n8n工作流自动化平台的实操:解决中文乱码
解决问题:
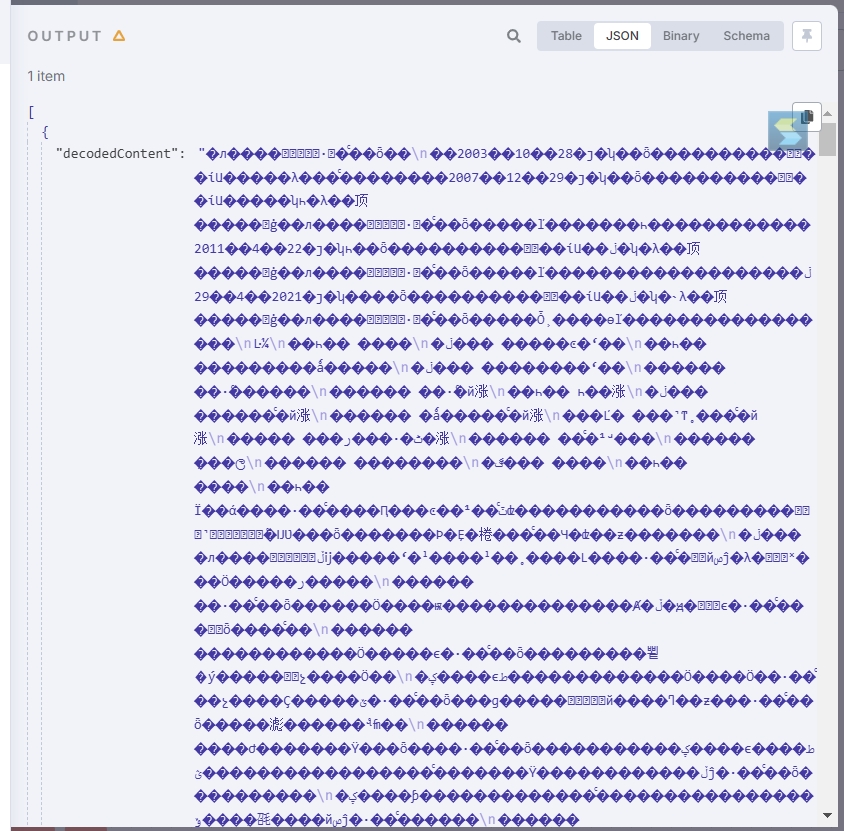
通过ftp读取中文内容的文件,会存在乱码,如下图:
解决方案
1.详见《安装 iconv-lite》
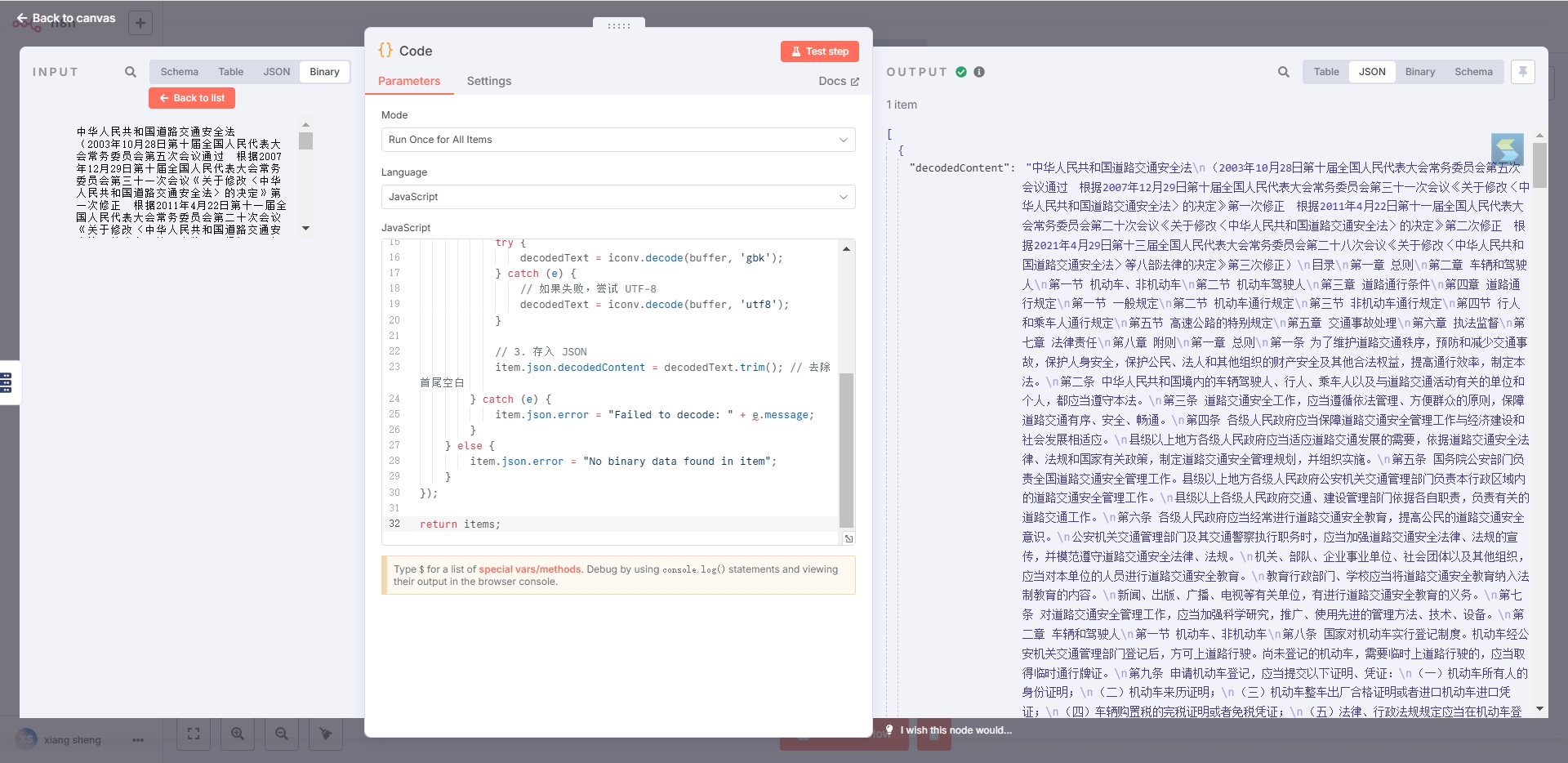
2.在code节点,写如下代码:
const iconv = require('iconv-lite');const items = $input.all();
items.forEach(item => {if (item.binary && item.binary.data) {// 假设 item.binary.data.data 是一个 Base64 字符串const base64Data = item.binary.data.data;try {// 1. 先将其转换为 Bufferconst buffer = Buffer.from(base64Data, 'base64');// 2. 尝试使用 GBK 解码(适合中文)let decodedText;try {decodedText = iconv.decode(buffer, 'gbk');} catch (e) {// 如果失败,尝试 UTF-8decodedText = iconv.decode(buffer, 'utf8');}// 3. 存入 JSONitem.json.decodedContent = decodedText.trim(); // 去除首尾空白} catch (e) {item.json.error = "Failed to decode: " + e.message;}} else {item.json.error = "No binary data found in item";}
});return items;再执行,效果如下图: