【LDM】视觉自回归建模:通过Next-Scale预测生成可扩展图像(NeurIPS2024最佳论文阅读笔记与吃瓜)
【LDM】视觉自回归建模:通过Next-Scale预测生成可扩展图像(NeurIPS2024最佳论文阅读笔记与吃瓜)
《Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction》
视觉自回归建模:通过Next-Scale预测生成可扩展图像
文章目录
- 1、吃瓜:tky事件,NeurIPS与最佳论文
- 2、论文:摘要,正文,结论
- 3、导读:文章核心内容总结

1、吃瓜:tky事件,NeurIPS与最佳论文
去年的瓜,当时就关注了下,后来一直没空看,就咕咕咕,最近在看AI相关的内容,突然想起来了,就来填一个远古的坑 1, 2 , tkygithub,
吃瓜时间线
- 10月,有消息称,字节跳动某实习生破坏了大模型训练代码,造成严重后果。后来,字节内部人士证实,确有此事,实习生已经被辞退,名为田柯宇。
- 本来,字节只是将田柯宇退回,让学校处理,并没有追究他的经济赔偿。但是,田柯宇后来多次表示,自己发完论文后,就从字节离职了,是另一个人篡改了模型代码,并将过失扣到了自己头上。
- 11月底,有媒体报道称,字节跳动请求法院判令田某某赔偿公司侵权损失 800 万元及合理支出 2 万元,并公开赔礼道歉。
- 正当大模型老板们都在感叹,这样的员工技术再好也不能用时,田柯宇又用科研论文在研究领域狠狠扳回了一分,获得NeurIPS2024最佳论文奖。
NeurIPS最佳论文的含金量
- 神经信息处理系统大会(NIPS, NeurIPS ,Conference and Workshop on Neural Information Processing Systems),是一个关于机器学习和计算神经科学的国际会议。nips官网
- 该会议位列CCFA。与ICML,ICLR并称为机器学习领域难度最大,水平最高,影响力最强的会议三大会议。1
- 头部计划seed,PAAI,青云计划,群星未来之夜,豆包火种之夜,线下邀请函,年薪高达165w+
- NeurIPS 2024 将于 12 月 10 日星期二至 12 月 15 日星期日在温哥华举办。
- NeurIPS 2024 年共接收了 15671 篇论文(比去年又增长了27%),录取率为25.8%(去年为 26.1%),大概 4043 篇左右。1, 2, 3
- 公开数据显示,中国人民大学、字节跳动、蚂蚁集团、腾讯等中国高校和互联网企业均分别有数十篇论文被NeurIPS 2024收录。 蚂蚁集团被 NeurIPS 2024 收录了20篇论文,其中有一篇为Spotlight(特别关注)。按往年数据估算,NeurIPS 的 Spotlight 论文录取率约为 3%。 1
- 在这4000多篇论文中,一共有两篇论文获得最佳论文奖, 其中一篇就是tky的《Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction》(视觉自回归建模:通过Next-Scale预测生成可扩展图像),1


2、论文:摘要,正文,结论
项目模型和代码,论文正式版 , 预印本
参考资料:1, 2,
背景介绍
- 在自然语言处理中,以 GPT、LLaMa 系列等大语言模型为例的 Autoregressive 自回归模型已经取得了较大的成功,尤其 Scaling Law 缩放定律和 Zero-shot Task Generalizability 零样本任务泛化能力十分亮眼,初步展示出通往「通用人工智能 AGI」的潜力。
- 然而在图像生成领域中,自回归模型却广泛落后于扩散(Diffusion)模型:近期持续刷屏的 DALL-E3、Stable Diffusion3、SORA 等模型均属于 Diffusion 家族。此外,对于视觉生成领域是否存在「Scaling Law 缩放定律」仍未知,即测试集损失是否随模型或训练开销增长而呈现出可预测的幂律 (Power-law) 下降趋势仍待探索。GPT 形式自回归模型的强大能力与 Scaling Law,在图像生成领域,似乎被「锁」住了。
- 剑指「解锁」自回归模型的能力和 Scaling Laws,研究团队从图像模态内在本质出发,模仿人类处理图像的逻辑顺序,提出一套全新的「视觉自回归」生成范式:VAR, Visual AutoRegressive Modeling,首次使得 GPT 风格的自回归视觉生成,在效果、速度、Scaling 能力多方面超越 Diffusion,并迎来了视觉生成领域的 Scaling Laws。
实现方案
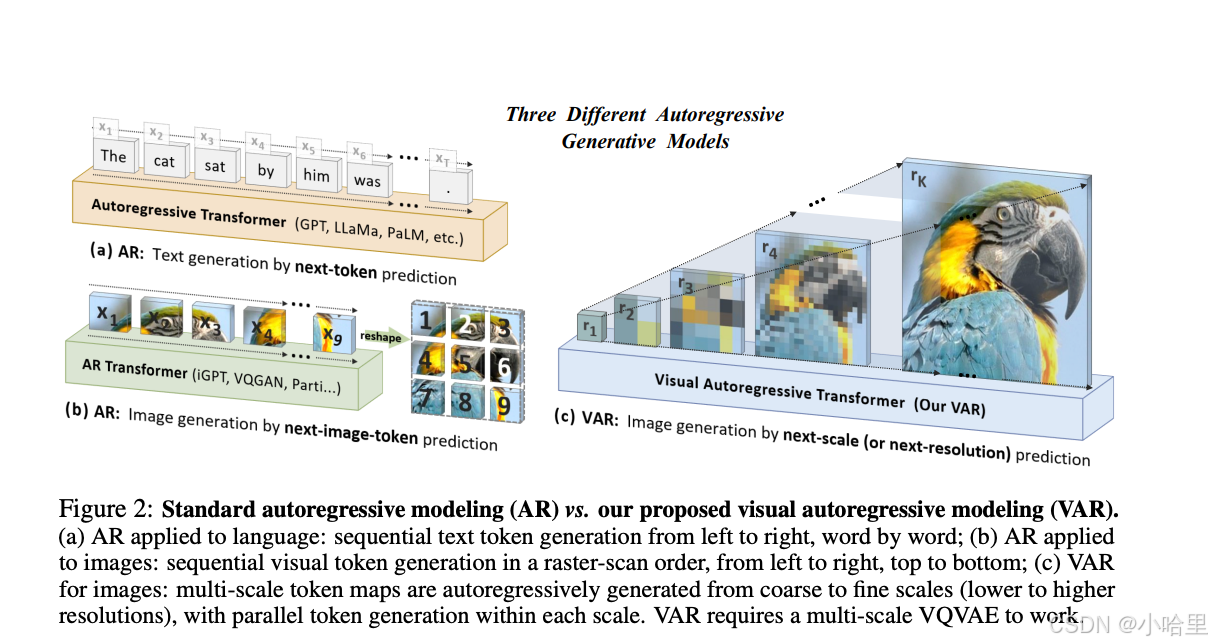
- VAR 方法核心:模仿人类视觉,重新定义图像自回归顺序
人类在感知图像或进行绘画时,往往先概览全局、再深入细节。这种由粗到细、从把握整体到精调局部的思想非常自然。然而,传统的图像自回归(AR)却使用一种不符合人类直觉(但适合计算机处理)的顺序,即自上而下、逐行扫描的光栅顺序(或称 raster-scan 顺序),来逐个预测图像。 - VAR 则「以人为本」,模仿人感知或人创造图像的逻辑顺序。
使用从整体到细节的多尺度顺序逐渐生成 token map。一个显著优势是大幅提高了生成速度:在自回归的每一步(每一个尺度内部),所有图像 token 是一次性并行生成的;跨尺度则是自回归的。这使得在模型参数和图片尺寸相当的情况下,VAR 能比传统 AR 快数十倍。 - VAR 方法细节:两阶段训练
VAR 在第一阶段训练一个多尺度量化自动编码器(Multi-scale VQVAE),在第二阶段训练一个与 GPT-2 结构一致(结合使用 AdaLN)的自回归 Transformer。 - 作者表示,VAR 的自回归框架是全新的
而具体技术方面则吸收了 RQ-VAE 的残差 VAE、StyleGAN 与 DiT 的 AdaLN、PGGAN 的 progressive training 等一系列经典技术的长处。VAR 实际是站在巨人的肩膀上,聚焦于自回归算法本身的创新。
实验效果对比
- VAR 在 Conditional ImageNet 256x256 和 512x512 上进行实验:
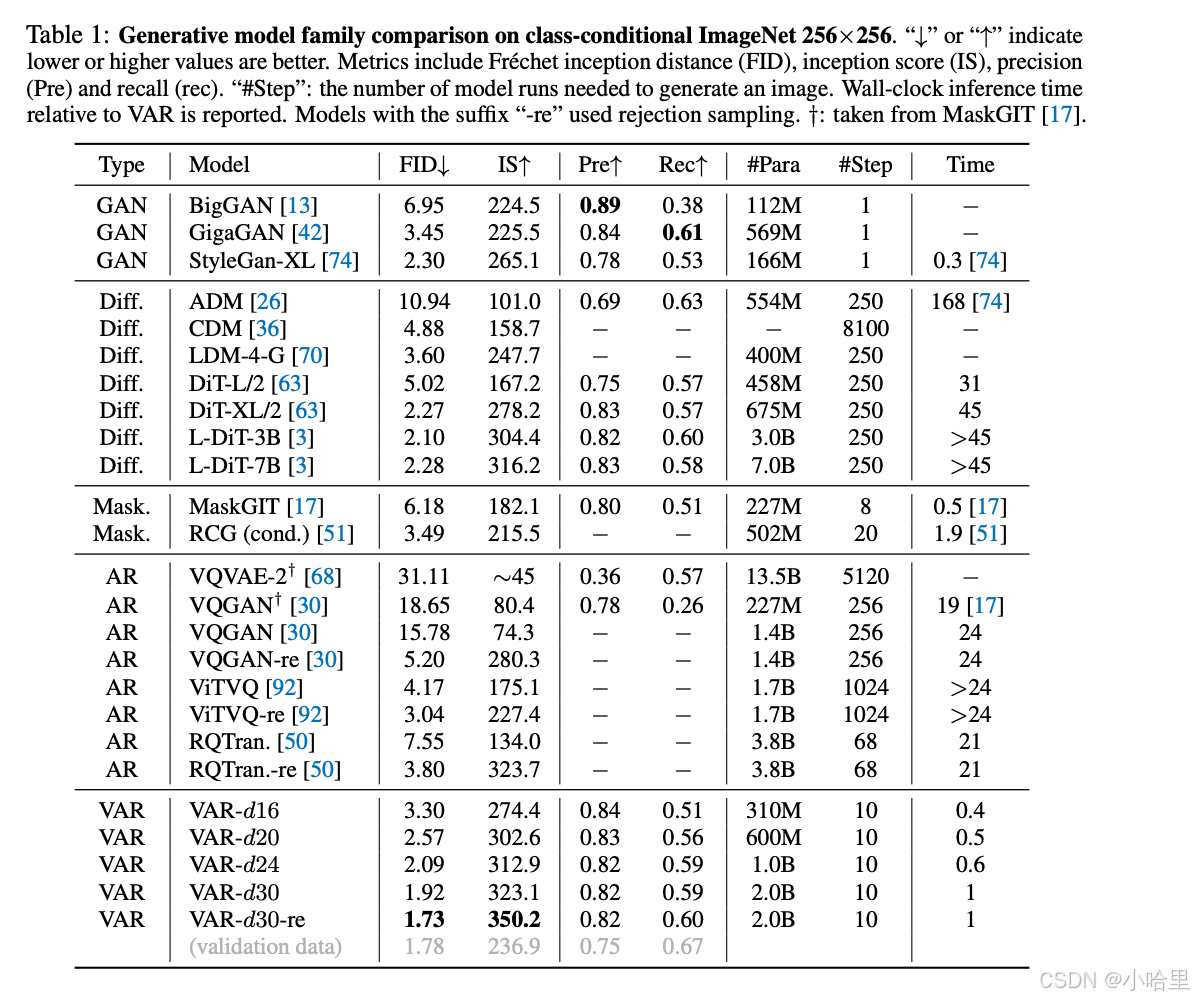
VAR 大幅提升了 AR 的效果,一转 AR 落后于 Diffusion 的局面
VAR 仅需 10 步自回归步骤,生成速度大幅超过 AR、Diffusion,甚至逼近 GAN 的高效率
通过 Scale up VAR 直至 2B/3B,VAR 达到了 SOTA 水平,展现出一个全新的、有潜力的生成模型家族。 - 通过与 SORA、Stable Diffusion 3 的基石模型 Diffusion Transformer(DiT)对比:
更好效果:经过 scale up,VAR 最终达到 FID=1.80,逼近理论上的 FID 下限 1.78(ImageNet validation set),显著优于 DiT 最优的 2.10
更快速度:VAR 只需不到 0.3 秒即可生成一张 256 图像,速度是 DiT 的 45 倍;在 512 上更是 DiT 的 81 倍
更好 Scaling 能力:如左图所示,DiT 大模型在增长至 3B、7B 后体现出饱和现象,无法靠近 FID 下限;而 VAR 经过缩放到 20 亿参数,性能不断提升,最终触及 FID 下限
更高效的数据利用:VAR 仅需 350 epoch 训练即超过 DiT 1400 epoch 训练 - Scaling Law 实验
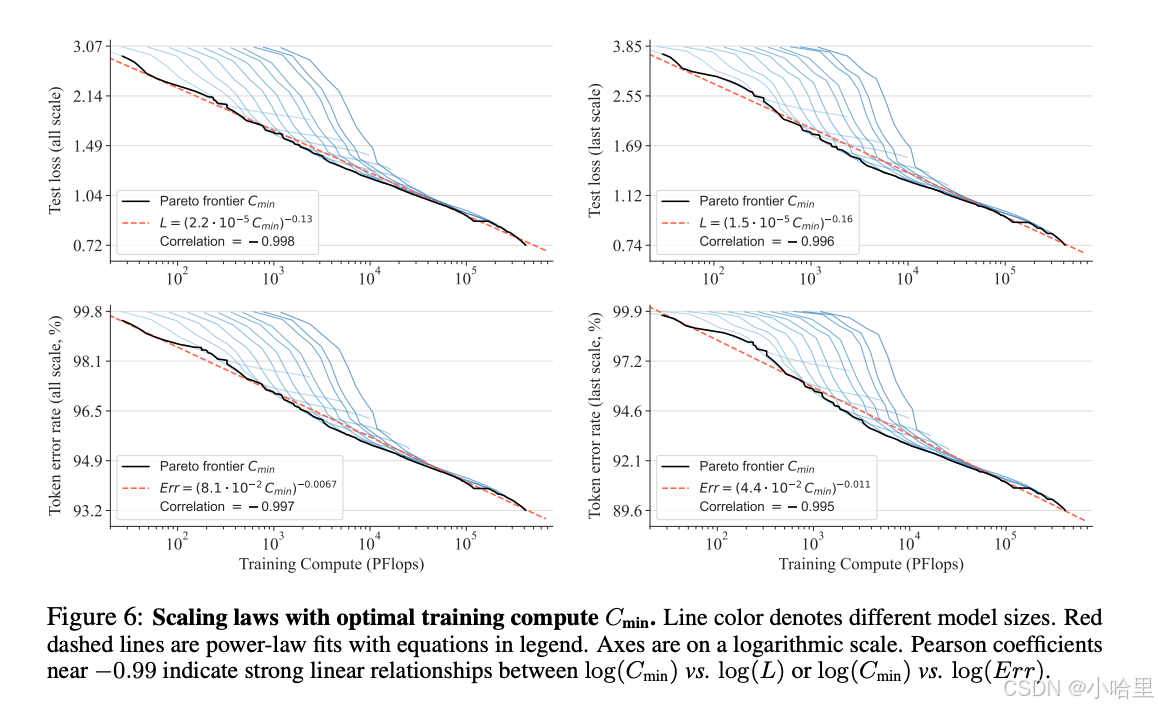
Scaling law 可谓是大语言模型的「皇冠明珠」。相关研究已经确定,在 Scale up 自回归大型语言模型过程中,测试集上的交叉熵损失 L,会随着模型参数量 N、训练 token 个数 T,以及计算开销 Cmin 进行可预测的降低,呈现出幂律(Power-law)关系。
通过实验,研究者观察到了 VAR 展现出与 LLM 几乎完全一致的幂律 Scaling Law:研究者训练了 12 种大小的模型,缩放模型参数量从 1800 万到 20 亿,总计算量横跨 6 个数量级,最大总 token 数达到 3050 亿,并观察到测试集损失 L 或测试集错误率 与 N 之间、L 与 Cmin 之间展现出平滑的的幂律关系,并拟合良好 - Zero-shot 实验
得益于自回归模型能够使用 Teacher-forcing 机制强行指定部分 token 不变的这一优良性质,VAR 也展现出一定的零样本任务泛化能力。在条件生成任务上训练好的 VAR Transformer,不通过任何微调即可零样本泛化到一些生成式任务中,例如图像补全(inpainting)、图像外插(outpainting)、图像编辑(class-condition editing),并取得一定效果
结论
- VAR 为如何定义图像的自回归顺序提供了一个全新的视角,即由粗到细、由全局轮廓到局部精调的顺序。在符合直觉的同时,这样的自回归算法带来了很好的效果:VAR 显著提升自回归模型的速度和生成质量,在多方面使得自回归模型首次超越扩散模型。
3、导读:文章核心内容总结
本节来源 ,AI总结
1. 核心思想
- Next-Scale Prediction(下一尺度预测):
传统自回归模型(如PixelRNN)逐像素生成图像,计算效率低且难以捕获长程依赖。本文提出按尺度渐进生成:先生成低分辨率图像,再逐步预测更高分辨率的细节,形成层级生成过程。 - 自回归的跨尺度扩展:
将自回归建模从像素空间转移到尺度空间,每个步骤基于当前尺度的图像预测下一尺度的残差细节,而非直接生成完整图像。
2. 关键技术
- 多尺度图像分解:
将图像分解为不同尺度的金字塔表示(如从64×64→128×128→256×256…),每个尺度对应一组残差特征。 - 条件自回归建模:
使用Transformer或CNN模型,以当前尺度图像为条件,预测下一尺度的残差(即Δ = Next_Scale − Current_Scale)。 - 渐进训练策略:
分阶段训练模型,先训练低尺度生成,再逐步扩展到高尺度,避免直接处理高分辨率数据的复杂性。
3. 优势与创新
- 可扩展性:
通过分尺度生成,显著降低计算复杂度,支持生成超高分辨率图像(如1024×1024以上)。 - 细粒度控制:
用户可通过干预中间尺度的生成结果(如草图→细节),实现可控的图像编辑。 - 高质量生成:
相比传统自回归模型,能更好地捕获全局结构和局部细节的关联。
4. 应用场景
- 高分辨率图像合成:适用于艺术创作、游戏素材生成等。
- 图像编辑与修复:基于中间尺度结果进行局部修改(如替换物体、修复遮挡区域)。
- 多模态生成:与文本/布局条件结合,实现文本到图像的精准生成。
5. 对比现有方法
- vs 扩散模型(Diffusion):
扩散模型通过迭代去噪生成图像,计算成本高;而分尺度自回归能更高效地利用层级结构。 - vs 传统自回归模型(如PixelCNN):
避免了逐像素生成的序列过长问题,通过尺度跳跃加速推理。 - vs GANs:
避免了模式坍塌问题,生成结果更稳定,且支持渐进式编辑。
6. 未来方向
- 与潜在扩散结合:在潜在空间进行分尺度自回归,进一步提升效率。
- 动态尺度调度:根据图像内容自适应选择下一生成尺度,优化资源分配。
该方法通过尺度维度重新思考自回归建模,为大规模图像生成提供了新的平衡点——在生成质量、计算效率和可控性之间取得了显著改进。