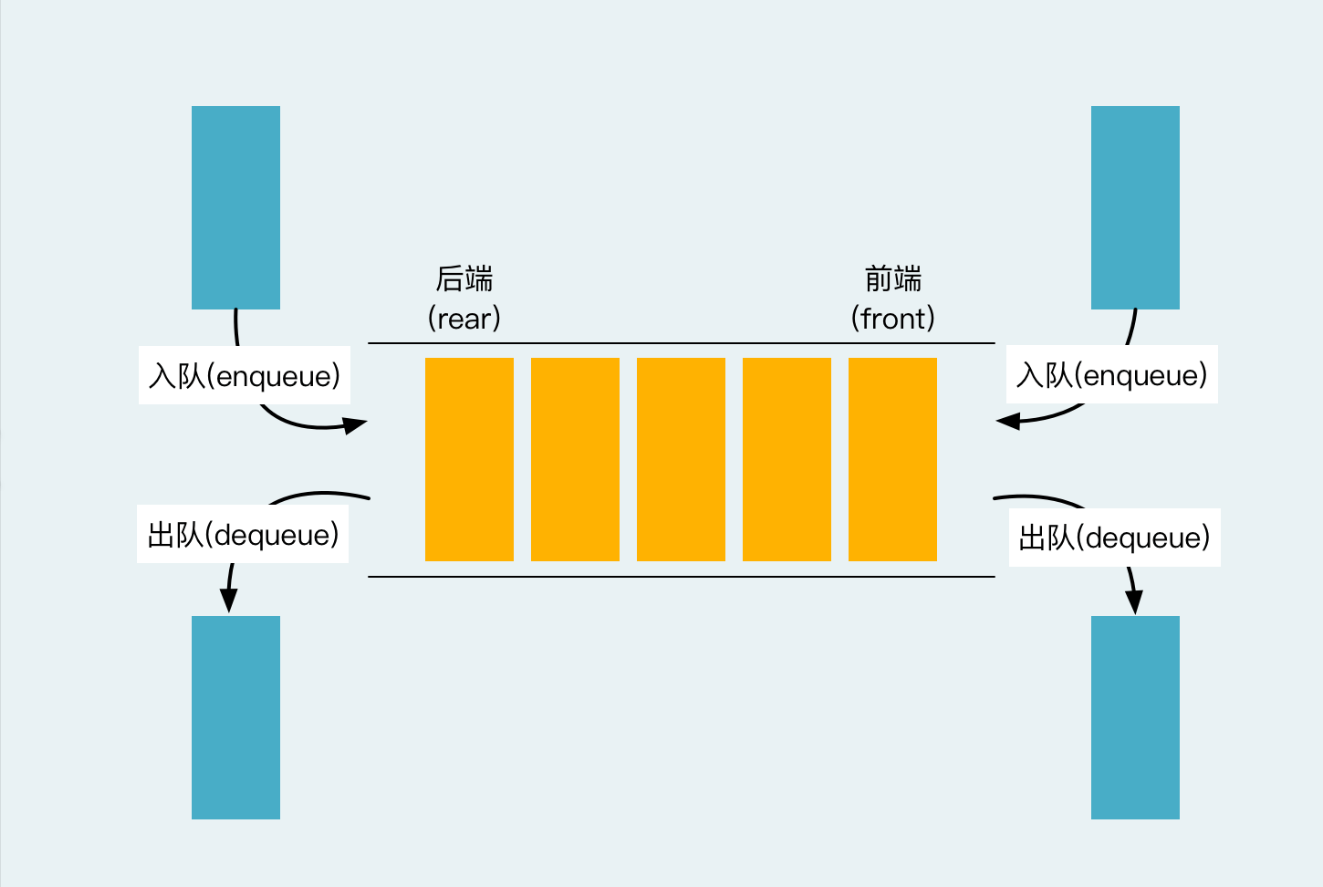
duque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似与一个动态的二维数组,其底层结构如下图所示:
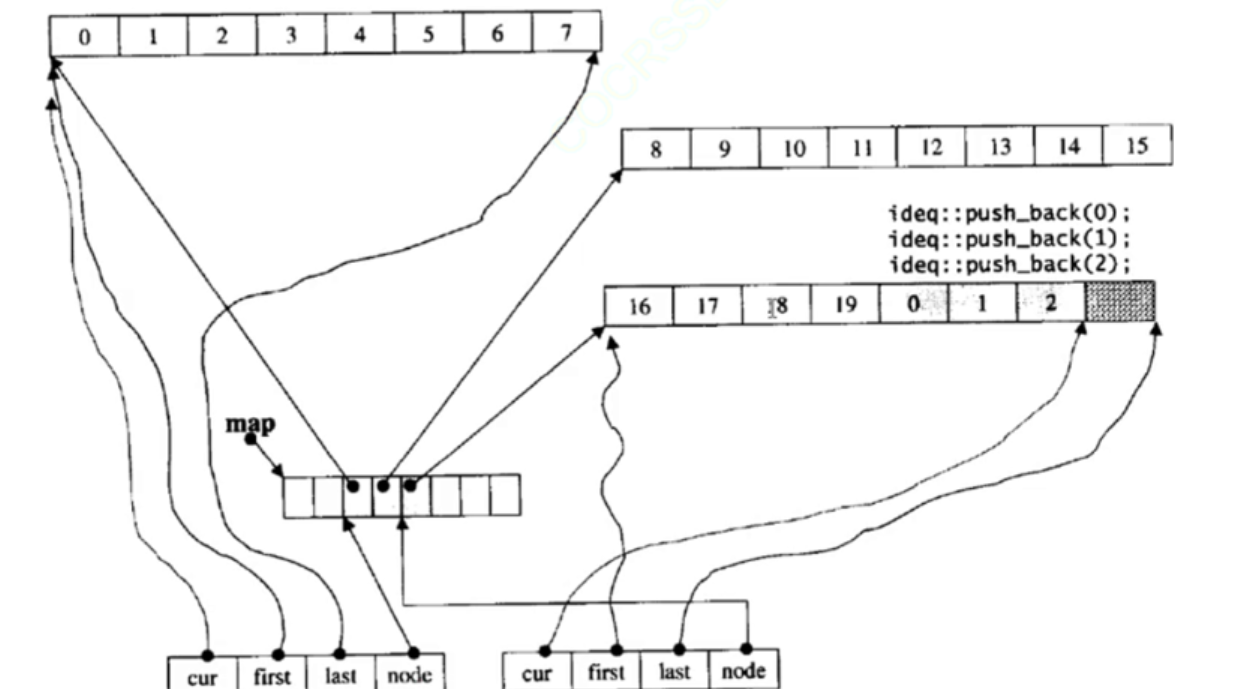
简单来说,deque底层是由一系列固定大小的连续存储块组成,这些存储块叫缓冲区(buffer)
此外,还有一个中控器(通常是一个数组map)存储着指向buffer的指针来管理缓冲区
那它怎么支持随机访问???,这就落在了deque的迭代器身上了,简单来说就是用中控器中的结点,然后用来构造迭代器类型,迭代器里面又有cur first last node等管理,每遍历一个点,cur就往后走,直到last它就遍历结束这一块buffer,遍历完之后node就++就走到下一个结点,然后依次循环下去就是连续遍历
deque的缺陷
与vector相比,deque的优势是:头部插入和删除时,不需要搬移元素,(我们只要在前面多加一个结点,这个结点新开一些buffer,就能解决头插,头删时只要指针指向的位置变就可以)效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是比vector高的,这些可以归结与一个原因,就是vector是连续的物理空间,deque不是连续的,它是通过一个中控器去管理,连续的不够大了就需要重新找一块连续的,而deque不需要
与list相比,deque底层是类似连续的空间,空间利用率高,不需要存储额外的字段,你list每个结点还要存前一个结点和后一个结点的指针
但是deque有一个致命缺陷:不适合遍历,在遍历时,deque的迭代器要频繁的检查是否移动到某段buffer的边界,导致效率低下,而序列式场景中,可能需要经常的遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,这也就是为什么我们没有重点学习deque的接口原因,deque的应用并不多,目前我们能看到的就是stack和queue底层使用deque
为什么选择deque作为stack和queue的底层默认容器
1.stack和queue不需要遍历(因此其没有迭代器),只需要在固定的一端或者两端进行操作,那deque遍历效率低就在stack和queue这没啥影响了
2.在stack中元素增长时,deque比vector效率高(扩容时不需要搬移大量数据),queue中的元素增长时,deque不仅效率高,而且内存使用率也高,也就是无论头插还是尾插,头删还是尾删,deque的效率也不比list和vector低多少,综合而言,结合了deque的优点,避开了其缺陷
stack和list的模拟实现:
June: 这里包含我的c++和Linux及数据结构![]() https://gitee.com/taifanshu/day2.git已经上传gitee,有需要可以自行拿取,代码有问题可以私聊问
https://gitee.com/taifanshu/day2.git已经上传gitee,有需要可以自行拿取,代码有问题可以私聊问