MySQL的内置函数与复杂查询
目录
前言
一、聚合函数
1.1日期函数
1.2字符串函数
1.3数学函数
1.4其它函数
二、关键字周边
2.1关键字的生效顺序
2.2数据源
2.3可以使用聚合函数的关键字
前言
在前面几篇文章中,讲解了有关MySQL数据库、数据库表的创建、数据库表的数据操作等等。本文我们主要讲解MySQL中给我们内置好的,可以帮助我们完成一定功能的函数,以及一些复杂场景下的查询操作。这里不建议没有基础的同学进行阅读。
一、内置函数函数
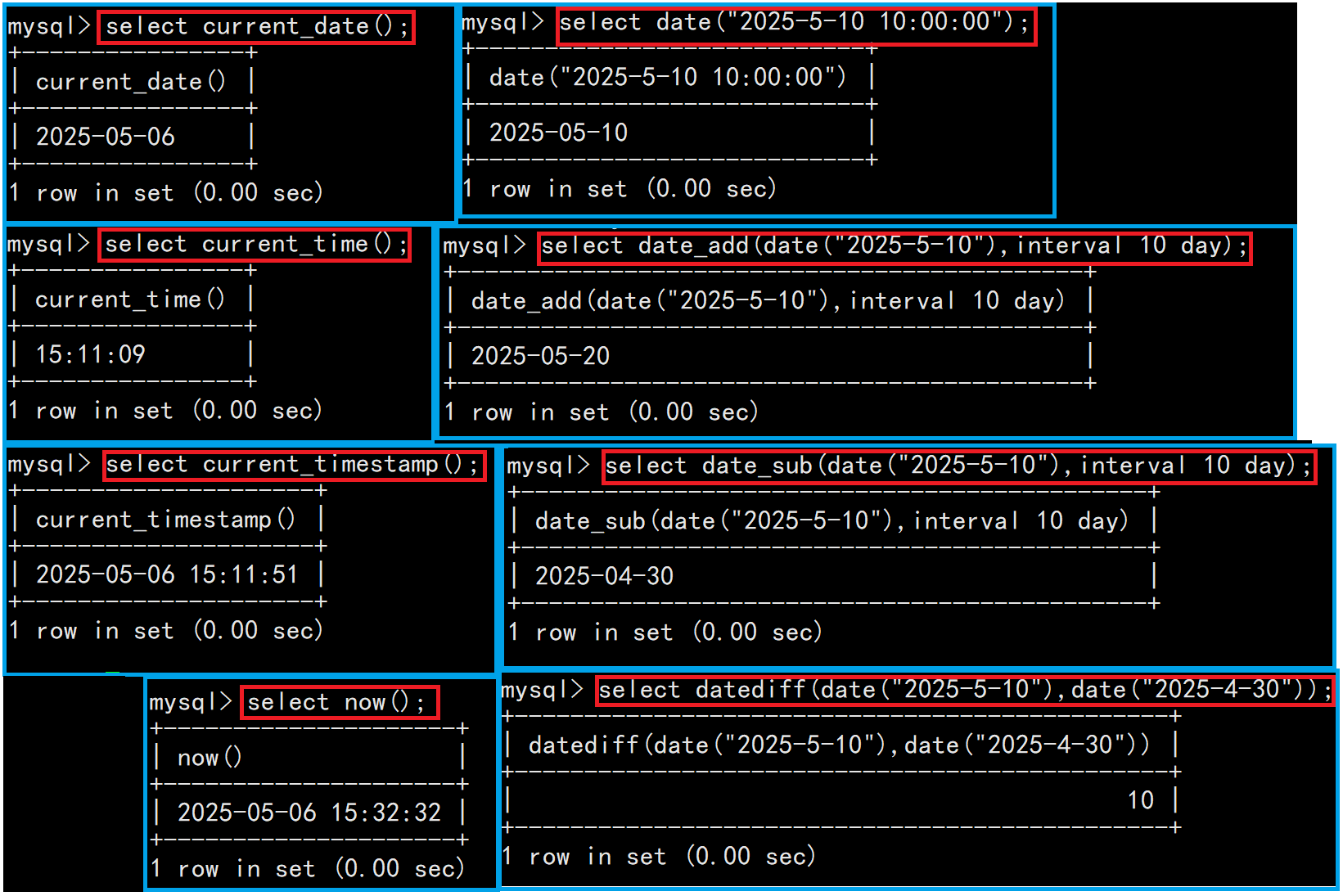
1.1日期函数
| 函数名称 | 描述 |
|---|---|
| current_date() | 当前日期 |
| current_time() | 当前时间 |
| current_timestamp() | 当前时间戳 |
| date(datetime) | 按照datetime格式返回时间 |
| date_add(date, interval d_value_type) | 在date的基础上添加时间。 d_value_type可以是year、day、minute、second其中之一 |
| date_sub(date, interval d_value_type) | 在date的基础上减去时间。 d_value_type可以是year、day、minute、second其中之一 |
| datediff(date1,date2) | 两个日期之差,单位是天 |
| now() | 获取当前时间 |
1.2字符串函数
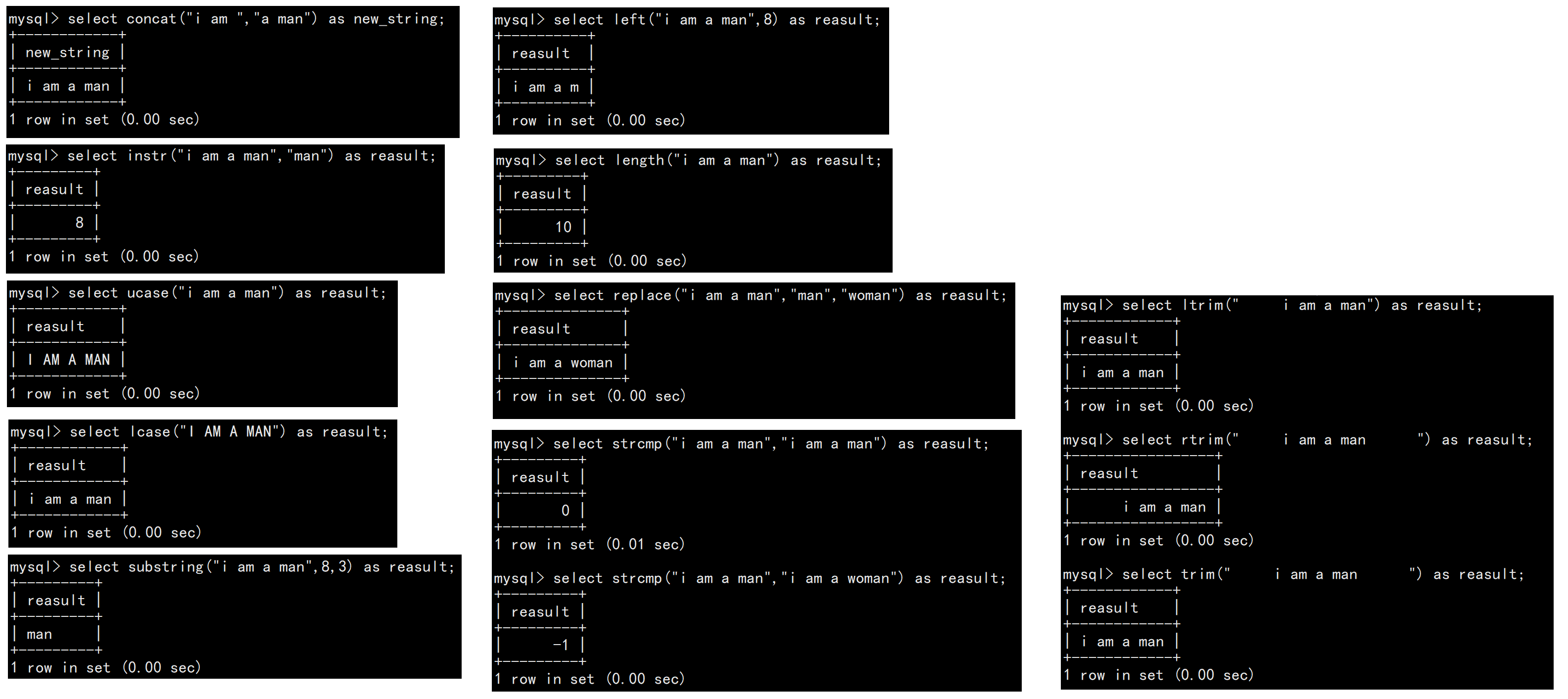
| 函数 | 说明 |
|---|---|
| charset() | 返回字段的字符集 |
| concat(str1,str,...) | 连接字符串 |
| instr(stringA,stringB) | 在stringA中查找是否存在stringB,存在则返回其所在位置,不存在则返回0 |
| ucase(string) | 转换为大写 |
| lcase(string) | 转换为小写 |
| left(string,length) | 从string首部其去除length个字符 |
| length(string) | 返回string的长度 |
| replace(str,search_str,replace_str) | 在str中使用replace_str替换search_str |
| strcmp(stringA,stringB) | 逐字符比较stringA与stringB的大小 |
| substring(str,position,length) | 从str的position位置取出length个字符 |
| ltrim(string) rtrim(string) trim(string) | 去除string中的左空格、右空格、左右空格 |
1.3数学函数
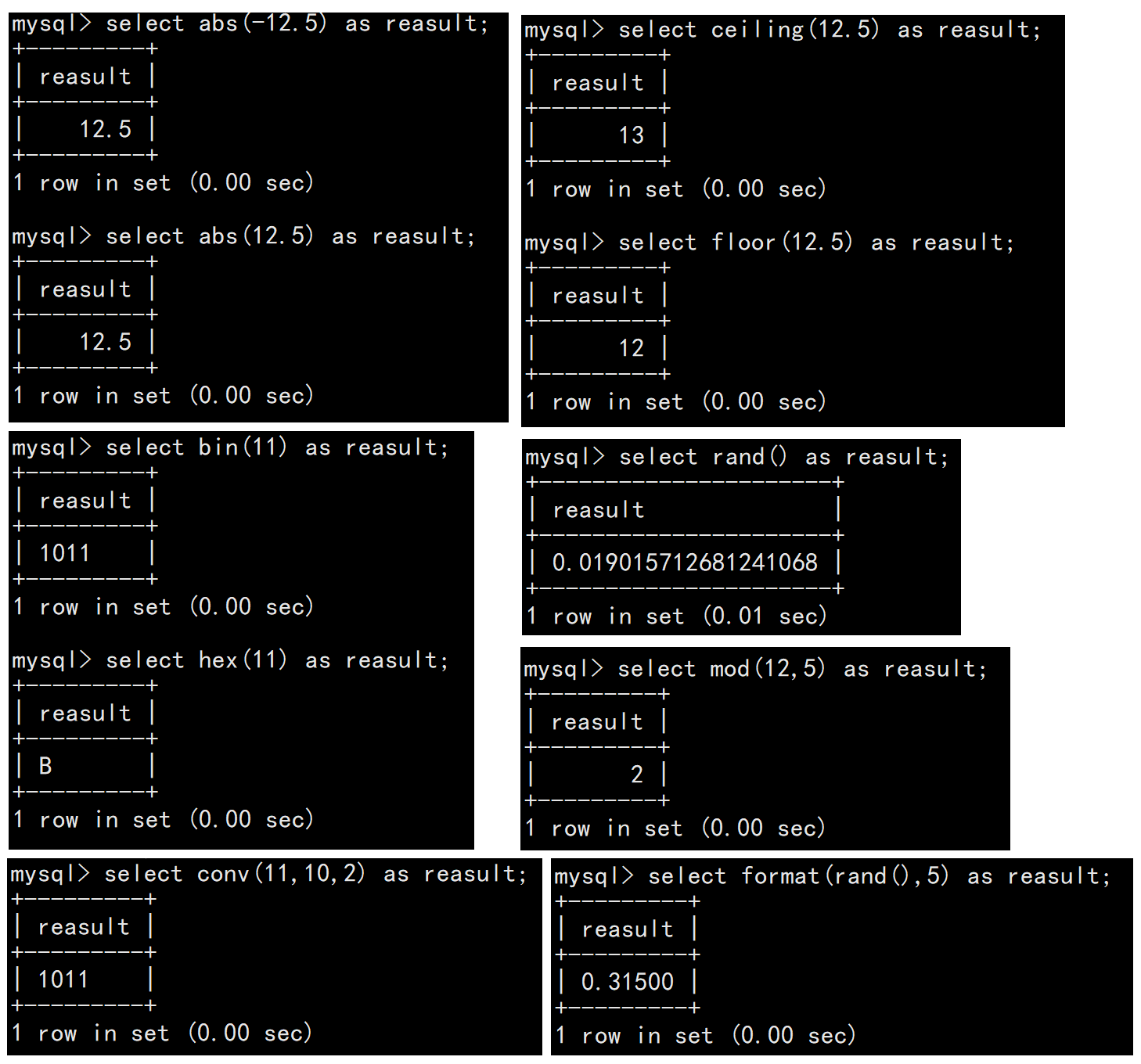
| 函数名称 | 说明 |
|---|---|
| abs(number) | 对number进行绝对值运算 |
| bin(decimal_number) | 十进制转换为二进制 |
| hex(decimal_number) | 十进制转换为十六进制 |
| conv(number,from_base,to_base) | 将number从from_base进制转换为to_base进制 |
| ceiling(number) | 向上取整 |
| floor(number) | 向下取整 |
| format(number,decimal_places) | 格式化,保留小数位 |
| rand() | 返回[0,1)之间的随机浮点数 |
| mod(number,denominator) | 取模,求余 |
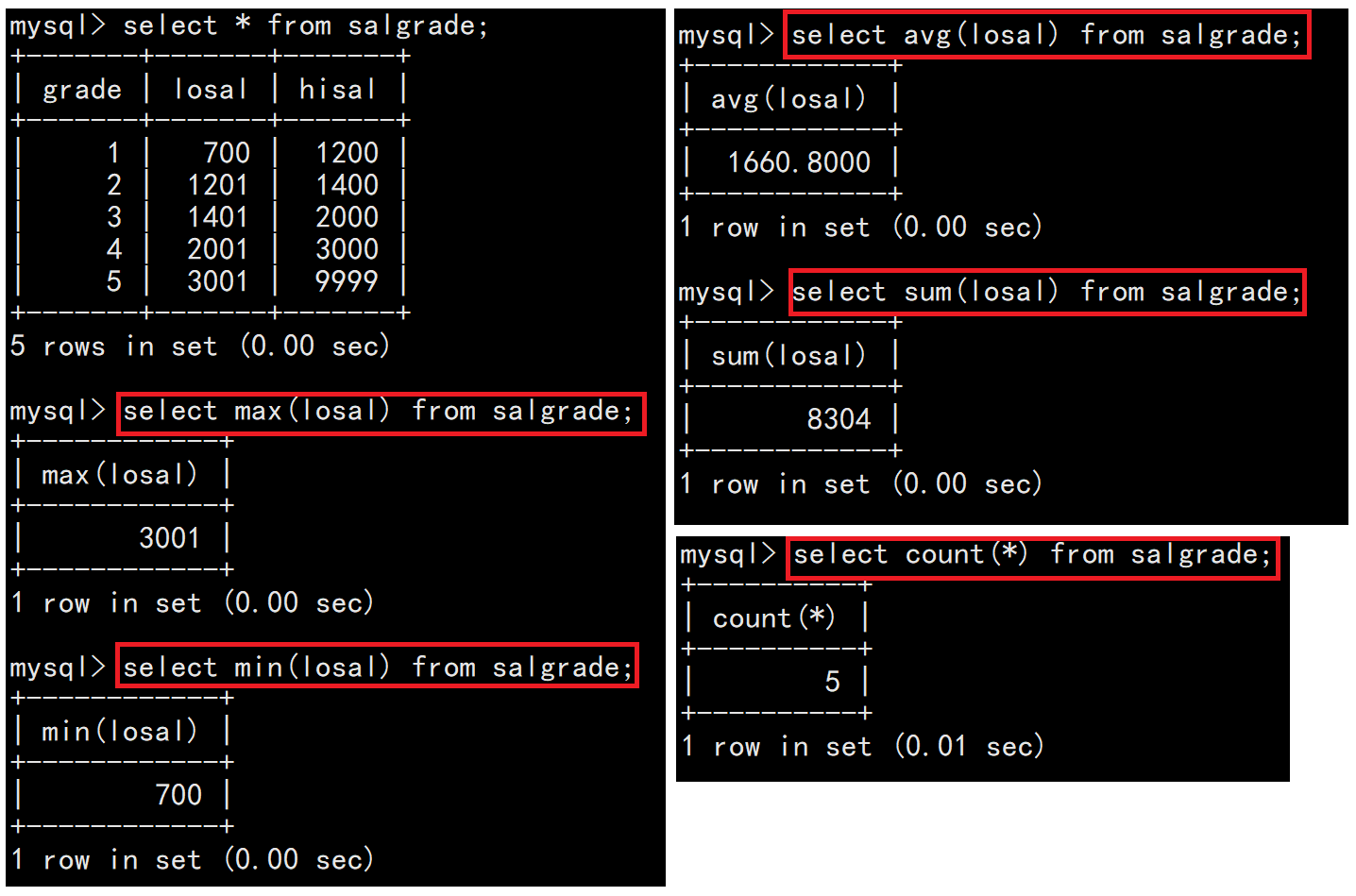
1.4聚合函数
| 函数名称 | 说明 |
|---|---|
| count() | 用来统计表中行的个数,使用count(*)可以统计所有行(包括值为null的列的行)的数量。 |
| sum() | 用来统计数值列的总和,只能用于数值列。 |
| avg() | 用来统计数值列的平均值,只能用于数值列。 |
| max() | 用于获取指定列的最大值。可以用于数值、日期、字符串等类型的列。 |
| min() | 用于获取指定列的最小值。与 MAX()类似,可以用于多种数据类型。 |
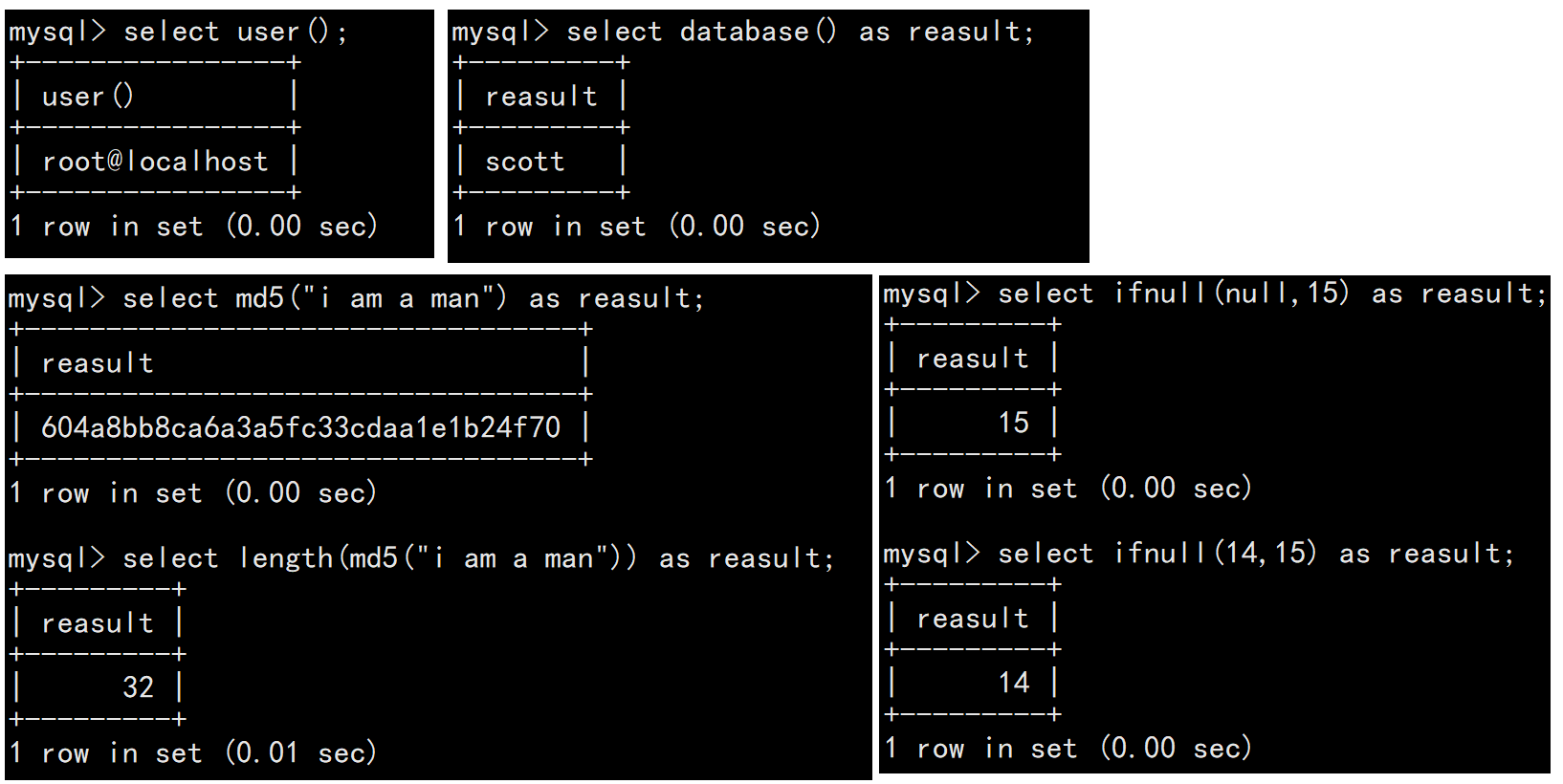
1.5其它函数
| 函数名称 | 说明 |
|---|---|
| user() | 查看当前登录用户的用户名 |
| md5(str) | 对str生成一个32位的md5摘要 |
| database() | 显示当前正在使用的数据库 |
| ifnull(val1,val2) | 如果val1为null,返回val2,否则返回val1 |
二、关键字周边
2.1关键字的生效顺序
- FROM:该关键字表示我们将从哪一个数据的表中获取数据,这也是最先生效的关键字。
- WHERE:该关键字表示我们将按照一定的规则筛选表中的数据,将不满足条件的数据筛选掉。
- GROUP BY:该关键字会将where条件筛选后的数据按照一定的规则进行分组。
- HAVING:该关键字会对分组后的数据按照一定的规则进行筛选,筛选掉不符合的数据。
- SELECT:讲过分组后筛选的数据就会被select挑选原则进行挑选,因为每一行数据可能有很多的字段并不是每一个字段都会被使用到。
- ORDER BY:在选择好对应的数据后,将符合条件的数据按照一定的规则进行排序。
- LIMIT/OFFSET:LIMIT用于限制返回结果的行数,OFFSET表示从第几行开始返回。这两个子句通常是一次查询最后执行的部分。
- UNION:将多个包含相同列数的、SELECT的结果集进行去重后合并,UNION ALL与UNION类似,但是UNION ALL不会对进行去重操作。
2.2数据源
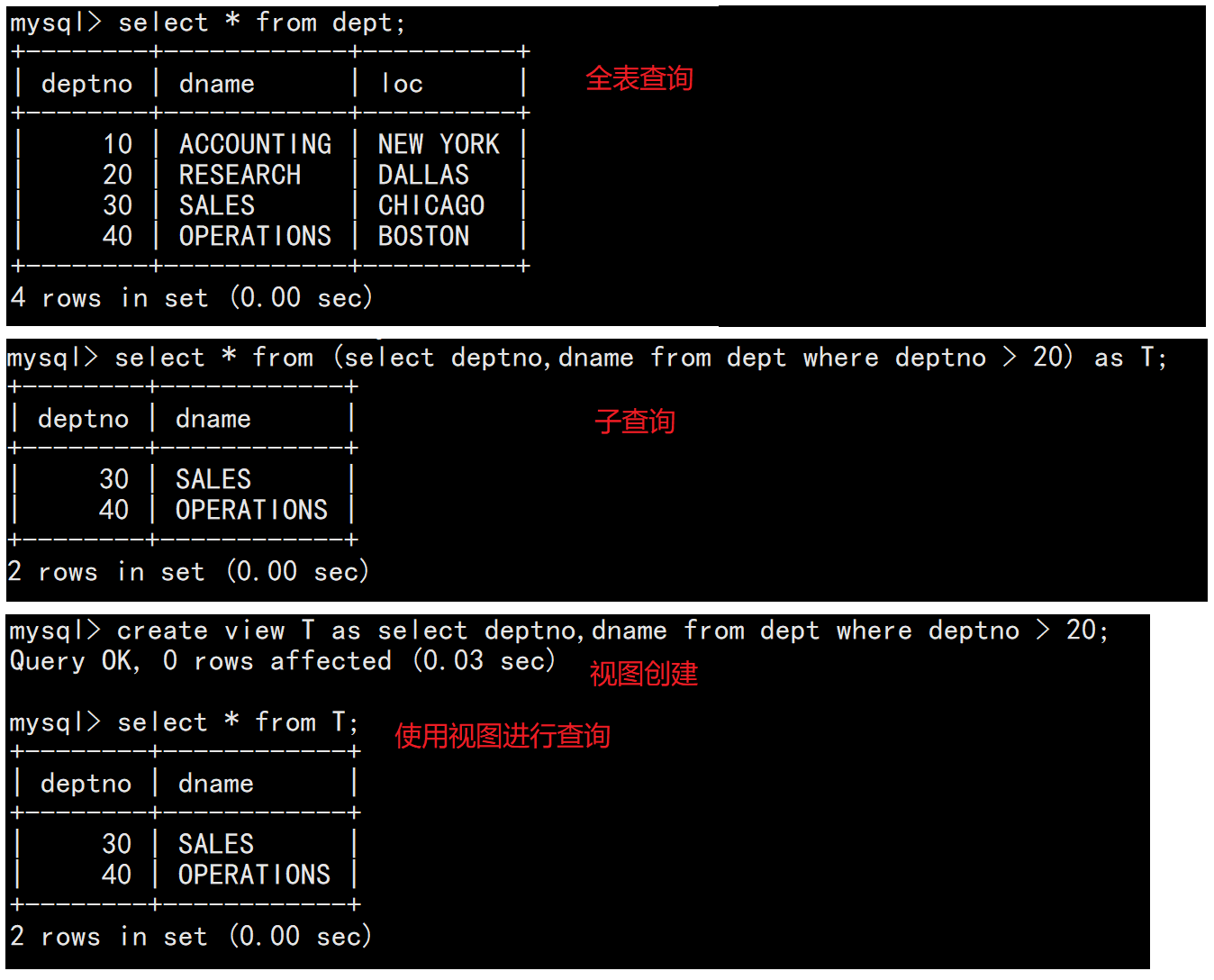
我们的from对数据的获取不仅可以从数据库表中获取,也可以从视图和子查询的结果中获取。
实际上所谓的视图你可以理解为是一个子查询以视图的形式进行了保存,这意味着如果某个查询事务常常被执行,那么我们就可以创建一个视图,然后从这个视图里获取数据而不是从数据库中重新筛选获取。需要说明的是——视图不会掉电丢失。
2.3可以使用聚合函数的关键字
关于这个问题,我们首先要了解聚合函数存在的意义是什么,聚合中的“聚”字代表有很多的数据,“合”字代表要将这些数据整合为一个值用来表示这些数据的一个整体的指标。
例如,COUNT 函数用于统计行数,它会对表中的一组行进行计数,将这组行的数量聚合成一个数字;SUM 函数用于计算某一列数值的总和,是将该列的多个值聚合为一个总和值;AVG 函数计算平均值,是先将一组数值进行求和聚合,再除以数量得到一个平均值;MAX 和 MIN 函数则是从一组数据中找出最大值或最小值,也是一种聚合操作,将一组数据聚合成一个代表最大或最小的值。
所以在where和group by阶段直接使用聚合函数是没有意义的,因为在where阶段我们往往是要确定筛选的条件,而不是使用聚合函数去得出一个能够描述全表数据特征的一个值,对于group by来说也是如此,但是对于select和having阶段就有所不同了,select关键字的意思很明显就是想查看值,如果我们想查看一个表的特征值这显然是合理的,having则是对经过分组后的数据添加约束条件,这就意味着如果我们此时使用聚合函数描述的是分组后的数据的特征值,显然我们可以根据分组特征值筛去一些不合理的分组。