【计算机网络-应用层】HTTP服务器原理理解以及C++编写
📚 博主的专栏
🐧 Linux | 🖥️ C++ | 📊 数据结构 | 💡C++ 算法 | 🅒 C 语言 | 🌐 计算机网络
上篇文章:基于C++与JSON的自定义协议实现——构建网络版计算器
下篇文章: HTTP下,继续HTTP未完成内容,GET,POST方法等
本篇文章所讲到的Http.hpp完整代码,在文章末尾
摘要:本文深入解析HTTP协议核心原理,涵盖请求/响应格式、URL编码、状态码等关键概念,并基于C++手把手实现轻量级HTTP服务器。通过反序列化请求、构建响应报文、处理资源路径及文件类型(如HTML、图片),演示如何解析GET请求、管理Content-Type与Content-Length头部字段,并适配状态码(如200、404)。文章结合Fiddler抓包工具分析通信流程,探讨Host、User-Agent等头部字段作用,最终实现静态资源托管与动态响应生成,为网络编程与协议开发提供实践指南。
目录
HTTP 协议
认识 **URL**--->统一资源定位符(标识互联网中唯一的资源)
编码(做了解)
使用代码见http请求和应答
Http请求格式:
Http响应格式:
代码编写
HttpRequest类(编写分成三次,“做三次反序列化”)
HttpRequest类 --->代码中做这样的增加:(注意这里的代码不全)
HttpRequest类
Response类的编写:
HttpResponse类:
Content-Length属性:实体主体的字节大小
GET:
content-type属性:
Fiddler:
抓包:?
HOST属性:
总结一下Header:
关于 connection 报头
语法格式
HTTP 请求和服务器应答的版本的意义:
HTTP状态码和状态码描述
HTTP状态码
Http.hpp完整代码:下篇文章继续使用
HTTP 协议
- 虽然我们说, 应用层协议是我们程序猿自己定的. 但实际上, 已经有大佬们定义了一些现成的, 又非常好用的应用层协议, 供我们直接参考使用. HTTP(超文本传输协议)就是其中之一。
- 在互联网世界中, HTTP(HyperText Transfer Protocol, 超文本传输协议) 是一个至关重要的协议。 它定义了客户端(如浏览器) 与服务器之间如何通信, 以交换或传输超文本(如 HTML 文档) 。
- HTTP 协议是客户端与服务器之间通信的基础。 客户端通过 HTTP 协议向服务器发送请求, 服务器收到请求后处理并返回响应。 HTTP 协议是一个无连接、 无状态的协议, 即每次请求都需要建立新的连接, 且服务器不会保存客户端的状态信息。
补充:手机上许多App,电脑客户端程序、以及浏览器内部要通信都必须用Http/Https,Http属于应用层协议,但是底层使用的是TCP协议(是面向连接的),但为什么 HTTP为什么是一个无连接的,HTTP是用TCP,TCP建的是自己的和HTTP没有关系,并且他们还是分层的。无状态是:HTTP核心工作是间进行:数据、超文本,服务器和主机之间的交换的,不需要记录客户端状态信息。
认识 **URL**--->统一资源定位符(标识互联网中唯一的资源)
平时我们俗称的 "网址" 其实就是说的 URL,现在大多都使用https,并且端口号默认忽略了

需要注意的:
域名 ------> 自动转换成IP地址-------> DNS(地址转化)
所有服务器必须绑定80的端口
协议名称端口号是强关联的
当浏览器发起请求时,会自动拼接端口号80
资源:超文本、资源(网页,图片、视频、音频)。
进程间通信的本质是IO问题,HTTP属于网络协议,浏览器是客户端,Http将来要匹配实现Http协议的服务器端。
url标识该主机上的唯一一个文件资源,用域名区分主机唯一性,用路径区分资源唯一性
端口号80表示当前主机上的唯一的一个服务进程。
没有获得资源时,所有的资源都在服务器端。其实是我们用协议Http或其他,将服务器的资源再根据客户的需求(通过url标识出来),http再在服务器中找到,再在服务器中打开并且通过http网络推送给客户端。
所有资源都在服务器端,也就是说所有资源都在云服务器上,云服务器就是我们的后端服务器上一般都是linux,对于网页、图片等资源对于linux来说都是文件,看是二进制的还是文本的也就是超文本的,包括文本但不限于文本的文件资源。推送资源的前提是打开资源,打开资源的前提是能够在本主机上找到对应的资源。在linux中就是根据路径来找寻。
因此在url后半部分对应的就是一个资源路径。第一个/是web根目录,可以是linux中任何一个目录。但是都可以表示文件的唯一性。
编码(做了解)
正常输入,做变量的值,输入特殊字符,会被浏览器自动编码(urlencode)用户提交的参数被编码,为了防止url链接出现问题。最后浏览器再decode给服务器。未来也有可能需要自己转码,网上都有许多转码方式。
使用代码见http请求和应答
所需文件,都是之前博客所讲过的原代码:
修改上篇博客所讲解的:Tcpserver.hpp
#pragma once
#include "Socket.hpp"
#include "InetAddr.hpp"
#include <functional>
// 设置函数对象using namespace socket_ns;
static const int gport = 8888;using service_t = std::function<std::string(std::string &resqueststr)>;class TcpServer
{public:TcpServer(service_t service, uint16_t port = gport): _port(port), _listensock(std::make_shared<TcpSocket>()), _isrunning(false), _service(service){_listensock->BuildListenSocket(_port);}class ThreadData{public:SockSPtr _sockfd;TcpServer *_self;InetAddr _addr; // 给InetAddr再添加一个无参构造public:ThreadData(SockSPtr sockfd, TcpServer *self, const InetAddr &addr) : _sockfd(sockfd), _self(self), _addr(addr){}};void Loop(){// signal(SIGCHLD, SIG_IGN);_isrunning = true;while (_isrunning){InetAddr client;SockSPtr newsock = _listensock->Accepter(&client);if (newsock == nullptr){continue;}LOG(INFO, "get a new link, client info : %s, sockfd is: %d\n", client.AddrStr().c_str(), newsock->Sockfd());// version2-----多线程版本 --- 不能关闭fd,也不需要pthread_t tid;ThreadData *td = new ThreadData(newsock, this, client);pthread_create(&tid, nullptr, Execute, td);}_isrunning = false;}//执行static void *Execute(void *args){pthread_detach(pthread_self());ThreadData *td = static_cast<ThreadData *>(args);std::string requeststr;// 我们后面不做请求的分离了,我们认为我们读到的是一个完整的请求--bugssize_t n = td->_sockfd->Recv(&requeststr);if (n > 0){// 直接回调我们定义的函数对象,把请求字符串给我,我在service进行处理std::string responsestr = td->_self->_service(requeststr);//返回一个序列化之后的responsestrtd->_sockfd->Send(responsestr); }// 处理完了,直接关闭td->_sockfd->Close();delete td;return nullptr;}~TcpServer(){}private:uint16_t _port;// int _listensockfd;// 定义套接字对象SockSPtr _listensock;bool _isrunning;service_t _service;
};
所做的修改集中在:因为我现在的客户端是浏览器,我想接收道浏览器给我发送的请求
//执行static void *Execute(void *args){pthread_detach(pthread_self());ThreadData *td = static_cast<ThreadData *>(args);std::string requeststr;// 我们后面不做请求的分离了,我们认为我们读到的是一个完整的请求--bugssize_t n = td->_sockfd->Recv(&requeststr);if (n > 0){// 直接回调我们定义的函数对象,把请求字符串给我,我在service进行处理std::string responsestr = td->_self->_service(requeststr);//返回一个序列化之后的responsestrtd->_sockfd->Send(responsestr); }// 处理完了,直接关闭td->_sockfd->Close();delete td;return nullptr;}创建Http.hpp
#pragma once
#include <iostream>#include<string>class HttpServer
{public:HttpServer(){}std::string HandlerHttpRequest(std::string &reqstr){ std::cout << "---------------------------------------" <<std::endl;std::cout << reqstr;return std::string(); }~HttpServer(){}
};ServerMain.cc:
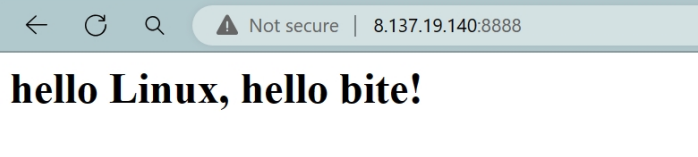
//会话层,只有一个tcp服务器-->进行基本的tcp管理 #include "TcpServer.hpp" //能够读到http字符串 #include "Http.hpp"// ./tcpserver 8888 int main(int argc, char *argv[]) {if (argc != 2){std::cerr << "Usage: " << argv[0] << " local-port" << std::endl;exit(0);}uint16_t port = std::stoi(argv[1]);HttpServer hserver;// //构建TCP服务器std::unique_ptr<TcpServer> tsvr = std::make_unique<TcpServer>(std::bind(&HttpServer::HandlerHttpRequest, &hserver, std::placeholders::_1), port);tsvr->Loop();return 0; }从网页读取到服务器:我们在网页当中输入我的ip加上我运行时所写的端口号
这个就叫做Http请求

User-Agent:客户端信息
服务器给客户端传回信息:
#pragma once #include <iostream>#include<string>class HttpServer {public:HttpServer(){}std::string HandlerHttpRequest(std::string &reqstr){ std::cout << "---------------------------------------" <<std::endl;std::cout << reqstr;std::string responsestr = "HTTP/1.1 200 OK\r\n";responsestr += "Content-Type: text/html\r\n";responsestr += "\r\n";responsestr += "<html><h1>hello Linux, hello bite!</h1></html>";return responsestr; }~HttpServer(){} };运行结果:
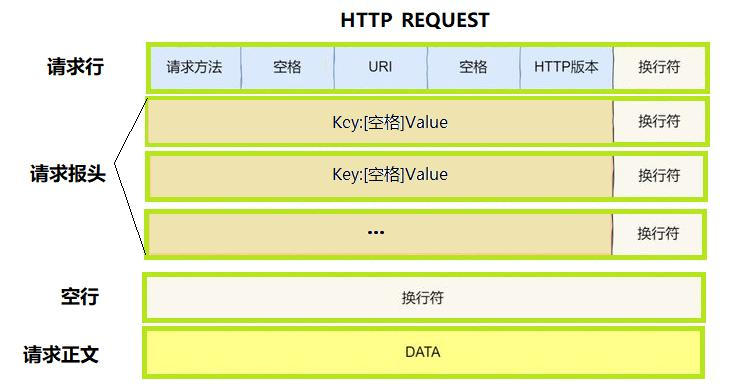
Http请求格式:
• 首行: [方法] + [url] + [版本]
• Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\r\n 分隔;遇到空行表示 Header 部分结束
• Body: 空行后面的内容都是 Body. Body 允许为空字符串. 如果 Body 存在, 则在Header 中会有一个 Content-Length 属性来标识 Body 的长度;
一个完整的http请求基本格式是上图所示,请求所有的内容都是以行为单位陈列,除了请求正文(可选、可写可不写)。
请求行
请求方法:GET(80%使用)、POST、DELETE、HEAD.....
URI(uri):一般是url的后半部分,携带的是要访问资源的路径
HTTP版本:http/1.0(文章用的1.0) http/1.1(主流使用) http/2.0
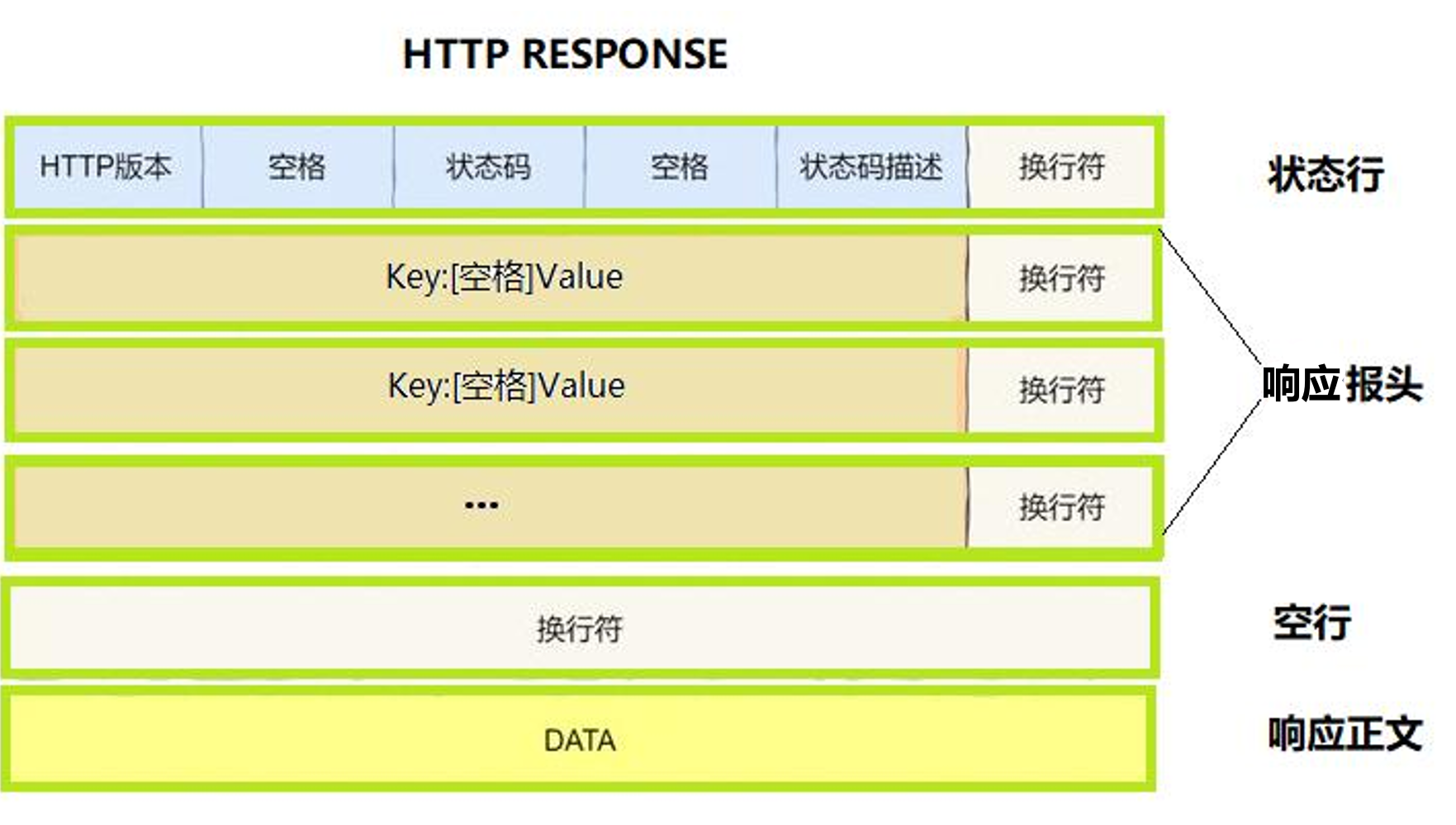
Http响应格式:
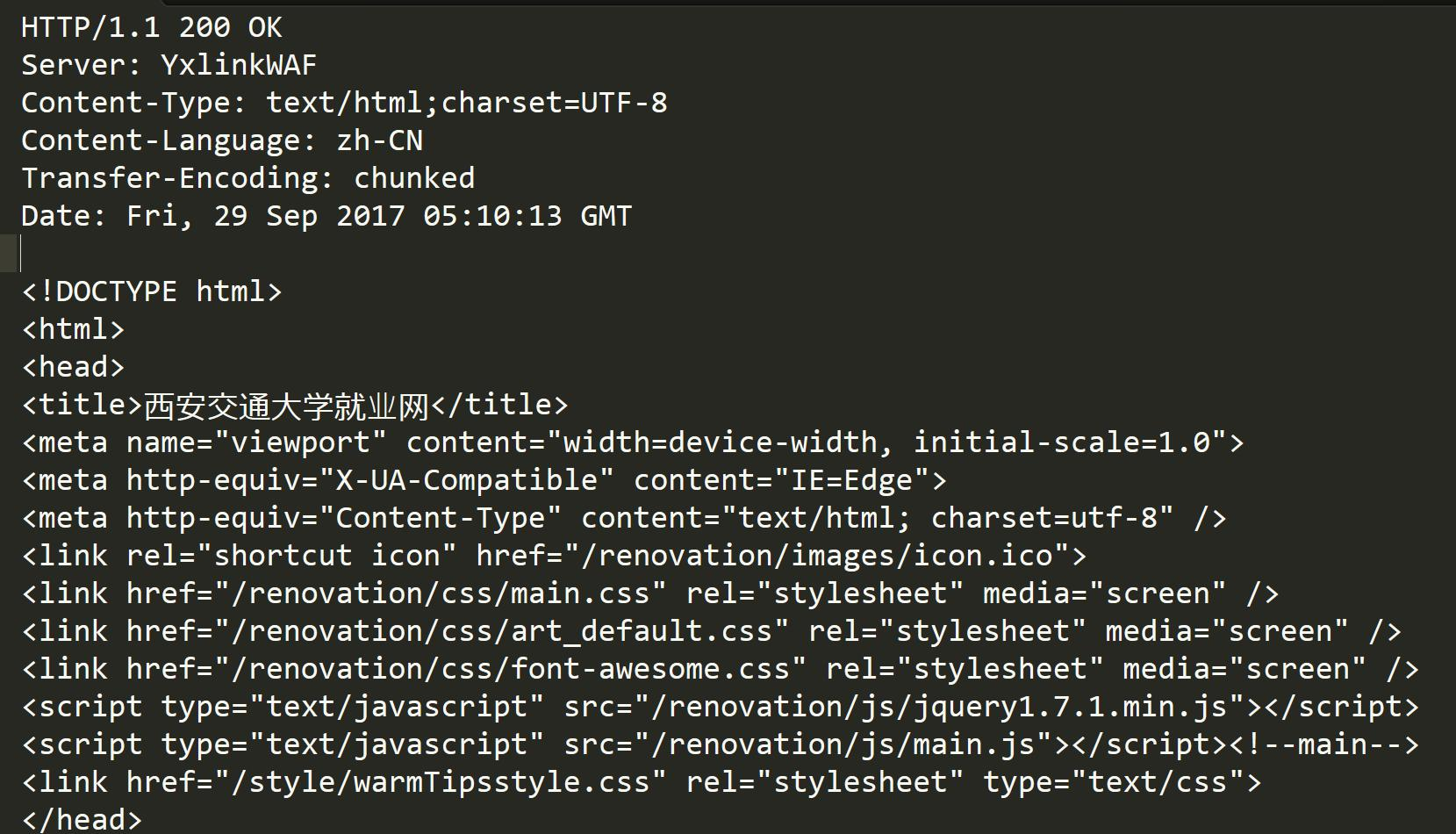
• 首行: [版本号] + [状态码] + [状态码解释]
• Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\r\n 分隔;遇到空行表示 Header 部分结束
• Body: 空行后面的内容都是 Body. Body 允许为空字符串. 如果 Body 存在, 则在Header 中会有一个 Content-Length 属性来标识 Body 的长度(因此能知道data的长度,保证所读到的能是一个完整的报文); 如果服务器返回了一个 html 页面, 那么 html 页面内容就是在 body 中.
对于http请求和响应格式中的请求报头和响应报头都可以没有,但建议有。而响应的正文部分就是我们请求的资源内容(html 图片 音频.....)
注意:
1.将报头和有效载荷进行分离(封装)
因为http的底层是tcp,未来就是我们将http拷贝给tcp,然后tcp进行发送,在http中是如何做到将报头和有效载荷进行分离?就是用的\r\n,可以看看我的上篇博客所讲的手写一个网络版计算器serialize、deserialize。
Content-Length属性:只要有正文,就一定会有(在报头里面)。保证我们能知道正文长度,因此,我们一定能够将报头读完,所以能保证读到一个完整的报文。
理解了以上的内容,现在我们可以开始处理http的发送给服务器的请求:
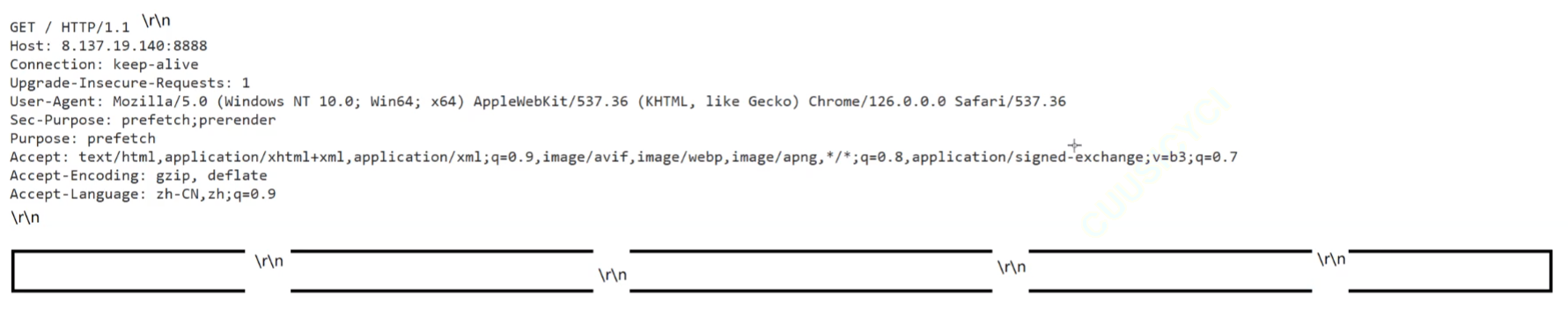
我们知道,我们所获得的请求报文,实际上就是一段连续的字符串,中间由\r\n进行换行处理:并且 reqstr 曾经被客户端序列化过!!!
http不想使用第三方ku(jsoncpp等,)对应的协议是由客户端自己定的。因此在代码中我们再改写:
代码编写
HttpRequest类(编写分成三次,“做三次反序列化”)
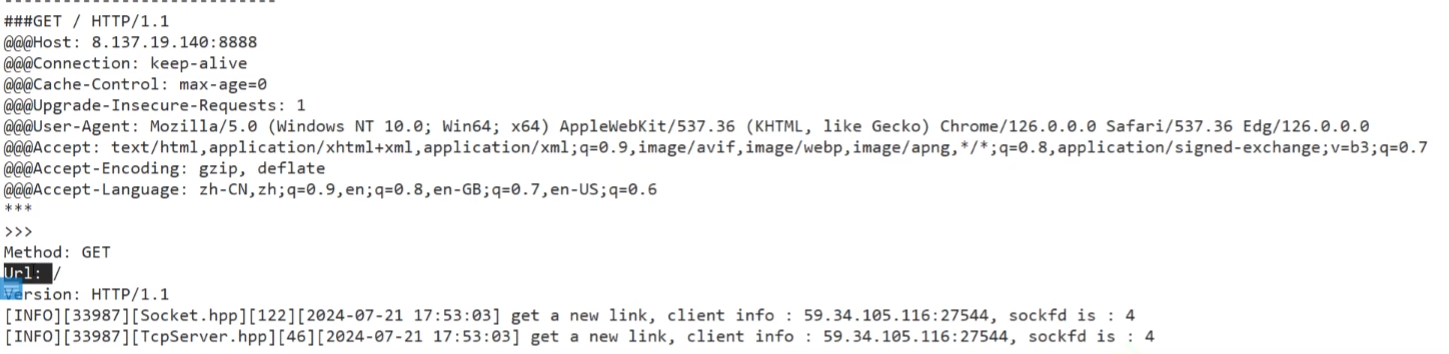
#pragma once #include <iostream> #include <string> #include <vector>const static std::string base_sep = "\r\n";class HttpRequest { public:HttpRequest() : _blank_line(base_sep){}// \r\n// \r\n datastd::string Getline(std::string &reqstr){auto pos = reqstr.find(base_sep);if (pos == std::string::npos)return std::string();// 注意是前闭后开区间// 获取到一行:std::string line = reqstr.substr(0, pos);// 将一行的内容全部读取(包括"\r\n"reqstr.erase(0, line.size() + base_sep.size());// 如果读取到的是空行,也就是pos==0, line为空字符串,则说明已经读完报头return line.empty() ? base_sep : line;}// 反序列化:void Deserialize(std::string &reqstr){// 1.获得请求行_req_line = Getline(reqstr);// 2.获得请求报头std::string header;do{header = Getline(reqstr);if (header.empty())break;else if (header == base_sep)break;_req_headers.push_back(header);} while (true);// 则说明有正文内容,因此正文内容直接等于剩下的内容if (!reqstr.empty()){_body_text = reqstr;}}void Print(){// 打印请求行std::cout << "###" << _req_line << std::endl;// 打印请求报头for (auto &header : _req_headers){std::cout << "@@@" << header << std::endl;}std::cout << "****" << _blank_line;std::cout << ">>>" << _body_text << std::endl;}~HttpRequest(){}private:// 基本的http请求的基本格式// 1.请求行std::string _req_line;// 2.请求报头std::vector<std::string> _req_headers;// 3.空行std::string _blank_line;// 4.请求正文内容std::string _body_text; };class HttpServer {public:HttpServer(){}std::string HandlerHttpRequest(std::string &reqstr){ #ifdef TESTstd::cout << "---------------------------------------" << std::endl;std::cout << reqstr;std::string responsestr = "HTTP/1.1 200 OK\r\n";responsestr += "Content-Type: text/html\r\n";responsestr += "\r\n";responsestr += "<html><h1>hello linux</h1></html>";return responsestr; #else// 将请求构建成一个结构化请求HttpRequest req;//反序列化req.Deserialize(reqstr);//打印出反序列化后的结果req.Print();return std::string();#endif}~HttpServer(){} };运行结果:
但仅做反序列化是不够的,在未来我们还是需要通过属性来得到其中的值:
比如从Get里获取到方法: / HTTP/1.1

HttpRequest类 --->代码中做这样的增加:(注意这里的代码不全)
// c++中将字符串转化成流 #include <sstream>const static std::string base_sep = "\r\n";void ParseReqLine(){// 将字符串转化成 字符串流std::stringstream ss(_req_line); // 类似于cin >>ss >> _method >> _url >> _version; // 依次按空格为分隔符依次输入多个单词}// 反序列化:void Deserialize(std::string &reqstr){// A<基本反序列化>// 1.获得请求行_req_line = Getline(reqstr);// 2.获得请求报头std::string header;do{header = Getline(reqstr);if (header.empty())break;else if (header != base_sep)break;_req_headers.push_back(header);} while (true);// 则说明有正文内容,因此正文内容直接等于剩下的内容if (!reqstr.empty()){_body_text = reqstr;}// B<进一步反序列化>// 解析ReqLineParseReqLine();}void Print(){std::cout << "----------------------------------------------------" << std::endl;// 打印请求行std::cout << "###" << _req_line << std::endl;// 打印请求报头for (auto &header : _req_headers){std::cout << "@@@" << header << std::endl;}std::cout << "****" << _blank_line;std::cout << ">>>" << _body_text << std::endl;std::cout << "Method: " << _method << std::endl<< " Url: " << _url << std::endl<< "Version" << _version << std::endl;}~HttpRequest(){}private:// 基本的http请求的基本格式// 1.请求行std::string _req_line;// 2.请求报头std::vector<std::string> _req_headers;// 3.空行std::string _blank_line;// 4.请求正文内容std::string _body_text;// 更具体的属性字段,需要进一步反序列化std::string _method;std::string _url;std::string _version;std::unordered_map<std::string, std::string> _headers_kv; };当客户端的请求过来了:就能分别得到每一个属性值
在网页进行请求时,试试这样请求:
进一步提取:将Header给反序列化出来,注意到Headers中的内容都是呈现Key - Value的形式,因此,我们使用到unordered_map,并且注意到分隔符是:" : "冒号加空格,因此我们根据这个分隔符来存key值和value到unordered_map当中:
HttpRequest类
#pragma once #include <iostream> #include <string> #include <vector> #include <unordered_map> // c++中将字符串转化成流 #include <sstream>const static std::string base_sep = "\r\n"; const static std::string line_sep = ": ";class HttpRequest { public:HttpRequest() : _blank_line(base_sep){}// \r\n// \r\n datastd::string Getline(std::string &reqstr){auto pos = reqstr.find(base_sep);if (pos == std::string::npos)return std::string();// 注意是前闭后开区间// 获取到一行:std::string line = reqstr.substr(0, pos);// 将一行的内容全部读取(包括"\r\n"reqstr.erase(0, line.size() + base_sep.size());// 如果读取到的是空行,也就是pos==0, line为空字符串,则说明已经读完报头return line.empty() ? base_sep : line;}void ParseReqLine(){// 将字符串转化成 字符串流std::stringstream ss(_req_line); // 类似于cin >>ss >> _method >> _url >> _version; // 依次按空格为分隔符依次输入多个单词}void ParseReqHeader(){for (auto &header : _req_headers){auto pos = header.find(line_sep);if (pos == std::string::npos)continue;// 注意substr提取到的字符串是左闭右开std::string key = header.substr(0, pos);std::string val = header.substr(pos + line_sep.size());if (key.empty() || val.empty())continue;_headers_kv.insert(std::make_pair(key, val));}}// 反序列化:void Deserialize(std::string &reqstr){// A<基本反序列化>// 1.获得请求行_req_line = Getline(reqstr);// 2.获得请求报头std::string header;do{header = Getline(reqstr);if (header.empty())break;else if (header == base_sep)break;_req_headers.push_back(header);} while (true);// 则说明有正文内容,因此正文内容直接等于剩下的内容if (!reqstr.empty()){_body_text = reqstr;}// B<进一步反序列化>// 解析ReqLineParseReqLine();// C<再进一步反序列化>ParseReqHeader();}void Print(){std::cout << "----------------------------------------------------" << std::endl;// 打印请求行std::cout << "###" << _req_line << std::endl;// 打印请求报头for (auto &header : _req_headers){std::cout << "@@@" << header << std::endl;}std::cout << "****" << _blank_line;std::cout << ">>>" << _body_text << std::endl;std::cout << "Method: " << _method << std::endl<< " Url: " << _url << std::endl<< "Version" << _version << std::endl;for (auto &header_kv : _headers_kv){std::cout << ")))" << header_kv.first << "->" << header_kv.second << std::endl;}}~HttpRequest(){}private:// 基本的http请求的基本格式// 1.请求行std::string _req_line;// 2.请求报头std::vector<std::string> _req_headers;// 3.空行std::string _blank_line;// 4.请求正文内容std::string _body_text;// 更具体的属性字段,需要进一步反序列化std::string _method;std::string _url;std::string _version;std::unordered_map<std::string, std::string> _headers_kv; };class HttpServer {public:HttpServer(){}std::string HandlerHttpRequest(std::string &reqstr){ #ifdef TESTstd::cout << "---------------------------------------" << std::endl;std::cout << reqstr;std::string responsestr = "HTTP/1.1 200 OK\r\n";responsestr += "Content-Type: text/html\r\n";responsestr += "\r\n";responsestr += "<html><h1>hello linux</h1></html>";return responsestr; #else// 将请求构建成一个结构化请求HttpRequest req;// 反序列化req.Deserialize(reqstr);// 打印出反序列化后的结果req.Print();return std::string();#endif}~HttpServer(){} };运行结果:未来我们想要查请求报头,就通过unordered_map的key就能查到value

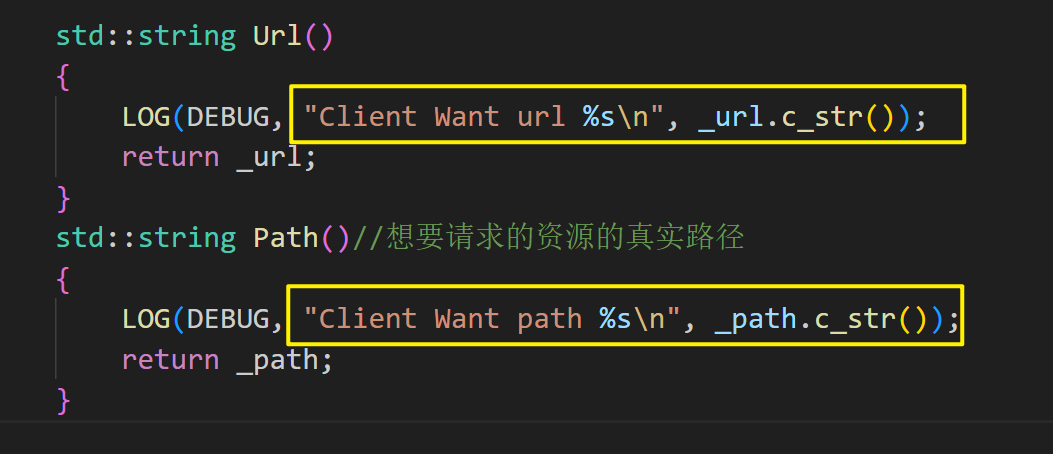
例如我现在想要获得url,在HttpRequest类当中写上这样一个公有函数来获取_url:
std::string Url(){LOG(DEBUG, "Client Want %s\n", _url.c_str());return _url;}在HttpServer类当中写到:这样一个公有函数来获得url
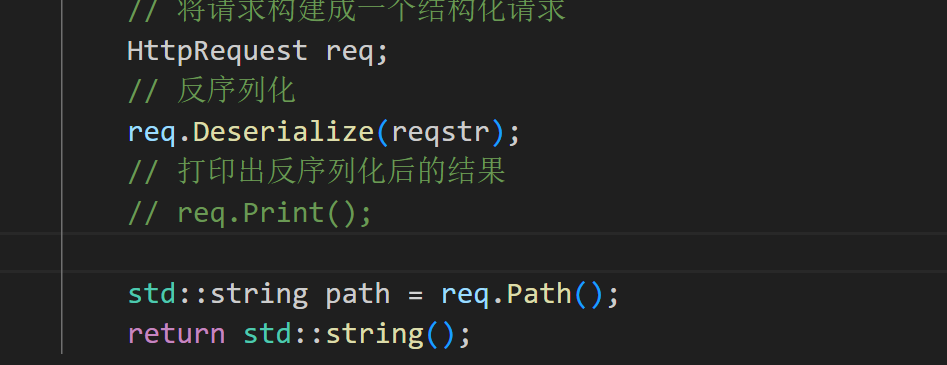
std::string HandlerHttpRequest(std::string &reqstr){ #ifdef TESTstd::cout << "---------------------------------------" << std::endl;std::cout << reqstr;std::string responsestr = "HTTP/1.1 200 OK\r\n";responsestr += "Content-Type: text/html\r\n";responsestr += "\r\n";responsestr += "<html><h1>hxy is a pigpig</h1></html>";return responsestr; #else// 将请求构建成一个结构化请求HttpRequest req;// 反序列化req.Deserialize(reqstr);// 打印出反序列化后的结果// req.Print();std::string url = req.Url();return std::string();#endif}
ServerMain.cc中不变
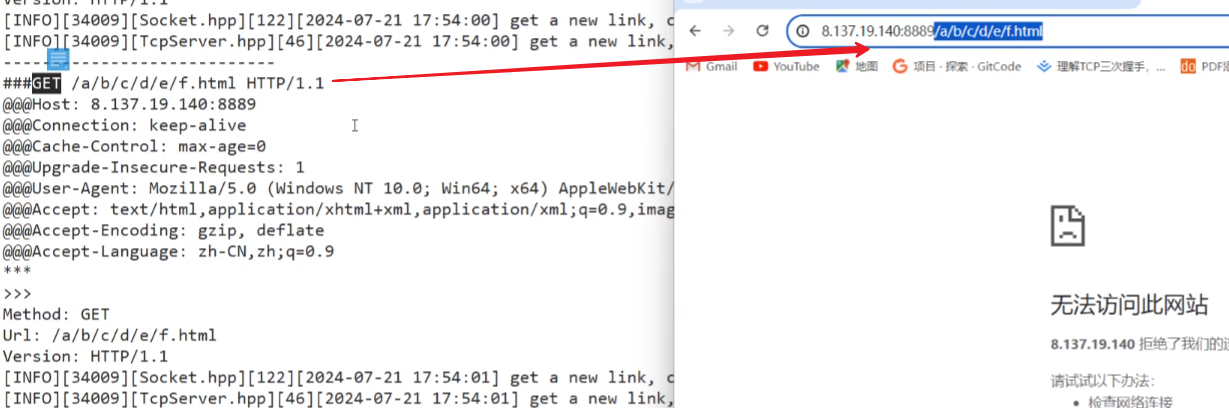
运行代码:./httpserver 8899,在浏览器搜索功能当中输入:你的IP地址 + :8899/a/b/c/html,注意想要收到反馈,需要在服务器当中将防火墙,你设定的端口号打开,例如,我是腾讯云服务器,我就讲端口8899打开,并且我使用的协议是TCP
于是在我们的服务器当中,就能收到从浏览器发过来的请求:
浏览器在没有得到相应的时候还会重复请求,因此我们只输入一次,他发送了多次。



能注意到在上面我们是携带了路径的,之前也提到过,这个路径可以是我们后端服务器当中的任意一个路径,那么如何制定好这个路径呢,现在我们来引入:
1.首先在当前路径下,又创建一个wwwroot目录:
紧接着,在Http.hpp中更新代码:
1.添加一个记录wwwroot的路径的前缀路径:
const static std::string prefixpath = "wwwroot";
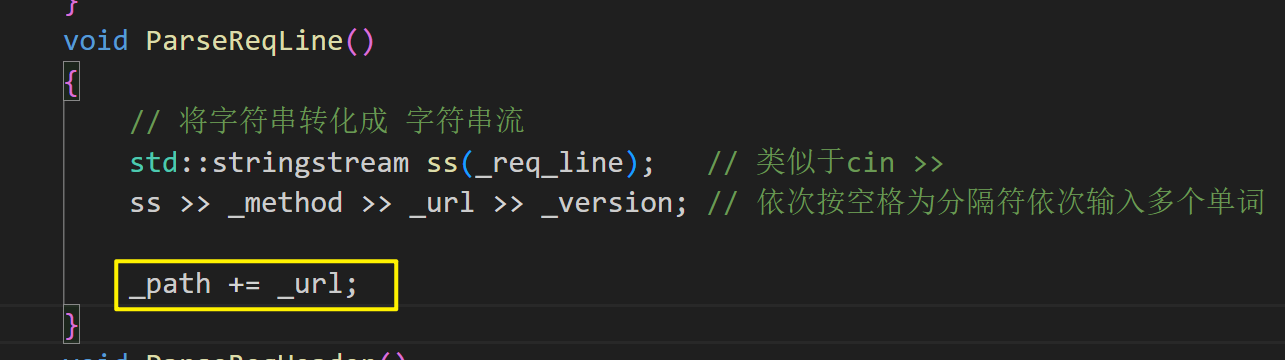
2._url是我们要访问的资源的简化的路径,为了获取资源我们需要一个完整路径_path。由简化路径与前缀路径拼接得来:
构造函数初始化时初始化path为前缀路径
HttpRequest() : _blank_line(base_sep), _path(prefixpath){}在分解请求行的函数当中拼接好完整路径:
再写一个获取_path的函数:
获取path:
如图:我们就获取到了

在将来,我们可以在这个前缀路径里放配置文件,当请求的时候,就能将这个放在linux中任意一个路径里面。
而在 访问一个浏览器的时候,都会由制作的人,自己设定一个首页,将来虽打开的是根目录,实际上,打开的就会是这个首页:wwwroot/首页(index.html一般)
例如:这是我们打开的百度页面
指定号index.html:仍然是
因此我们也需要写一个默认的index.html:
首先在wwroot下创建一个index.html,其次,定义一个全局静态常量:
const static std::string homepage = "index.html";


在函数中做判断:
void ParseReqLine(){// 将字符串转化成 字符串流std::stringstream ss(_req_line); // 类似于cin >>ss >> _method >> _url >> _version; // 依次按空格为分隔符依次输入多个单词_path += _url;//判断打开的是否是根目录,也就是需要打开默认页if(_path[_path.size() - 1] == '/'){_path += homepage;}}运行结果:这就是我们的首页了
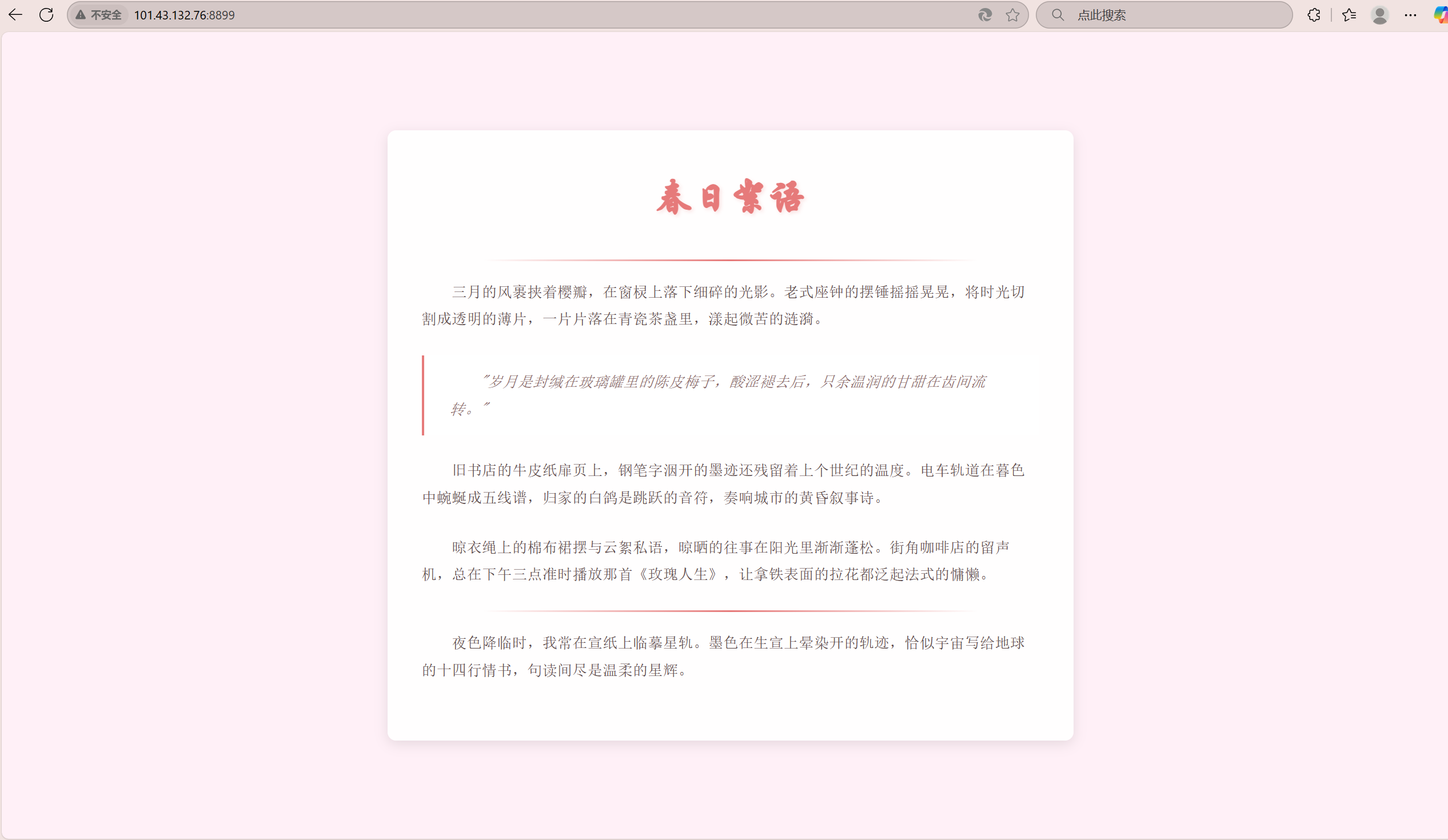
好的现在我们准备一个前端页面:这是一个将css html写在一起的简单代码:
<!DOCTYPE html>
<html lang="zh-CN">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>时光絮语</title><style>* {margin: 0;padding: 0;box-sizing: border-box;}body {background-color: #fff0f7;font-family: '宋体', SimSun, serif;line-height: 1.8;color: #5c4a4a;min-height: 100vh;display: flex; justify-content: center; align-items: center; padding: 20px; }.container {max-width: 800px;width: 100%; /* 新增 */background: rgba(255, 255, 255, 0.9);padding: 40px;border-radius: 10px;box-shadow: 0 4px 15px rgba(0, 0, 0, 0.1);animation: fadeIn 1.5s ease-in;/* 移除 margin: 0 auto */}h1 {font-family: '华文行楷', STXingkai, cursive;color: #e67a7a;text-align: center;margin-bottom: 30px;font-size: 2.8em;text-shadow: 2px 2px 4px rgba(230, 122, 122, 0.2);}.decorative-line {width: 80%;height: 2px;background: linear-gradient(90deg, transparent, #e67a7a 50%, transparent);margin: 20px auto;}p {text-indent: 2em;margin-bottom: 1.5em;font-size: 1.1em;}.quote {font-style: italic;color: #8f6b6b;padding: 15px 30px;border-left: 3px solid #e67a7a;margin: 25px 0;background: rgba(255, 255, 255, 0.5);}@keyframes fadeIn {from { opacity: 0; transform: translateY(20px); }to { opacity: 1; transform: translateY(0); }}@media (max-width: 768px) {.container {padding: 20px;}h1 {font-size: 2em;}p {font-size: 1em;}}</style>
</head>
<body><div class="container"><h1>春日絮语</h1><div class="decorative-line"></div><p>三月的风裹挟着樱瓣,在窗棂上落下细碎的光影。老式座钟的摆锤摇摇晃晃,将时光切割成透明的薄片,一片片落在青瓷茶盏里,漾起微苦的涟漪。</p><p class="quote">"岁月是封缄在玻璃罐里的陈皮梅子,酸涩褪去后,只余温润的甘甜在齿间流转。"</p><p>旧书店的牛皮纸扉页上,钢笔字洇开的墨迹还残留着上个世纪的温度。电车轨道在暮色中蜿蜒成五线谱,归家的白鸽是跳跃的音符,奏响城市的黄昏叙事诗。</p><p>晾衣绳上的棉布裙摆与云絮私语,晾晒的往事在阳光里渐渐蓬松。街角咖啡店的留声机,总在下午三点准时播放那首《玫瑰人生》,让拿铁表面的拉花都泛起法式的慵懒。</p><div class="decorative-line"></div><p>夜色降临时,我常在宣纸上临摹星轨。墨色在生宣上晕染开的轨迹,恰似宇宙写给地球的十四行情书,句读间尽是温柔的星辉。</p></div>
</body>
</html>最终我们要实现的是给客户端返回这个页面资源:
根据以上,我们就将Request写好,接下来我们写Response部分,根据url将客户端需要的资源响应给客户端
Response类的编写:
首先需要知道,不用给客户端写序列化和反序列化了,因为会由浏览器自行解析,服务器端传给客户端的东西都能由浏览器也就是客户端那边自动解析,浏览器需要做的是对请求的序列化和对应答的反序列化。
编写的代码,思路与上面获得请求(请求是进行反序列化)的思路相似,服务器端需要将序列化好的字符串响应给客户端,序列化是进行组合,将每个字段组合成每一行,最后拼接到一起,就序列化完成。1、构建状态行,2.构建整体。根据此图:
HttpResponse类:
class HttpResponse
{
public:HttpResponse():_version(httpversion), _blank_line(base_sep){}void AddCode(int code){_status_code = code;_desc = "OK";}void AddHeader(const std::string &k, const std::string &v){//如果key不存在则添加,存在则修改_headers_kv[k] = v;}void AddBodyText(const std::string &body_text){_resp_body_text = body_text;}//序列化请求字符串std::string Serialize(){ //最后将这里得到的字符串return回去给客户端// 1.构建状态行_status_line = _version + space_sep + std::to_string(_status_code) + space_sep + _desc + base_sep;// 2.构建应答报头:for(auto &header : _headers_kv){std::string header_line = header.first + line_sep + header.second + base_sep;_resp_headers.push_back(header_line);}// 3.空行和正文// 4.正式序列化std::string responsestr = _status_line;for(auto &line : _resp_headers){responsestr += line;}responsestr += _blank_line;responsestr += _resp_body_text;return responsestr;}~HttpResponse(){}private://httpresponse的基本属性// 1.HTTP版本std::string _version;//默认httpversion 1.0// 2.状态码int _status_code; //默认设置为200// 3.状态码描述std::string _desc;// 4.将来的报头和内容的映射关系,全部都在这里std::unordered_map<std::string, std::string> _headers_kv;// 基本的http响应基本格式// 1.状态行std::string _status_line;// 2.响应报头std::vector<std::string> _resp_headers;// 3.空行std::string _blank_line;// 4.响应正文内容std::string _resp_body_text;
};HttpServer类:
Content-Length属性:实体主体的字节大小
写一个获取客户端那边发来的请求文件的函数:
class HttpServer { private://获取请求文件:文件读取操作std::string GetFileContent(const std::string &path){ //读取必须才用二进制,因为有可能有图片等等std::ifstream in(path, std::ios::binary);if(!in.is_open()) return std::string();in.seekg(0, in.end);//此时读取到了结尾int filesize = in.tellg(); //告知我你的rw偏移量是多少,也就是得到文件对应的大小//再将读写位置恢复到最开始in.seekg(0, in.beg);std::string content;content.resize(filesize);//这样写会稍微有些破坏字符串的完整性in.read((char*)content.c_str(), filesize);in.close();return content;} public:HttpServer(){}std::string HandlerHttpRequest(std::string &reqstr){ #ifdef TESTstd::cout << "---------------------------------------" << std::endl;std::cout << reqstr;std::string responsestr = "HTTP/1.1 200 OK\r\n";responsestr += "Content-Type: text/html\r\n";responsestr += "\r\n";responsestr += "<html><h1>hxy is a pigpig</h1></html>";return responsestr; #else// 将请求构建成一个结构化请求HttpRequest req;// 反序列化req.Deserialize(reqstr);// 最基本的上层处理// 打印出反序列化后的结果// req.Print();std::string content = GetFileContent(req.Path());if(content.empty()) return std::string();// Todo//走到这里就说明,一定获取成功HttpResponse resp;//状态码设置为200resp.AddCode(200); //告诉别人请求报头的长度resp.AddHeader("Content-Length", std::to_string(content.size()));resp.AddBodyText(content);return resp.Serialize(); #endif}~HttpServer(){} };由此我们再访问:就能获取到我们所写的默认页index.html
注意这是我们指定了index.html
因为我们是二进制读取,所以可以读取到图片等:
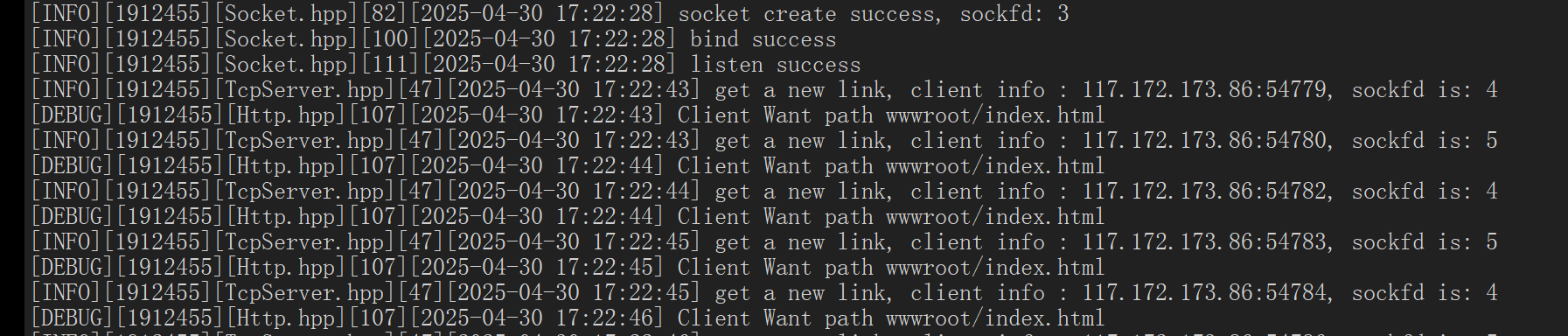
此时我们会发现,客户端向服务器发了多次不同的请求:
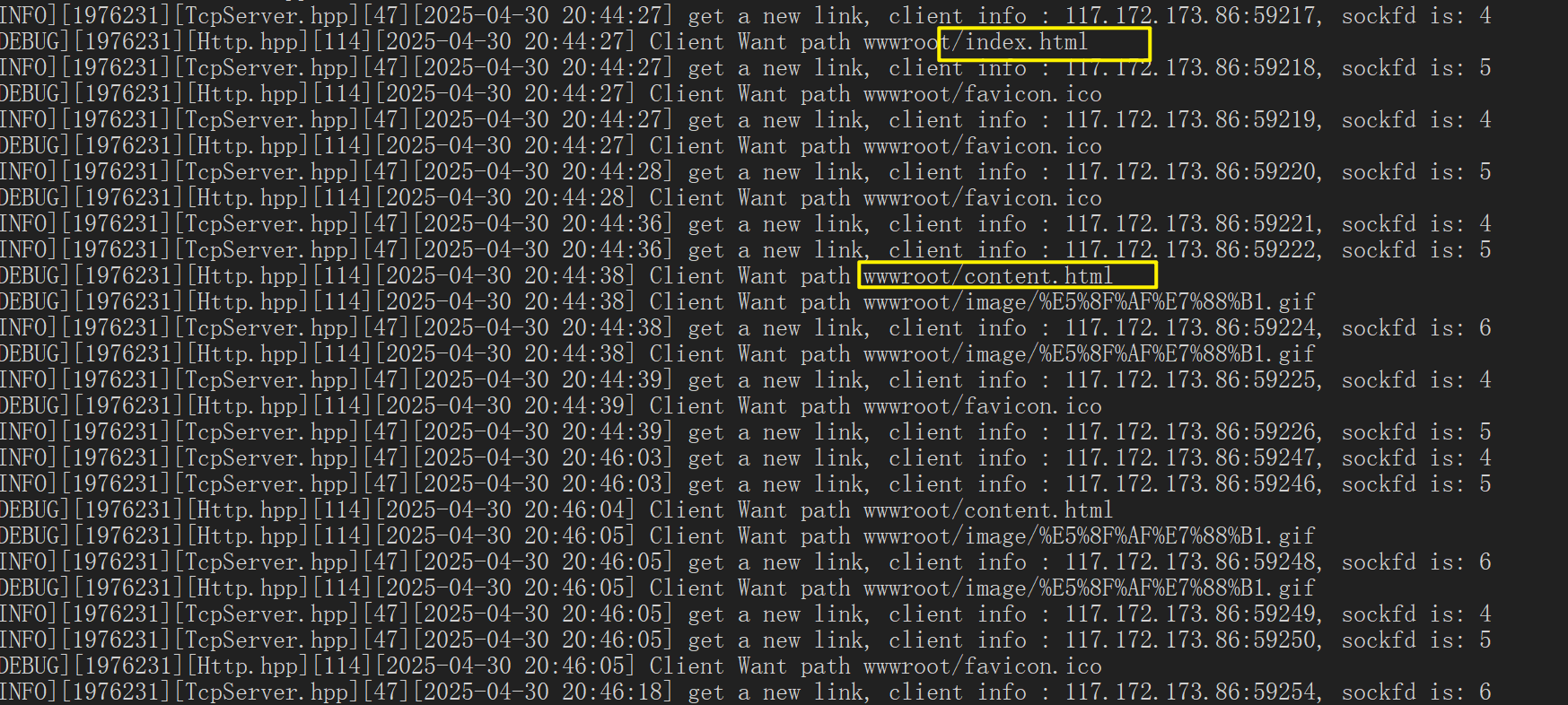
获得一个完整的网页,浏览器先要得到HTML,根据HTML的标签,检测出我们还需要获取其他资源,浏览器就会继续发起http请求。



现在我准备了几个不同的页面,在跳转到不同页面时:也会给服务器中发起请求
GET:
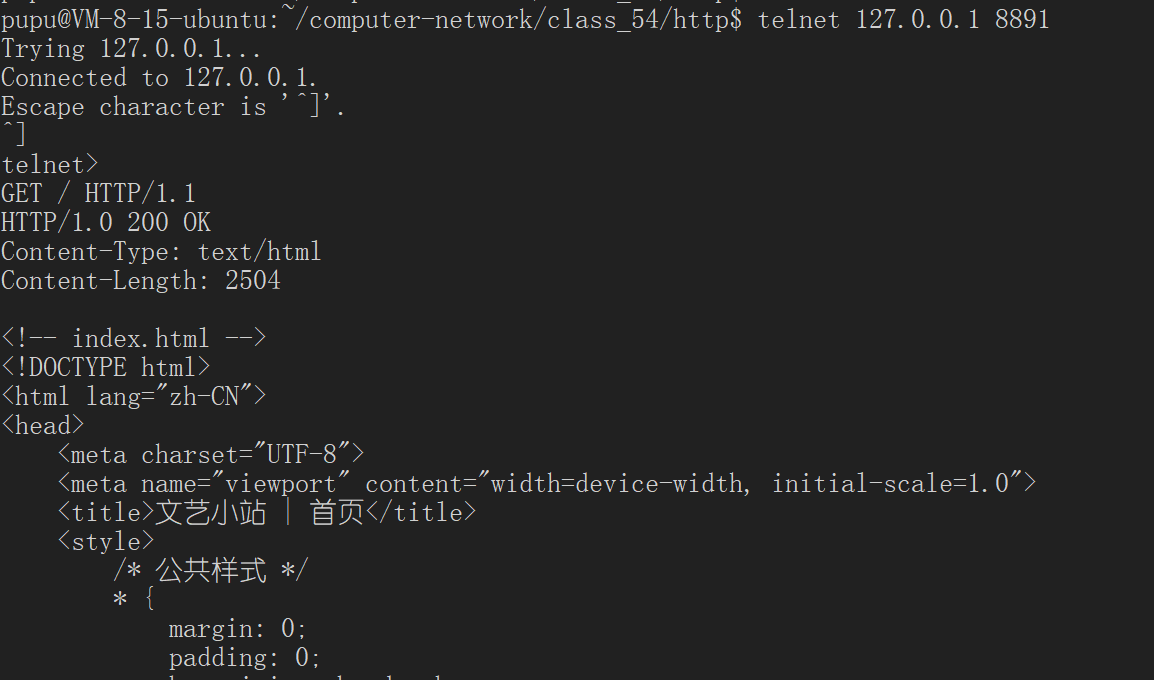
使用telnet命令:
通过GET可以直接在服务器当中获取到整个网页
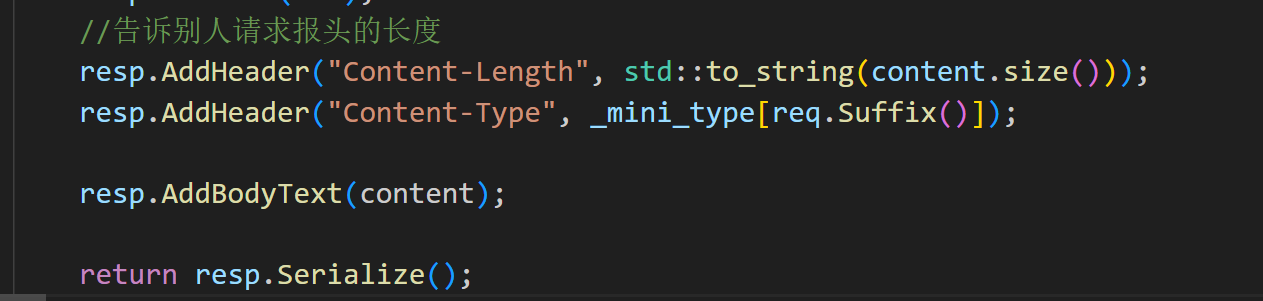
在这里我们就能看到我们整个网页的实体主体字节大小是2504
在HTTP协议当中:
content-type属性:
资源类型、并且可以通过content-type对照表,就可以查到,通过文件后缀名和content-type的对照:
因此为什么http可以识别超文本,因为各种文件类型他都认识。
浏览器向我们发起请求的时候,我们也需要对资源的类型进行解析:
因此,对于HttpResponse类:增加键值对的_mini_type
std::unordered_map<std::string, std::string> _mini_type;在初始化时,添加几个:.default(不知道是什么类型)就拼接成text/html。
HttpServer(){_mini_type().insert(std::make_pair(".html", "text/html"));_mini_type().insert(std::make_pair(".jpg", "application/x-jpg"));_mini_type().insert(std::make_pair(".pdf", "application/pdf"));_mini_type().insert(std::make_pair(".gif", "image/gif"));_mini_type().insert(std::make_pair(".png", "image/png"));_mini_type().insert(std::make_pair(".default", "text/html"));}因此,还需要改写HttpRequest类:
首先,添加成员变量:资源后缀_suffix,提取资源的后缀名
std::string _suffix; //资源后缀我们知道,文件后缀与文件名之间一定有一个".",因此我们将此定义为后缀分隔符
const static std::string suffixsep = ".";以此来分割:这是需求类当中的函数
void ParseReqLine(){// 将字符串转化成 字符串流std::stringstream ss(_req_line); // 类似于cin >>ss >> _method >> _url >> _version; // 依次按空格为分隔符依次输入多个单词_path += _url;//判断打开的是否是根目录,也就是需要打开默认页if(_path[_path.size() - 1] == '/'){_path += homepage;}//提取后缀:auto pos = _path.find(suffixsep);if(pos != std::string::npos){_suffix = _path.substr(pos);}else{_suffix = ".default";}}再提供一个suffix获取的接口:
std::string Suffix()//想要请求的资源的真实路径{return _suffix;}
对于HttpServer类当中的函数:
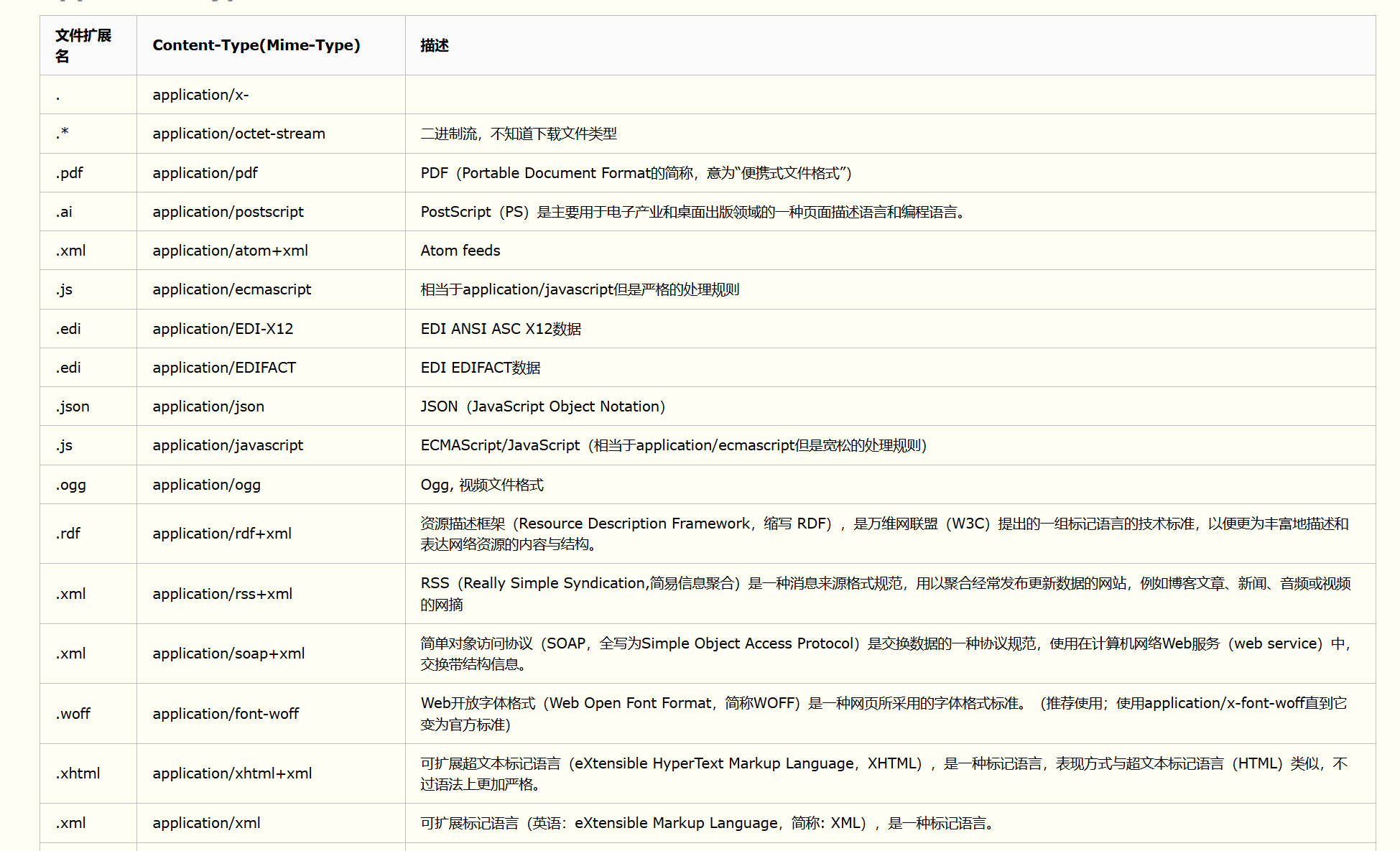
将Content-Type属性添加:
resp.AddHeader("Content-Type", _mini_type[req.Suffix()]);运行代码:由此我们获取到了资源信息
Fiddler:
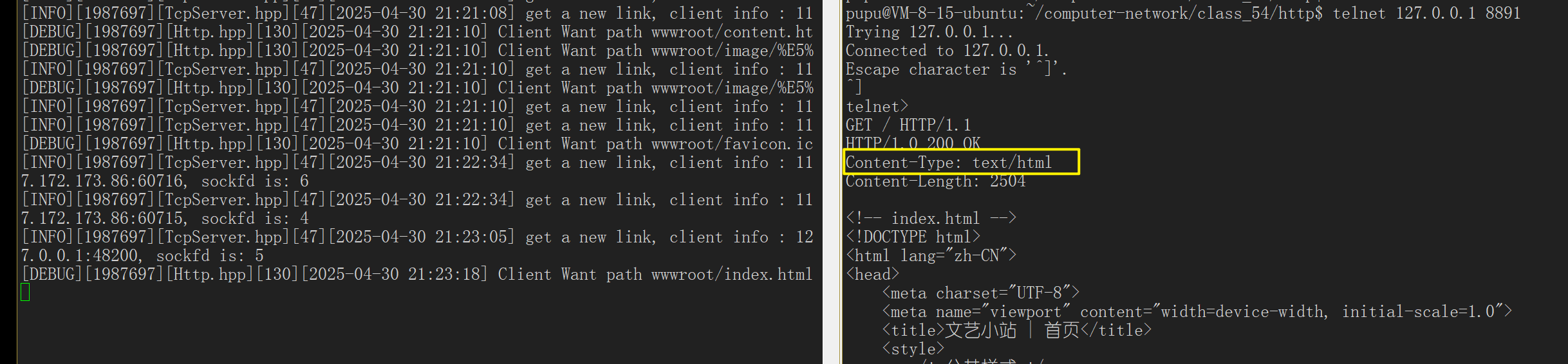
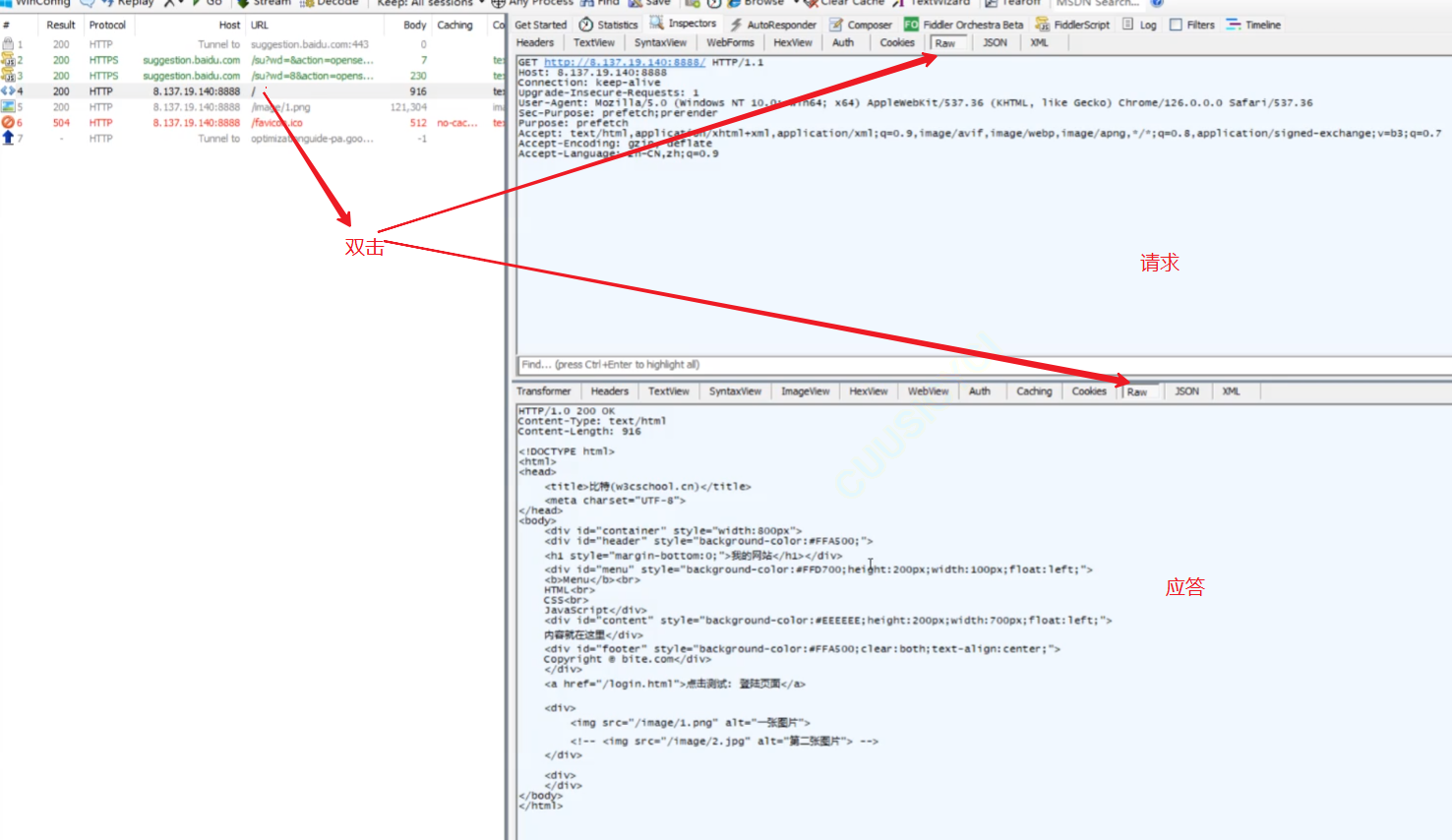
或者使用工具:Fiddler,可以帮我们进行抓包,帮我们抓取本地浏览器,向服务器发起请求时的HTTP报文,想看哪个资源 ,就双击查看:
抓包:?
一般我们在启动服务器服务的时候:浏览器直接向服务器请求,服务器直接响应给浏览器,我们的浏览器是存在于我们的本地电脑上的
在使用Fiddler的时候,他也是在我们的本地电脑上的,Fiddler会劫持我们的浏览器,浏览器所发送的所有请求,先由Fiddler拿到,Fiddler再把请求发给服务器,服务器(在服务器端看来,是Fiddler发送的报文)的应答再返回给Fiddler,Fiddler再将应答转给浏览器。这就是抓包。
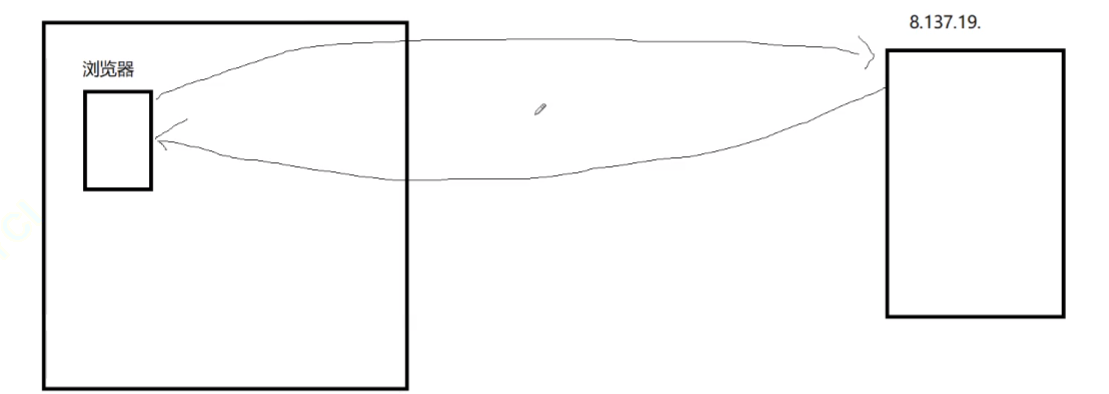
HOST属性:
对我们的代码进行条件编译:
运行这段代码:然后发起请求
HOST就是目标服务器的IP和端口,未来要访问域名就是域名。
但是访问的不就是我的主机吗,我难道不知道我自己设定的服务器合端口?
这是因为,将来可能要访问的那部分文件资源并不在我这个服务器上,可能我不对这个请求做序列化,而是将这个请求再发(我的服务器又充当了客户端)给这个资源所在的服务器端(HOST所指的服务器)上,另外的服务器再将资源响应给我我再做序列化处理之后再响应给客户端,这里就类似于Fiddler。实际上客户端想要访问的资源不在我这个服务器上,被我对外隐藏在其他服务器上。相当于我们的服务器端既是客户端也是服务器端。我的服务器,就称之为代理服务器。代理服务器才知道客户端要访问的资源在哪里。

总结一下Header:
• Content-Type: 数据类型(text/html 等)
• Content-Length: Body 的长度
• Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
• User-Agent: 声明用户的操作系统和浏览器版本信息;
• referer: 当前页面是从哪个页面跳转过来的;(未讲)
• Location: 搭配 3xx 状态码使用, 告诉客户端接下来要去哪里访问;(内容过多,单独章节讲)
• Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;(内容过多,单独章节讲)
referer:
根据referer锁记录的信息,在某些情况,我们可以来统计用户是从哪里跳转过来的,可以对客户的来源进行统计,可以统计一个用户喜欢从哪个页面到哪个页面,通常我们就可以通过这些信息,来进行一个跨站级别的标识,我们可以禁止一个人从某个页面访问到当前页面,可以通过referer属性进行判断,如果他的上一个页面是什么页面,就禁止显示某个页面。
关于 connection 报头
HTTP 中的 Connection 字段是 HTTP 报文头的一部分, 它主要用于控制和管理客户端与服务器之间的连接状态。
• 管理持久连接: Connection 字段还用于管理持久连接(也称为长连接) 。 持久连接允许客户端和服务器在请求/响应完成后不立即关闭 TCP 连接, 以便在同一个连接上发送多个请求和接收多个响应。持久连接(长连接)
• HTTP/1.1: 在 HTTP/1.1 协议中, 默认使用持久连接。 当客户端和服务器都不明确指定关闭连接时, 连接将保持打开状态, 以便后续的请求和响应可以复用同一个连接。
• HTTP/1.0: 在 HTTP/1.0 协议中, 默认连接是非持久的。 如果希望在 HTTP/1.0上实现持久连接, 需要在请求头中显式设置 Connection: keep-alive。
语法格式
• Connection: keep-alive: 表示希望保持连接以复用 TCP 连接。
• Connection: close: 表示请求/响应完成后, 应该关闭 TCP 连接。
关于长连接:在之前的tcp套接字编程当中的网络计算器,写过长连接(用while循环做到的,一直接受请求,与一直服务),感兴趣可以通过连接 去看看详细思路。
浏览器非常聪明,有可能会将我们访问过的资源缓存下来,在下一次访问的时候就不会对服务器发送请求,直接从本地拿出来就好了
HTTP 请求和服务器应答的版本的意义:
客户端和服务器在微信这个场景下,是如何区分是新客户端还是老客户端?给其带上版本号。服务器和客户端都有版本号,互相交换版本号,HTTP是一个协议,浏览器是一个应用,用了HTTP协议,浏览器会告诉服务器,用的是HTTP的什么版本,如果浏览器用的是HTTP/1.1那么HTTP/2.0的功能就不会提供给客户端。服务器也会给浏览器响应版本。浏览器也能知道服务器的版本号,双方都知道相互的版本,再提供或需求相应的功能。
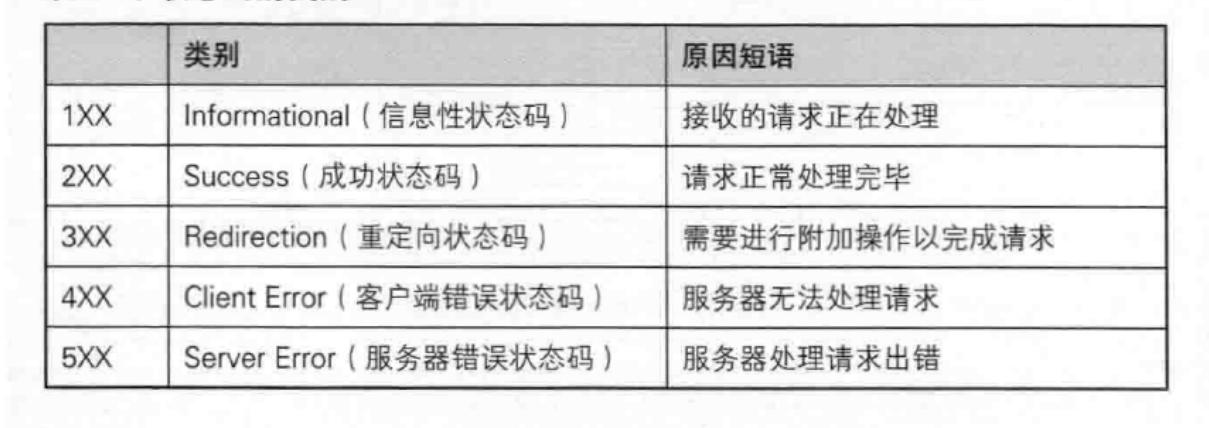
HTTP状态码和状态码描述
HTTP状态码
最常见的状态码, 比如 200(OK), 404(Not Found、请求的资源不存在,这个错误就是客户端的错误), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway),重定向又被分为临时重定向(广告、登录页面...)、永久重定向。如果是服务器的错误,他不一定会将5XX的状态码返回给我们。即便是服务器内部错了,也不会应答5XX的数字。
在PC年代,浏览器是人们上网的入口,刚开始百度作为一个搜索引擎是当时的使用率是非常多的而比搜索引擎先打开的软件是浏览器,除了搜索引擎能赚很多钱以外,就是浏览器。因为流量大,利益大,许多浏览器公司就内置了搜索引擎,因此百度产生了危机感,也做了浏览器。正因为浏览器跟利益十分相关,因此就注定了大量企业、组织参与浏览器的开发,因此大部分浏览器都做的很好。特别是HTTP协议的标准的提出者本身就是某个浏览器背后的公司利益链条有关,因此其他浏览器就不想遵守。这就导致了某些浏览器对于某些功能的支持不太好。因此前端开发需要做各种浏览器的各种方面的兼容测试,需要做很多的适配。一旦和利益有关,就会发生冲突。因此状态码,不一定就真的是那样。
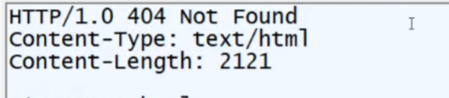
因此对于我们的代码还要做出修改,状态码部分,如果所读取到的文件是空时,要响应状态码404,并且响应状态信息,以及返回到一个404.html的页面。
在使用Fiddler抓包的时候就能看到响应的错误码:
但是,难道我每次都需要服务器自己手动的来填状态码和状态码描述吗?并不是
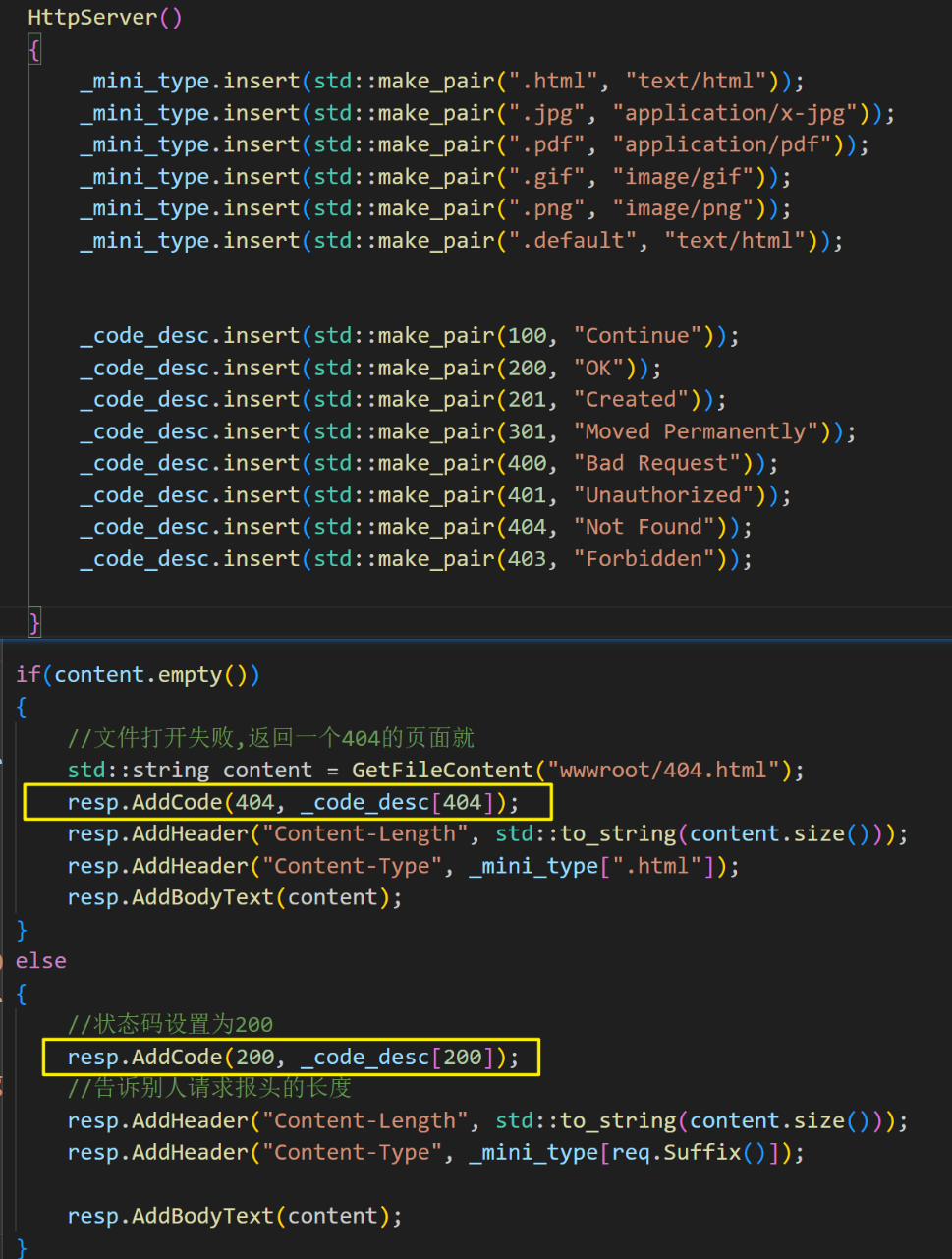
HTTPServer类:提供一个状态码和状态描述的映射关系
使用unordered_map
std::unordered_map<int, std::string> _code_desc;
由此将状态码和状态描述的映射关系维护起来。
下篇文章我们将继续讲解HTTP,3开头的重定向,以及请求方法GET、POST,以及如何将HttpServer改造,http不仅可以请求某些网页也能请求服务
Http.hpp完整代码:下篇文章继续使用
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <unordered_map>
// c++中将字符串转化成流
#include <sstream>#include<fstream>const static std::string base_sep = "\r\n";
const static std::string line_sep = ": ";
//前缀路径
const static std::string prefixpath = "wwwroot";
const static std::string homepage = "index.html";
//服务器 HTTP版本
const static std::string httpversion = "HTTP/1.0";const static std::string space_sep = " ";const static std::string suffixsep = ".";const static std::string html_404 = "404.html";class HttpRequest
{
public:HttpRequest() : _blank_line(base_sep), _path(prefixpath){}// \r\n// \r\n datastd::string Getline(std::string &reqstr){auto pos = reqstr.find(base_sep);if (pos == std::string::npos)return std::string();// 注意是前闭后开区间// 获取到一行:std::string line = reqstr.substr(0, pos);// 将一行的内容全部读取(包括"\r\n"reqstr.erase(0, line.size() + base_sep.size());// 如果读取到的是空行,也就是pos==0, line为空字符串,则说明已经读完报头return line.empty() ? base_sep : line;}void ParseReqLine(){// 将字符串转化成 字符串流std::stringstream ss(_req_line); // 类似于cin >>ss >> _method >> _url >> _version; // 依次按空格为分隔符依次输入多个单词_path += _url;//判断打开的是否是根目录,也就是需要打开默认页if(_path[_path.size() - 1] == '/'){_path += homepage;}//提取后缀:auto pos = _path.find(suffixsep);if(pos != std::string::npos){_suffix = _path.substr(pos);}else{_suffix = ".default";}}void ParseReqHeader(){for (auto &header : _req_headers){auto pos = header.find(line_sep);if (pos == std::string::npos)continue;// 注意substr提取到的字符串是左闭右开std::string key = header.substr(0, pos);std::string val = header.substr(pos + line_sep.size());if (key.empty() || val.empty())continue;_headers_kv.insert(std::make_pair(key, val));}}// 反序列化:void Deserialize(std::string &reqstr){// A<基本反序列化>// 1.获得请求行_req_line = Getline(reqstr);// 2.获得请求报头std::string header;do{header = Getline(reqstr);if (header.empty())break;else if (header == base_sep)break;_req_headers.push_back(header);} while (true);// 则说明有正文内容,因此正文内容直接等于剩下的内容if (!reqstr.empty()){_body_text = reqstr;}// B<进一步反序列化>// 解析ReqLineParseReqLine();// C<再进一步反序列化>ParseReqHeader();}std::string Url(){LOG(DEBUG, "Client Want url %s\n", _url.c_str());return _url;}std::string Path()//想要请求的资源的真实路径{LOG(DEBUG, "Client Want path %s\n", _path.c_str());return _path;}std::string Suffix()//想要请求的资源的真实路径{return _suffix;}void Print(){std::cout << "----------------------------------------------------" << std::endl;// 打印请求行std::cout << "###" << _req_line << std::endl;// 打印请求报头for (auto &header : _req_headers){std::cout << "@@@" << header << std::endl;}std::cout << "****" << _blank_line;std::cout << ">>>" << _body_text << std::endl;std::cout << "Method: " << _method << std::endl<< " Url: " << _url << std::endl<< "Version" << _version << std::endl;for (auto &header_kv : _headers_kv){std::cout << ")))" << header_kv.first << "->" << header_kv.second << std::endl;}}~HttpRequest(){}private:// 基本的http请求的基本格式// 1.请求行std::string _req_line;// 2.请求报头std::vector<std::string> _req_headers;// 3.空行std::string _blank_line;// 4.请求正文内容std::string _body_text;// 更具体的属性字段,需要进一步反序列化std::string _method;std::string _url;//--->url是我们要访问的资源,是简化的路径std::string _path;//--->将路径拼接好得到完整路径std::string _suffix; //资源后缀 std::string _version;std::unordered_map<std::string, std::string> _headers_kv;
};class HttpResponse
{
public:HttpResponse():_version(httpversion), _blank_line(base_sep){}void AddCode(int code, const std::string &desc){_status_code = code;_desc = desc;}void AddHeader(const std::string &k, const std::string &v){//如果key不存在则添加,存在则修改_headers_kv[k] = v;}void AddBodyText(const std::string &body_text){_resp_body_text = body_text;}//序列化请求字符串std::string Serialize(){ //最后将这里得到的字符串return回去给客户端// 1.构建状态行_status_line = _version + space_sep + std::to_string(_status_code) + space_sep + _desc + base_sep;// 2.构建应答报头:for(auto &header : _headers_kv){std::string header_line = header.first + line_sep + header.second + base_sep;_resp_headers.push_back(header_line);}// 3.空行和正文// 4.正式序列化std::string responsestr = _status_line;for(auto &line : _resp_headers){responsestr += line;}responsestr += _blank_line;responsestr += _resp_body_text;return responsestr;}~HttpResponse(){}private://httpresponse的基本属性// 1.HTTP版本std::string _version;//默认httpversion 1.0// 2.状态码int _status_code; //默认设置为200// 3.状态码描述std::string _desc;// 4.将来的报头和内容的映射关系,全部都在这里std::unordered_map<std::string, std::string> _headers_kv;// 基本的http响应基本格式// 1.状态行std::string _status_line;// 2.响应报头std::vector<std::string> _resp_headers;// 3.空行std::string _blank_line;// 4.响应正文内容std::string _resp_body_text;
};class HttpServer
{
private://获取请求文件:文件读取操作std::string GetFileContent(const std::string &path){ //读取必须才用二进制,因为有可能有图片等等std::ifstream in(path, std::ios::binary);if(!in.is_open()) return std::string();in.seekg(0, in.end);//此时读取到了结尾int filesize = in.tellg(); //告知我你的rw偏移量是多少,也就是得到文件对应的大小//再将读写位置恢复到最开始in.seekg(0, in.beg);std::string content;content.resize(filesize);//这样写会稍微有些破坏字符串的完整性in.read((char*)content.c_str(), filesize);in.close();return content;}
public:HttpServer(){_mini_type.insert(std::make_pair(".html", "text/html"));_mini_type.insert(std::make_pair(".jpg", "application/x-jpg"));_mini_type.insert(std::make_pair(".pdf", "application/pdf"));_mini_type.insert(std::make_pair(".gif", "image/gif"));_mini_type.insert(std::make_pair(".png", "image/png"));_mini_type.insert(std::make_pair(".default", "text/html"));_code_desc.insert(std::make_pair(100, "Continue"));_code_desc.insert(std::make_pair(200, "OK"));_code_desc.insert(std::make_pair(201, "Created"));_code_desc.insert(std::make_pair(301, "Moved Permanently"));_code_desc.insert(std::make_pair(400, "Bad Request")); _code_desc.insert(std::make_pair(401, "Unauthorized"));_code_desc.insert(std::make_pair(404, "Not Found"));_code_desc.insert(std::make_pair(403, "Forbidden"));}
// #define TESTstd::string HandlerHttpRequest(std::string &reqstr){
#ifdef TESTstd::cout << "---------------------------------------" << std::endl;std::cout << reqstr;std::string responsestr = "HTTP/1.1 200 OK\r\n";responsestr += "Content-Type: text/html\r\n";responsestr += "\r\n";responsestr += "<html><h1>hxy is a pigpig</h1></html>";return responsestr;
#elsestd::cout << "---------------------------------------------------"<<std::endl;std::cout << reqstr;std::cout << "---------------------------------------------------"<<std::endl;// 将请求构建成一个结构化请求HttpRequest req;// 反序列化req.Deserialize(reqstr);// if(req.Suffix() == ".ico") return std::string();// 最基本的上层处理HttpResponse resp;// 打印出反序列化后的结果// req.Print();std::string content = GetFileContent(req.Path());if(content.empty()){ //文件打开失败,返回一个404的页面就std::string content = GetFileContent("wwwroot/404.html");resp.AddCode(404, _code_desc[404]);resp.AddHeader("Content-Length", std::to_string(content.size()));resp.AddHeader("Content-Type", _mini_type[".html"]);resp.AddBodyText(content);}else{//状态码设置为200resp.AddCode(200, _code_desc[200]); //告诉别人请求报头的长度resp.AddHeader("Content-Length", std::to_string(content.size()));resp.AddHeader("Content-Type", _mini_type[req.Suffix()]);resp.AddBodyText(content);}return resp.Serialize();
#endif}~HttpServer(){}
private: std::unordered_map<std::string, std::string> _mini_type;std::unordered_map<int, std::string> _code_desc;
};结语:
随着这篇博客接近尾声,我衷心希望我所分享的内容能为你带来一些启发和帮助。学习和理解的过程往往充满挑战,但正是这些挑战让我们不断成长和进步。我在准备这篇文章时,也深刻体会到了学习与分享的乐趣。
在此,我要特别感谢每一位阅读到这里的你。是你的关注和支持,给予了我持续写作和分享的动力。我深知,无论我在某个领域有多少见解,都离不开大家的鼓励与指正。因此,如果你在阅读过程中有任何疑问、建议或是发现了文章中的不足之处,都欢迎你慷慨赐教。
你的每一条反馈都是我前进路上的宝贵财富。同时,我也非常期待能够得到你的点赞、收藏,关注这将是对我莫大的支持和鼓励。当然,我更期待的是能够持续为你带来有价值的内容。