亿级流量系统架构设计与实战(四)
本章关键词 : 读 / 写分离 、 数据缓存 、 缓存更新 、 CQRS 、 数据分片 、 异步写。
高并发架构设计的要点
形成高并发系统的必要条件
高性能、高可用、可扩展。
- 高性能: 性能代表一个系统的并行处理能力,在同样的硬件设备条件下 , 性能越高 , 越能节约硬件资源。
- 高可用: 系统可以长期稳定 、 正常地对外提供服务 , 而不是经常出故障 、 宕机 、崩溃 。
- 可扩展: 系统可以通过水平扩容的方式 , 从容应对请求量的日渐递增乃至突发的请求量激增。
高并发系统的衡量指标
- 高性能指标:
- 响应的平均时间: 在一段时间内系统的平均响应时间 。
- 平均值易受极端值的影响,当出现偏大值时,平均值将会增大;当出现偏小值时 ,平均值将会减小。
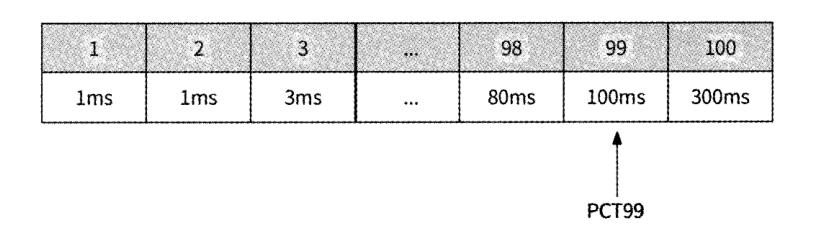
- 响应时间 PCTn 统计方式, PCTn 表示请求响应时间按从小到大排序后第 n 分位的响应时间。
- 假设在一段时间内 100 个请求的响应时间从小到大排序如图所示 , 则第 99 分位的响应时间是 100ms,即 PCT99 = 100ms
- 分位值越大 , 对响应时间长的请求越敏感 。 比如统计 10000 个请求的响应时间 :
- PCT50 =1ms, 表示在 10000 个请求中 50% 的请求响应时间都在 1ms 以内 。
- PCT99 = 800 ms, 表示在 10000 个请求中 99% 的请求响应时间都在 800ms 以内。
- PCT999 = 1.2 s, 表示在 10000 个请求中 99.9% 的请求响应时间都在 1.2s 以内。
- 假设在一段时间内 100 个请求的响应时间从小到大排序如图所示 , 则第 99 分位的响应时间是 100ms,即 PCT99 = 100ms
- 请求的平均响应时间 =200ms, 且 PCT99=1s的高并发系统基本能够满足高性能要求.
- 响应的平均时间: 在一段时间内系统的平均响应时间 。
- 高可用性指标:
- 可用性 = 系统正常运行时间 / 系统总运行时间。一般使用 N 个 9 来描述系统的可用性。

- 高可用性要求系统至少保证 3 个 9 或 4 个 9 的可用性 。 在实际的系统指标监控中 , 很多公司会取 3 个 9 和 4 个 9 的中位数 : 99.95% ( 3 个 9 、 1 个 5 ) , 作为系统可用性监控的阈值 。
- 可扩展性指标:
- 面对到来的突发流量,来不及对系统做架构改造 , 而更快捷 、 有效的做法是增加系统集群中的节点来水平扩展系统的服务能力 。
- 可扩展性=吞吐量提升比例 / 集群节点增加比例 。 在最理想的情况下 ,集群节点增加几倍 , 系统吞吐量就能增加几倍。 一般来说,拥有 70% 〜 80% 可扩展性的系统基本能够满足可扩展性要求
高并发场景分类
各种业务操作体现到数据上就 读和写 两种。
高并发场景也就有** 高并发读、高并发写**。(读多写少、读少写多、读多写多)
并发读场景方案 1 : 数据库读 / 写分离
大部分互联网应用都是读多写少的 , 比如刷帖的请求永远比发帖的请求多 , 浏览商品的请求永远比下单购买商品的请求多 。
数据库承受的高并发请求压力 , 主要来自读请求 。
我们可以把数据库按照读 / 写请求分成专门负责处理写请求的数据库 ( 写库 ) 和专门负责处理读请求的数据库 ( 读库 ) , 让所有的写请求都落到写库 , 写库将写请求处理后的最新数据同步到读库 , 所有的读请求都从读库中读取数据 。
数据库读 / 写分离使大量的读请求从数据库中分离出来 , 减少了数据库访问压力 , 缩短了请求响应时间。
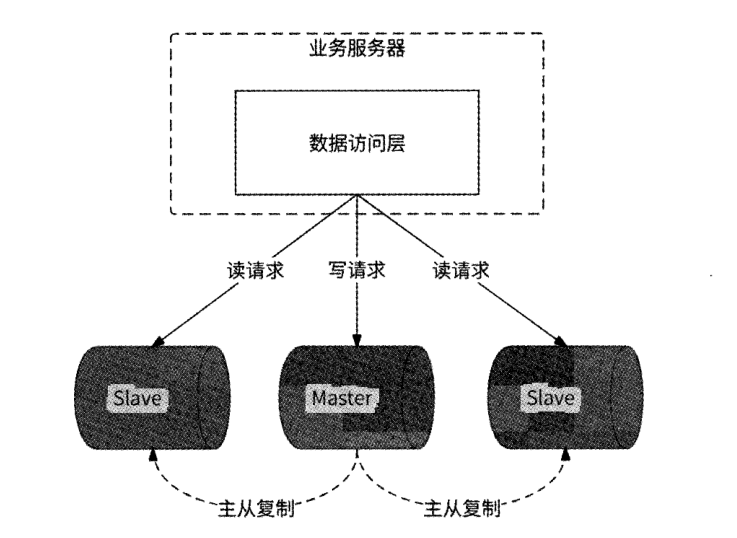
读 / 写分离架构
通常使用数据库主从复制技术实现读 / 写分离架构 , 将数据库主节点 Master 作为“ 写库 ” , 将数据库从节点 Slave 作为 “ 读库 ” , 一个 Master 可以与多个 Slave 连接。
读/写请求路由方式
在数据库读 / 写分离架构下 , 把写请求交给 Master 处理 , 而把读请求交给 Slave 处理,那么由什么角色来执行这样的读 / 写请求路由呢 ?
- 基于数据库 Proxy 代理的方式
- 在业务服务和数据库服务器之间增加数据库 Proxy 代理节点 ( 下文简称 Proxy ) , 业务服务对数据库的一切操作都需要经过 Proxy 转发 。 Proxy 收到业务服务的数据库操作请求后 , 根据请求中的 SQL 语句进行归类 , 将属于写操作的请求 ( 如 insert/delete/update 语句 )转发到数据库 Master, 将属于