【Java IO流】字节输入流FileInputStream、字节输出流FileOutputStream
目录
0.前言
1.FileInputStream
1.1 概述
1.2 构造方法
1.3 成员方法
1.4 FileInputStream读取文件案例演示
2.FileOutputStream
2.1 概述
2.2 构造方法
2.3 成员方法
2.4 写入文本文件案例演示
3.FileInputStream + FileOutputStream拷贝文件
0.前言
本文讲解的是两个比较重要的节点流,也是两个比较重要的字节流。即字节输入流 FileInputStream、字节输出流 FileOutputStream
Java IO 流体系图如下:
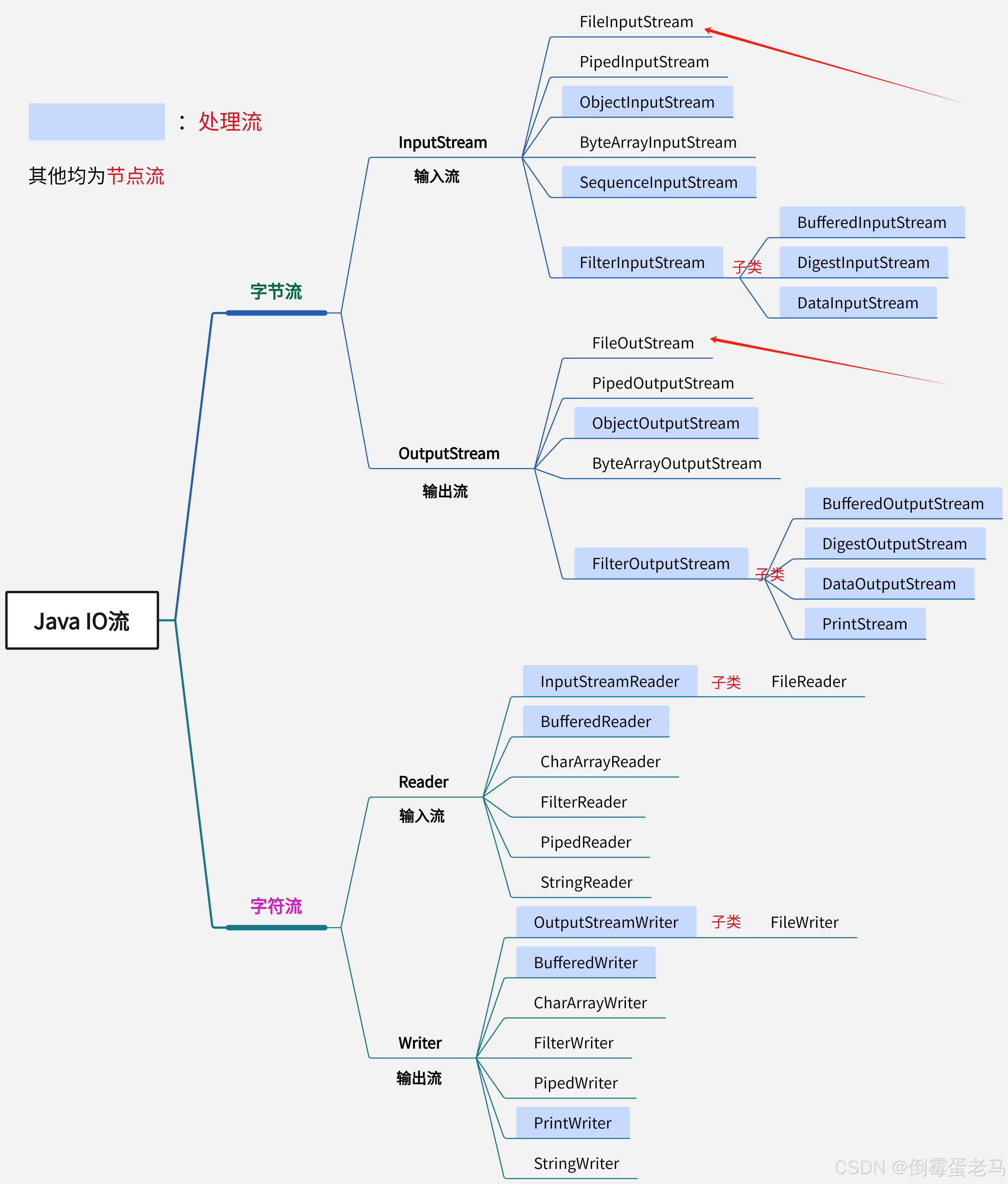
1.FileInputStream
1.1 概述
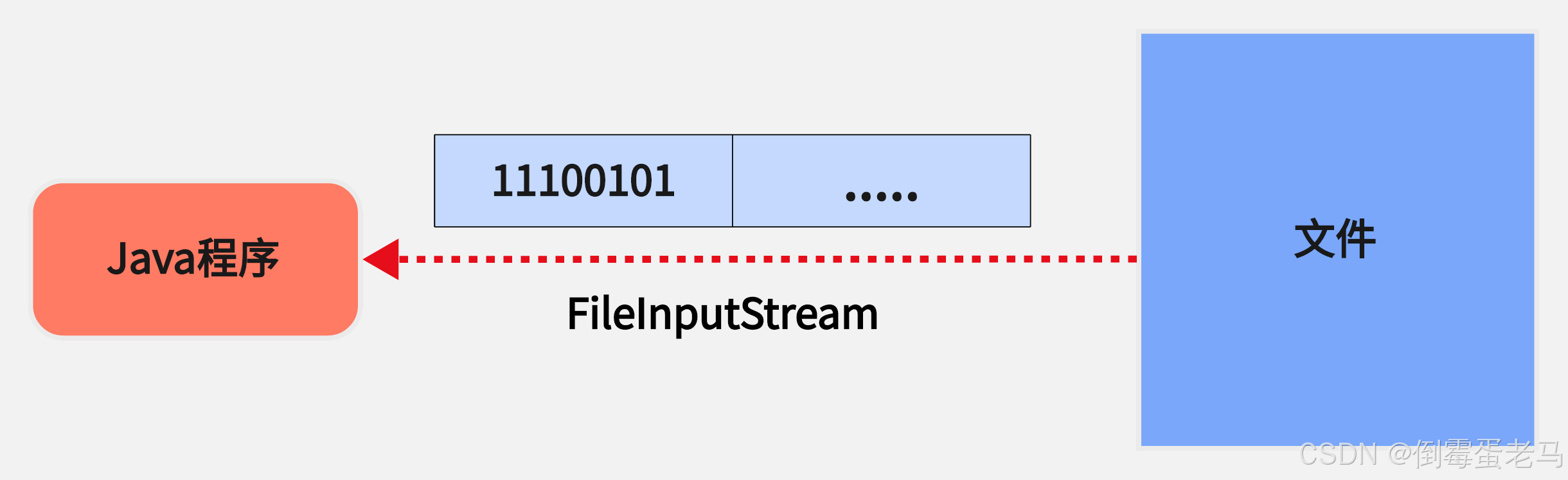
作用:从磁盘文件中读取字节数据 Java 程序(内存)中
1.2 构造方法

1.3 成员方法
FileInputStream 读取数据的方法如下:
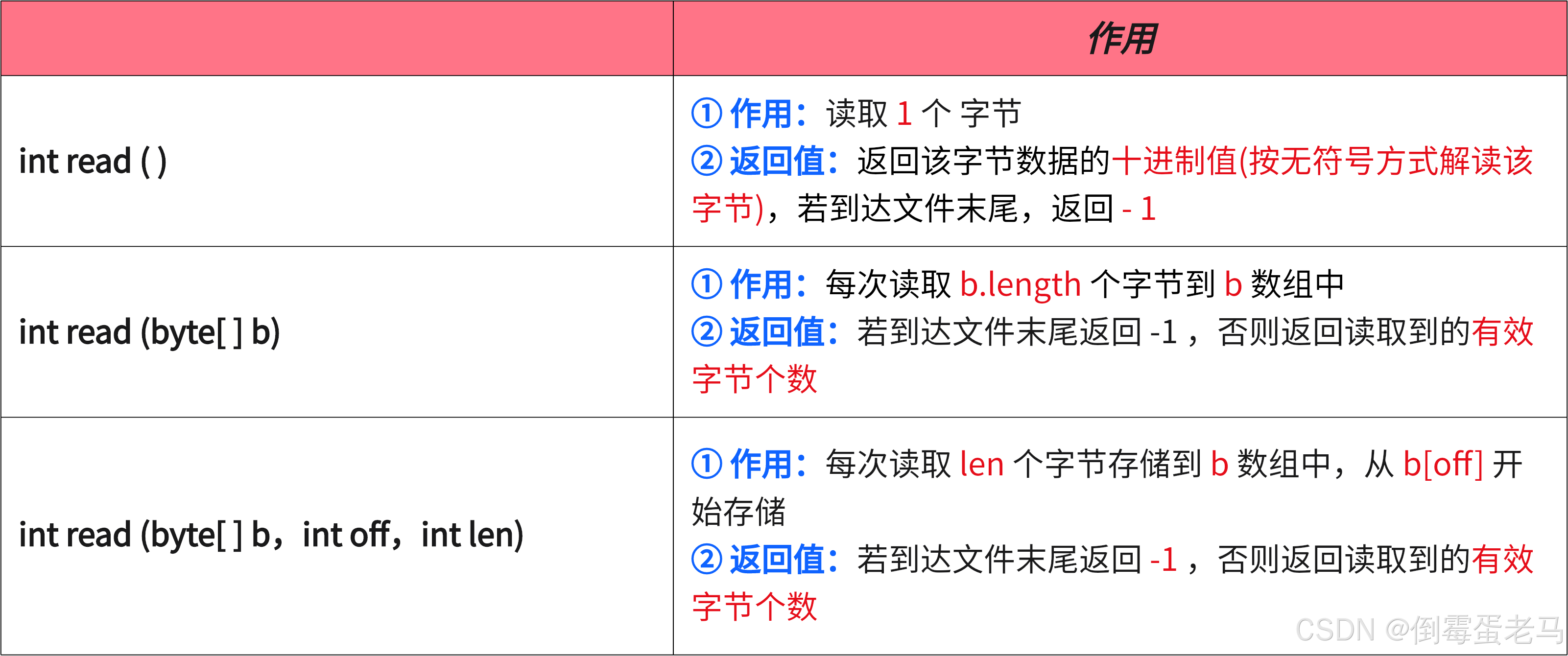
注:调用 read() 每次只能从文件中读取 1 个字节数据,速度较慢,而且返回值是 int 类型,操作不方便。所以最好使用 read(byte[] b) 来读取字节数据,每次读取 b.length 个字节数据
1.4 FileInputStream读取文件案例演示
虽然字节流可以操作任何类型文件,但由于不同的字符在文本文件中占用的字节数不同,因此使用字节流来读取文本文件非常容易发生乱码的现象
所以字节输入流 FileInputStream 通常用于读取图片、视频等二进制文件
但这里为了看到读取效果,还是以读取文本文件举一些案例吧,我还会举一些发生乱码和不发生乱码的清空
FileInputStream 字节输入流读取文件的步骤
① 创建字节输入流对象 FileInputStream,关联数据源文件 (建议第一步就抛出父类异常IOException)
② 定义变量,记录读取到的字节数据
③ 循环调用 read 方法读取字节数据,只要还未到文件末尾就一直读,并将读取到的字节数据保存在变量中
④ 释放流资源,避免内存泄漏
前言:所有案例文本文件的编码方式均为 UTF-8
案例1:文本内容只有英文字符 (不发生乱码)
ASCII 字符集的 128 个字符经过 UTF-8 编码之后都用 1 字节存储即可,所以使用 FileInputStream 字节输入流读取只有英文字符的文本不会出现乱码
演示类中使用到的文件路径是 D:\javaProjects\untitled\fileDemo\5.txt ,5.txt 使用的编码方式是 UTF-8,文本内容是 "abc"。具体如下:
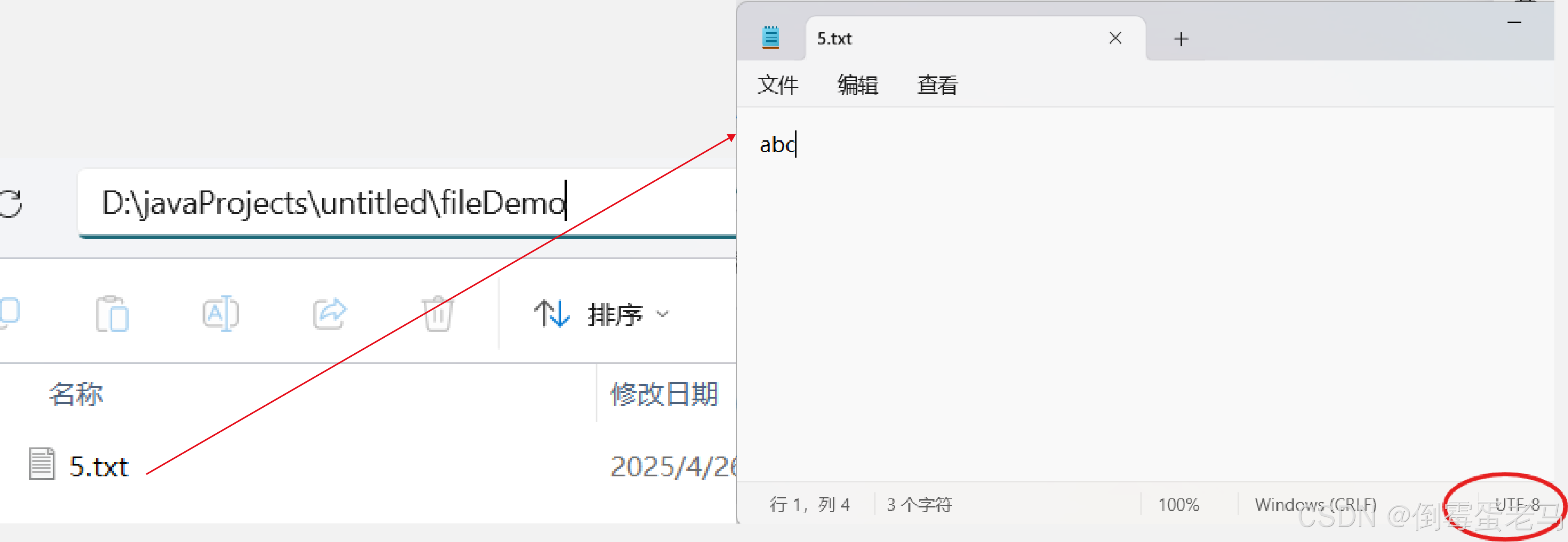
演示类完成的任务是:调用 read(byte[ ] b) ,读取 5.txt 的所有字节,并将文本内容正确显示在控制台上
代码如下:
import java.io.*;
public class demo {public static void main(String[] args) throws IOException {//1.创建FileInputStream字节输入流对象,关联目的地文件 5.txtFileInputStream inputStream = new FileInputStream("D:\\javaProjects\\untitled\\fileDemo\\5.txt");//2.定义字节数组b,记录读取到的字节数据byte[] b = new byte[3];//每次读取3个字节(文本内容只有英文字符时,字节数组的长度可以任意,长度多少都不会发生乱码)int len;//用来记录每次读取的有效字节数//3.循环调用 read(byte[] b) 方法读取数据,只要还未到文件末尾就一直读,并将读取到的字节保存在b数组中while ((len = inputStream.read(b)) != -1) {//关键处:对读取到的字节数据按 "UTF-8" 进行解码String s = new String(b, 0, len, "UTF-8");System.out.print(s);}//4.释放流资源,避免内存泄漏inputStream.close();}
}运行结果:
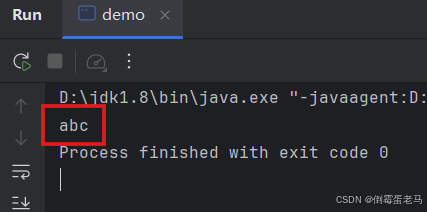
🆗,为什么文本内容只有英文字符就不会发生乱码呢?下面是解码过程,如下:
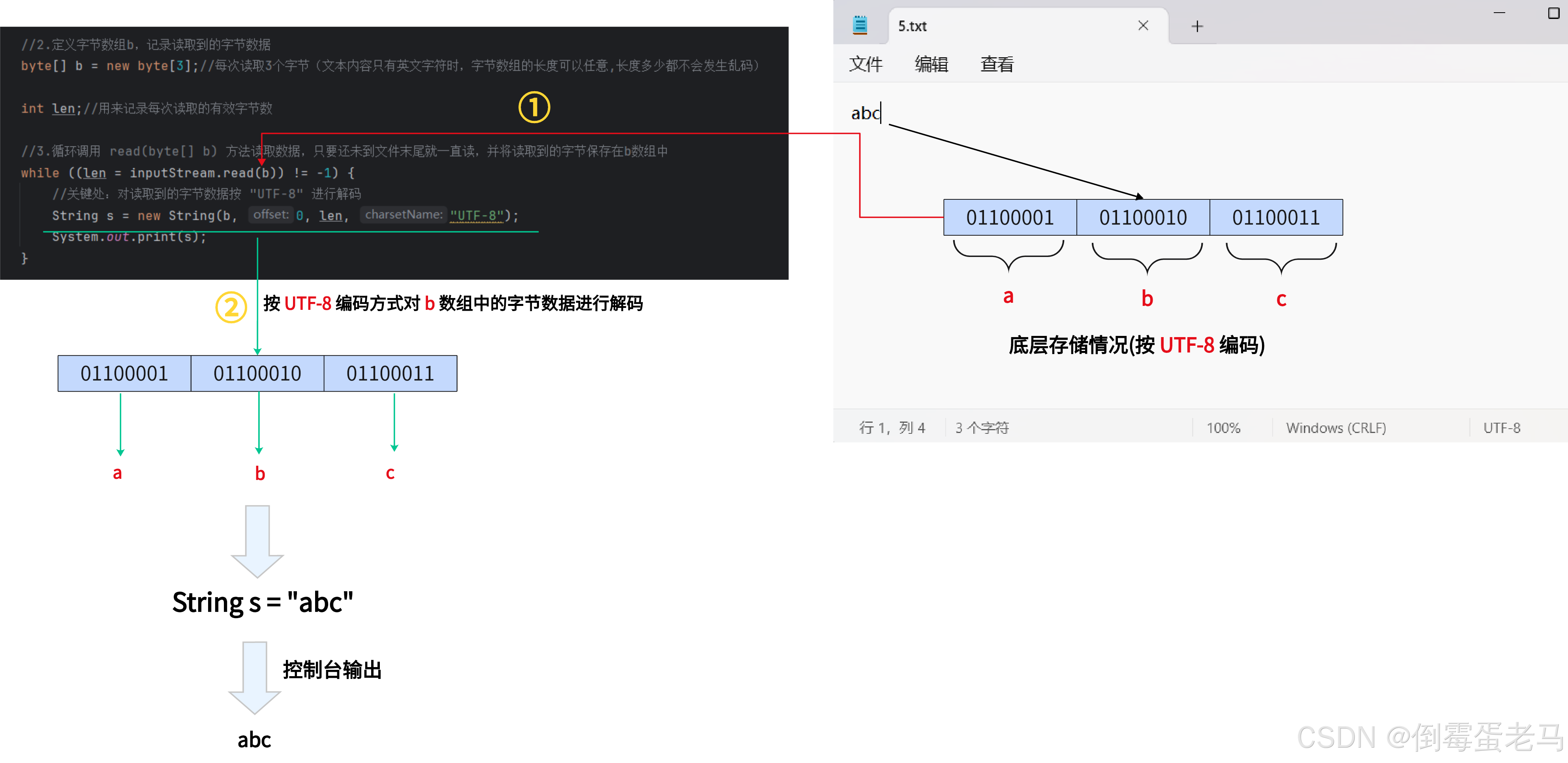
由于每个英文字符 UTF-8 编码之后固定占用 1 个字节,所以不会发生乱码
案例2:文本内容包含 英文字符 + 中文字符 (发生乱码)
演示类中使用到的文件路径是 D:\javaProjects\untitled\fileDemo\4.txt ,4.txt 使用的编码方式是 UTF-8,文本内容是 "a小"。具体如下:
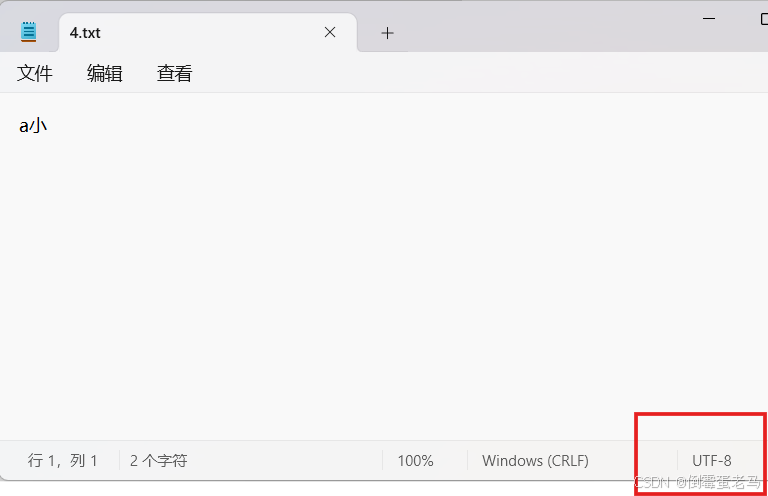
这里为了方便解释为什么发生乱码,我们只读取 4.txt 文件的 3 字节数据,代码如下:
import java.io.*;
public class demo {public static void main(String[] args) throws IOException {//1.创建FileInputStream字节输入流对象,关联目的地文件 4.txtFileInputStream inputStream = new FileInputStream("D:\\javaProjects\\untitled\\fileDemo\\4.txt");//2.定义字节数组b,记录读取到的字节数据byte[] b = new byte[3];int len;//用来记录每次读取的有效字节数//3.调用read(byte[] b) 方法读取文件中的3字节数据len = inputStream.read(b);//4.对读取到的3字节数据按 "UFT-8" 进行解码String s = new String(b, 0, len, "UTF-8");System.out.println(s);//5.释放流资源,避免内存泄漏inputStream.close();}
}运行结果:
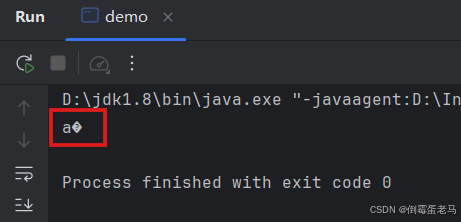
可以看到,确实发生乱码了, 发生乱码的原因可以看如下的解码过程:
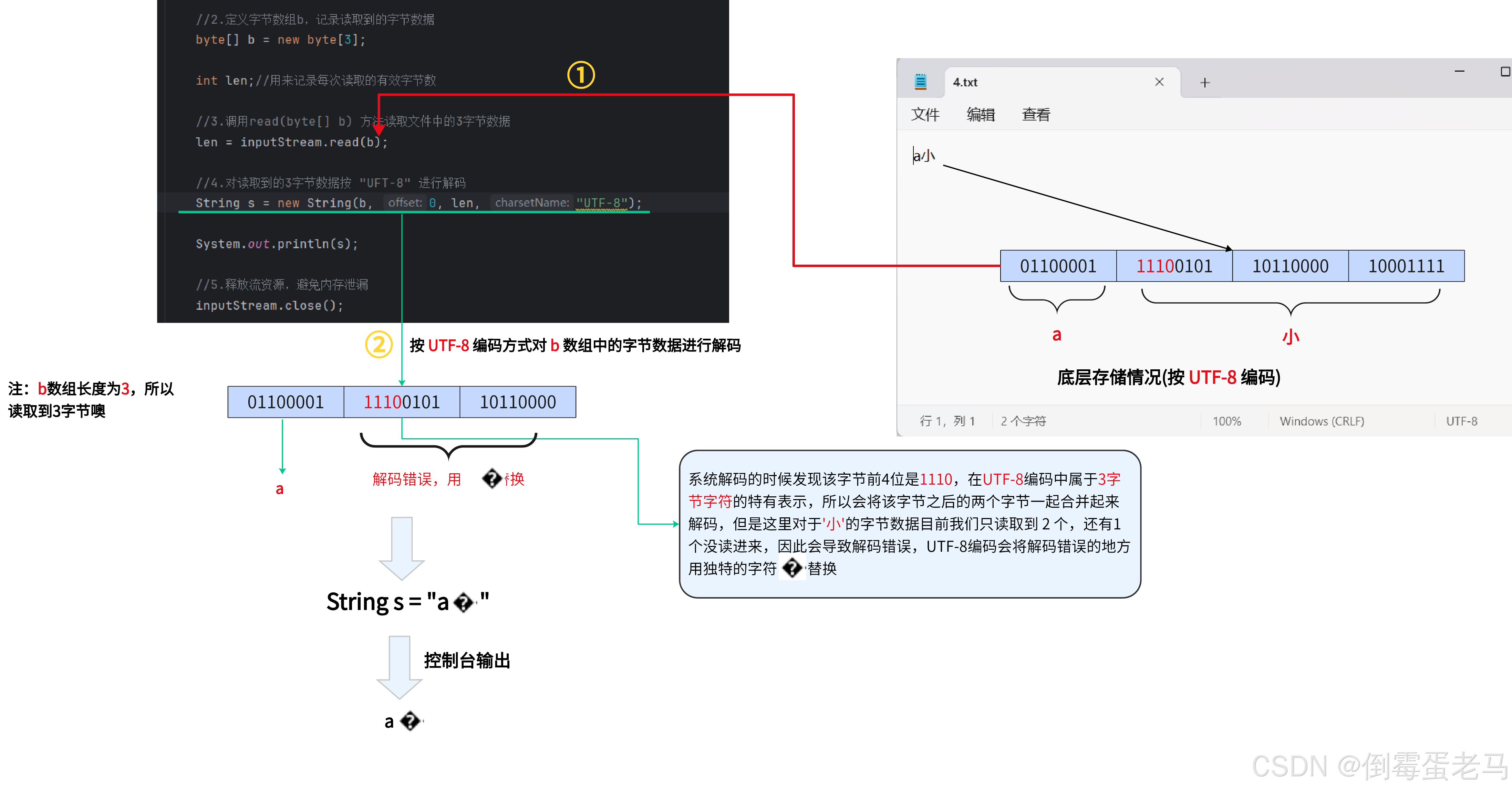
所以,发生乱码的本质原因就是非英文字符在经过某种编码之后,占据的字节数 > 1,比如常用的汉字在 UTF-8 编码之后占用 3 字节,生僻字占用 4 字节,这就会导致在解析读取到的字节数据时,可能某个字符对应的编码字节被 "分割" 开,导致解码错误,从而发生乱码
🆗,解释清楚了,那么请问:在发生乱码的这个案例中,如果我们把字节数据 b 的长度改为 4,仍然去读取 4.txt 文件,是否会发生乱码呢?
答案是不会,代码如下:
import java.io.*;
public class demo {public static void main(String[] args) throws IOException {//1.创建FileInputStream字节输入流对象,关联目的地文件 4.txtFileInputStream inputStream = new FileInputStream("D:\\javaProjects\\untitled\\fileDemo\\4.txt");//2.定义字节数组b,记录读取到的字节数据byte[] b = new byte[4];int len;//用来记录每次读取的有效字节数//3.调用read(byte[] b) 方法读取文件中的3字节数据len = inputStream.read(b);//4.对读取到的3字节数据按 "UFT-8" 进行解码String s = new String(b, 0, len, "UTF-8");System.out.println(s);//5.释放流资源,避免内存泄漏inputStream.close();}
}运行结果:
可以看到,确实不发生乱码了,不发生乱码的原因可以看如下的解码过程:
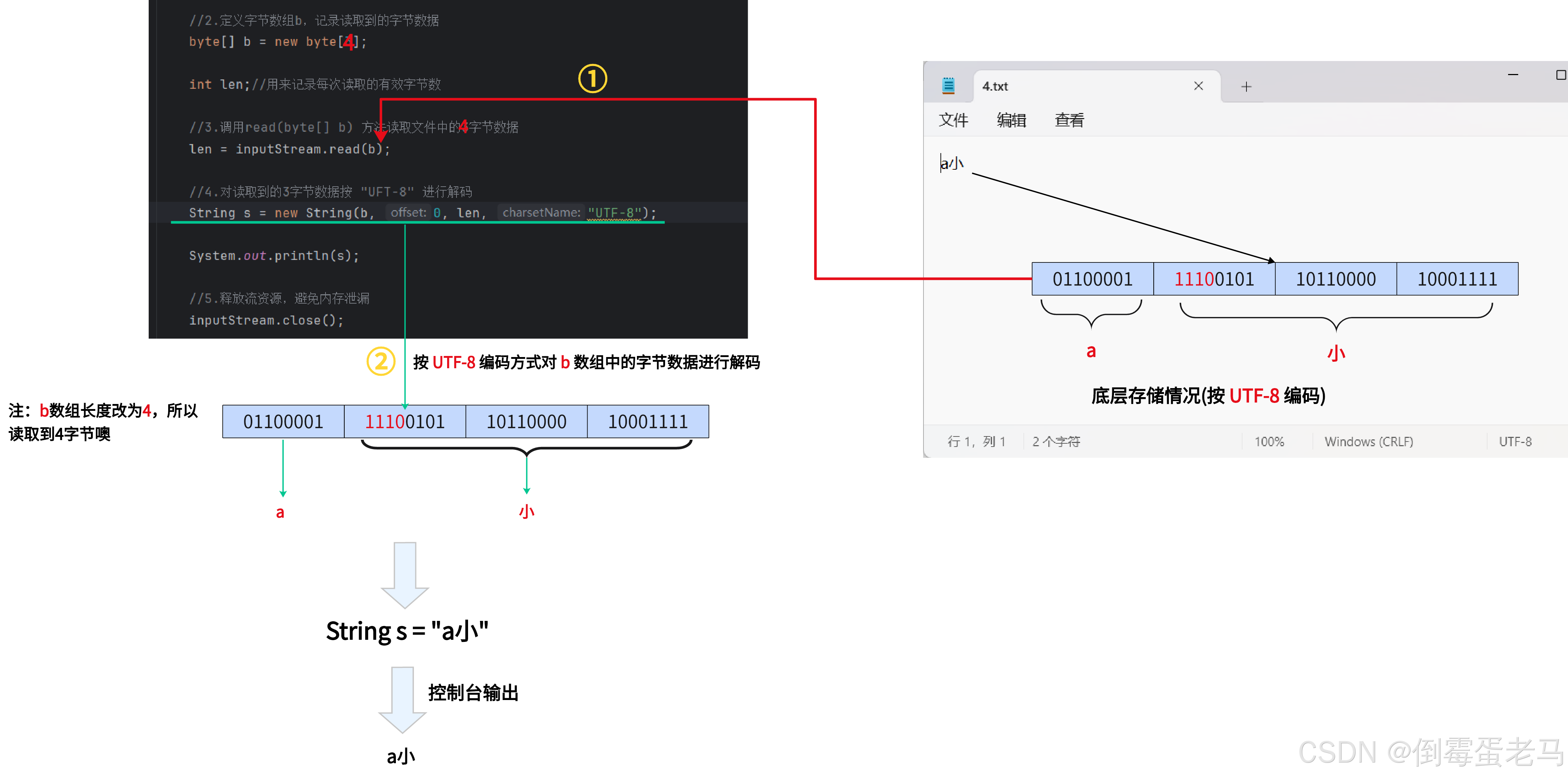
可以看到,由于我们将字节数组 b 的长度改为 4,刚好可以读取完 4.txt 的所有字节数据,而且 '小' 对应的 UTF-8 编码字节没有被 "分割" 开,所以系统在用 UTF-8 解码字节数组 b 时不会发生乱码
总结:所以说在 Java IO 流中几乎不会用字节流来操作纯文本文件,因为容易发生乱码,字节流更多用于操作二进制文件,比如 .img、.mp3、.ppt 等等,操作纯文本文件更多由字符流来完成,各司其职
2.FileOutputStream
2.1 概述
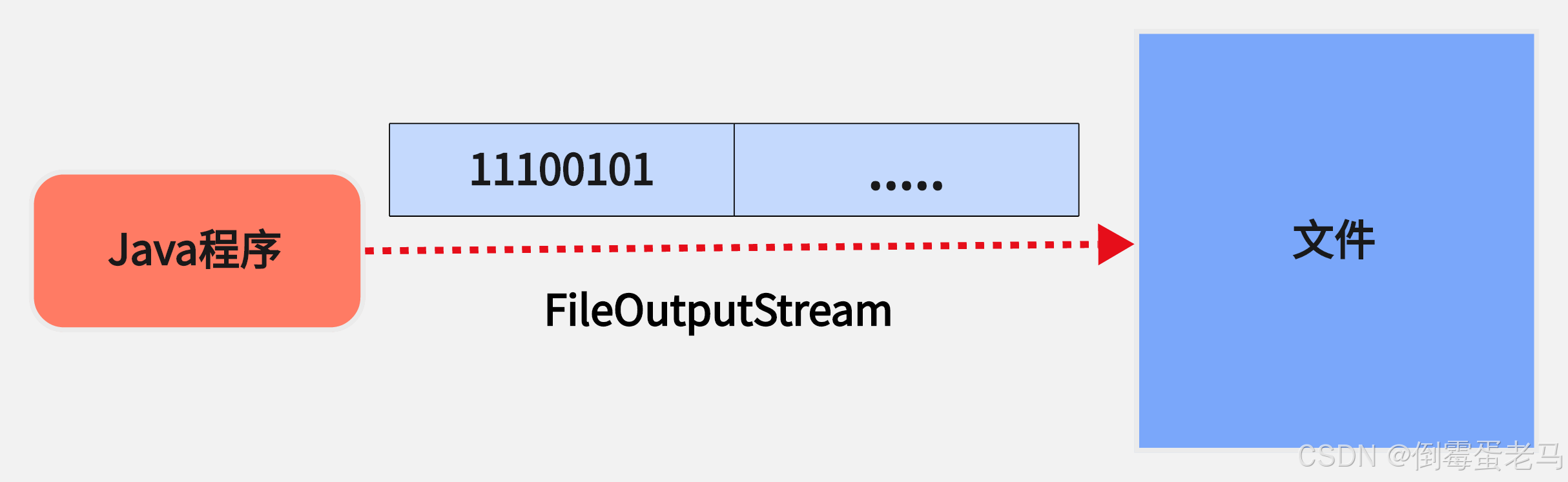
作用:将字节数据 从 Java 程序(内存) 写入到磁盘文件
2.2 构造方法
FileOutputStream 的 4 个常用的构造方法如下:
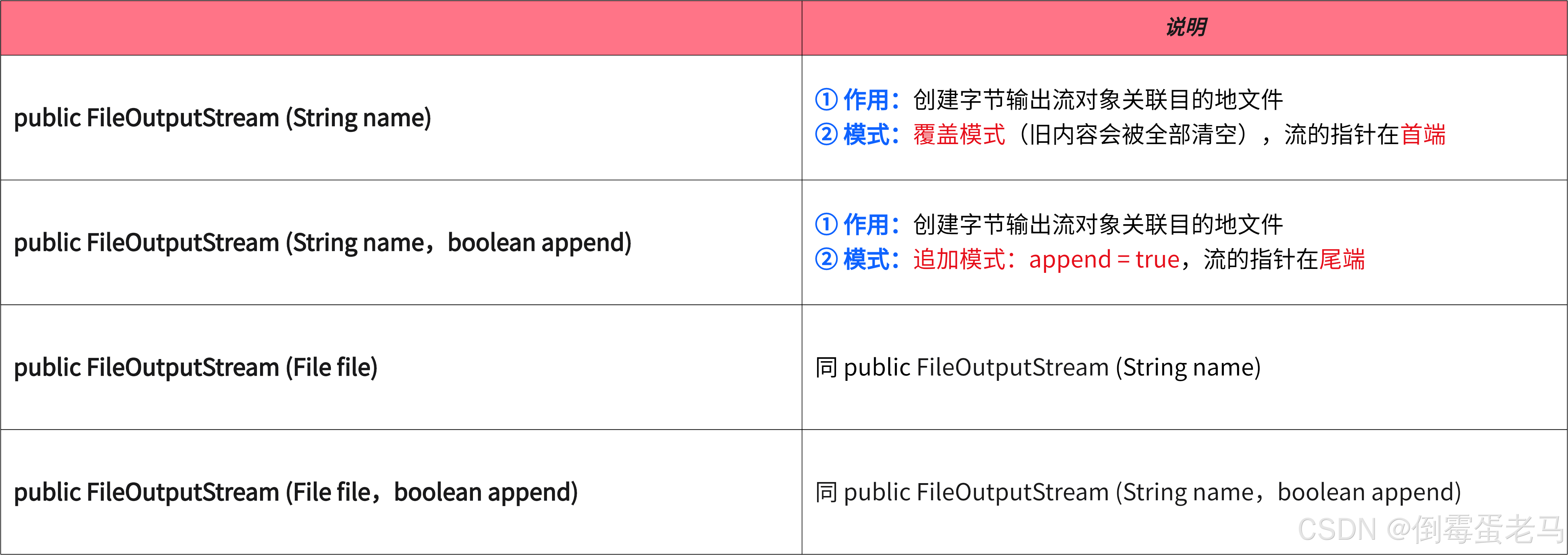
注:如果目的地文件不存在,使用 FileOutputStream 构造器方法后会在磁盘上生成该文件,但要保证父级目录是存在的
2.3 成员方法
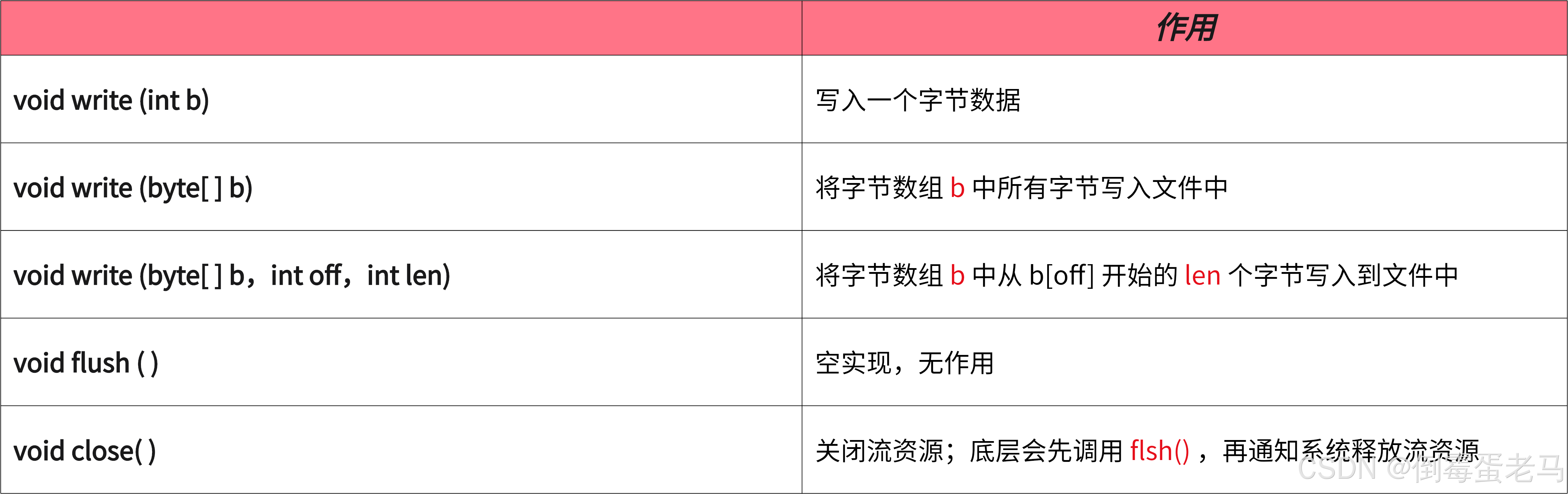
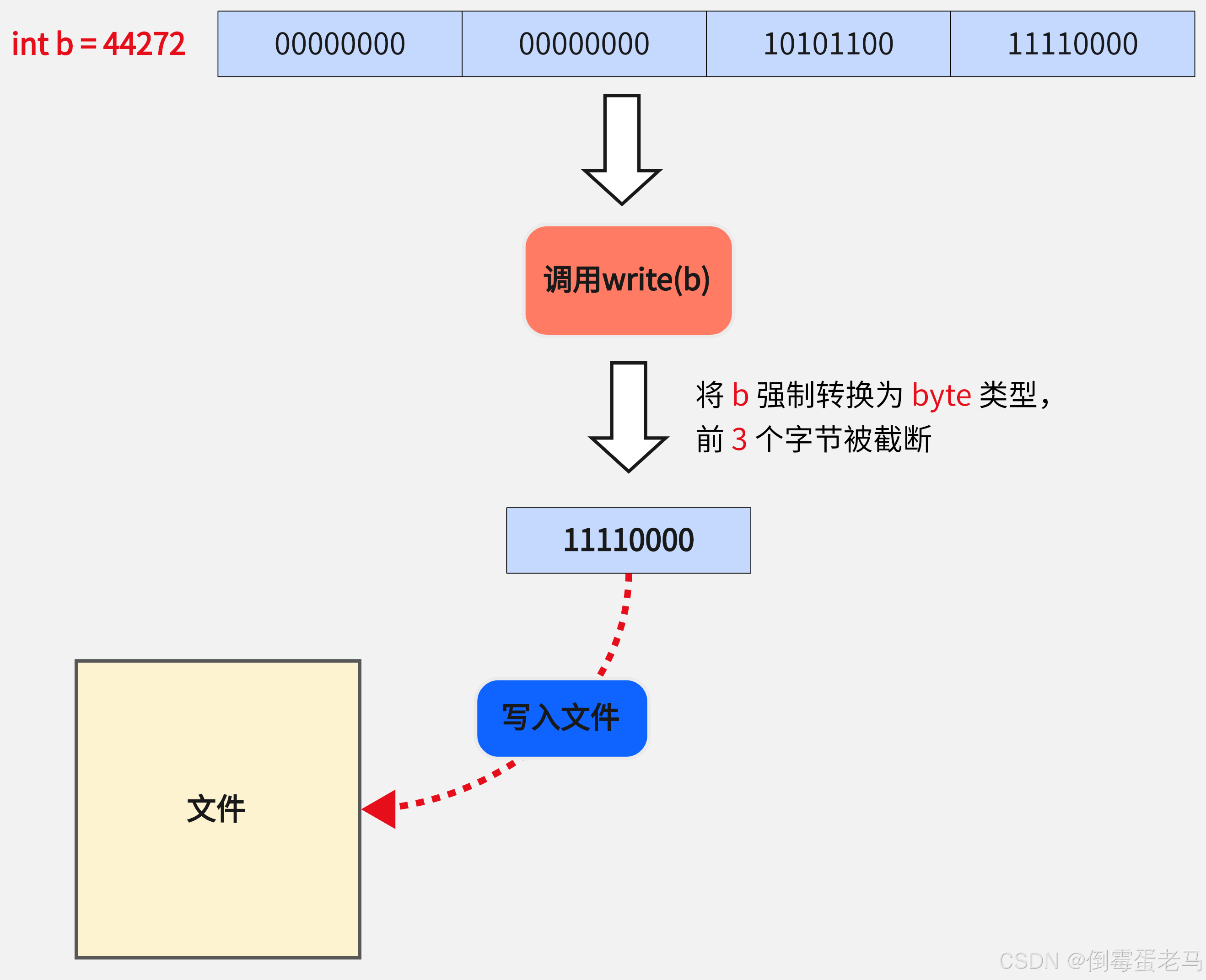
① void write(int b) 虽然接收参数是 int 类型,但底层实际会进行强制类型转换 int ----> byte ,所以调用 write(int b) 是写入一个 8 位的字节数据,如下所示:
② 与字符输出流(比如 FileWriter ) 不同,FileOutputStream 本身不带有缓冲区,所以其 flush() 底层是个空方法,没有作用。所以每次调用 write 方法时,会直接将数据写入文件中,即只要 write() 方法执行成功,数据就会被写入文件。但是最终还是要调用 close() 释放流资源噢,避免内存泄漏
PS:这里可以自己尝试一下,就不举例子说明了
2.4 写入文本文件案例演示
Java 的 String 类提供了 getBytes 编码方法,使得使用字节输出流 FileOutputStream 向文本文件中写入字符比较方便
字节输出流写入文件的步骤
① 创建字节输出流对象 FileOutputStream ,关联目的地文件(建议第一步就抛出父类异常IOException)
② 调用 wirte(byte[ ] b) 方法将字节数据写入到目的地文件中
③ 释放流资源,避免内存泄漏
注:调用 write(int b) 每次写入 1 个字节数据不方便,而且速度太慢,我们这里直接使用 write(byte[ ] b) ;另外 FileOutputStream 使用后,必须要调用 close() 关闭,否则无法写入文件中
案例演示
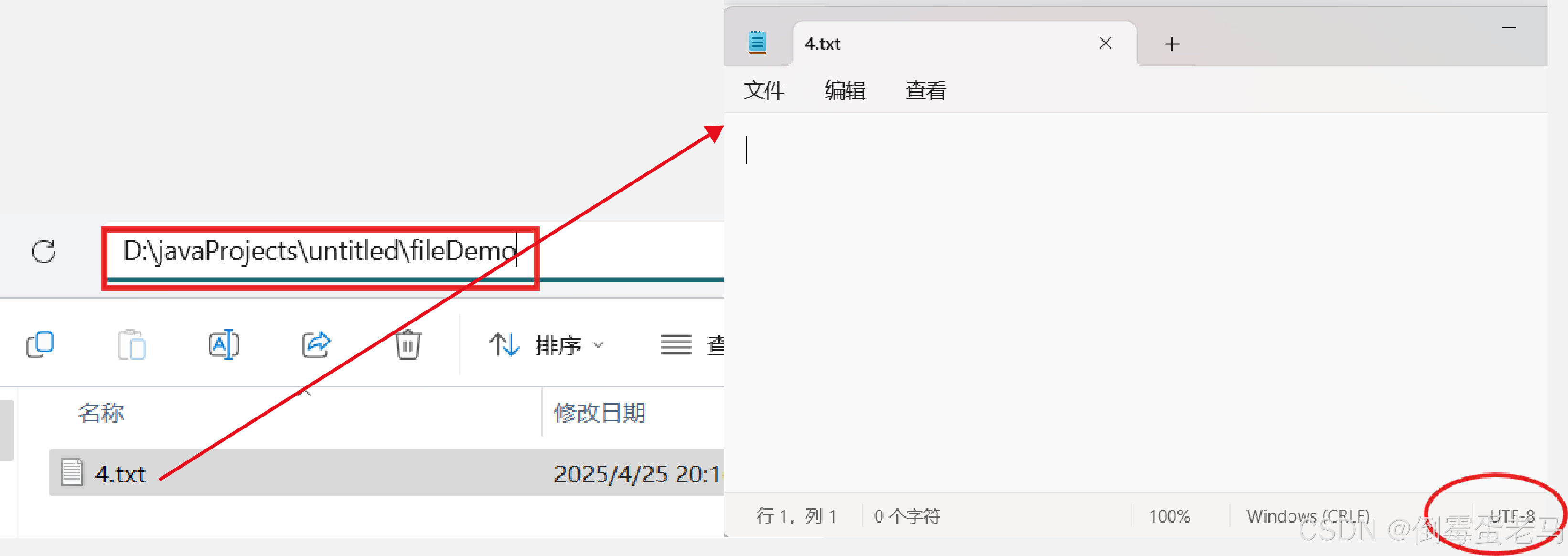
演示类中使用到的文件路径是 D:\javaProjects\untitled\fileDemo\4.txt,4.txt 是一个使用 UTF-8 编码的空文件,如下:
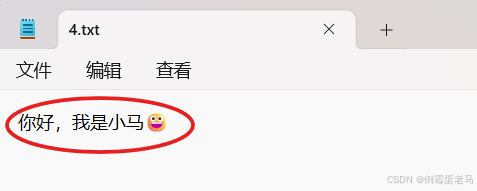
演示类完成的任务是:调用 write(byte[ ] b),往 4.txt 文件中写入文本内容 "你好,我是小马😀"
代码如下:
import java.io.*;
public class demo {public static void main(String[] args) throws IOException {//1.创建FileWriter字符输出流对象,关联目的地文件 4.txtFileOutputStream fos = new FileOutputStream("D:\\javaProjects\\untitled\\fileDemo\\4.txt");//2.调用write(byte[] b)写入文本内容"你好,我是小马😀"String content = "你好,我是小马😀";//定义写入内容byte[] bytes = content.getBytes("UTF-8");//对字符串按UTF-8编码,得到编码之后的字节数组fos.write(bytes);//把"你好,我是小马😀"对应的UTF-8字节数据写入文件//3.释放流资源,避免内存泄漏fos.close();}
}运行结果:
3.FileInputStream + FileOutputStream拷贝文件
拷贝文件大致流程图如下:
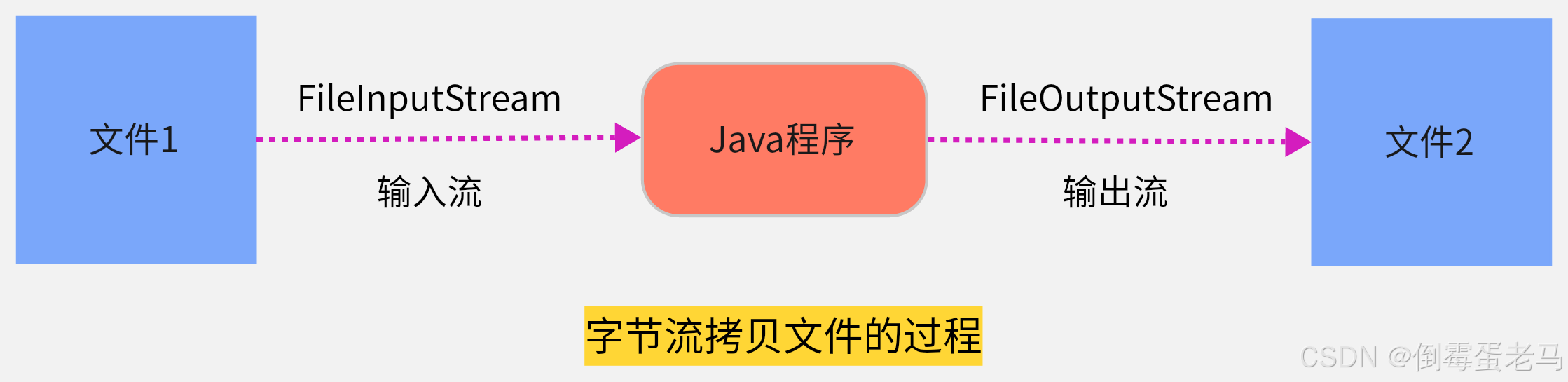
字符流只能拷贝 .txt、.java、.c、.cpp 等一些纯文本文件,对于.ppt、.png、.img、.mp3 等非文本文件是无法操作的,这时候就可以使用字节流来拷贝
需要注意的是:字节流是可以操作任何类型文件的,但因为在使用 FileInputStream 的时候读取文本文件的时候容易乱码,所以不会用来拷贝文本文件
下面就以拷贝一张图片为例,代码是通用的,拷贝视频、音频等二进制文件都行
字节流 FileInputStream + FileOutputStream 拷贝文件步骤
① 创建字符输入流 FileInputStream 对象,关联源文件
② 创建字符输出流 FileOutputStream 对象,关联目的地文件
③ 定义 byte 类型数组 b ,记录读取到的字节数据
④ 循环调用 FileInputStream 的 read(byte[ ] b) 方法读取,只要未到流末尾就一直读,将读取到的字节数据保存在 b 中
⑤ 将读取到的字节数据调用 FileOutputStream 的 write(byte[ ] b,int off,int len) 方法写入到目的地文件
⑥ 释放流资源,避免内存泄漏
案例演示
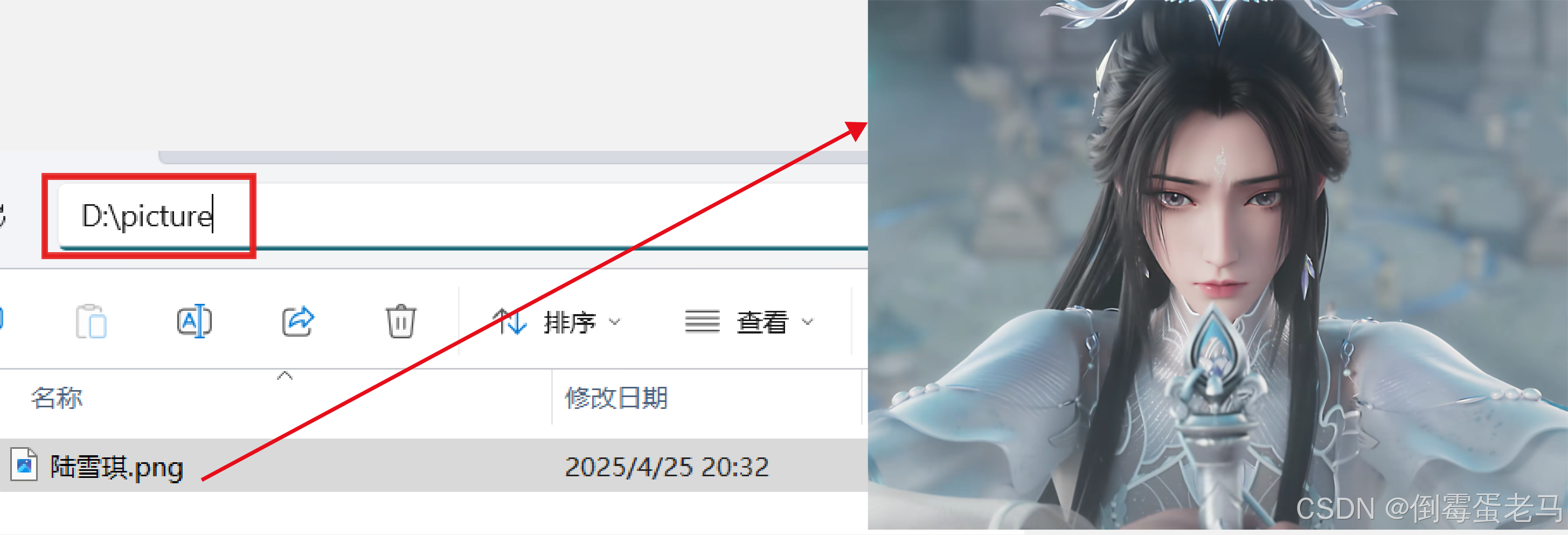
演示类中使用到的图片路径是 D:\picture\陆雪琪.png,如下:
演示类完成的任务是:拷贝该图片,拷贝后的图片存放在 D:\picture\陆雪琪拷贝.png
代码如下:
import java.io.*;
public class demo {public static void main(String[] args) throws IOException {/**字节流拷贝文件的通用代码模板*///1.创建字节输入流FileInputStream,关联源文件 陆雪琪.pngFileInputStream fis = new FileInputStream("D:\\picture\\陆雪琪.png");//2.创建字节输出流FileOutputStream,关联目的地文件 陆雪琪拷贝.pngFileOutputStream fos = new FileOutputStream("D:\\picture\\陆雪琪拷贝.png");//3.定义字节数组b,每次读取1024个字节byte[] b = new byte[1024];int len;//用来记录读取到的有效字符个数// 4.循环调用 read(byte[] b) 方法读取,未到文件末尾就一直读,并将读取到的字节数据保存在b中while ((len = fis.read(b)) != -1) {//5.将读取到的字节数据调用 write(byte[] b,int off,int len) 方法写入到目的地文件fos.write(b, 0, len);}//6.释放流资源,避免内存泄漏fos.close();fis.close();}
}运行结果:
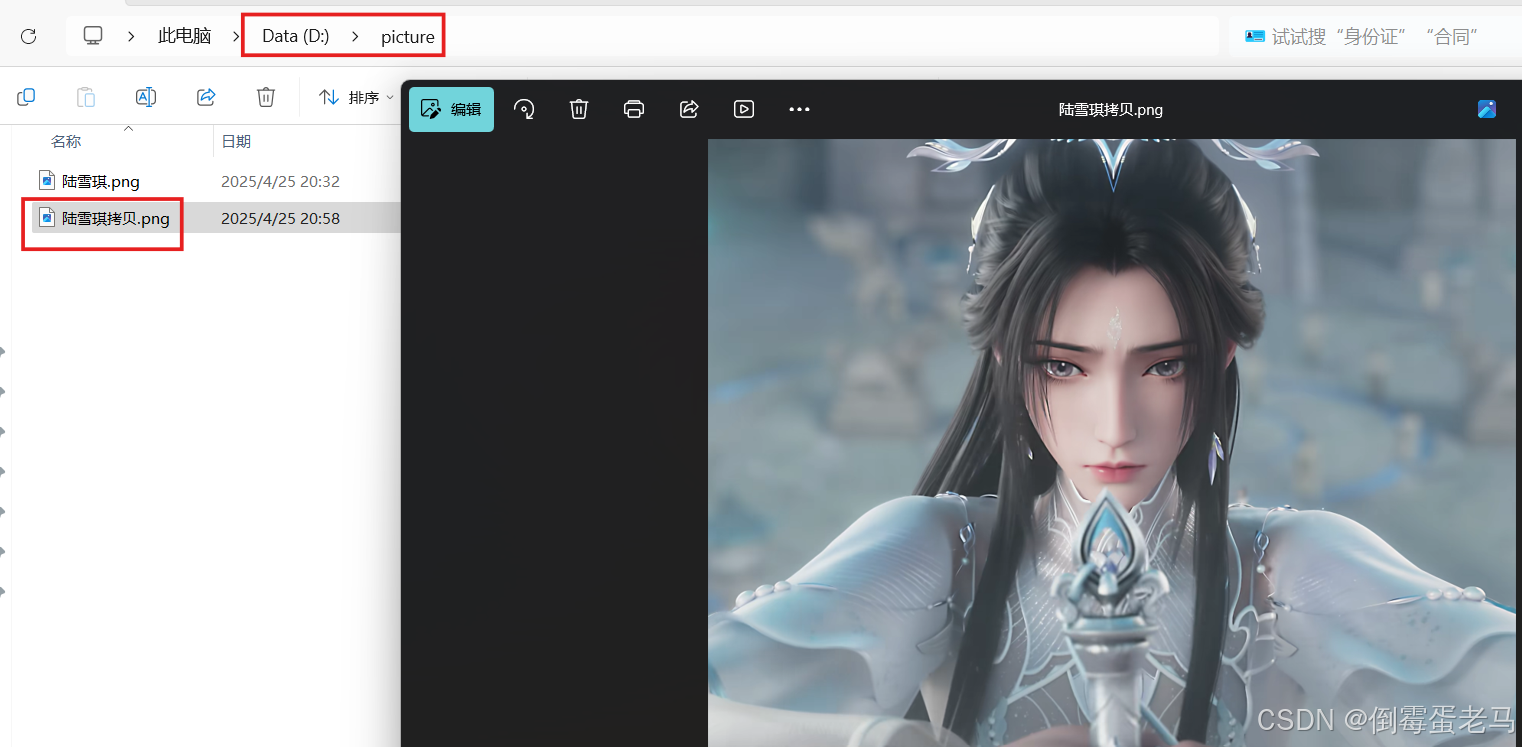
✌,拷贝成功
🆗,以上就是 FileInputStream 、 FileOutputStream 的所有内容,重点是拷贝文件部分