用 Python 分析 IRIS 数据集:概率论与数理统计实战教程
一、引言
在数据科学的世界里,IRIS 数据集就像是一位常客,频繁出现在各种数据分析和机器学习的案例中。它包含 150 条记录,分属 Setosa、Versicolour、Virginica 这 3 种鸢尾花类别,每条记录还带有萼片长度、萼片宽度、花瓣长度、花瓣宽度这 4 个特征。今天,咱们就用 Python 和概率论与数理统计的知识,好好探索一下这个数据集!
二、任务一:数据初步分析
(一)计算描述性统计量
描述性统计量能帮我们快速了解数据的大致情况。在 Python 里,用pandas和scipy.stats库就能轻松搞定。
import pandas as pd
from scipy.stats import skew, kurtosisiris = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',names=['sepal_length','sepal_width', 'petal_length', 'petal_width','species'])def calculate_statistics(data):stats = pd.DataFrame()for column in data.select_dtypes(include=[np.number]).columns:stats[column] = [data[column].mean(),data[column].var(),skew(data[column]),kurtosis(data[column])]stats.index = ['均值', '方差', '偏度', '峰度']return statsstats = calculate_statistics(iris)
print("\n描述性统计分析结果:")
print(stats)
calculate_statistics函数,它遍历数据集中的数值型列,计算每列的均值、方差、偏度和峰度,最后整理成一个 DataFrame 展示出来。
(二)绘制直方图和箱线图
直方图和箱线图能直观地展示数据的分布特性。借助seaborn和matplotlib库,绘制过程非常简单。
import matplotlib.pyplot as plt
import seaborn as snsplt.figure(figsize=(15, 10))
for i, feature in enumerate(iris.select_dtypes(include=[np.number]).columns):plt.subplot(2, 4, i + 1)sns.histplot(data=iris, x=feature, kde=True)plt.title(f'{feature}的直方图')for i, feature in enumerate(iris.select_dtypes(include=[np.number]).columns):plt.subplot(2, 4, i + 5)sns.boxplot(data=iris, y=feature)plt.title(f'{feature}的箱线图')plt.tight_layout()
plt.savefig('task1_plots.png')
plt.close()
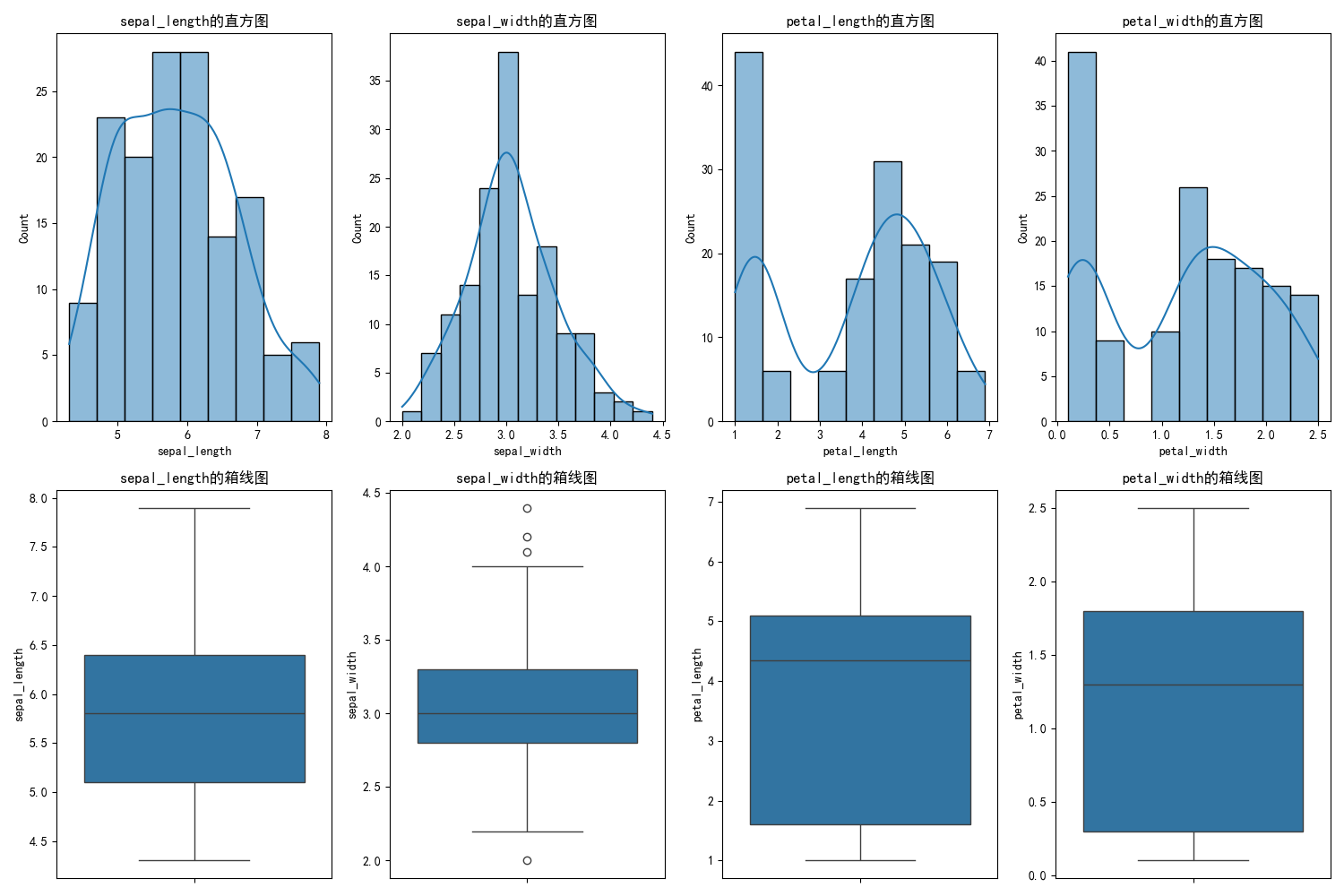
在这段代码里,两个for循环分别绘制直方图和箱线图。sns.histplot绘制直方图并添加核密度估计曲线(kde=True),sns.boxplot绘制箱线图。
三、任务二:单变量假设检验
我们来检验花瓣长度的均值是不是 4.5,分别用 Z 检验(假设方差已知)和 t 检验(假设方差未知)。
import numpy as np
from scipy import statsmu0 = 4.5
alpha = 0.05
petal_length = iris['petal_length']# Z检验
sample_mean = np.mean(petal_length)
sample_std = np.std(petal_length, ddof=1)
n = len(petal_length)
z_stat = (sample_mean - mu0) / (sample_std / np.sqrt(n))
p_value_z = 2 * (1 - stats.norm.cdf(abs(z_stat)))
print("\nZ检验结果:")
print(f"Z统计量: {z_stat:.4f}")
print(f"P值: {p_value_z:.4f}")
print(f"在显著性水平{alpha}下,", "拒绝原假设" if p_value_z < alpha else "接受原假设")# t检验
t_stat, p_value_t = stats.ttest_1samp(petal_length, mu0)
print("\nt检验结果:")
print(f"t统计量: {t_stat:.4f}")
print(f"P值: {p_value_t:.4f}")
print(f"在显著性水平{alpha}下,", "拒绝原假设" if p_value_t < alpha else "接受原假设")
Z 检验关键是计算z_stat和p_value_z,t 检验直接用stats.ttest_1samp函数就能得到 t 统计量和 P 值,然后根据 P 值和显著性水平比较,决定接受还是拒绝原假设。
四、任务三:两组比较
比较 Setosa 和 Versicolour 两类花的萼片宽度均值有没有显著差异,先检验方差是否相等,再做两独立样本 t 检验。
from scipy import statssetosa_width = iris[iris['species'] == 'Iris-setosa']['sepal_width']
versicolor_width = iris[iris['species'] == 'Iris-versicolor']['sepal_width']# 检验方差是否相等(Levene检验)
levene_stat, levene_p = stats.levene(setosa_width, versicolor_width)
print("Levene检验结果:")
print(f"统计量: {levene_stat:.4f}")
print(f"P值: {levene_p:.4f}")
print("两组方差", "相等" if levene_p >= 0.05 else "不相等")# 两独立样本t检验
t_stat, p_value = stats.ttest_ind(setosa_width, versicolor_width, equal_var=(levene_p >= 0.05))
print("\n两独立样本t检验结果:")
print(f"t统计量: {t_stat:.4f}")
print(f"P值: {p_value:.4f}")
print(f"在显著性水平0.05下,两组均值", "有显著差异" if p_value < 0.05 else "无显著差异")
stats.levene做 Levene 检验判断方差是否相等,stats.ttest_ind进行两独立样本 t 检验,equal_var参数根据方差检验结果来设置。
五、任务四:参数估计
对 Virginica 类别中花瓣长度的均值和标准差进行估计,有点估计和构造 95% 置信区间两种方法。
import numpy as np
from scipy import statsvirginica_length = iris[iris['species'] == 'Iris-virginica']['petal_length']# 点估计
mean_estimate = np.mean(virginica_length)
std_estimate = np.std(virginica_length, ddof=1)
print("点估计结果:")
print(f"均值的点估计: {mean_estimate:.4f}")
print(f"标准差的点估计: {std_estimate:.4f}")# 区间估计
n = len(virginica_length)
confidence = 0.95
df = n - 1
t_value = stats.t.ppf((1 + confidence) / 2, df)
mean_se = std_estimate / np.sqrt(n)
mean_ci = (mean_estimate - t_value * mean_se,mean_estimate + t_value * mean_se)chi2_lower = stats.chi2.ppf((1 - confidence) / 2, df)
chi2_upper = stats.chi2.ppf((1 + confidence) / 2, df)
std_ci = (np.sqrt((n - 1) * std_estimate**2 / chi2_upper),np.sqrt((n - 1) * std_estimate**2 / chi2_lower))
print("\n95%置信区间:")
print(f"均值的置信区间: ({mean_ci[0]:.4f}, {mean_ci[1]:.4f})")
print(f"标准差的置信区间: ({std_ci[0]:.4f}, {std_ci[1]:.4f})")
点估计直接计算均值和标准差,区间估计则要用到t分布和卡方分布相关知识,计算出均值和标准差的置信区间。
六、任务五:数据建模与预测
假设萼片长度服从正态分布,用 Kolmogorov - Smirnov 检验验证,再计算萼片长度落在 [5,6] 区间的概率。
from scipy import statssepal_length = iris['sepal_length']# 正态性检验(Kolmogorov-Smirnov检验)
ks_stat, ks_p = stats.kstest(sepal_length, 'norm',args=(np.mean(sepal_length), np.std(sepal_length, ddof=1)))
print("Kolmogorov-Smirnov检验结果:")
print(f"统计量: {ks_stat:.4f}")
print(f"P值: {ks_p:.4f}")
print(f"在显著性水平0.05下,数据", "服从正态分布" if ks_p >= 0.05 else "不服从正态分布")# 计算概率
mean = np.mean(sepal_length)
std = np.std(sepal_length, ddof=1)
prob = stats.norm.cdf(6, mean, std) - stats.norm.cdf(5, mean, std)
print(f"\n萼片长度落在[5,6]区间的概率: {prob:.4f}")
stats.kstest执行 Kolmogorov - Smirnov 检验,stats.norm.cdf计算正态分布的累积分布函数,从而得到萼片长度落在指定区间的概率。
七、任务六:结果展示
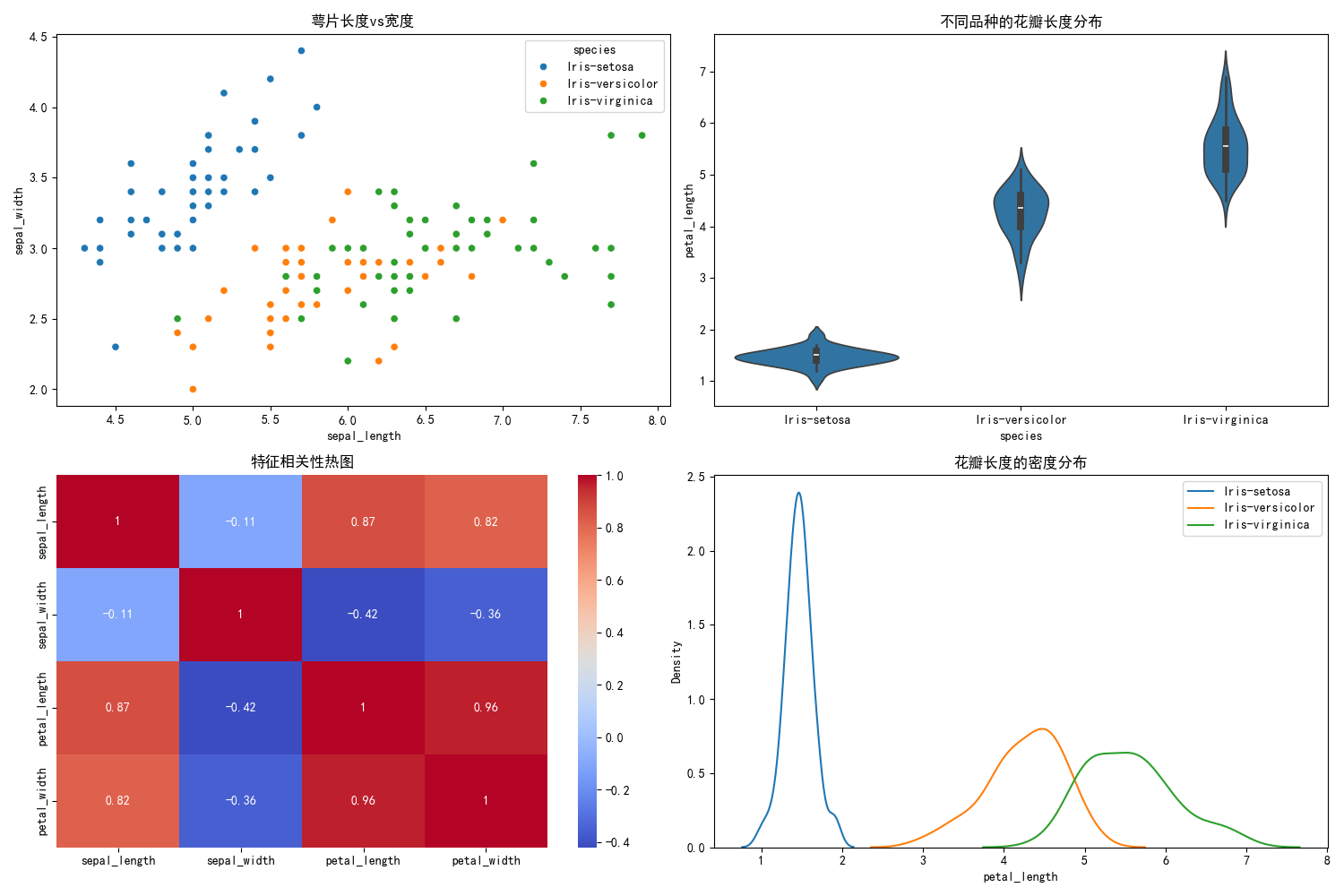
用散点图矩阵、小提琴图、相关性热图和密度图,把分析结果可视化。
import matplotlib.pyplot as plt
import seaborn as snsplt.figure(figsize=(15, 10))# 散点图矩阵
plt.subplot(2, 2, 1)
sns.scatterplot(data=iris, x='sepal_length', y='sepal_width', hue='species')
plt.title('萼片长度vs宽度')# 小提琴图
plt.subplot(2, 2, 2)
sns.violinplot(data=iris, x='species', y='petal_length')
plt.title('不同品种的花瓣长度分布')# 相关性热图
numeric_iris = iris.select_dtypes(include=['float64', 'int64'])
correlation = numeric_iris.corr()
plt.subplot(2, 2, 3)
sns.heatmap(correlation, annot=True, cmap='coolwarm')
plt.title('特征相关性热图')# 密度图
plt.subplot(2, 2, 4)
for species in iris['species'].unique():sns.kdeplot(data=iris[iris['species'] == species]['petal_length'],label=species)
plt.title('花瓣长度的密度分布')
plt.legend()plt.tight_layout()
plt.savefig('task6_visualization.png')
plt.close()
seaborn的scatterplot绘制散点图矩阵,violinplot绘制小提琴图,heatmap绘制相关性热图,kdeplot绘制密度图,每个图都能从不同角度展示数据特征。