基于图像处理的道路监控与路面障碍检测系统设计与实现 (源码+定制+开发) 图像处理 计算机视觉 道路监控系统 视频帧分析 道路安全监控 城市道路管理
博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。🍅获取源码请在文末联系我🍅
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
目录
YOLO介绍:
数据集介绍:
训练结果展示:
核心代码介绍:
训练模型代码:
项目实现界面:
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!
一、详细操作演示视频
在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流!

YOLO介绍:
YOLO 系列模型通过多层特征融合(Feature Fusion)在不同尺度上同时提取语义信息和空间细节,从而提升小目标和复杂场景下的检测精度。以 YOLOv3 为例,先利用主干网络(Darknet-53)在三种不同分辨率的特征图上做预测,然后通过上采样(Upsampling)与浅层特征拼接(Concatenation)实现自上而下的特征融合。YOLOv4/YOLOv5 则进一步引入了特征金字塔网络(FPN)和路径聚合网络(PANet),在自顶向下和自底向上的双向信息流中,加入空间金字塔池化(SPP)等模块,对多尺度特征进行丰富的上下文融合,以兼顾检测速度与精度。
数据集介绍:



训练结果展示:
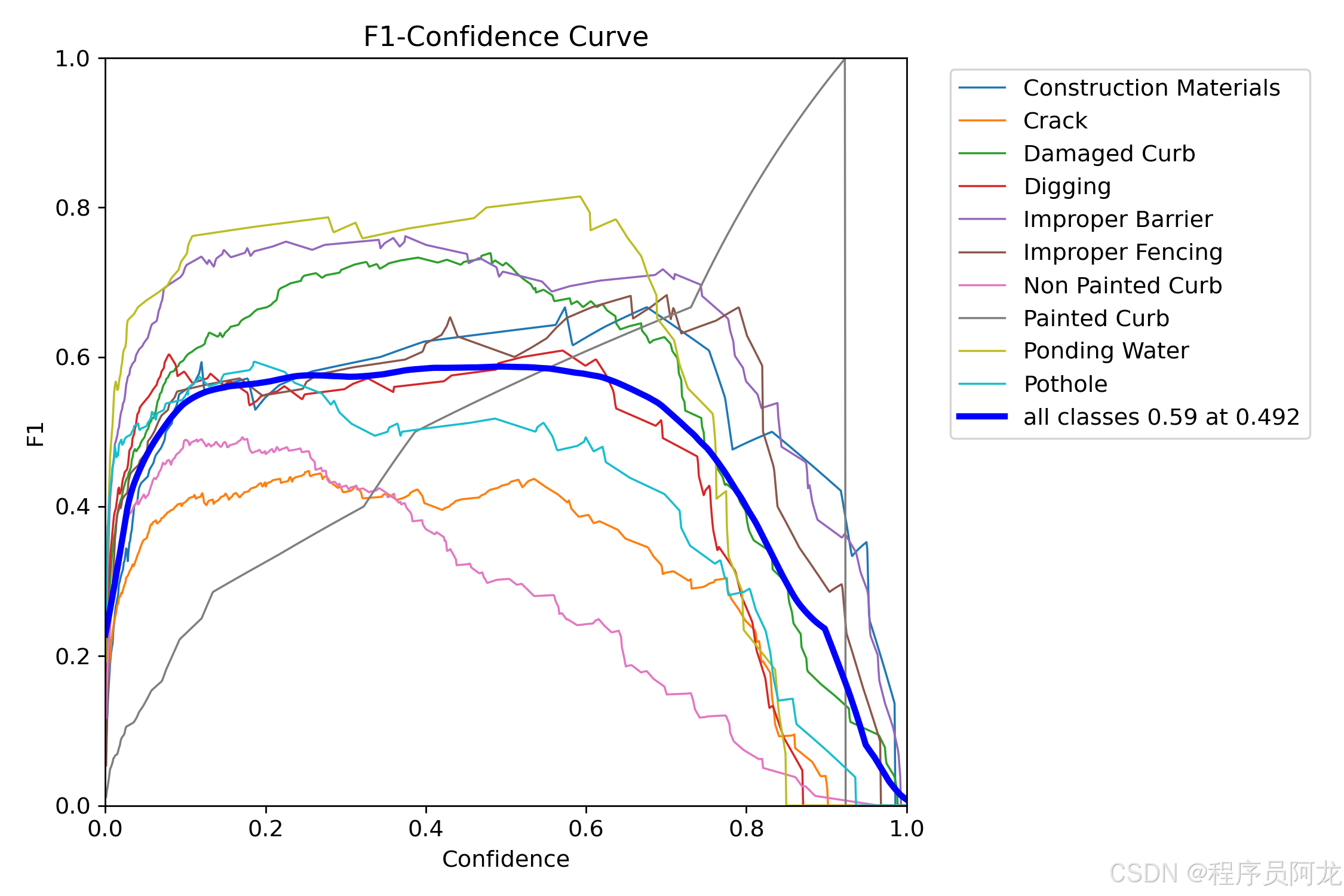
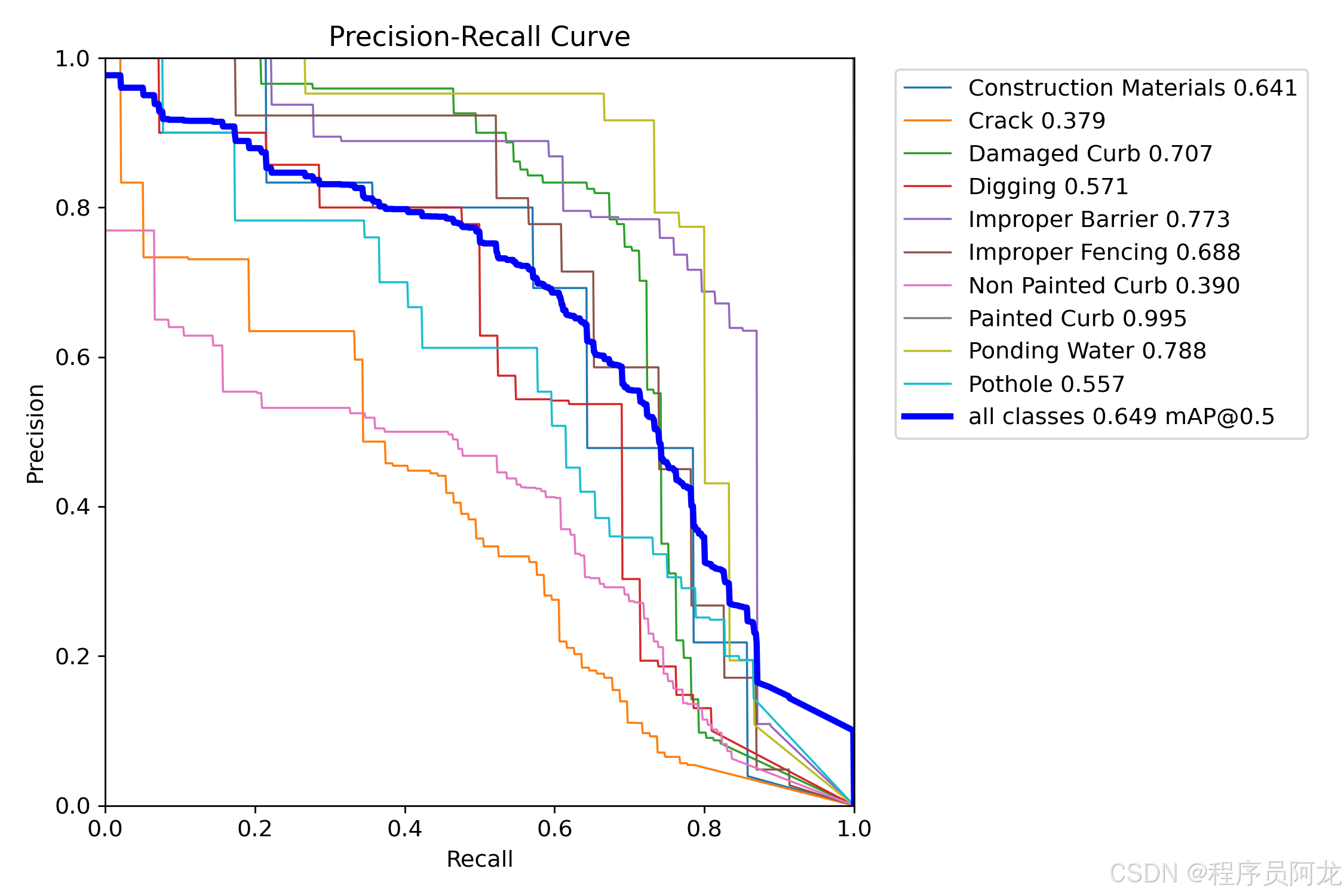



核心代码介绍:
import random
import tempfile
import time
import os
import cv2
import numpy as np
import streamlit as st
from QtFusion.path import abs_path
from QtFusion.utils import drawRectBoxfrom log import ResultLogger, LogTable
from model import Web_Detector
from chinese_name_list import Label_list
from ui_style import def_css_hitml
from utils import save_uploaded_file, concat_results, load_default_image, get_camera_names
import tempfile
from PIL import ImageFont, ImageDraw, Image
from datetime import datetimeimport numpy as np
import cv2
from hashlib import md5def calculate_polygon_area(points):# 计算多边形面积的函数return cv2.contourArea(points.astype(np.float32))def draw_with_chinese(img, text, position, font_size):# 假设这是一个自定义函数,用于在图像上绘制中文文本# 具体实现需要根据你的需求进行调整font = cv2.FONT_HERSHEY_SIMPLEXcolor = (255, 255, 255)thickness = 2cv2.putText(img, text, position, font, font_size, color, thickness, cv2.LINE_AA)return imgdef generate_color_based_on_name(name):# 使用哈希函数生成稳定的颜色hash_object = md5(name.encode())hex_color = hash_object.hexdigest()[:6] # 取前6位16进制数r, g, b = int(hex_color[0:2], 16), int(hex_color[2:4], 16), int(hex_color[4:6], 16)return (b, g, r) # OpenCV 使用BGR格式def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):"""在OpenCV图像上绘制中文文字"""# 将图像从 OpenCV 格式(BGR)转换为 PIL 格式(RGB)image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))draw = ImageDraw.Draw(image_pil)# 使用指定的字体font = ImageFont.truetype("simsun.ttc", font_size, encoding="unic")draw.text(position, text, font=font, fill=color)# 将图像从 PIL 格式(RGB)转换回 OpenCV 格式(BGR)return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)def adjust_parameter(image_size, base_size=1000):# 计算自适应参数,基于图片的最大尺寸max_size = max(image_size)return max_size / base_sizedef adjust_parameter(image_size, base_size=1000):max_size = max(image_size)return max_size / base_sizedef draw_detections(image, info, alpha=0.2):name, bbox, conf, cls_id, mask = info['class_name'], info['bbox'], info['score'], info['class_id'], info['mask']adjust_param = adjust_parameter(image.shape[:2])spacing = int(20 * adjust_param)if mask is None:x1, y1, x2, y2 = bboxaim_frame_area = (x2 - x1) * (y2 - y1)cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(5 * adjust_param))image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间else:mask_points = np.concatenate(mask)aim_frame_area = calculate_polygon_area(mask_points)mask_color = generate_color_based_on_name(name)try:overlay = image.copy()cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))# 计算面积、周长、圆度area = cv2.contourArea(mask_points.astype(np.int32))perimeter = cv2.arcLength(mask_points.astype(np.int32), True)circularity = 4 * np.pi * area / (perimeter ** 2) if perimeter > 0 else 0# 计算色彩mask = np.zeros(image.shape[:2], dtype=np.uint8)cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)color_points = cv2.findNonZero(mask)selected_points = color_points[np.random.choice(color_points.shape[0], 5, replace=False)]colors = np.mean([image[y, x] for x, y in selected_points[:, 0]], axis=0)color_str = f"({colors[0]:.1f}, {colors[1]:.1f}, {colors[2]:.1f})"# 绘制类别名称x, y = np.min(mask_points, axis=0).astype(int)image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间# 绘制面积、周长、圆度和色彩值# metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]# for idx, (metric_name, metric_value) in enumerate(metrics):# text = f"{metric_name}: {metric_value}"# image = draw_with_chinese(image, text, (x, y - y_offset - spacing * (idx + 1)),# font_size=int(35 * adjust_param))except Exception as e:print(f"An error occurred: {e}")return image, aim_frame_areadef calculate_polygon_area(points):"""计算多边形的面积,输入应为一个 Nx2 的numpy数组,表示多边形的顶点坐标"""if len(points) < 3: # 多边形至少需要3个顶点return 0return cv2.contourArea(points)def format_time(seconds):# 计算小时、分钟和秒hrs, rem = divmod(seconds, 3600)mins, secs = divmod(rem, 60)# 格式化为字符串return "{:02}:{:02}:{:02}".format(int(hrs), int(mins), int(secs))def save_chinese_image(file_path, image_array):"""保存带有中文路径的图片文件参数:file_path (str): 图片的保存路径,应包含中文字符, 例如 '示例路径/含有中文的文件名.png'image_array (numpy.ndarray): 要保存的 OpenCV 图像(即 numpy 数组)"""try:# 将 OpenCV 图片转换为 Pillow Image 对象image = Image.fromarray(cv2.cvtColor(image_array, cv2.COLOR_BGR2RGB))# 使用 Pillow 保存图片文件image.save(file_path)print(f"成功保存图像到: {file_path}")except Exception as e:print(f"保存图像失败: {str(e)}")class Detection_UI:"""检测系统类。Attributes:model_type (str): 模型类型。conf_threshold (float): 置信度阈值。iou_threshold (float): IOU阈值。selected_camera (str): 选定的摄像头。file_type (str): 文件类型。uploaded_file (FileUploader): 上传的文件。detection_result (str): 检测结果。detection_location (str): 检测位置。detection_confidence (str): 检测置信度。detection_time (str): 检测用时。"""def __init__(self):"""初始化行人跌倒检测系统的参数。"""# 初始化类别标签列表和为每个类别随机分配颜色self.cls_name = Label_listself.colors = [[random.randint(0, 255) for _ in range(3)] for _ inrange(len(self.cls_name))]# 设置页面标题self.title = "基于图像处理技术道路监控监测路面障碍设计"self.setup_page() # 初始化页面布局def_css_hitml() # 应用 CSS 样式# 初始化检测相关的配置参数self.model_type = Noneself.conf_threshold = 0.15 # 默认置信度阈值self.iou_threshold = 0.5 # 默认IOU阈值# 初始化相机和文件相关的变量self.selected_camera = Noneself.file_type = Noneself.uploaded_file = Noneself.uploaded_video = Noneself.custom_model_file = None # 自定义的模型文件# 初始化检测结果相关的变量self.detection_result = Noneself.detection_location = Noneself.detection_confidence = Noneself.detection_time = None# 初始化UI显示相关的变量self.display_mode = None # 设置显示模式self.close_flag = None # 控制图像显示结束的标志self.close_placeholder = None # 关闭按钮区域self.image_placeholder = None # 用于显示图像的区域self.image_placeholder_res = None # 图像显示区域self.table_placeholder = None # 表格显示区域self.log_table_placeholder = None # 完整结果表格显示区域self.selectbox_placeholder = None # 下拉框显示区域self.selectbox_target = None # 下拉框选中项self.progress_bar = None # 用于显示的进度条# 初始化FPS和视频时间指针self.FPS = 30self.timenow = 0# 初始化日志数据保存路径self.saved_log_data = abs_path("tempDir/log_table_data.csv", path_type="current")# 如果在 session state 中不存在logTable,创建一个新的LogTable实例if 'logTable' not in st.session_state:st.session_state['logTable'] = LogTable(self.saved_log_data)# 获取或更新可用摄像头列表if 'available_cameras' not in st.session_state:st.session_state['available_cameras'] = get_camera_names()self.available_cameras = st.session_state['available_cameras']# 初始化或获取识别结果的表格self.logTable = st.session_state['logTable']# 加载或创建模型实例if 'model' not in st.session_state:st.session_state['model'] = Web_Detector() # 创建Detector模型实例self.model = st.session_state['model']# 加载训练的模型权重self.model.load_model(model_path=abs_path("weights/yolov8s.pt", path_type="current"))# 为模型中的类别重新分配颜色self.colors = [[random.randint(0, 255) for _ in range(3)] for _ inrange(len(self.model.names))]self.setup_sidebar() # 初始化侧边栏布局def setup_page(self):# 设置页面布局# st.set_page_config(# page_title=self.title,# page_icon="REC",# initial_sidebar_state="expanded"# )# 居中显示标题st.markdown(f'<h1 style="text-align: center;">{self.title}</h1>',unsafe_allow_html=True)def setup_sidebar(self):"""设置 Streamlit 侧边栏。在侧边栏中配置模型设置、摄像头选择以及识别项目设置等选项。"""# 置信度阈值的滑动条self.conf_threshold = float(st.sidebar.slider("置信度设定", min_value=0.0, max_value=1.0, value=0.15))# IOU阈值的滑动条self.iou_threshold = float(st.sidebar.slider("IOU设定", min_value=0.0, max_value=1.0, value=0.25))# 设置侧边栏的模型设置部分st.sidebar.header("模型设置")# 选择模型类型的下拉菜单self.model_type = st.sidebar.selectbox("选择任务类型", ["检测任务","分割任务"])# 选择模型文件类型,可以是默认的或者自定义的model_file_option = st.sidebar.radio("模型设置", ["默认", "指定权重文件"])if model_file_option == "指定权重文件":# 如果选择自定义模型文件,则提供文件上传器model_file = st.sidebar.file_uploader("选择.pt文件", type="pt")# 如果上传了模型文件,则保存并加载该模型if model_file is not None:self.custom_model_file = save_uploaded_file(model_file)self.model.load_model(model_path=self.custom_model_file)self.colors = [[random.randint(0, 255) for _ in range(3)] for _ inrange(len(self.model.names))]elif model_file_option == "默认":if self.model_type == "检测任务":self.model.load_model(model_path=abs_path("./yolo11s.pt", path_type="current"))elif self.model_type == "分割任务":self.model.load_model(model_path=abs_path("./yolo11s-seg.pt", path_type="current"))# 为模型中的类别重新分配颜色self.colors = [[random.randint(0, 255) for _ in range(3)] for _ inrange(len(self.model.names))]# 设置侧边栏的摄像头配置部分st.sidebar.header("摄像头识别设置")# 选择摄像头的下拉菜单self.selected_camera = st.sidebar.selectbox("选择摄像头序号", self.available_cameras)# 设置侧边栏的识别项目设置部分st.sidebar.header("图片视频识别设置")# 选择文件类型的下拉菜单self.file_type = st.sidebar.selectbox("选择文件类型", ["图片文件", "视频文件"])# 根据所选的文件类型,提供对应的文件上传器if self.file_type == "图片文件":self.uploaded_file = st.sidebar.file_uploader("上传图片", type=["jpg", "png", "jpeg"])elif self.file_type == "视频文件":self.uploaded_video = st.sidebar.file_uploader("上传视频文件", type=["mp4"])# 提供相关提示信息,根据所选摄像头和文件类型的不同情况if self.selected_camera == "摄像头检测关闭":if self.file_type == "图片文件":st.sidebar.write("请选择图片并点击'开始运行'按钮,进行图片检测!")if self.file_type == "视频文件":st.sidebar.write("请选择视频并点击'开始运行'按钮,进行视频检测!")else:st.sidebar.write("请点击'开始检测'按钮,启动摄像头检测!")def load_model_file(self):if self.custom_model_file:self.model.load_model(self.custom_model_file)else:pass # 载入def process_camera_or_file(self):"""处理摄像头或文件输入。根据用户选择的输入源(摄像头、图片文件或视频文件),处理并显示检测结果。"""# 如果选择了摄像头输入if self.selected_camera != "摄像头检测关闭":self.logTable.clear_frames() # 清除之前的帧记录# 创建一个结束按钮self.close_flag = self.close_placeholder.button(label="停止")# 使用 OpenCV 捕获摄像头画面if str(self.selected_camera) == '0':camera_id = 0else:camera_id = self.selected_cameracap = cv2.VideoCapture(camera_id)self.uploaded_video = Nonefps = cap.get(cv2.CAP_PROP_FPS)self.FPS = fps# 设置总帧数为1000total_frames = 1000current_frame = 0self.progress_bar.progress(0) # 初始化进度条try:if len(self.selected_camera) < 8:camera_id = int(self.selected_camera)else:camera_id = self.selected_cameracap = cv2.VideoCapture(camera_id)# 获取和帧率fps = cap.get(cv2.CAP_PROP_FPS)self.FPS = fps# 创建进度条self.progress_bar.progress(0)# 创建保存文件的信息camera_savepath = './tempDir/camera'if not os.path.exists(camera_savepath):os.makedirs(camera_savepath)# ret, frame = cap.read()# height, width, layers = frame.shape# size = (width, height)## file_name = abs_path('tempDir/camera.avi', path_type="current")# out = cv2.VideoWriter(file_name, cv2.VideoWriter_fourcc(*'DIVX'), fps, size)while cap.isOpened() and not self.close_flag:ret, frame = cap.read()if ret:# 调节摄像头的分辨率# 设置新的尺寸new_width = 1080new_height = int(new_width * (9 / 16))# 调整图像尺寸frame = cv2.resize(frame, (new_width, new_height))framecopy = frame.copy()image, detInfo, _ = self.frame_process(frame, 'camera')# 保存目标结果图片if detInfo:file_name = abs_path(camera_savepath + '/' + str(current_frame + 1) + '.jpg', path_type="current")save_chinese_image(file_name, image)## # 保存目标结果视频# out.write(image)# 设置新的尺寸new_width = 1080new_height = int(new_width * (9 / 16))# 调整图像尺寸resized_image = cv2.resize(image, (new_width, new_height))resized_frame = cv2.resize(framecopy, (new_width, new_height))if self.display_mode == "叠加显示":self.image_placeholder.image(resized_image, channels="BGR", caption="视频画面")else:self.image_placeholder.image(resized_frame, channels="BGR", caption="原始画面")self.image_placeholder_res.image(resized_image, channels="BGR", caption="识别画面")self.logTable.add_frames(image, detInfo, cv2.resize(frame, (640, 640)))# 更新进度条progress_percentage = int((current_frame / total_frames) * 100)self.progress_bar.progress(progress_percentage)current_frame = (current_frame + 1) % total_frames # 重置进度条else:breakif self.close_flag:self.logTable.save_to_csv()self.logTable.update_table(self.log_table_placeholder)cap.release()# out.release()self.logTable.save_to_csv()self.logTable.update_table(self.log_table_placeholder)cap.release()# out.release()finally:if self.uploaded_video is None:name_in = Noneelse:name_in = self.uploaded_video.nameres = self.logTable.save_frames_file(fps=self.FPS, video_name=name_in)st.write("识别结果文件已经保存:" + self.saved_log_data)if res:st.write(f"结果的目标文件已经保存:{res}")else:# 如果上传了图片文件if self.uploaded_file is not None:self.logTable.clear_frames()self.progress_bar.progress(0)# 显示上传的图片source_img = self.uploaded_file.read()file_bytes = np.asarray(bytearray(source_img), dtype=np.uint8)image_ini = cv2.imdecode(file_bytes, 1)framecopy = image_ini.copy()image, detInfo, select_info = self.frame_process(image_ini, self.uploaded_file.name)save_chinese_image('./tempDir/' + self.uploaded_file.name, image)# self.selectbox_placeholder = st.empty()# self.selectbox_target = self.selectbox_placeholder.selectbox("目标过滤", select_info, key="22113")self.logTable.save_to_csv()self.logTable.update_table(self.log_table_placeholder) # 更新所有结果记录的表格# 设置新的尺寸new_width = 1080new_height = int(new_width * (9 / 16))# 调整图像尺寸resized_image = cv2.resize(image, (new_width, new_height))resized_frame = cv2.resize(framecopy, (new_width, new_height))if self.display_mode == "叠加显示":self.image_placeholder.image(resized_image, channels="BGR", caption="图片显示")else:self.image_placeholder.image(resized_frame, channels="BGR", caption="原始画面")self.image_placeholder_res.image(resized_image, channels="BGR", caption="识别画面")self.logTable.add_frames(image, detInfo, cv2.resize(image_ini, (640, 640)))self.progress_bar.progress(100)# 如果上传了视频文件elif self.uploaded_video is not None:# 处理上传的视频self.logTable.clear_frames()self.close_flag = self.close_placeholder.button(label="停止")video_file = self.uploaded_videotfile = tempfile.NamedTemporaryFile(delete=False, suffix='.mp4')try:tfile.write(video_file.read())tfile.flush()tfile.seek(0) # 确保文件指针回到文件开头cap = cv2.VideoCapture(tfile.name)# 获取视频总帧数和帧率total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))fps = cap.get(cv2.CAP_PROP_FPS)self.FPS = fps# 计算视频总长度(秒)total_length = total_frames / fps if fps > 0 else 0print('视频时长:' + str(total_length)[:4] + 's')# 创建进度条self.progress_bar.progress(0)current_frame = 0# 创建保存文件的信息video_savepath = './tempDir/' + self.uploaded_video.nameif not os.path.exists(video_savepath):os.makedirs(video_savepath)# ret, frame = cap.read()# height, width, layers = frame.shape# size = (width, height)# file_name = abs_path('tempDir/' + self.uploaded_video.name + '.avi', path_type="current")# out = cv2.VideoWriter(file_name, cv2.VideoWriter_fourcc(*'DIVX'), fps, size)while cap.isOpened() and not self.close_flag:ret, frame = cap.read()if ret:framecopy = frame.copy()# 计算当前帧对应的时间(秒)current_time = current_frame / fpsif current_time < total_length:current_frame += 1current_time_str = format_time(current_time)image, detInfo, _ = self.frame_process(frame, self.uploaded_video.name,video_time=current_time_str)# 保存目标结果图片if detInfo:# 将字符串转换为 datetime 对象time_obj = datetime.strptime(current_time_str, "%H:%M:%S")# 将 datetime 对象格式化为所需的字符串格式formatted_time = time_obj.strftime("%H_%M_%S")file_name = abs_path(video_savepath + '/' + formatted_time + '_' + str(current_frame) + '.jpg',path_type="current")save_chinese_image(file_name, image)# # 保存目标结果视频# out.write(image)# 设置新的尺寸new_width = 1080new_height = int(new_width * (9 / 16))# 调整图像尺寸resized_image = cv2.resize(image, (new_width, new_height))resized_frame = cv2.resize(framecopy, (new_width, new_height))if self.display_mode == "叠加显示":self.image_placeholder.image(resized_image, channels="BGR", caption="视频画面")else:self.image_placeholder.image(resized_frame, channels="BGR", caption="原始画面")self.image_placeholder_res.image(resized_image, channels="BGR", caption="识别画面")self.logTable.add_frames(image, detInfo, cv2.resize(frame, (640, 640)))# 更新进度条if total_length > 0:progress_percentage = int(((current_frame + 1) / total_frames) * 100)try:self.progress_bar.progress(progress_percentage)except:passcurrent_frame += 1else:breakif self.close_flag:self.logTable.save_to_csv()self.logTable.update_table(self.log_table_placeholder)cap.release()# out.release()self.logTable.save_to_csv()self.logTable.update_table(self.log_table_placeholder)cap.release()# out.release()finally:if self.uploaded_video is None:name_in = Noneelse:name_in = self.uploaded_video.nameres = self.logTable.save_frames_file(fps=self.FPS, video_name=name_in)st.write("识别结果文件已经保存:" + self.saved_log_data)if res:st.write(f"结果的目标文件已经保存:{res}")tfile.close()# 如果不需要再保留临时文件,可以在处理完后删除print(tfile.name + ' 临时文件可以删除')# os.remove(tfile.name)else:st.warning("请选择摄像头或上传文件。")def toggle_comboBox(self, frame_id):"""处理并显示指定帧的检测结果。Args:frame_id (int): 指定要显示检测结果的帧ID。根据用户选择的帧ID,显示该帧的检测结果和图像。"""# 确保已经保存了检测结果if len(self.logTable.saved_results) > 0:frame = self.logTable.saved_images_ini[-1] # 获取最近一帧的图像image = frame # 将其设为当前图像# 遍历所有保存的检测结果for i, detInfo in enumerate(self.logTable.saved_results):if frame_id != -1:# 如果指定了帧ID,只处理该帧的结果if frame_id != i:continueif len(detInfo) > 0:name, bbox, conf, use_time, cls_id = detInfo # 获取检测信息label = '%s %.0f%%' % (name, conf * 100) # 构造标签文本disp_res = ResultLogger() # 创建结果记录器res = disp_res.concat_results(name, bbox, str(round(conf, 2)), str(use_time)) # 合并结果self.table_placeholder.table(res) # 在表格中显示结果# 如果有保存的初始图像if len(self.logTable.saved_images_ini) > 0:if len(self.colors) < cls_id:self.colors = [[random.randint(0, 255) for _ in range(3)] for _ inrange(cls_id+1)]image = drawRectBox(image, bbox, alpha=0.2, addText=label,color=self.colors[cls_id]) # 绘制检测框和标签# 设置新的尺寸并调整图像尺寸new_width = 1080new_height = int(new_width * (9 / 16))resized_image = cv2.resize(image, (new_width, new_height))resized_frame = cv2.resize(frame, (new_width, new_height))# 根据显示模式显示处理后的图像或原始图像if self.display_mode == "叠加显示":self.image_placeholder.image(resized_image, channels="BGR", caption="识别画面")else:self.image_placeholder.image(resized_frame, channels="BGR", caption="原始画面")self.image_placeholder_res.image(resized_image, channels="BGR", caption="识别画面")def frame_process(self, image, file_name,video_time = None):"""处理并预测单个图像帧的内容。Args:image (numpy.ndarray): 输入的图像。file_name (str): 处理的文件名。Returns:tuple: 处理后的图像,检测信息,选择信息列表。对输入图像进行预处理,使用模型进行预测,并处理预测结果。"""# image = cv2.resize(image, (640, 640)) # 调整图像大小以适应模型pre_img = self.model.preprocess(image) # 对图像进行预处理# 更新模型参数params = {'conf': self.conf_threshold, 'iou': self.iou_threshold}self.model.set_param(params)t1 = time.time()pred = self.model.predict(pre_img) # 使用模型进行预测t2 = time.time()use_time = t2 - t1 # 计算单张图片推理时间aim_area = 0 #计算目标面积det = pred[0] # 获取预测结果# 初始化检测信息和选择信息列表detInfo = []select_info = ["全部目标"]# 如果有有效的检测结果if det is not None and len(det):det_info = self.model.postprocess(pred) # 后处理预测结果if len(det_info):disp_res = ResultLogger()res = Nonecnt = 0# 遍历检测到的对象for info in det_info:name, bbox, conf, cls_id, mask = info['class_name'], info['bbox'], info['score'], info['class_id'], info['mask']# 绘制检测框、标签和面积信息image,aim_frame_area = draw_detections(image, info, alpha=0.5)# image = drawRectBox(image, bbox, alpha=0.2, addText=label, color=self.colors[cls_id])res = disp_res.concat_results(name, bbox, str(int(aim_frame_area)),video_time if video_time is not None else str(round(use_time, 2)))# 添加日志条目self.logTable.add_log_entry(file_name, name, bbox, int(aim_frame_area), video_time if video_time is not None else str(round(use_time, 2)))# 记录检测信息detInfo.append([name, bbox, int(aim_frame_area), video_time if video_time is not None else str(round(use_time, 2)), cls_id])# 添加到选择信息列表select_info.append(name + "-" + str(cnt))cnt += 1# 在表格中显示检测结果self.table_placeholder.table(res)return image, detInfo, select_infodef frame_table_process(self, frame, caption):# 显示画面并更新结果self.image_placeholder.image(frame, channels="BGR", caption=caption)# 更新检测结果detection_result = "None"detection_location = "[0, 0, 0, 0]"detection_confidence = str(random.random())detection_time = "0.00s"# 使用 display_detection_results 函数显示结果res = concat_results(detection_result, detection_location, detection_confidence, detection_time)self.table_placeholder.table(res)# 添加适当的延迟cv2.waitKey(1)def setupMainWindow(self):""" 运行检测系统。 """# st.title(self.title) # 显示系统标题st.write("--------")st.write("———————————————————————————————————————————Vision-Studio————————————————————————————————————————————")st.write("--------")# 插入一条分割线# 创建列布局,将表格移到最右侧col1, col2, col3 = st.columns([4, 1, 2])# 在第一列设置显示模式的选择with col1:self.display_mode = st.radio("单/双画面显示设置", ["叠加显示", "对比显示"])# 根据显示模式创建用于显示视频画面的空容器if self.display_mode == "叠加显示":self.image_placeholder = st.empty()if not self.logTable.saved_images_ini:self.image_placeholder.image(load_default_image(), caption="原始画面")else:# "双画面显示"self.image_placeholder = st.empty()self.image_placeholder_res = st.empty()if not self.logTable.saved_images_ini:self.image_placeholder.image(load_default_image(), caption="原始画面")self.image_placeholder_res.image(load_default_image(), caption="识别画面")# 显示用的进度条self.progress_bar = st.progress(0)# 创建一个空的结果表格res = concat_results("None", "[0, 0, 0, 0]", "0.00", "0.00s")# 在最右侧列设置识别结果表格的显示with col3:self.table_placeholder = st.empty() # 调整到最右侧显示self.table_placeholder.table(res)# 创建一个导出结果的按钮st.write("---------------------")if st.button("导出结果"):self.logTable.save_to_csv()if self.uploaded_video is None:name_in = Noneelse:name_in = self.uploaded_video.nameres = self.logTable.save_frames_file(fps=self.FPS, video_name=name_in)st.write("识别结果文件已经保存:" + self.saved_log_data)if res:st.write(f"结果的目标文件已经保存:{res}")self.logTable.clear_data()# 显示所有结果记录的空白表格self.log_table_placeholder = st.empty()self.logTable.update_table(self.log_table_placeholder)# 在第五列设置一个空的停止按钮占位符with col2:st.write("")self.close_placeholder = st.empty()# 在第二列处理目标过滤# with col2:# self.selectbox_placeholder = st.empty()# detected_targets = ["全部目标"] # 初始化目标列表## 遍历并显示检测结果# for i, info in enumerate(self.logTable.saved_results):# name, bbox, conf, use_time, cls_id = info# detected_targets.append(name + "-" + str(i))# self.selectbox_target = self.selectbox_placeholder.selectbox("目标过滤", detected_targets)## 处理目标过滤的选择# for i, info in enumerate(self.logTable.saved_results):# name, bbox, conf, use_time, cls_id = info# if self.selectbox_target == name + "-" + str(i):# self.toggle_comboBox(i)# elif self.selectbox_target == "全部目标":# self.toggle_comboBox(-1)with col2:st.write("")run_button = st.button("开始检测")if run_button:self.process_camera_or_file() # 运行摄像头或文件处理else:# 如果没有保存的图像,则显示默认图像if not self.logTable.saved_images_ini:self.image_placeholder.image(load_default_image(), caption="原始画面")if self.display_mode == "对比显示":self.image_placeholder_res.image(load_default_image(), caption="识别画面")# 实例化并运行应用
if __name__ == "__main__":app = Detection_UI()app.setupMainWindow()
训练模型代码:
import osimport torch
import yaml
from ultralytics import YOLO # 导入YOLO模型
from QtFusion.path import abs_path
device = "0" if torch.cuda.is_available() else "cpu"if __name__ == '__main__': # 确保该模块被直接运行时才执行以下代码workers = 1batch = 2data_name = "data"data_path = abs_path(f'datasets/{data_name}/{data_name}.yaml', path_type='current') # 数据集的yaml的绝对路径unix_style_path = data_path.replace(os.sep, '/')# 获取目录路径directory_path = os.path.dirname(unix_style_path)# 读取YAML文件,保持原有顺序with open(data_path, 'r') as file:data = yaml.load(file, Loader=yaml.FullLoader)# 修改path项if 'path' in data:data['path'] = directory_path# 将修改后的数据写回YAML文件with open(data_path, 'w') as file:yaml.safe_dump(data, file, sort_keys=False)if 'train' in data and 'val' in data and 'test' in data:data['train'] = directory_path + '/train'data['val'] = directory_path + '/val'data['test'] = directory_path + '/test'# 将修改后的数据写回YAML文件with open(data_path, 'w') as file:yaml.safe_dump(data, file, sort_keys=False)# 注意!不同模型大小不同,对设备等要求不同,如果要求较高的模型【报错】则换其他模型测试即可model = YOLO(model='./ultralytics/cfg/models/v11/yolo11.yaml', task='detect').load('./yolo11s.pt') # 加载预训练的YOLOv11模型# model = YOLO(model=r'F:\last\codeseg\200+种YOLOv11检测分割算法改进源码配置文件大全\改进YOLOv11检测模型配置文件\yolo11-DBB.yaml', task='detect').load('./yolo11s.pt') # yolo11-efficientViT.yaml、yolo11-ADown.yaml、...results2 = model.train( # 开始训练模型data=data_path, # 指定训练数据的配置文件路径device=device, # 自动选择进行训练workers=workers, # 指定使用2个工作进程加载数据imgsz=640, # 指定输入图像的大小为640x640epochs=200, # 指定训练100个epochbatch=batch, # 指定每个批次的大小为8name='train_v8_' + data_name # 指定训练任务的名称)

项目实现界面:
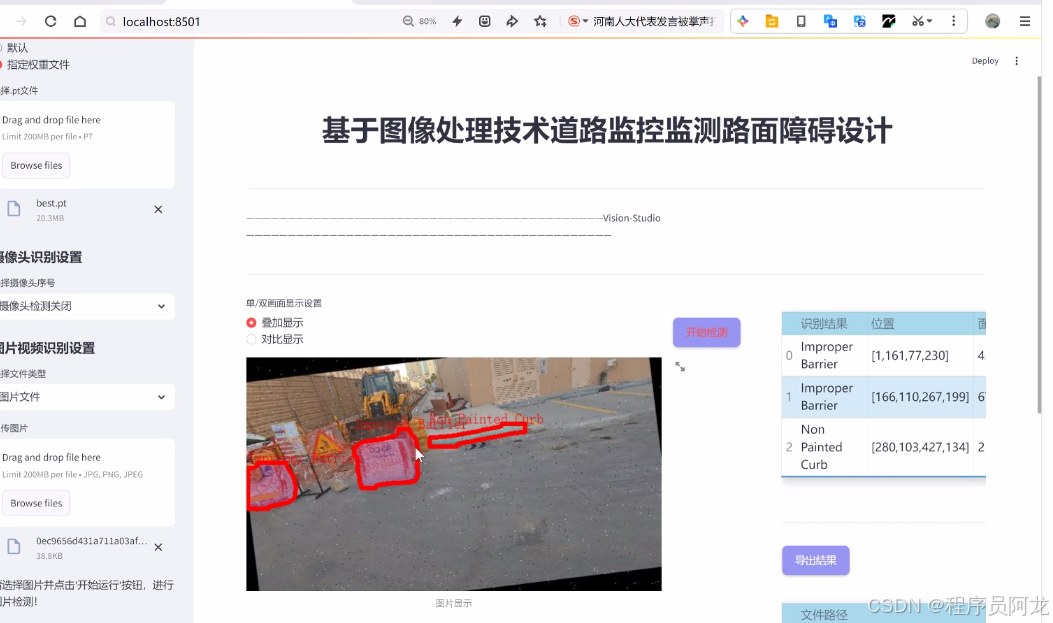

1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

源码获取
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏