【Linux】深入理解程序地址空间

🌟🌟作者主页:ephemerals__
🌟🌟所属专栏:Linux
目录
前言
一、什么是程序地址空间
二、深入理解程序地址空间
1. 引例
2. 理解地址转化
3. 再谈程序地址空间
4. 补充知识
总结
前言
在现代操作系统中,进程的地址空间管理是实现多任务和内存保护的核心机制。对于Linux操作系统而言,理解程序的地址空间布局不仅对于开发高效、稳定的应用至关重要,也是调试和优化程序不可或缺的基础。本文将简要介绍Linux程序在内存中的地址空间结构,帮助读者更好地理解进程如何利用和管理内存资源。
一、什么是程序地址空间
程序地址空间是指操作系统为一个程序分配的内存范围。在现代操作系统中,每个程序在运行时都有自己的程序地址空间。
程序地址空间通常分为以下几个部分:
1. 内核空间:供操作系统使用,与其他部分形成隔离,程序无法访问。
2. 栈区:存储函数的局部变量和函数调用的上下文等。
3. 内存映射段(共享区):为支持文件的高效访问或多进程的数据共享而划分的一块区域,通常包含文件映射、动态库和匿名映射等。
4. 堆区:动态内存分配所用区域,需要手动管理。
5. BSS段:存储未初始化的全局变量和静态变量。
6. 数据段(静态区):存储已经初始化的全局变量和静态变量。
7. 代码段(常量区):存放程序的可执行代码和只读常量,该区域通常只读,不可修改。
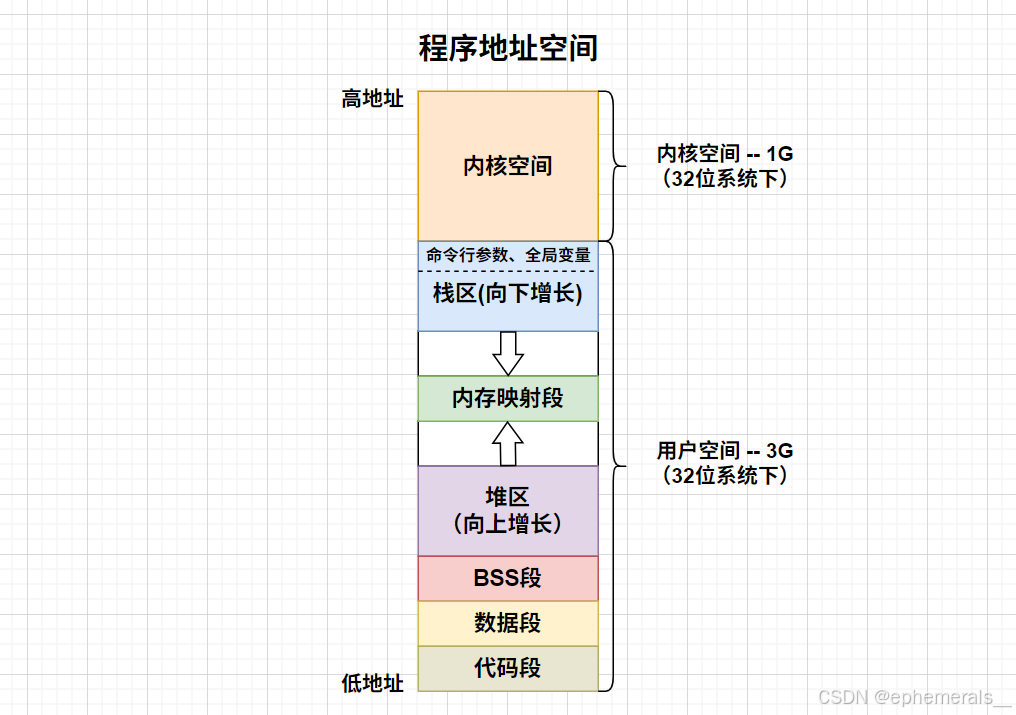
在32位系统下,程序地址空间一共有2^32个地址,大小为4GB;
在64位系统下,程序地址空间一共有2^64个地址,大小约为17179PB(是理论极限,实际比它小得多,并且整个内存大小远远达不到如此) 。
二、深入理解程序地址空间
1. 引例
首先我们写一段程序:
#include <stdio.h>
#include <unistd.h>int main()
{int m = 0;pid_t id = fork();if(id == 0) // 子进程{m = 10;printf("子进程修改了m\n");sleep(1);printf("子进程:m = %d;&m = %p\n", m, &m);}else // 父进程{sleep(1);printf("父进程:m = %d;&m = %p\n", m, &m);}return 0;
}这里我们使用fork创建了一个子进程,并让子进程修改m的值,此时会发生写时拷贝,两个进程的“m”应该不再表示同一份资源。接下来打印它们的值和地址。程序运行结果如下:
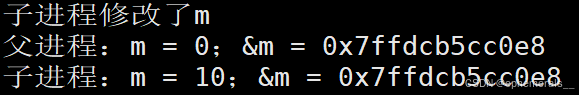
可以看到,出现了怪事:m的值不同,为什么它们的地址还相同呢?
只能说明:这个地址是假的,不是真实的内存地址(物理地址)。
实际上,我们使用C/C++编程时使用到的地址,全部都是虚拟地址,并不表示真实的内存地址。为了保护物理内存,真实的内存地址是由操作系统统一管理的,用户无法直接访问。
2. 理解地址转化
因此,刚才的例子当中,两个m的虚拟地址是相同的,但在物理层面,它们的物理地址是不同的。这就意味着两个进程的虚拟地址空间是不同的,并且操作系统必须将用户使用的虚拟地址转化为物理地址,然后进行访问等操作。负责虚拟地址和物理地址转化的东西,叫做页表。
我们可以暂时将页表理解为一个映射表,表的左边是虚拟地址,右边是物理地址,通过左边的虚拟地址就可以进行页表转化,找到真实的物理地址进行访问。
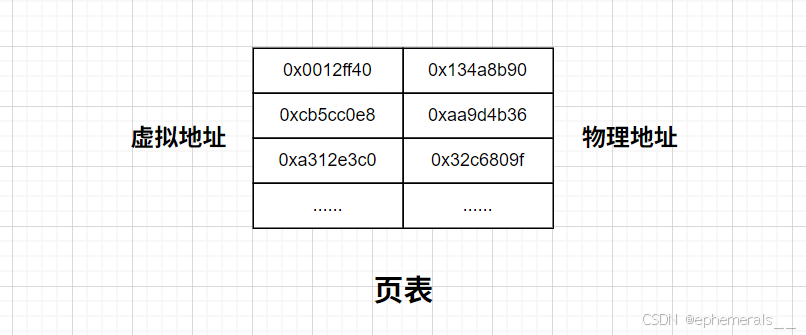
总结:
1. 一个进程具有一个程序地址空间
2. 一个进程具有一个页表,用于虚拟地址和物理地址的转化
3. 程序执行时,操作系统根据数据或代码的虚拟地址,通过页表找出对应的真实内存地址,进行访问。
3. 再谈程序地址空间
因此,再说“程序地址空间”就不太准确了,我们称其为“进程地址空间”或“虚拟地址空间”更为恰当。
实际上,不仅进程地址空间的地址是虚拟的,其“大小”也是虚拟的。进程地址空间就像是操作系统给进程画的一张大饼,让进程以为自己独占4GB的内存(32位系统下)。但由于其他进程可需要访问物理内存,物理内存总共就4GB,怎么可能被一个进程独占呢?所以虽说进程地址空间大小是4GB,但实际根本不可能有这么多。
因此,进程在创建时,操作系统按照程序代码和数据的大小,创建地址空间,并设定各个区域的范围和内存大小,然后加载程序,申请相应的物理内存,再创建页表,支持将物理地址转化为虚拟地址,供上层用户使用。
这样,我们就可以解释刚才的程序:
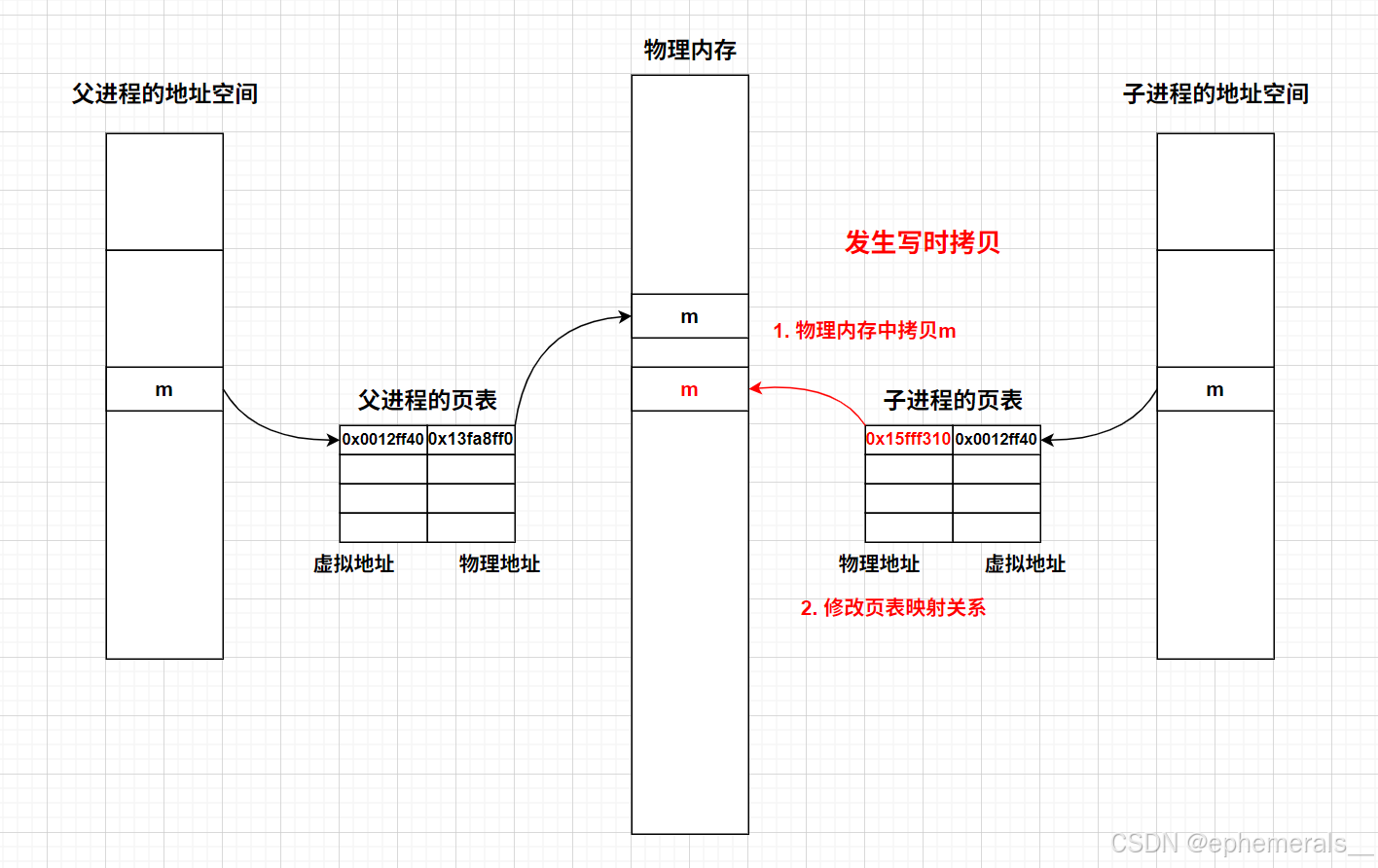
1. 子进程在创建之后,拷贝了父进程的进程地址空间以及页表,因此,父子进程的地址映射关系是相同的,具体表现就是虚拟地址相同,且维护的是同一块物理内存。
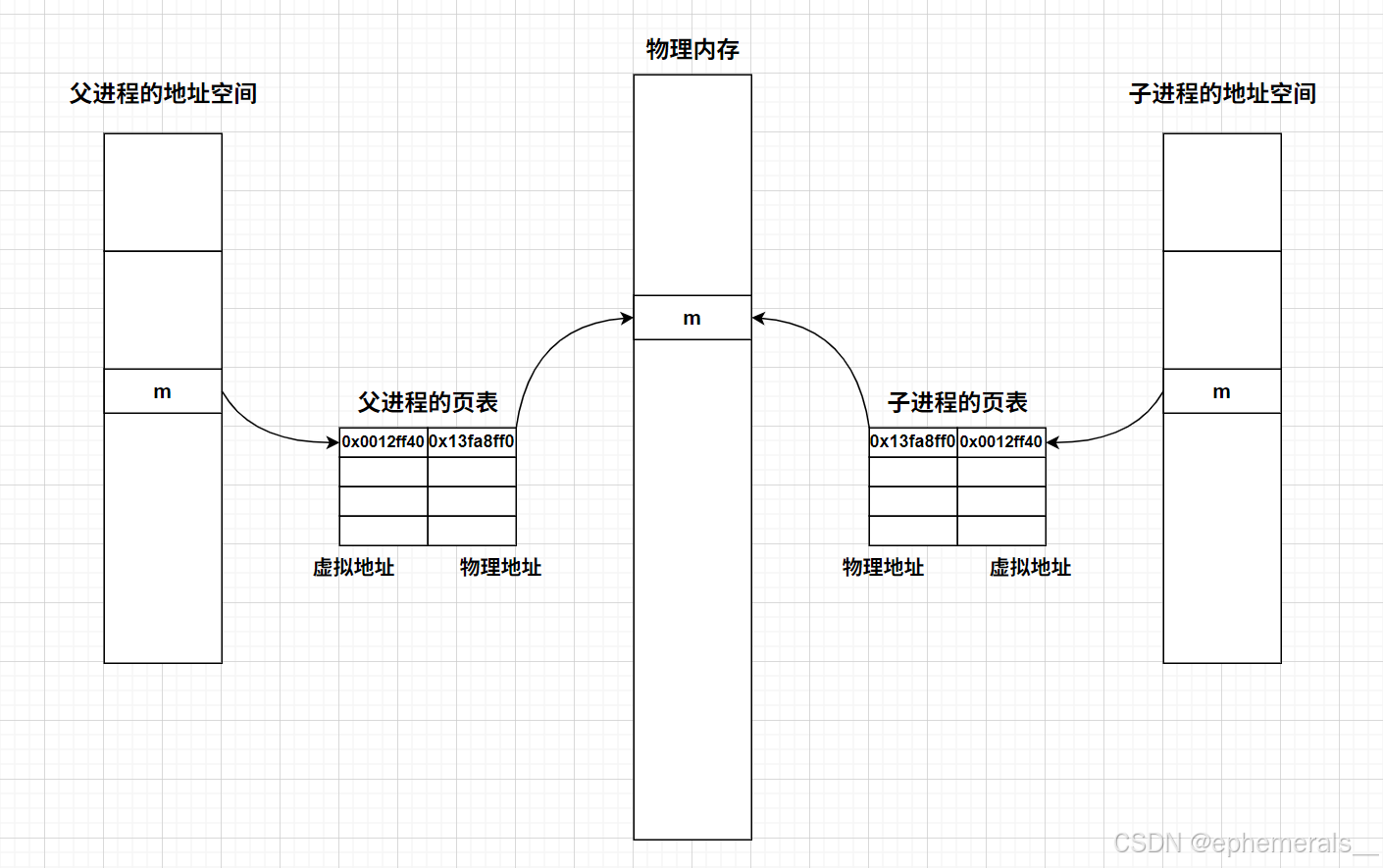
2. 此时子进程修改变量m的值,操作系统检测到变量要被修改,于时发生写时拷贝,在物理内存中对该变量进行拷贝,并修改子进程的页表映射关系,使原来的虚拟地址映射到别的物理地址处。这样,父子进程就各自维护一个m,它们表现出的虚拟地址相同,但物理地址不同,页表映射关系也不同,因此出现了地址相同,值不相同的情况。
那么为什么不支持直接访问物理内存,而这样大费周折地搞出一个什么进程地址空间和页表呢?有三点原因:
1. 如果每个进程都可以直接访问物理内存,那么就意味着这个程序可以直接修改另一个程序甚至操作系统的数据和代码,如果有恶意病毒程序,就会造成不可预料的后果。
2. 假设进程A需要申请地址为1~100的内存区域,并且代码中访问了地址为“50”的内存单元。下一次启动进程A时,如果已经有进程申请了1~100的内存区域,那么进程A如何申请内存呢?尚且申请101~200,但是代码中访问“50”已经写死了,没法修改,这导致每次程序执行的结果都是不确定的。
3. 如果直接使用物理内存,那么一个进程就是一整块内存区域,如果需要执行挂起或其他操作,就只能将整个区域都进行拷贝,效率降低。
进程地址空间的出现,就完美地解决了这些问题:
1. 地址转换过程中,可以对操作的合法性进行判定(页表中,针对虚拟地址空间中的各个区域,有明确的权限划分,假如在程序中修改常量数据,就会出现页表权限拦截,发生崩溃),从而保护物理内存,确保程序的正常执行。
2. 有了虚拟地址,物理内存申请就不必连续,经过页表可以转化成连续的虚拟地址,方便上层使用。
3. 除此之外,程序地址空间还使得操作系统对进程的管理和内存的管理之间进行一定的解耦合(用户申请内存根本无需关心物理内存的具体情况)。
4. 补充知识
1. 虚拟地址空间的本质是一个数据结构,在Linux下叫做mm_struct,其地址存放在task_struct对象当中,mm_struct维护着一个个vm_area_struct,这些vm_area_struct存储着进程地址空间每一个区域的起始和结束地址。要调整区域划分,只需对其中变量进行加减操作。
2. 一个进程具有一个进程地址空间,意味着一个进程维护一个mm_struct,操作系统要将这些mm_struct组织起来统一管理。当进程数量较少时,mm_struct是用单链表结构组织起来的;较多时,利用红黑树结构进行组织。
总结
本篇文章,我们学习了进程地址空间的基本概念,并深入理解了页表转化以及进程地址空间的本质。学习进程地址空间,为我们后续学习理解进程控制相关操作至关重要。如果你觉得博主讲的还不错,就请留下一个小小的赞在走哦,感谢大家的支持❤❤❤