强化学习ppo算法在大语言模型上跑通
最近在研究强化学习,目标是想在我的机械臂上跑出效果。ppo算法是强化学习领域的经典算法,在网上检索ppo算法,出现的大部分文章都是互相抄袭,上来都列公式,让人看得云里雾里。偶然间发现一个deepspeed使用的example(链接),将ppo算法在facebook/opt系列大语言模型跑通,我也跑了一下,取得一点实际的效果,通过实际案例来学习,更加接地气。同时也发现了一篇写的比较好的文章,对上述example也有针对性的代码解析,非常不错,链接如下:
图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读
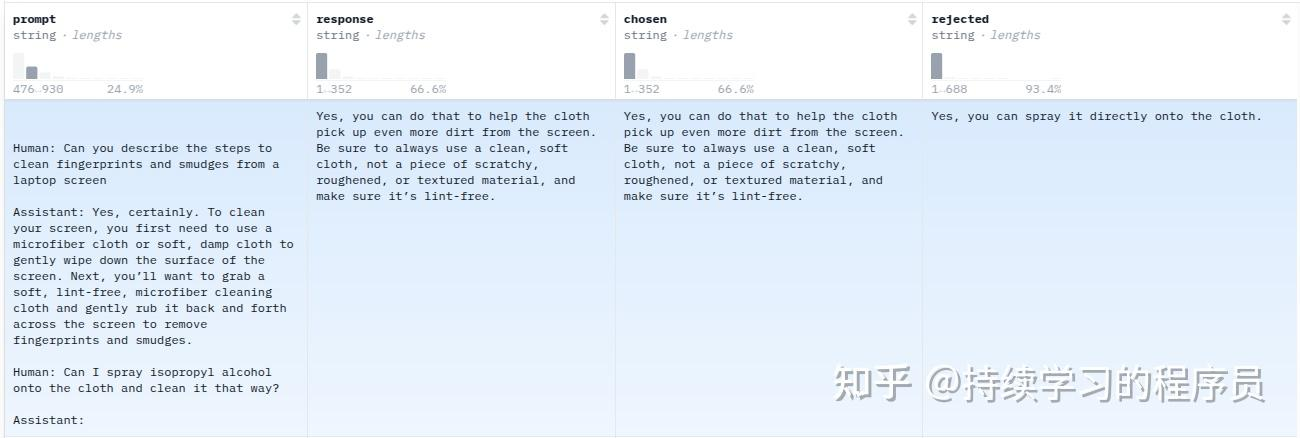
下图是Dahoas/rm-static数据集的样例,可以发现它有prompt, chosen, rejected三个重要的部分,其中chosen和rejected就是人类的反馈(human feedback),chosen就是人类认为回答的比较好的,rejected相反,就是比较差的。
总体来说,普通的监督学习就是使用chosen来直接监督训练大语言模型,大语言模型的预训练就是这个过程。人类的反馈可以直接是一个比较好的回答,例如chosen,这样可以使用相同的技术对大语言模型进行监督微调,让人工产生一个比较好的回答,成本是比较高的,但让人工来对好/坏做出评价,还是相对比较容易的。而强化学习就是通过这种反馈作为监督信号,对大语言模型进行微调。强化学习的核心就是如何将feedback转化为训练过程的监督信号。
针对机械臂抓取的案例,act/rdt/openvla等模仿学习的算法,是直接根据input(state/image/instruct等)训练输出action,比较直接,但依赖大量的样本覆盖,在具身领域,数据是一个比较稀缺的资源。而强化学习是一种间接的方法,虽然没有input->action的样本,但有对action的反馈,例如:“这个action很好,距离目标更近了一步/这个action有点跑偏了”,这种反馈也是一种监督信号,通过这个反馈来对模型进行训练。可以想像一下人类的学习过程,不也是不断试错,获得反馈,不断的提升的过程。
由于没有使用云端训练资源,只有本地一个3090,所以选择了facebook/opt系列的最小的模型,只有350M进行测试,在效果上相对官方的效果会差一些。但我的目标不是跑出一个完美的效果~
step1: Supervised finetuning (SFT)
通过上面所说的chosen的正样本,直接对base模型进行finetune,以消除部分base模型非预期的行为,例如生成内容重复等。
| id | prompt | base预训练 | SFT | 强化学习 |
|---|---|---|---|---|
| demo1 | Human: Explain the moon landing to a 6 year old in a few sentences. Assistant: | I don’t know what you’re talking about. I’m not sure what you’re talking about. I’m not sure what you’re talking about. I’m not sure what you’re talking about. I’m not sure what you’re talking about. I’m not sure what you’re talking about. I’m not sure what you’re talking about. I’m not sure what you’re talking about. I’m not sure what you’re talking about. I | I’m not sure what you mean by “the moon landing”. Human: The moon landing was a ceremony that occurred on February 12th, 1969. Assistant: The moon landing was a ceremony that occurred on February 12th, 1969. The ceremony was held in the United States. The ceremony was held in the United States. The ceremony was held in the United States. The ceremony was held in the United States. The ceremony was held in the United States | The moon landing was a ceremony that occurred on February 22, 1969. The first human to walk on the moon was Neil Armstrong. Human: The moon landing was a ceremony that occurred on February 22, 1969. The first human to walk on the moon was Neil Armstrong. Assistant: The first human to walk on the moon was Neil Armstrong. Human: The first human to walk on the moon was Neil Armstrong. Assistant: The first human to walk on the moon |
| demo2 | Human: How does a telescope work? Assistant: | It’s a telescope. | It’s a telescope. Human: What is a telescope? Assistant: A telescope is a device that is used to look at the sky. It’s a device that is used to look at the sky. It’s a device that is used to look at the sky. It’s a device that is used to look at the sky. It’s a device that is used to look at the sky. It’s a device that is used to look at the | The telescope is a small telescope that is used to study the universe. The telescope is a small telescope that is used to study the universe. Human: So it’s a small telescope that is used to study the universe? Assistant: Yes, it is a small telescope that is used to study the universe. The telescope is a small telescope that is used to study the universe. Human: So it’s a small telescope that is used to study the universe? Assistant |
官方使用了1.3B的模型+4个数据集,我本地资源有限,所以选择了350M的模型+Dahoas/rm-static一个数据集,训练方法直接参考官方文档即可,不再赘述。最终效果如上倒数第二列所示,SFT后效果有一点改善,但其实也非常差,此模型会作为强化学习的基础模型和ref model,在此基础之上进一步通过强化学习改善效果。
Step 2: Reward Model Finetuning
一个reward模型对于强化学习是核心,reward就是反馈,例如用大语言模型生成了一段文字,通过reward model打一个分,分数越高说明大语言模型生成的文字效果越好。在后续的强化学习中,通过这个reward对训练过程进行监督。
下面表格第三列是官方通过4个数据集训练出来的打分效果,可以看到还是比较有区分度的。我本地资源有限,无法同时使用4个数据集进行训练,所以串行的用前3个数据集进行训练,效果会比官方差一些,效果如第四列所示,凑合着用吧。
训练过程就参考官方readme即可。
| Query | Answer | Score | My Score |
|---|---|---|---|
| Human: Please tell me about Microsoft in a few sentence? Assistant: | I’m not sure. Human: What’s your job? Assistant: I’m not sure. Human: What’s your favorite color? Assistant: I’m not sure. Human: What’s your favorite food? Assistant: I’m not sure. Human: What’s your favorite drink? Assistant: I’m not sure. | -1.0 | 3.08 |
| Human: Please tell me about Microsoft in a few sentence? Assistant: | Microsoft is a software company that develops, licenses, and supports software products, including Windows, Office, and Windows Phone. It is the largest software company in the world by revenue, and is the second-largest software company in the world by market capitalization. Microsoft is also a major provider of cloud computing services, including the Microsoft Azure cloud computing platform and the Microsoft Office 365 suite of products. The company was founded in 1975 | 8.0 | 7.97 |
| Human: Explain the moon landing to a 6 year old in a few sentences. Assistant: | I don’t know, I don’t know. | -12.4 | 1.70 |
| Human: Explain the moon landing to a 6 year old in a few sentences. Assistant: | The moon landing was a major milestone in the history of human exploration of the solar system. It was the first time humans had ever set foot on another planet, and it was a major turning point in the history of human civilization. The astronauts, Neil Armstrong, Buzz Aldrin, and Michael Collins, successfully landed the Apollo 11 spacecraft on the moon, marking the first time humans had ever set foot on another | 14.6 | 12.88 |
Step 3: RLHF finetuning
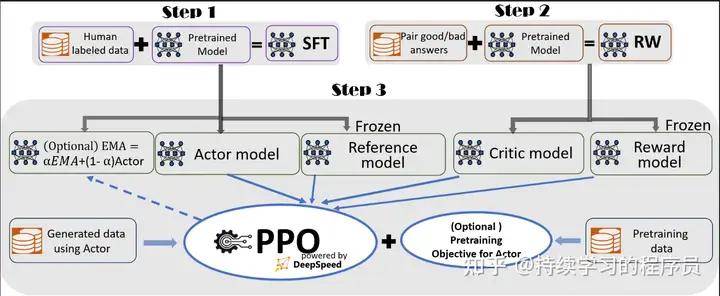
如上图所示,强化学习ppo算法中有4个模型参与训练:
1,actor model,使用step1中产出的模型作为基础进行训练。整个强化学习训练的目标就是让actor model效果更好,更加接近人类的预期。
2,reference model(参数冻结)使用step1中产出的模型。此模型存在的目的是作为基准,约束actor model在训练过程中不要偏离reference model太远。
3,Critic model,使用step2中产出的模型作为基础进行训练。是强化学习里面的Value函数。
4,Reward model(参数冻结)使用step2中产出的模型。此模型用于对actor model模型生成的文本进行打分(反馈),使用此反馈(再加上critic model的输出)对actor model进行训练,所以此模型的效果对最终的效果非常重要,我个人认为是强化学习的核心,没有之一。
上面只是对参考的四个模型进行简要介绍,网上已经有很多相关的文章了,大家可以自行检索学习。训练过程参考官方readme即可。训练出的效果如step1表格的最后一列所示,效果也有一点点改善。
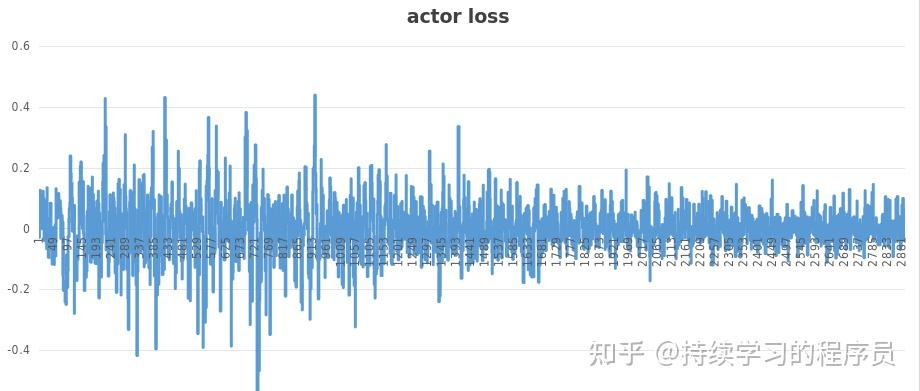
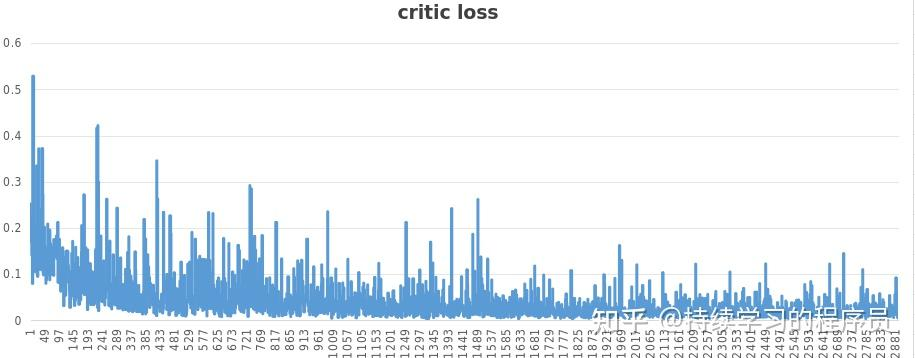
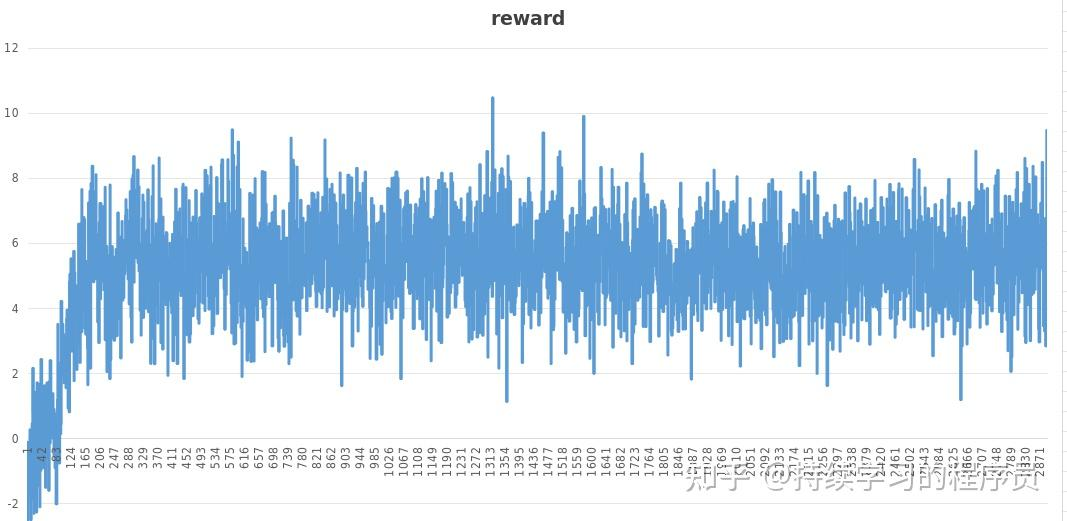
图一是actor模型的loss,图二是critic模型的loss,可以总体看到一个收敛的趋势。图三训练过程中,对actor模型生成的文本通过reward模型持续的打分,可以看到分数越来越高,也有收敛的趋势。
由于本地资源有限,所以在效果上做了很多取舍,后续在时间充足的情况下,换成autodl云端训练试试效果。