PDF内容搜索--支持跨文件夹多文件、组合词搜索
平时我们接触到的PDF文档特别多,需要对PDF文档做一些处理,那么今天给大家带来的这两个软件非常的棒,可以帮你提升处理文档的效率。
PDF内容搜索
快速检索
我用夸克网盘分享了「PDF搜索+PDF 转长图.zip」,点击链接即可保存。打开「夸克APP」,无需下载在线播放视频,畅享原画5倍速,支持电视投屏。
链接:https://pan.quark.cn/s/6866e48333e4
我们平时只能局限于单个PDF文件里面进行搜索,但是这个软件可以通过关键词在多个PDF文档内进行内容检索,并且还支持多关键词搜索。
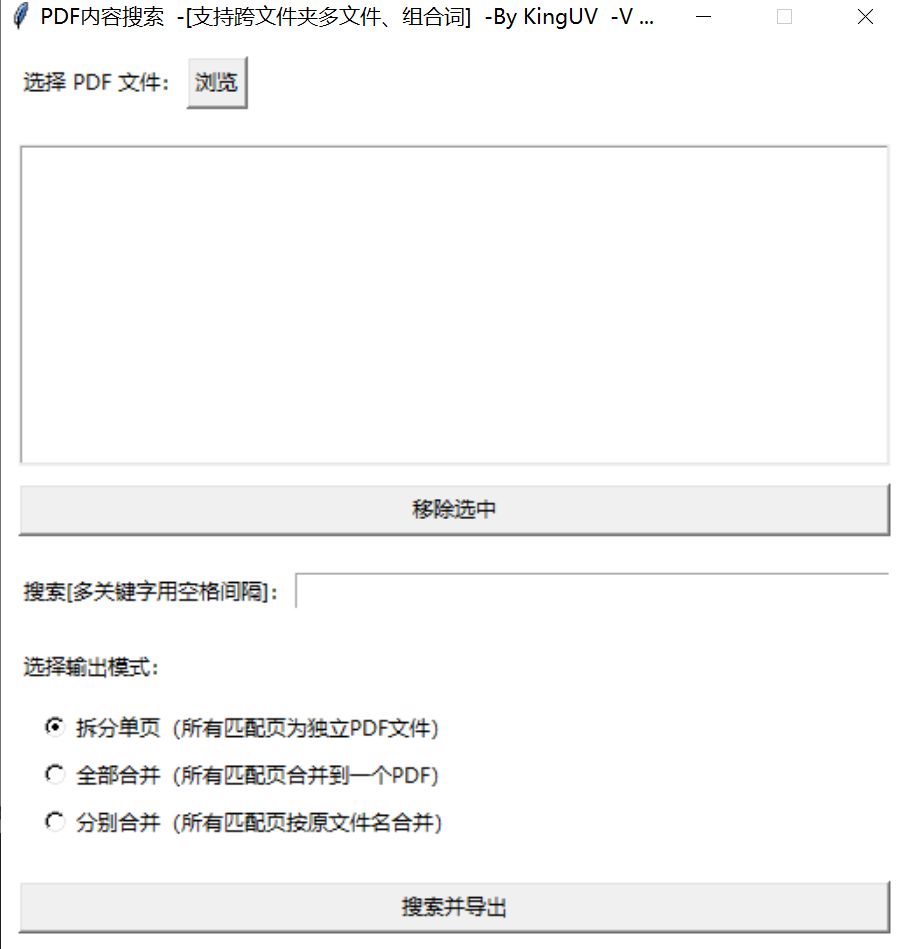
最厉害的在于,它可以把搜索出来的结果拆分成独立的PDF文件,或者合并成一个文件,这样就极大的简化了大量的流程,提高了工作效率。

比如,这两个PDF文档就合并完成了。
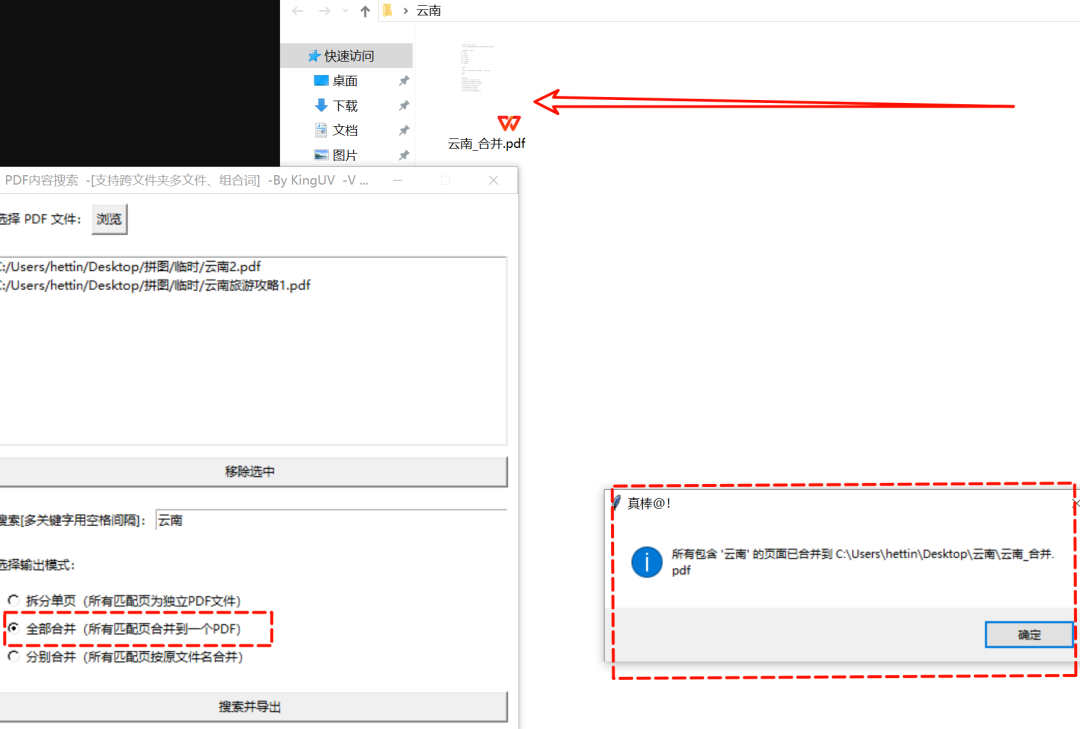
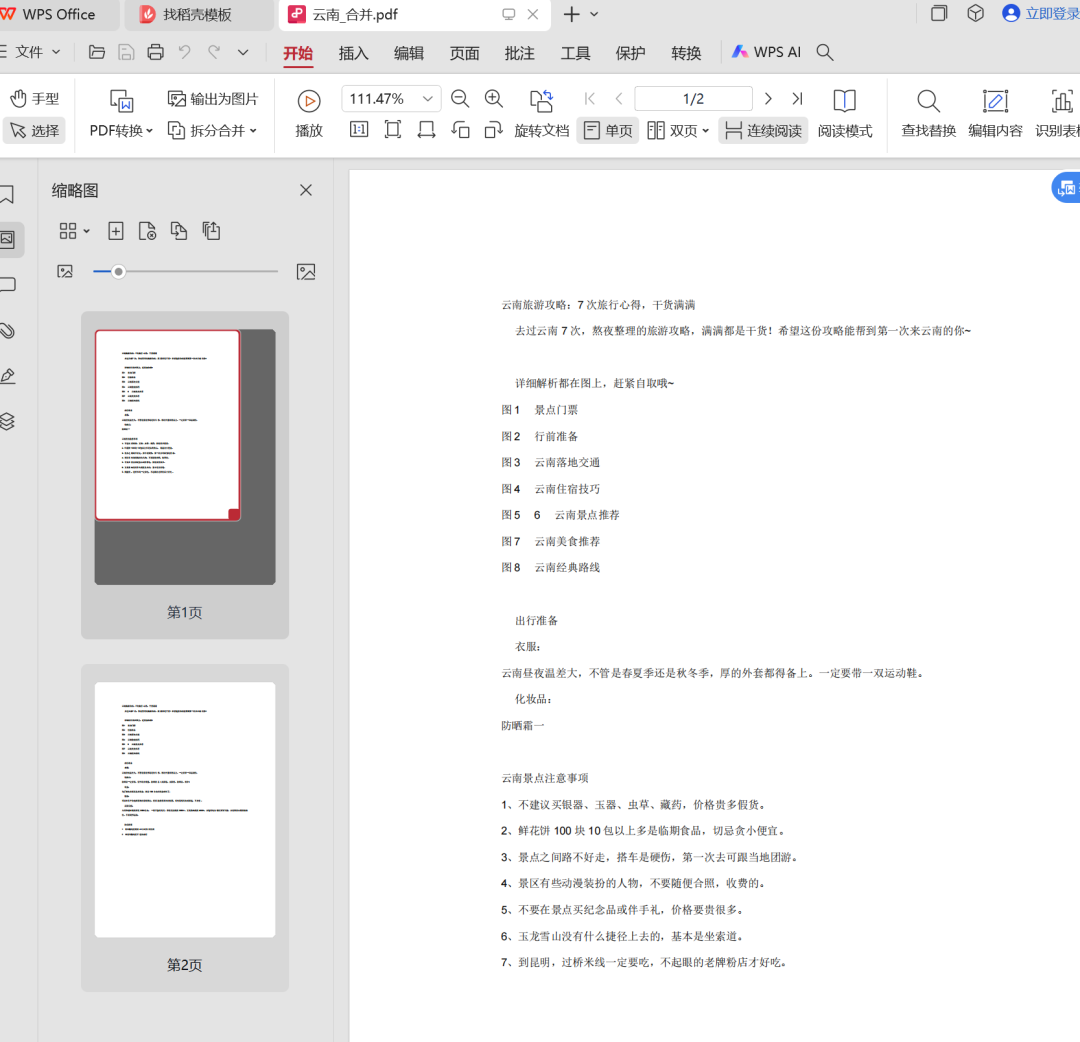
合并之后的文档也能够正常的打开,效率拉满。
PDF转长图片
自动拼接成长图
这个软件只有一个功能,就是把PDF里面的内容提取成为图片,并且自动拼接成长图。双击打开就能直接使用。
界面也非常的简单,没有别的广告。
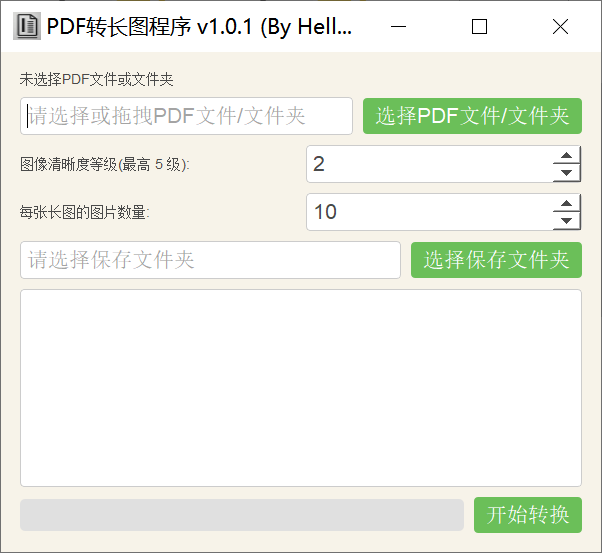
使用起来也非常简单,设置好保存文件夹,调整图像清晰度。然后就可以开始转换了。
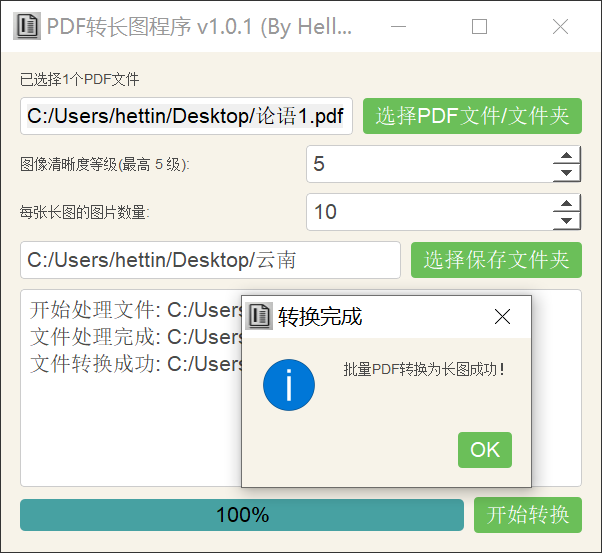
提取的效果还是非常棒的,图片也能正常打开。
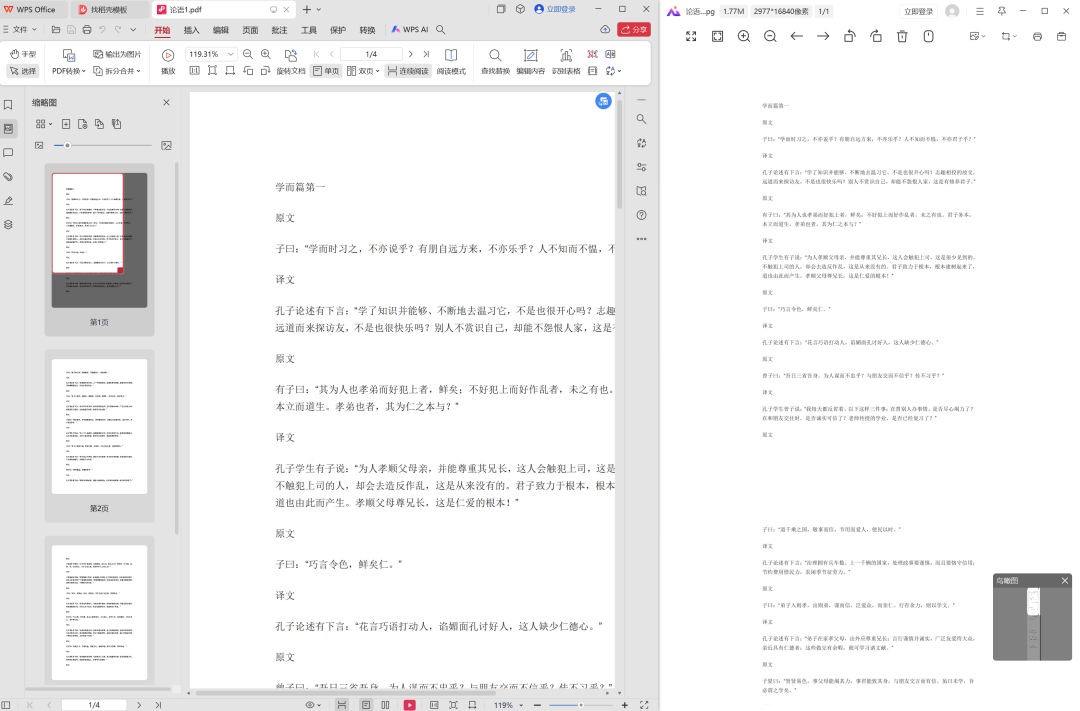
有了这两个PDF软件,工作效率直接拉满!