[特殊字符] 人工智能大模型之开源大语言模型汇总(国内外开源项目模型汇总) [特殊字符]
Large Language Model (LLM) 即大规模语言模型,是一种基于深度学习的自然语言处理模型,它能够学习到自然语言的语法和语义,从而可以生成人类可读的文本。
所谓 "语言模型",就是只用来处理语言文字(或者符号体系)的 AI 模型,发现其中的规律,可以根据提示 (prompt),自动生成符合这些规律的内容。
LLM 通常基于神经网络模型,使用大规模的语料库进行训练,比如使用互联网上的海量文本数据。这些模型通常拥有数十亿到数万亿个参数,能够处理各种自然语言处理任务,如自然语言生成、文本分类、文本摘要、机器翻译、语音识别等。
本文对国内外公司、科研机构等组织开源的 LLM 进行了全面的整理。
🌍 1. 开源中文 LLM
🔹 ChatGLM-6B —— 双语对话语言模型
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,并针对中文进行了优化。该模型基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
✅ 特点:
-
支持中英双语问答
-
优化中文理解与生成
-
低显存需求,适合本地部署
🔗 GitHub
🔹 ChatGLM2-6B —— 中英双语对话模型第二代
基于 ChatGLM 初代模型的开发经验,ChatGLM2-6B 全面升级了基座模型,支持更长的上下文,更高效的推理,更开放的协议。
✅ 升级点:
-
更长的上下文支持
-
更快的推理速度
-
更开放的协议
🔗 GitHub
🔹 VisualGLM-6B —— 多模态对话语言模型
VisualGLM-6B 是一个支持 图像、中文和英文 的多模态对话语言模型,语言模型基于 ChatGLM-6B,视觉部分通过训练 BLIP2-Qformer 构建起视觉与语言的桥梁。
✅ 特点:
-
支持图像+文本多模态输入
-
78亿参数,增强视觉理解能力
🔗 GitHub
🔹 MOSS —— 支持中英双语的对话大语言模型
MOSS 是一个支持中英双语和多种插件的开源对话语言模型,moss-moon 系列模型具有 160 亿参数,在 FP16 精度下可在单张 A100/A800 或两张 3090 显卡运行。
✅ 特点:
-
支持插件增强
-
在千亿级中英文数据上预训练
-
适用于多轮对话
🔗 GitHub
🔹 DB-GPT —— 数据库大语言模型
DB-GPT 是一个开源的以 数据库为基础 的 GPT 实验项目,使用本地化的 GPT 大模型与数据和环境进行交互,无数据泄露风险,100% 私密。
✅ 特点:
-
专为数据库场景优化
-
支持本地部署,数据安全可控
🔗 GitHub
🔹 CPM-Bee —— 中英文双语大语言模型
CPM-Bee 是一个 完全开源、允许商用 的百亿参数中英文基座模型,采用 Transformer 自回归架构,使用 万亿级高质量语料 进行预训练。
✅ 特点:
-
开源可商用
-
中英双语性能优异
-
超大规模训练数据
🔗 GitHub
🔹 LaWGPT —— 基于中文法律知识的大语言模型
LaWGPT 是一系列基于 中文法律知识 的开源大语言模型,在通用中文基座模型的基础上扩充法律领域专有词表,增强法律语义理解能力。
✅ 特点:
-
法律领域优化
-
支持司法考试数据集
🔗 GitHub
🔹 伶荔 (Linly) —— 大规模中文语言模型
Linly 是目前最大的中文 LLaMA 模型之一(33B),支持 中文增量训练,并提供量化推理框架。
✅ 特点:
-
支持 CPU/GPU 推理
-
提供 7B、13B、33B 版本
🔗 GitHub
🔹 Chinese-Vicuna —— 基于 LLaMA 的中文大语言模型
Chinese-Vicuna 是一个中文低资源的 LLaMA + LoRA 方案,支持 CPU 推理。
✅ 特点:
-
低成本微调方案
-
支持 C++ CPU 推理
🔗 GitHub
🔹 ChatYuan —— 对话语言大模型
ChatYuan 是一个支持中英双语的功能型对话语言大模型,最低仅需 400M 显存(INT4) 即可运行。
✅ 特点:
-
轻量化,适合移动端
-
优化指令理解
🔗 GitHub
🔹 华佗 GPT —— 开源中文医疗大模型
HuatuoGPT(华佗 GPT)是开源中文医疗大模型,基于 医生回复 + ChatGPT 数据 训练,提供丰富的医疗问诊能力。

✅ 特点:
-
医疗领域优化
-
支持诊断建议
🔗 GitHub
🔹 本草 (BenTsao) —— 基于中文医学知识的 LLaMA 微调模型
本草(原名华驼)是基于 中文医学知识 的 LLaMA 微调模型,适用于医疗问答。
✅ 特点:
-
医学指令微调
-
支持知识图谱
🔗 GitHub
🔹 鹏程·盘古α —— 中文预训练语言模型
「鹏程·盘古α」是业界首个 2000 亿参数 的中文预训练生成语言模型,支持知识问答、阅读理解等任务。
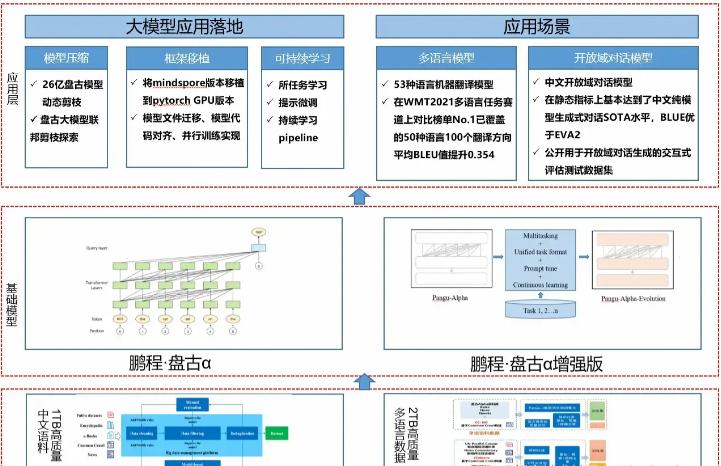
✅ 特点:
-
超大规模训练
-
支持少样本学习
🔗 GitHub
🔹 悟道 —— 双语多模态大语言模型
“悟道” 是 1.75 万亿参数 的双语多模态预训练模型,涵盖 文本、图像、蛋白质 等多个领域。
✅ 子模型:
-
CogView(文生图)
-
BriVL(图文检索)
-
GLM(英文预训练)
-
CPM(中文生成)
🔗 GitHub
🔹 BBT-2 —— 120 亿参数大语言模型
BBT-2 是包含 120 亿参数 的通用大语言模型,衍生出 代码、金融、文生图 等专业模型。
✅ 衍生模型:
-
BBT-2-12B-TC-001(代码模型)
-
BBT-2-12B-TF-001(金融模型)
-
BBT-2-12B-Fig(文生图)
🔗 GitHub
🔹 BELLE —— 开源中文对话大模型
BELLE 目标是促进 中文对话大模型 开源社区的发展,基于 BLOOM 优化中文能力。
✅ 特点:
-
使用 ChatGPT 生成数据微调
-
支持个性化训练
🔗 GitHub
🔹 TigerBot —— 多模态大语言模型
TigerBot 是一个多语言多任务的大规模语言模型,TigerBot-7B 达到 OpenAI 同规模模型的 96% 性能。
✅ 特点:
-
支持多语言
-
高性能推理
🔗 GitHub
🔹 YuLan-Chat —— 大语言对话模型
中国人民大学发布的 中英文双语对话模型,优化指令微调技术。
✅ 特点:
-
学术研究导向
-
支持多轮交互
🔗 GitHub
🔹 百聆 (BayLing) —— 中英双语大语言模型
中国科学院计算技术研究所开发的 中英双语大语言模型,性能达 ChatGPT 90%。
✅ 特点:
-
优越的中英生成能力
-
支持多轮交互
🔗 GitHub
🌎 2. 开源国际 LLM
🔹 通义千问-7B (Qwen-7B) —— 阿里云开源大模型
Qwen-7B 基于 Transformer 架构,支持 8K 上下文,覆盖多种 NLP 任务。
✅ 特点:
-
大规模预训练数据(2.2 万亿 token)
-
支持插件调用
🔗 GitHub
🔹 Code Llama —— 基于 Llama 2 的 AI 代码生成模型
Meta 发布的 代码生成大模型,支持 Python、C++、Java 等编程语言。
✅ 版本:
-
Code Llama(基础代码模型)
-
Code Llama-Python(Python 优化)
-
Code Llama-Instruct(指令理解)
🔗 GitHub
🔹 MiLM-6B —— 小米 AI 大模型
小米开发的 64 亿参数 中文大模型,在 C-Eval 和 CMMLU 评测中表现优异。
✅ 特点:
-
中文优化
-
高性能推理
🔗 GitHub
🔹 LLaMA —— Meta 开源大语言模型
Meta 的 LLaMA 系列(7B/13B/33B/65B),性能超越 GPT-3。
✅ 特点:
-
高效推理
-
适合本地部署
🔗 GitHub
🔹 Falcon —— 阿联酋开源语言模型
Falcon 40B 是目前 最强大的开源语言模型之一,性能优于 LLaMA。
✅ 特点:
-
400 亿参数
-
高效推理
🔗 GitHub
🔹 Vicuna —— 基于 LLaMA 的微调模型
Vicuna-13B 达到 ChatGPT 90% 的质量,训练成本仅 300 美元。
✅ 特点:
-
低成本微调
-
高性能对话
🔗 GitHub
🔹 BLOOM —— 1760 亿参数多语言模型
BLOOM 支持 46 种自然语言 + 13 种编程语言,完全开源。
✅ 特点:
-
多语言支持
-
免费商用
🔗 GitHub
🔹 GPT-J —— 60 亿参数开源模型
GPT-J 基于 GPT-3 架构,性能接近 OpenAI 的 67 亿参数版本。
✅ 特点:
-
完全开源
-
支持代码生成
🔗 GitHub
🔹 WizardLM —— 基于 LLaMA 的微调模型
WizardLM 使用 Evol-Instruct 方法自动生成训练数据,优化指令理解。
✅ 特点:
-
70K 指令微调
-
高性能对话
🔗 GitHub
🛠️ 3. LLM 相关工具
🔹 OpenLLM —— 大语言模型操作平台
支持 Fine-tune、Serve、部署、监控 任何 LLM,兼容多种开源模型。
✅ 特点:
-
支持 RESTful API
-
简化部署
🔗 GitHub
🔹 LangChain —— 构建 LLM 应用的工具
提供 Prompt 管理、LLM 接口、文档加载、链式调用 等功能。
✅ 特点:
-
支持多种 LLM
-
灵活构建 AI 应用
🔗 GitHub
🔹 JARVIS —— 连接 LLM 和 AI 模型的协作系统
由 LLM 作为控制器,调用 HuggingFace 模型执行任务。
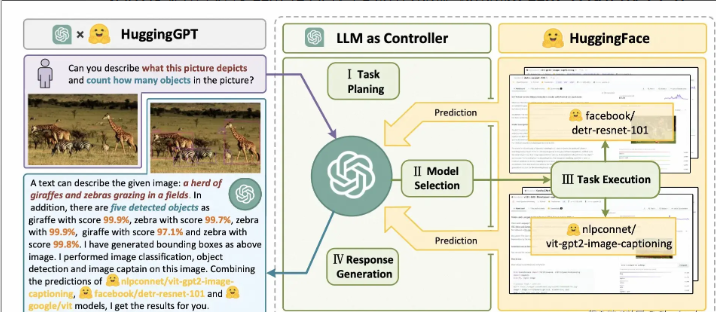

✅ 工作流程:
-
任务规划
-
模型选择
-
任务执行
-
生成响应
🔗 GitHub
🔹 Dify —— LLMOps 平台
可视化编排 Prompt、数据集、API,支持 GPT-3/4、LLaMA 等模型。
✅ 特点:
-
开箱即用
-
支持私有化部署
🔗 GitHub
🔹 Flowise —— 可视化构建 LLM 应用
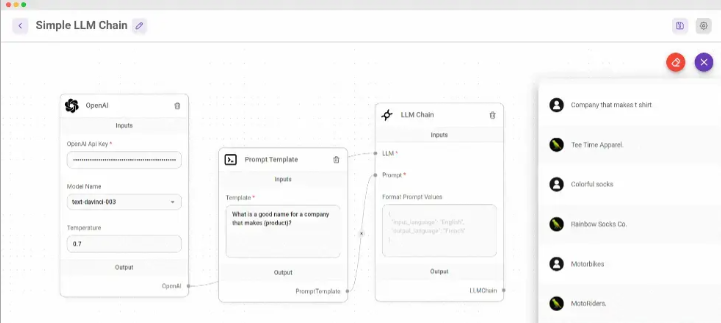
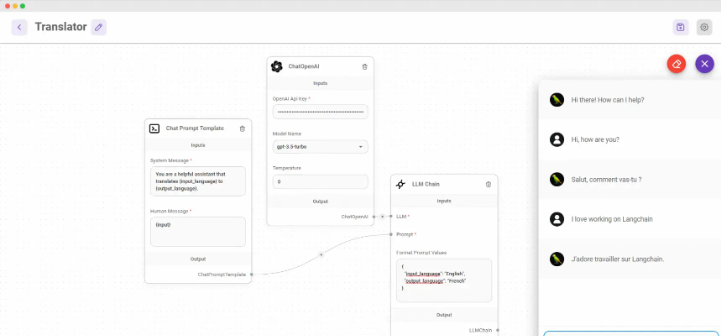
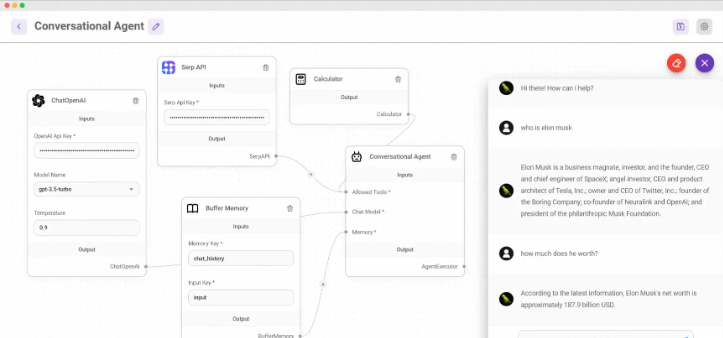
基于 LangChain 的低代码工具,支持对话链、记忆代理等。
✅ 特点:
-
拖拽式 UI
-
快速原型开发
🔗 GitHub
🎉 总结
本文整理了 国内外 50+ 开源大语言模型及相关工具,涵盖:
-
中文 LLM(ChatGLM、MOSS、DB-GPT 等)
-
国际 LLM(LLaMA、Falcon、BLOOM 等)
-
LLM 工具(LangChain、Dify、Flowise 等)
无论是 学术研究 还是 商业应用,这些开源项目都提供了强大的支持! 🚀