R语言traj包进行潜轨迹分析
潜类别轨迹建模(Latent Class Trajectory Modeling, LCTM)是一种统计方法,用于识别具有相似时间发展模式的未观测群体。这种方法结合了潜变量模型和轨迹分析的优点,可以用来探索不同个体随时间变化的规律或趋势,并将这些个体分类到不同的潜类别中去。
主要特点
识别潜在群体:LCTM能够帮助研究者在数据中发现存在但不可直接观测到的不同群体。
考虑个体差异:此方法允许每个个体在其所属类别的框架内有不同的轨迹,从而考虑到个体之间的变异性。
灵活的模型设定:可以根据研究目的选择不同的模型设定,比如线性、二次方或者更复杂的函数形式来描述轨迹。
应用领域
LCTM被广泛应用于社会科学研究、心理学、公共卫生、医学研究等领域。例如,在医学研究中,它可以用来分析患者在接受某种治疗后的恢复过程,识别出不同的恢复模式以及与之相关的因素。
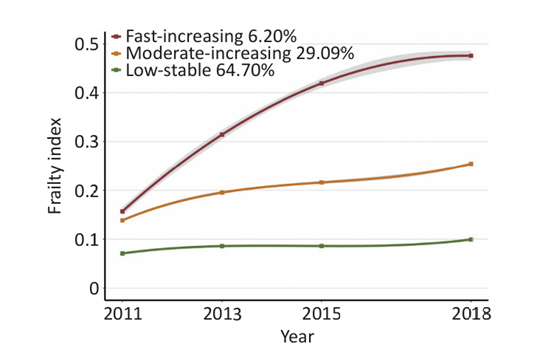
目前潜轨迹模型(GBTM)属于比较好发文的,能发的文章分数也比较高,有些机构还开专门开了潜轨迹模型(GBTM)培训班,既往咱们已经介绍额如何使用lcmm包构建潜轨迹模型,今天咱们来介绍traj包进行潜轨迹分析。
咱们先导入R包和数据,数据使用R包自带的trajdata数据
library(traj)
data(trajdata)
精简一下数据
dat <- trajdata[, -c(1,2)]
Traj包参考了文献(a three-step procedure in the spirit of Leffondre et al. (2004))的方法,使用3步法进行潜轨迹分析
(1)计算多个“变化度量”,捕捉轨迹的各种特征;
(2) 使用基于主成分分析的降维算法来选择度量子集
(3)使用k-means或k-means算法来识别轨迹簇。
方法也很简单,按照作者设计的程序来跑就行
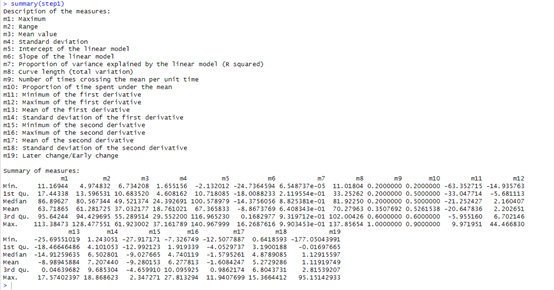
第一步计算多个度量
step1 <- Step1Measures(Data = dat, measures = 1:19)
summary(step1)
第二步使用基于主成分分析的降维算法来选择度量子集
step2 <- Step2Selection(trajMeasures = step1)
summary(step2)
第三步使用k-means或k-means算法进行分类,需要加入辅助包cluster
library(cluster)
set.seed(1337)
step3 <- Step3Clusters(trajSelection = step2, nclusters = 3)
plot(step3, ask = TRUE)
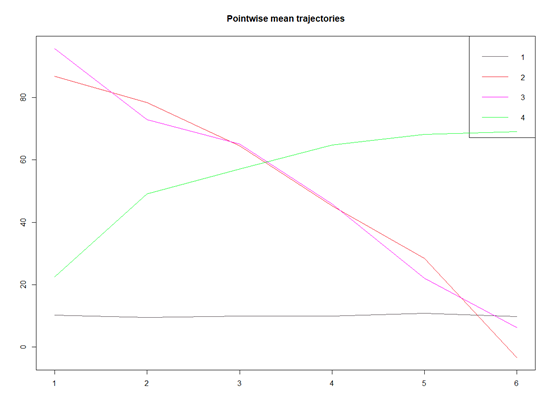
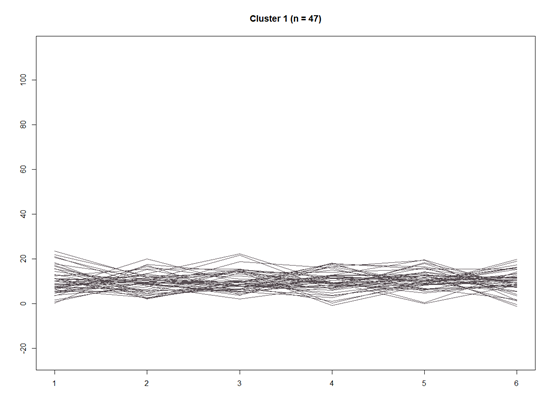
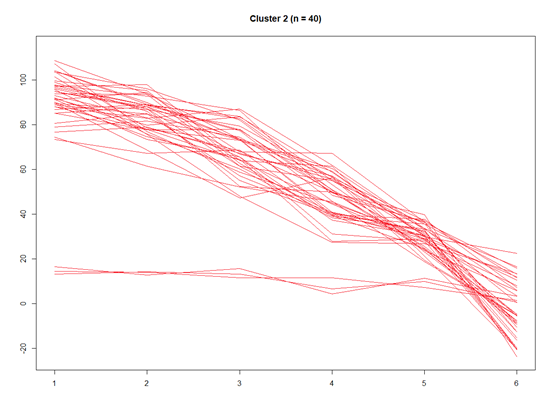
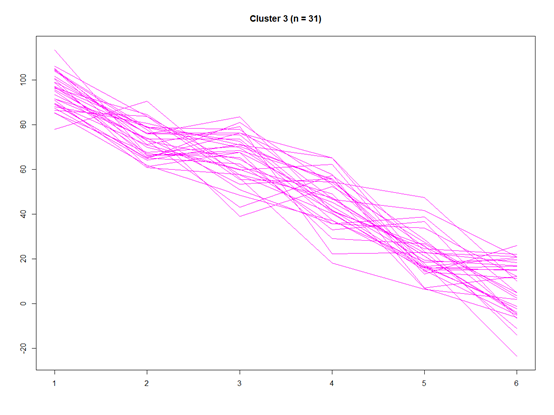
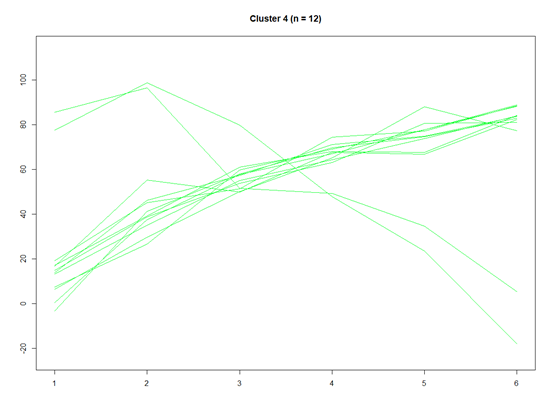
这样就分层了4类了,还是比较简单的
我们也可以把1-4单个聚类出来
color.pal <- palette.colors(palette = "Polychrome 36", alpha = 1)[-2]
par(mfrow = c(1, 1))
for(k in 1:4){w <- which(step3$partition$Cluster == k)dat.w <- dat[w, ]plot(y = 0, x = 0, ylim = c(floor(min(dat)), ceiling(max(dat))), xlim = c(1,6), xlab="", ylab="", type="n", main = paste("Cluster ", k, " (n = ", step3$partition.summary[k], ")", sep = ""))for(i in 1:length(w)){lines(y = dat.w[i, ], x = 1:6, col = color.pal[k])}
}